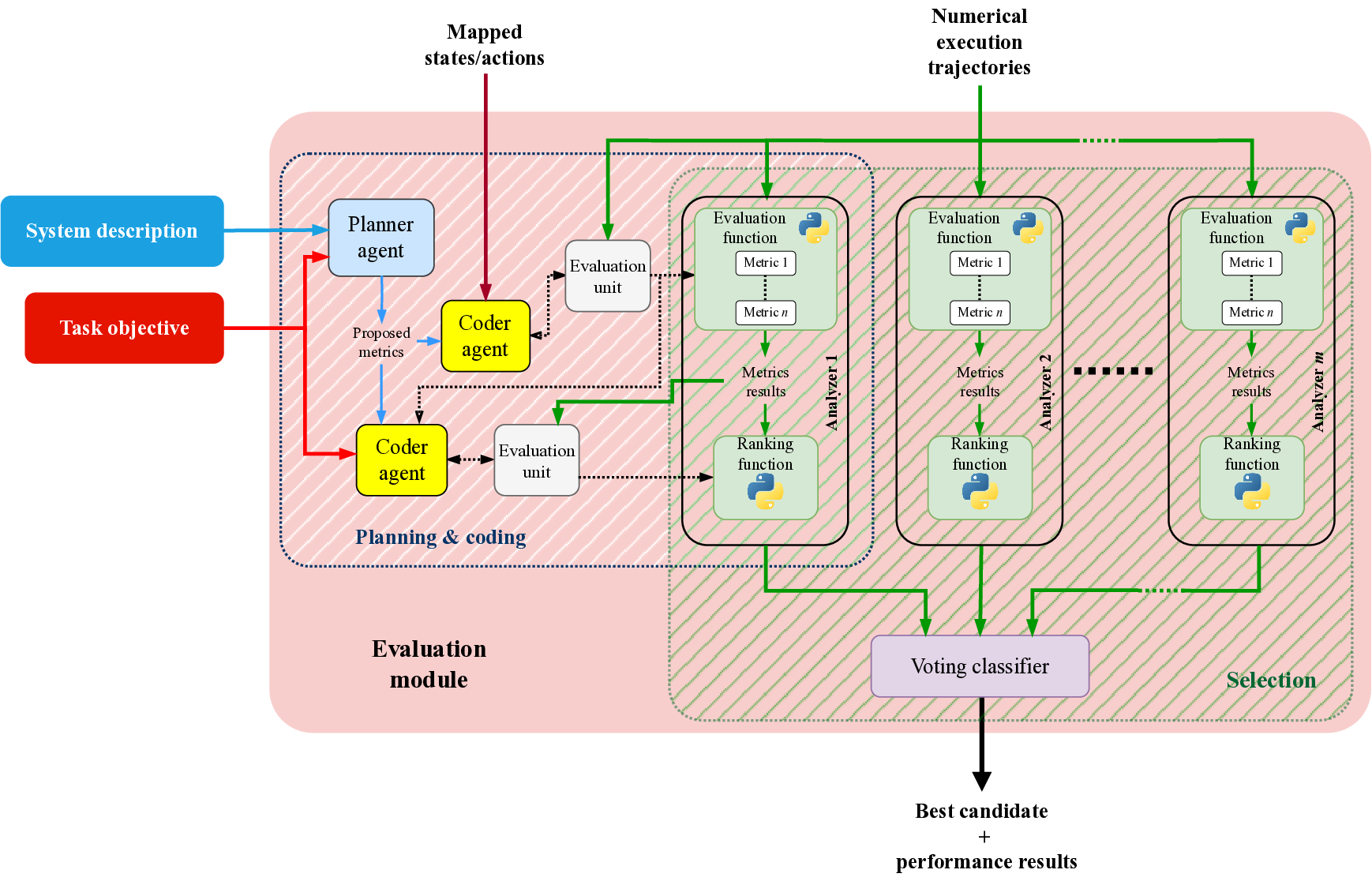
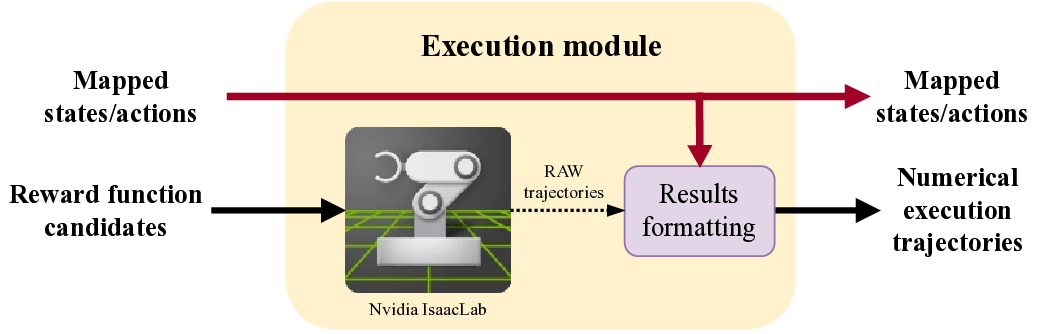
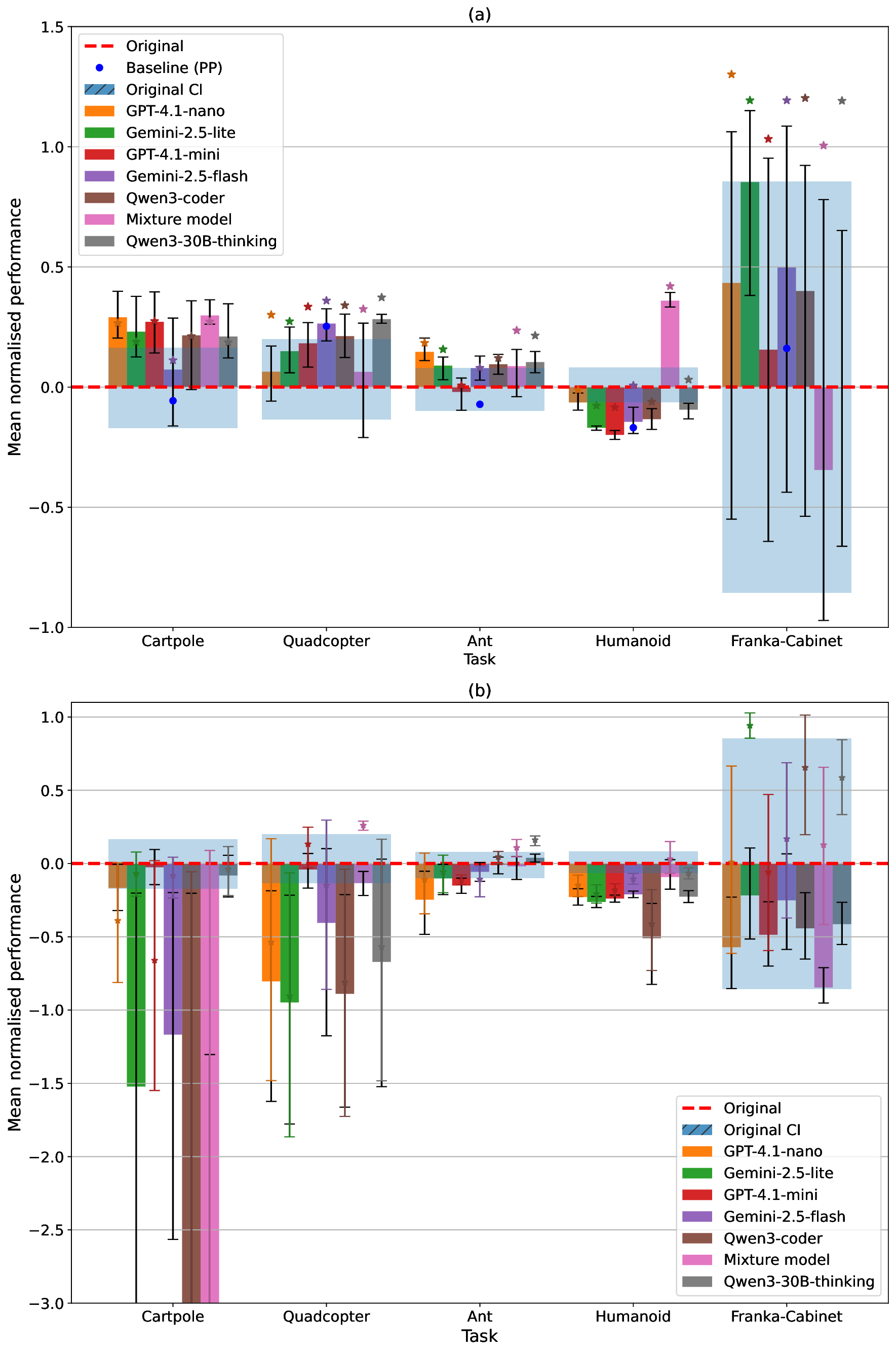
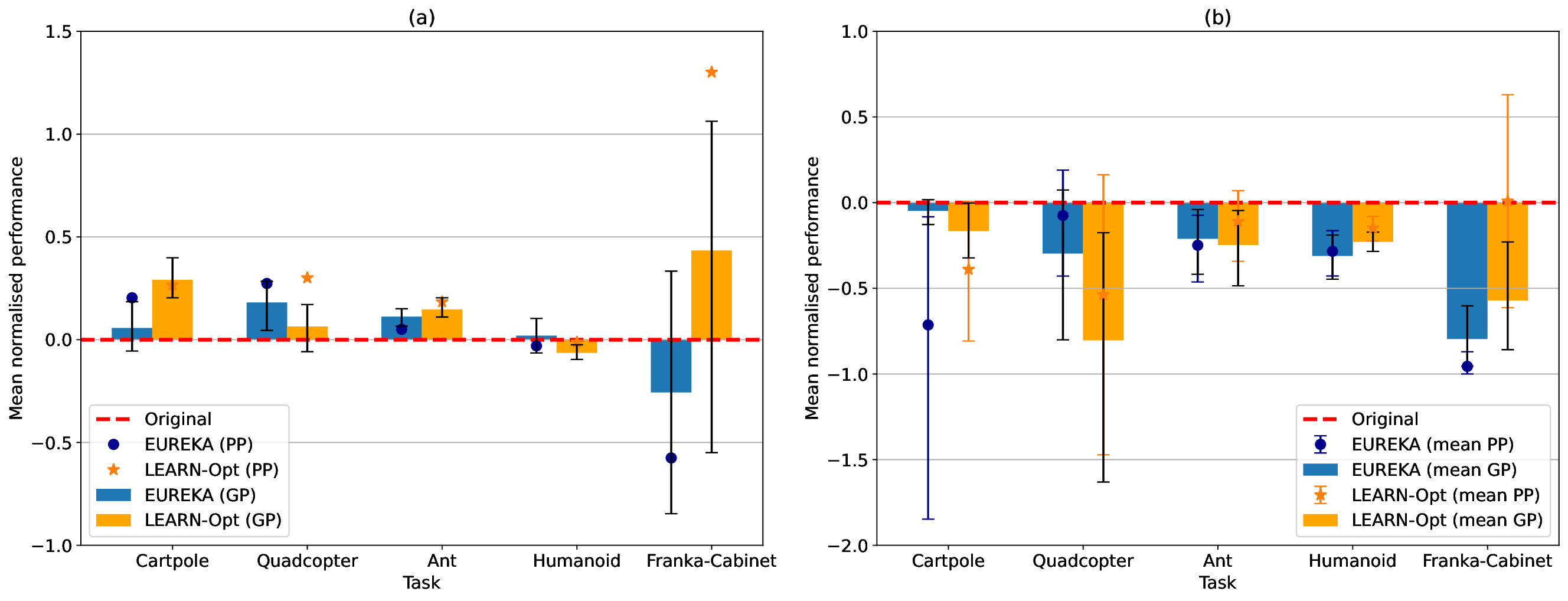
Title: Leveraging LLMs for reward function design in reinforcement learning control tasks
ArXiv ID: 2511.19355
Date: 2025-11-24
Authors: Franklin Cardenoso, Wouter Caarls
📝 Abstract
The challenge of designing effective reward functions in reinforcement learning (RL) represents a significant bottleneck, often requiring extensive human expertise and being time-consuming. Previous work and recent advancements in large language models (LLMs) have demonstrated their potential for automating the generation of reward functions. However, existing methodologies often require preliminary evaluation metrics, human-engineered feedback for the refinement process, or the use of environmental source code as context. To address these limitations, this paper introduces LEARN-Opt (LLM-based Evaluator and Analyzer for Reward functioN Optimization). This LLM-based, fully autonomous, and model-agnostic framework eliminates the need for preliminary metrics and environmental source code as context to generate, execute, and evaluate reward function candidates from textual descriptions of systems and task objectives. LEARN-Opt's main contribution lies in its ability to autonomously derive performance metrics directly from the system description and the task objective, enabling unsupervised evaluation and selection of reward functions. Our experiments indicate that LEARN-Opt achieves performance comparable to or better to that of state-of-the-art methods, such as EUREKA, while requiring less prior knowledge. We find that automated reward design is a high-variance problem, where the average-case candidate fails, requiring a multi-run approach to find the best candidates. Finally, we show that LEARN-Opt can unlock the potential of low-cost LLMs to find high-performing candidates that are comparable to, or even better than, those of larger models. This demonstrated performance affirms its potential to generate high-quality reward functions without requiring any preliminary human-defined metrics, thereby reducing engineering overhead and enhancing generalizability.
💡 Deep Analysis
📄 Full Content
Leveraging LLMs for reward function design in
reinforcement learning control tasks
Franklin Cardenoso1* and Wouter Caarls1
1*Departament of Electrical Engineering, Pontificial Catholic University
of Rio de Janeiro, Rua Marquˆes de S˜ao Vicente, 225, Rio de Janeiro,
22451-900, RJ, Brazil.
*Corresponding author(s). E-mail(s): fracarfer5@gmail.com;
Contributing authors: wouter@puc-rio.br;
Abstract
The challenge of designing effective reward functions in reinforcement learning
(RL) represents a significant bottleneck, often requiring extensive human exper-
tise and being time-consuming. Previous work and recent advancements in large
language models (LLMs) have demonstrated their potential for automating the
generation of reward functions. However, existing methodologies often require
preliminary evaluation metrics, human-engineered feedback for the refinement
process, or the use of environmental source code as context. To address these
limitations, this paper introduces LEARN-Opt (LLM-based Evaluator and Ana-
lyzer for Reward functioN Optimization). This LLM-based, fully autonomous,
and model-agnostic framework eliminates the need for preliminary metrics and
environmental source code as context to generate, execute, and evaluate reward
function candidates from textual descriptions of systems and task objectives.
LEARN-Opt’s main contribution lies in its ability to autonomously derive per-
formance metrics directly from the system description and the task objective,
enabling unsupervised evaluation and selection of reward functions. Our experi-
ments indicate that LEARN-Opt achieves performance comparable to or better
to that of state-of-the-art methods, such as EUREKA, while requiring less prior
knowledge. We find that automated reward design is a high-variance problem,
where the average-case candidate fails, requiring a multi-run approach to find
the best candidates. Finally, we show that LEARN-Opt can unlock the poten-
tial of low-cost LLMs to find high-performing candidates that are comparable
to, or even better than, those of larger models. This demonstrated performance
affirms its potential to generate high-quality reward functions without requiring
any preliminary human-defined metrics, thereby reducing engineering overhead
and enhancing generalizability.
1
arXiv:2511.19355v1 [cs.LG] 24 Nov 2025
Keywords: reinforcement learning, large language models, reward engineering, reward
function
1 Introduction
Reinforcement learning (RL), a trial-and-error-based policy optimization approach [1],
has demonstrated to be a powerful paradigm, achieving remarkable success in a wide
range of tasks, from mastering intricate games to advanced robotic control [2, 3].
However, its great success across diverse domains is highly related to the quality
of the reward functions, since well-designed reward signals are essential for guiding
the agent’s learning process towards desired behaviors and providing the necessary
feedback for policy optimization and convergence [4].
Given its fundamental importance, designing a practical reward function becomes
a challenging aspect of RL development, particularly for complex or high-dimensional
tasks. Although this process can be done through reward engineering or reward shaping
techniques, the manual design of reward functions is a highly non-trivial process that
often requires extensive domain expertise. In fact, quantifying desired outcomes is
inherently tricky, making it a time-consuming trial-and-error process [5].
This iterative process can lead to suboptimal behaviors or, in some cases, unin-
tended consequences, as the agent may exploit loopholes in the reward structure rather
than achieving the true underlying objective [6]. Consequently, the combined complex-
ity and effort required for human-crafted rewards create a major bottleneck, limitating
the applicability and scalability of RL systems in more complex scenarios. Therefore,
there is a need for automated solutions in reward design to advance the adoption and
scalability of these systems.
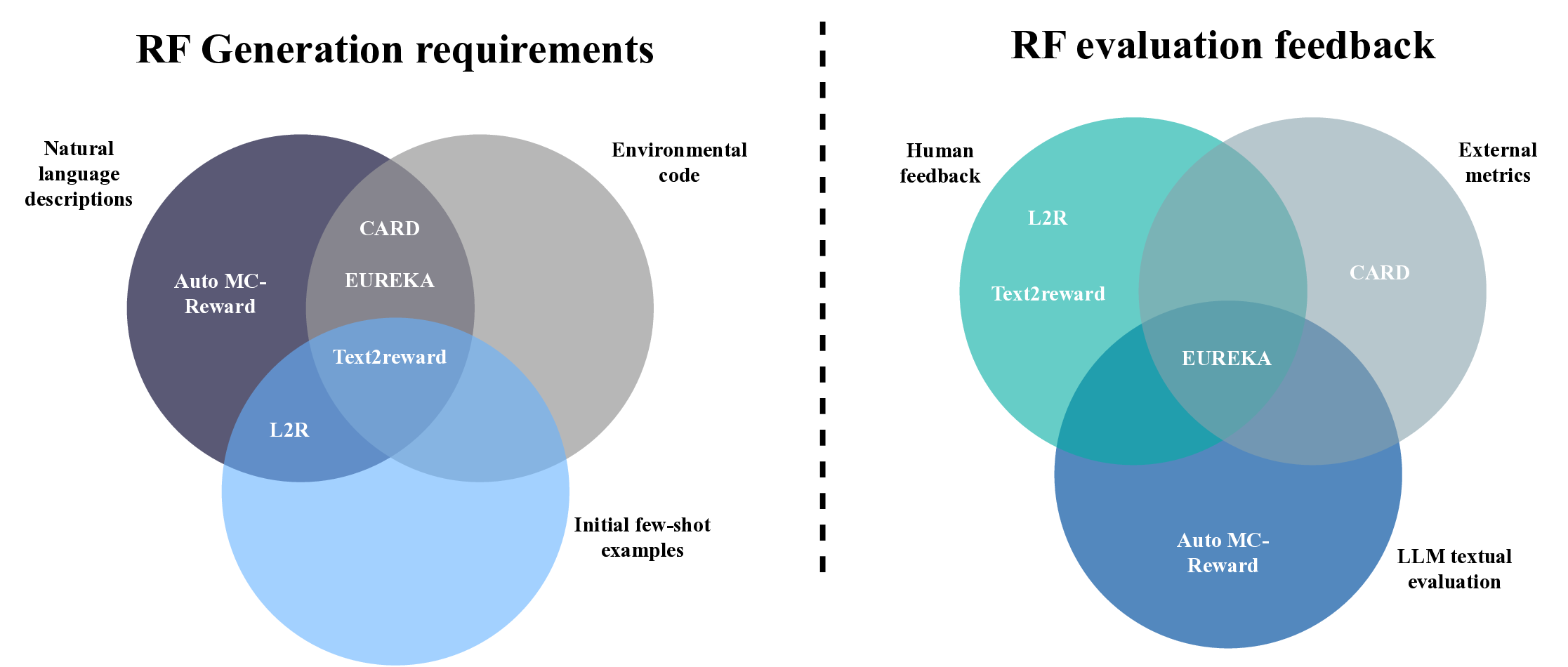
On the other hand, recent breakthroughs in large language models (LLMs) [7, 8]
have opened new avenues for automating various tasks, including, for instance, high-
level decision-making and code generation, which are used in general applications and,
more specifically, in robotics and RL [9, 10].
More specifically, the LLMs, with their advanced understanding of natural language
and specialized coding tasks, offer a promising path to decrease the manual effort and
become a powerful tool for automating the reward design process. One of the most
representative examples of this paradigm is EUREKA, which demonstrates how LLMs
can be leveraged for reward function code generation in an evolutionary scheme [11].
By using raw environment source code as input, EUREKA performs evolutionary
optimization over candidates guided by feedback, achieving impressive performance
across different tasks without requiring task-specific prompts. Besides EUREKA,