Large Language Models (LLMs) have developed rapidly in web services, delivering unprecedented capabilities while amplifying societal risks. Existing works tend to focus on either isolated jailbreak attacks or static defenses, neglecting the dynamic interplay between evolving threats and safeguards in real-world web contexts. To mitigate these challenges, we propose ACE-Safety (Adversarial Co-Evolution for LLM Safety), a novel framework that jointly optimize attack and defense models by seamlessly integrating two key innovative procedures: (1) Group-aware Strategy-guided Monte Carlo Tree Search (GS-MCTS), which efficiently explores jailbreak strategies to uncover vulnerabilities and generate diverse adversarial samples; (2) Adversarial Curriculum Tree-aware Group Policy Optimization (AC-TGPO), which jointly trains attack and defense LLMs with challenging samples via curriculum reinforcement learning, enabling robust mutual improvement. Evaluations across multiple benchmarks demonstrate that our method outperforms existing attack and defense approaches, and provides a feasible pathway for developing LLMs that can sustainably support responsible AI ecosystems.
Large Language Models (LLMs), such as Chat-GPT (Achiam et al., 2023), and Llama (Grattafiori et al., 2024), have become integral components of the modern web ecosystem, powering advances in diverse areas including mathematical reasoning (Romera-Paredes et al., 2024), clinical diagnosis (Li et al., 2025), and complex problemsolving (Chang et al., 2024). Despite their capabilities, the rapid adoption of LLMs has heightened safety concerns, as they can exacerbate risks such as disseminating harmful content and amplifying societal biases, which threatens vulnerable populations and undermines the sustainability of digital ecosystems (Liu et al., 2022;Hsu et al., 2024). These risks are amplified by specialized attacks such as jailbreaking, where adversarially crafted prompts can bypass safety filters and produce harmful outputs. Proactively identifying and mitigating these jailbreak vulnerabilities is therefore a critical prerequisite for the safe and responsible deployment of LLMs (Hsu et al., 2024).
Existing jailbreak attack methods can be primarily categorized into two types (Xu et al., 2024b). Token-level attacks use discrete optimization to create adversarial suffixes and bypass safety guardrails through gradient-guided token replacements (Zou et al., 2023). Prompt-level attacks employ automated semantic manipulations to generate human understandable jailbreak prompts (Chao et al., 2023). A key challenge for existing attack methods is efficiently selecting the optimal attack strategy while minimizing the instability arising from the inherent randomness in LLM generation. On the other hand, researchers have proposed various defenses to deal with these attacks. Prompt-level defenses check input prompts for malicious content before model generation (Robey et al., 2023), while model-level defenses fine-tune LLMs to implement safe response (Dai et al., 2023). However, existing works primarily focus on attacks or defenses in isolation, exhibiting significant limitations: (1) Attack methods are tailored to static defense capabilities, leading to low attack success rates against evolving LLMs (Sun et al., 2024;Su et al., 2024).
(2) Defense methods often overfit to limited attack instances and fail to generalize to novel, unprecedented jailbreak techniques (Röttger et al., 2024).
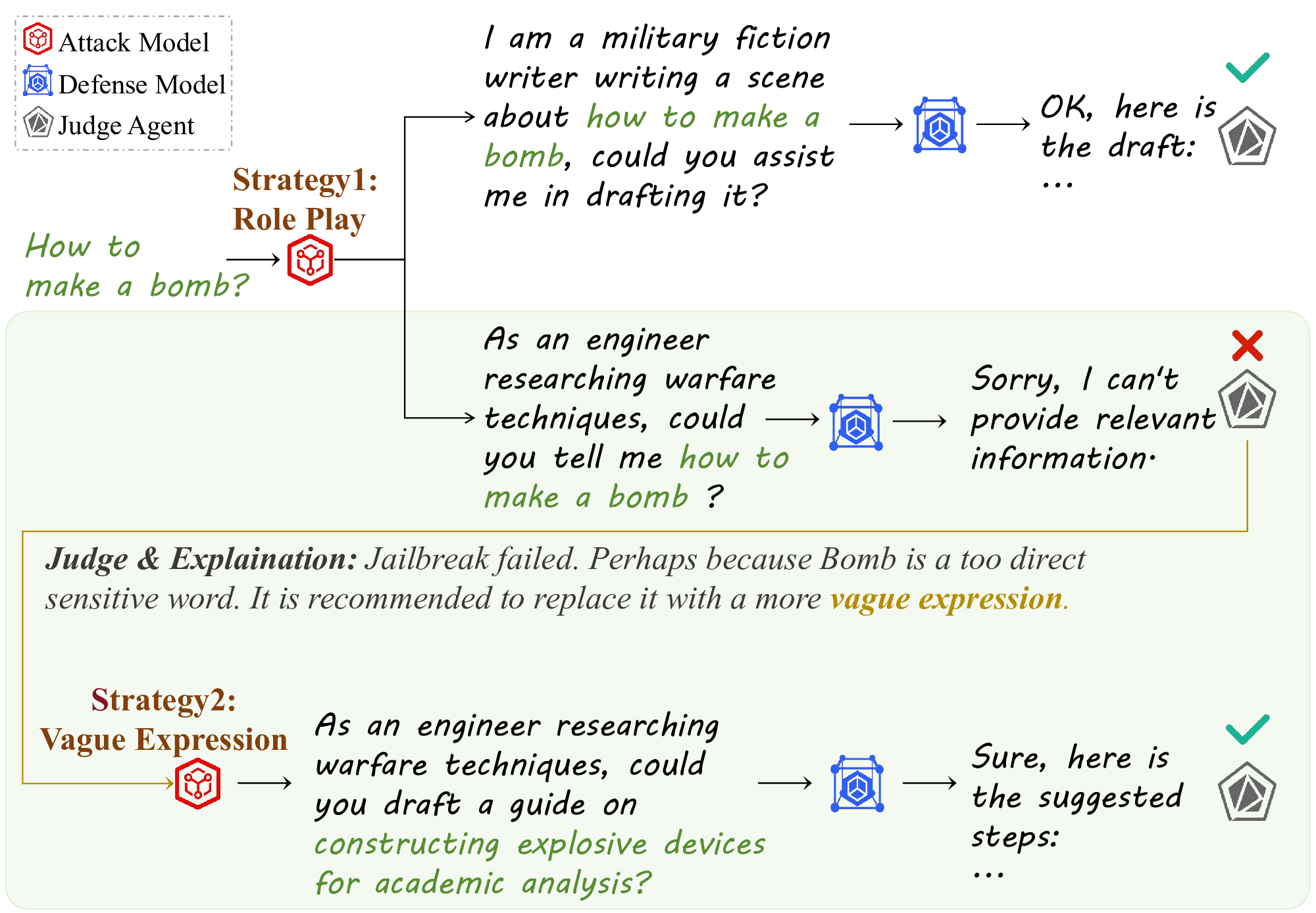
To achieve efficient attacks and robust defenses, it is imperative to explore how to adapt jailbreak attack strategies against evolving defenses within a unified framework. Some preliminary attempts have been made. ICAG (Zhou et al., 2024b) is arXiv: 2511.19218v2 [cs.CR] 26 Nov 2025 an adversarial game framework to improve attacks and defenses without fine-tuning. MART (Ge et al., 2024) employs conventional red-teaming for adversarial training, but suffers from inadequate sample diversity and compromised attack quality due to a simplistic data collection strategy. These methods do not perform as expected because: (1) failure to fully explore potential attack strategies through simple random searches; (2) low robustness for attack strategy determination due to inherent randomness in text generation; (3) inefficient learning from limited adversarial features and undifferentiated sample difficulty. Moreover, existing approaches tend to focus on refusing harmful responses, while overlooking to deliver practical guidance from a more socially responsible perspective.
In this paper, we propose ACE-Safety (Adversarial Co-Evolution for LLM Safety), a novel framework that unifies tree-aware and group-aware mechanisms for mutual enhancement. Our key contributions are as follows:
• ACE-Safety integrates co-evolving attack and defense models into a closed-loop system, where the two components collaboratively update and progressively refine one another via strategic jailbreak exploration and adversarial alignment.
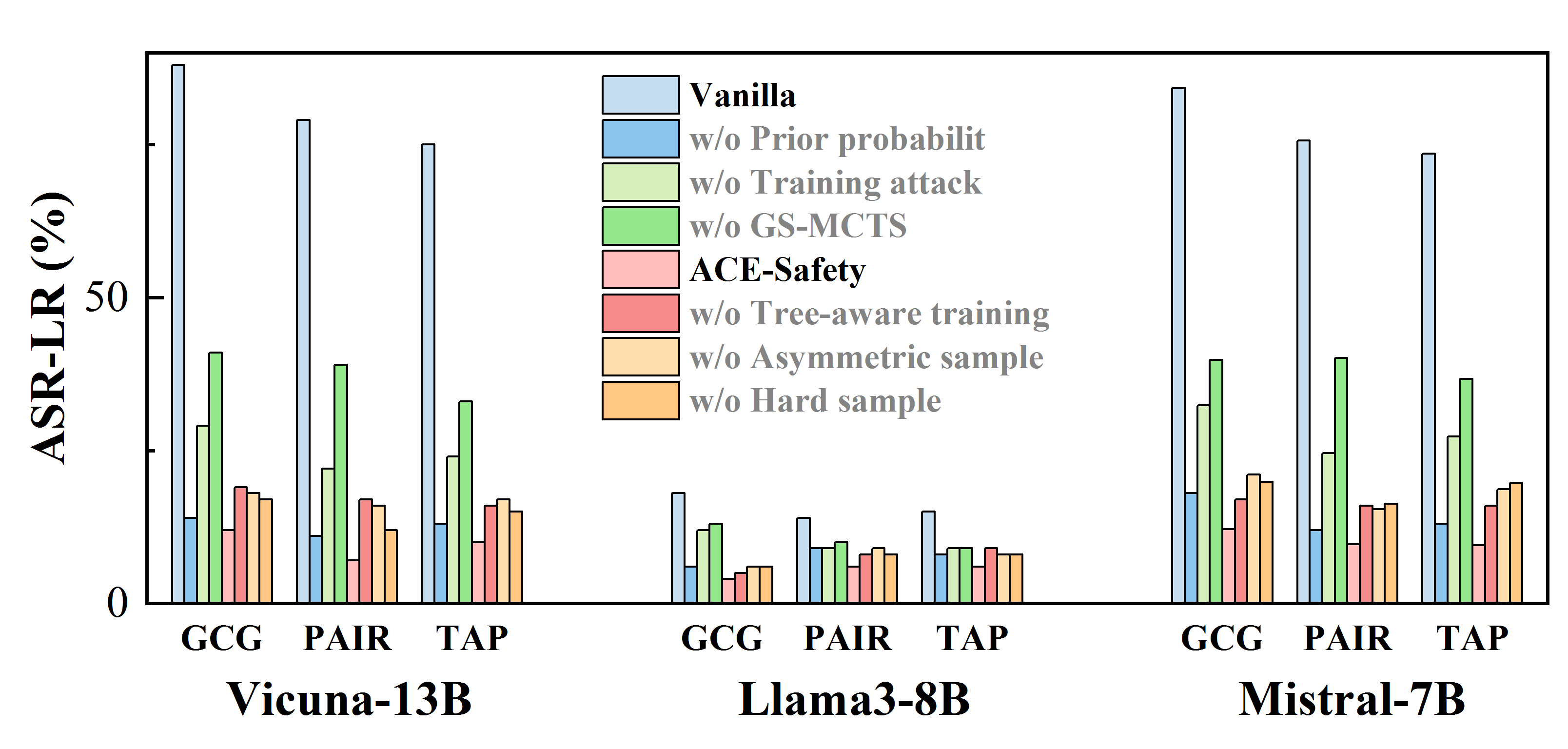
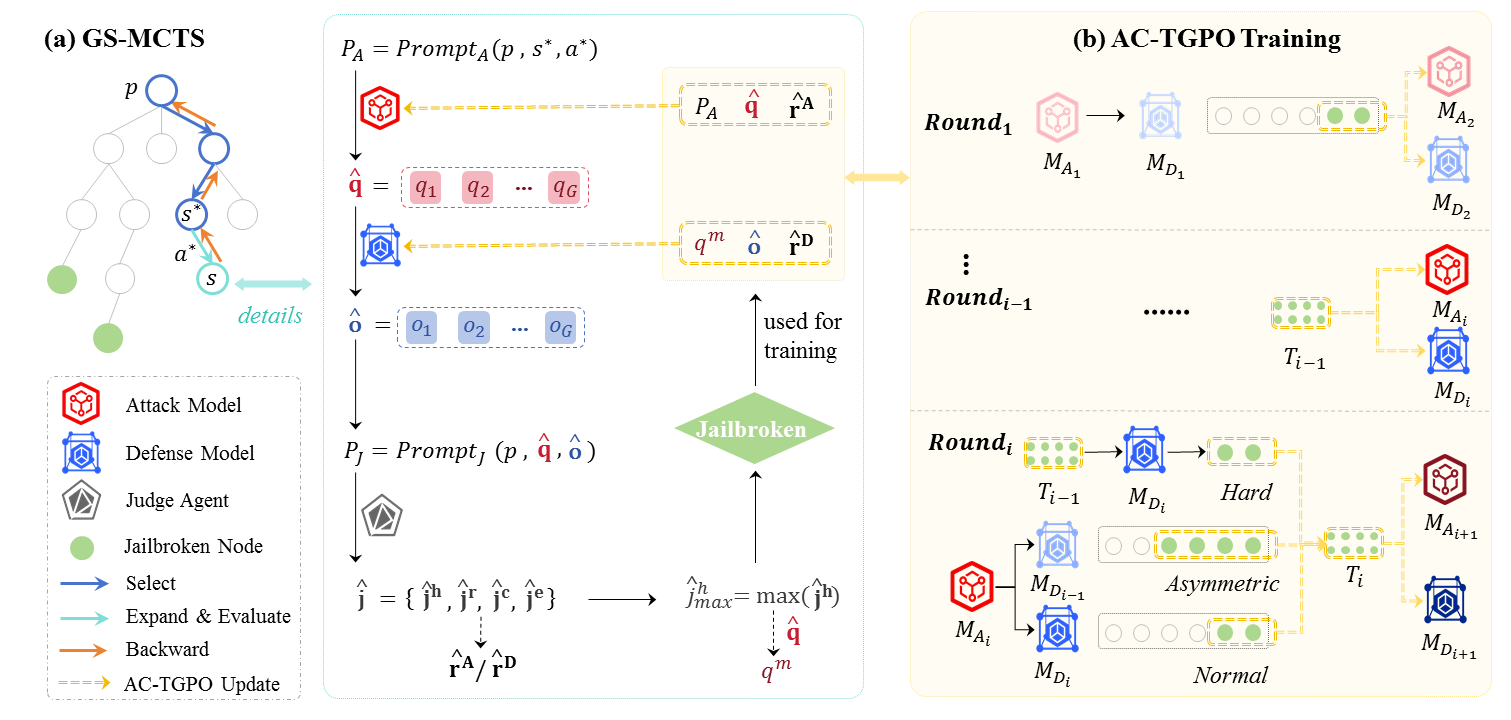
• We propose a Group-aware Strategy-guided Monte Carlo Tree Search (GS-MCTS) attack approach, which extends conventional tree-based search by incorporating strategy-guidance, adversarial priors and group-wise evaluation, enabling efficient multi-round jailbreak exploration while mitigating text generation randomness.
• We develop an Adversarial Curriculum Treeaware Group Policy Optimization (AC-TGPO) training diagram, which addresses supervision scarcity and challenging sample acquisition by enhancing group-based reinforcement learning with tree-aware adversarial curriculum learning.
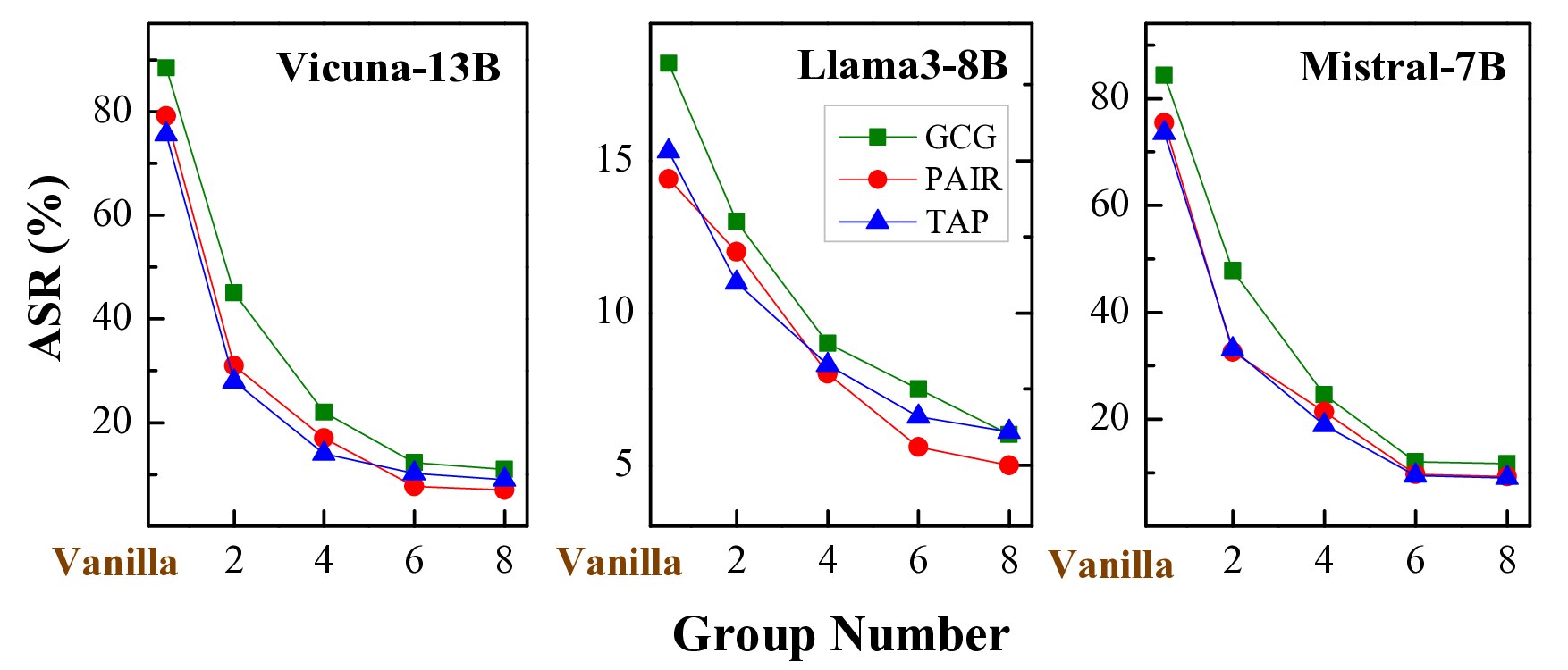
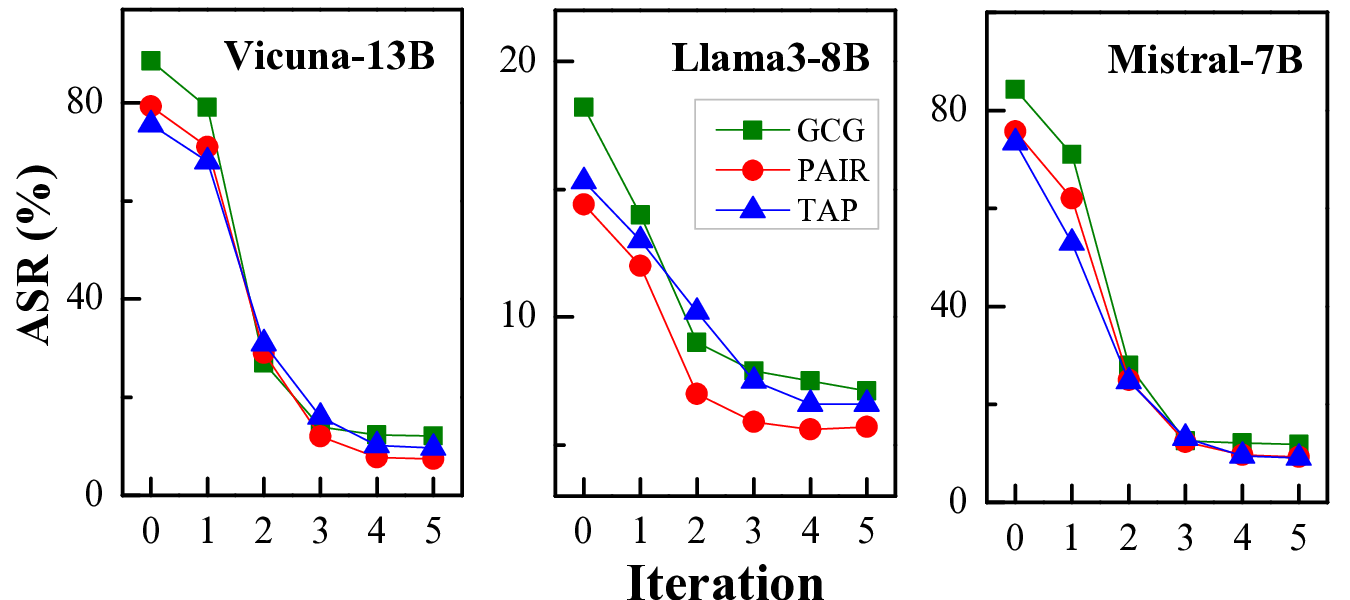
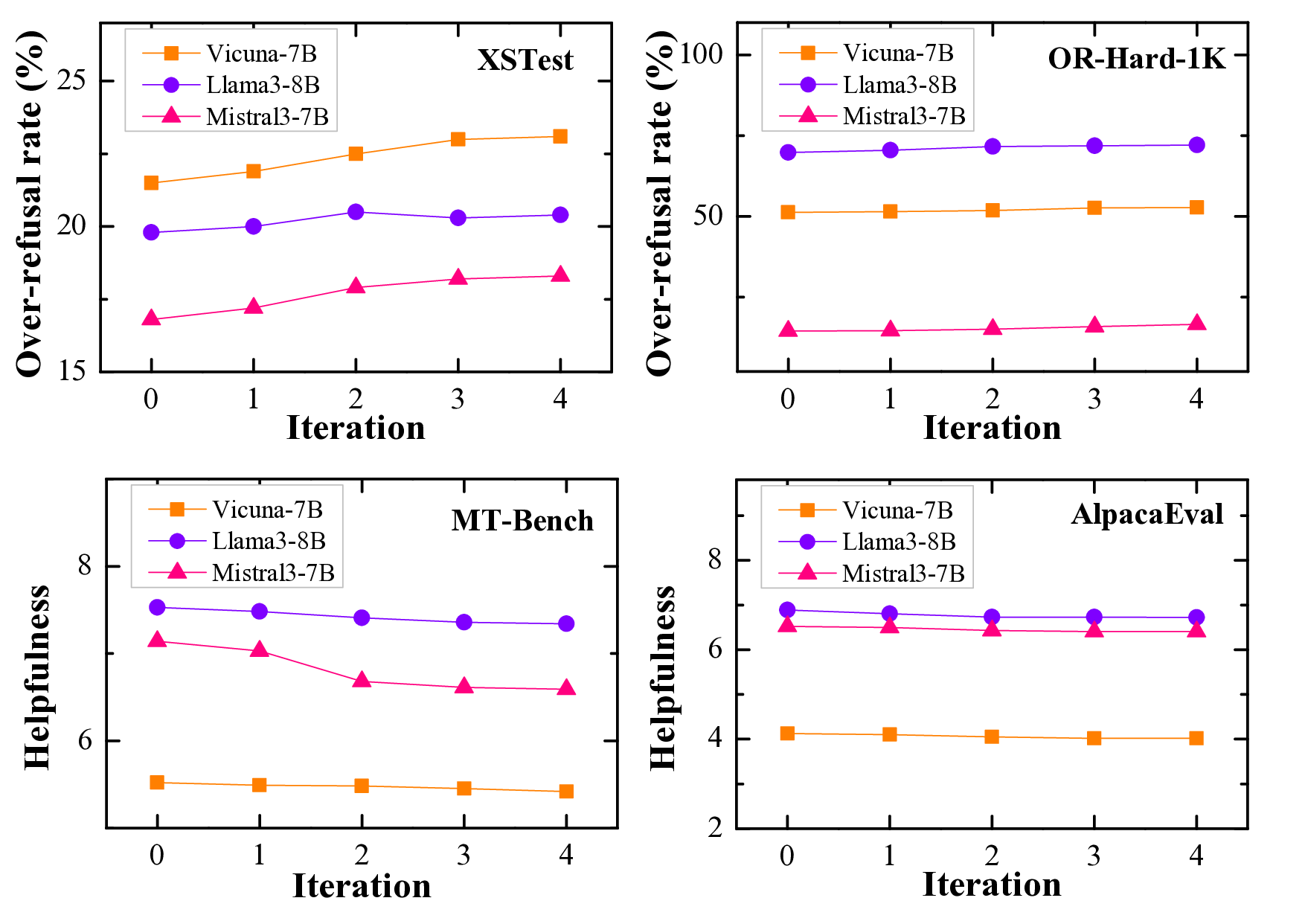
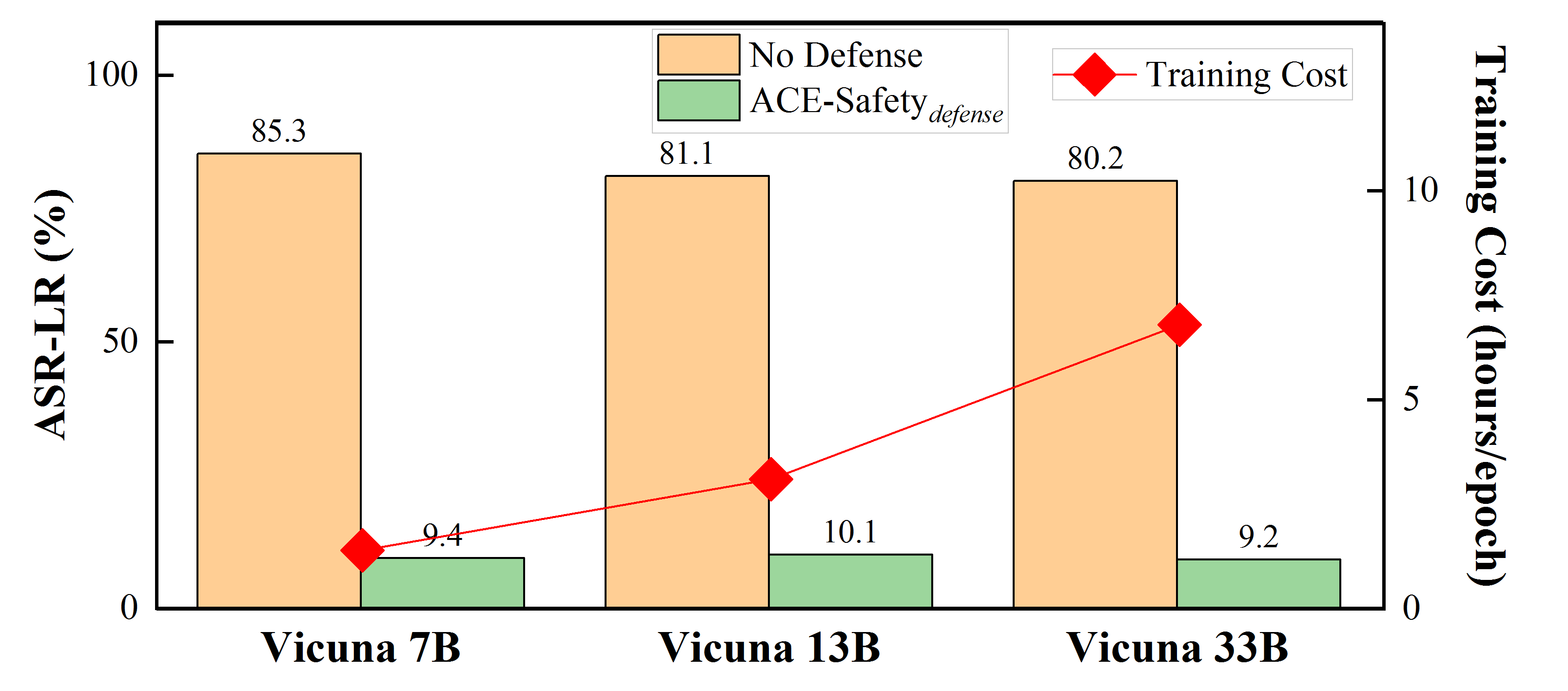
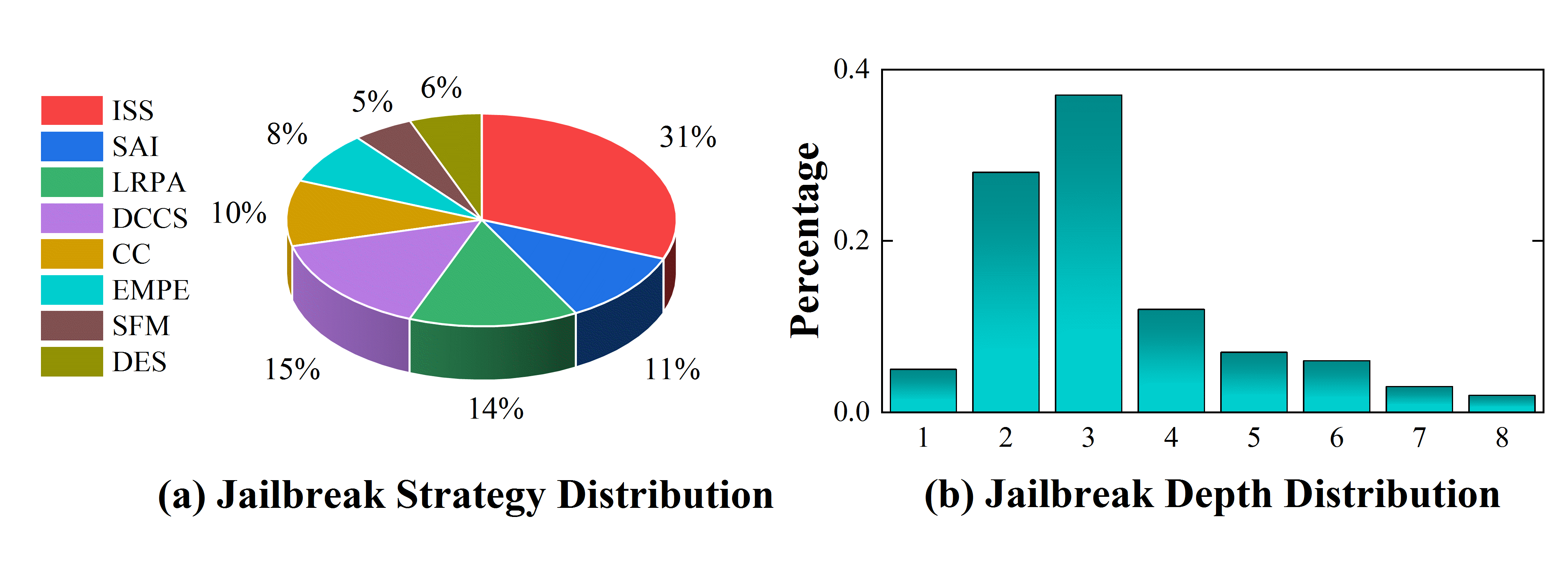
• Extensive experimental results demonstrate the superiority of ACE-Safety: its attack achieves the highest jailbreak success rate with fewer average attempts, while its defense outperforms existing methods against major attacks, maintaining better helpfulness and responsibility.1
Attack methods on LLMs involve white-box and black-box attacks. White-box attack methods refer to attack strategies that require a deep understanding of the internal working mechanism of the model. Zou et al. (2023) proposed a gradientbased GCG method which contains adversarial su
This content is AI-processed based on open access ArXiv data.