Emergent communication in multi-agent systems typically occurs through independent learning, resulting in slow convergence and potentially suboptimal protocols. We introduce TSLEC (Trust-Based Social Learning with Emergent Communication), a framework where agents explicitly teach successful strategies to peers, with knowledge transfer modulated by learned trust relationships. Through experiments with 100 episodes across 30 random seeds, we demonstrate that trust-based social learning reduces episodes-to-convergence by 23.9% (p < 0.001, Cohen's d = 1.98) compared to independent emergence, while producing compositional protocols (C = 0.38) that remain robust under dynamic objectives (Phi > 0.867 decoding accuracy). Trust scores strongly correlate with teaching quality (r = 0.743, p < 0.001), enabling effective knowledge filtering. Our results establish that explicit social learning fundamentally accelerates emergent communication in multi-agent coordination.
Autonomous agents coordinating without pre-designed protocols face a fundamental challenge: how to develop efficient communication while simultaneously learning task policies. Recent advances in Multi Agent Reinforcement Learning (MARL) demonstrate that communication protocols can emerge through task optimization [1,2,3], but agents typically learn independently, leading to redundant exploration and slower convergence. Human language acquisition, by contrast, relies heavily on social learning-children learn from teachers who explicitly demonstrate linguistic structures [4].
This raises our central question: can artificial agents accelerate communication emergence through mutual teaching, similar to human language learning? Existing approaches suffer from three limitations. First, agents learn protocols independently without explicit knowledge transfer mechanisms [5]. Second, most frameworks assume static environments where objectives remain fixed [6], yet real-world applications require adaptation to dynamic conditions. Third, there is limited understanding of how trust relationships between agents modulate communication effectiveness [7].
We introduce TSLEC (Trust-Based Social Learning with Emergent Communication), where agents that discover successful negotiation strategies actively teach these strategies to peers through encoded messages. Learners adopt strategies based on learned trust scores that reflect historical teaching quality, creating a social learning mechanism that filters high-quality knowledge from noise. Simultaneously, agents adapt their objectives in response to environmental changes and peer performance, requiring protocols to remain flexible.
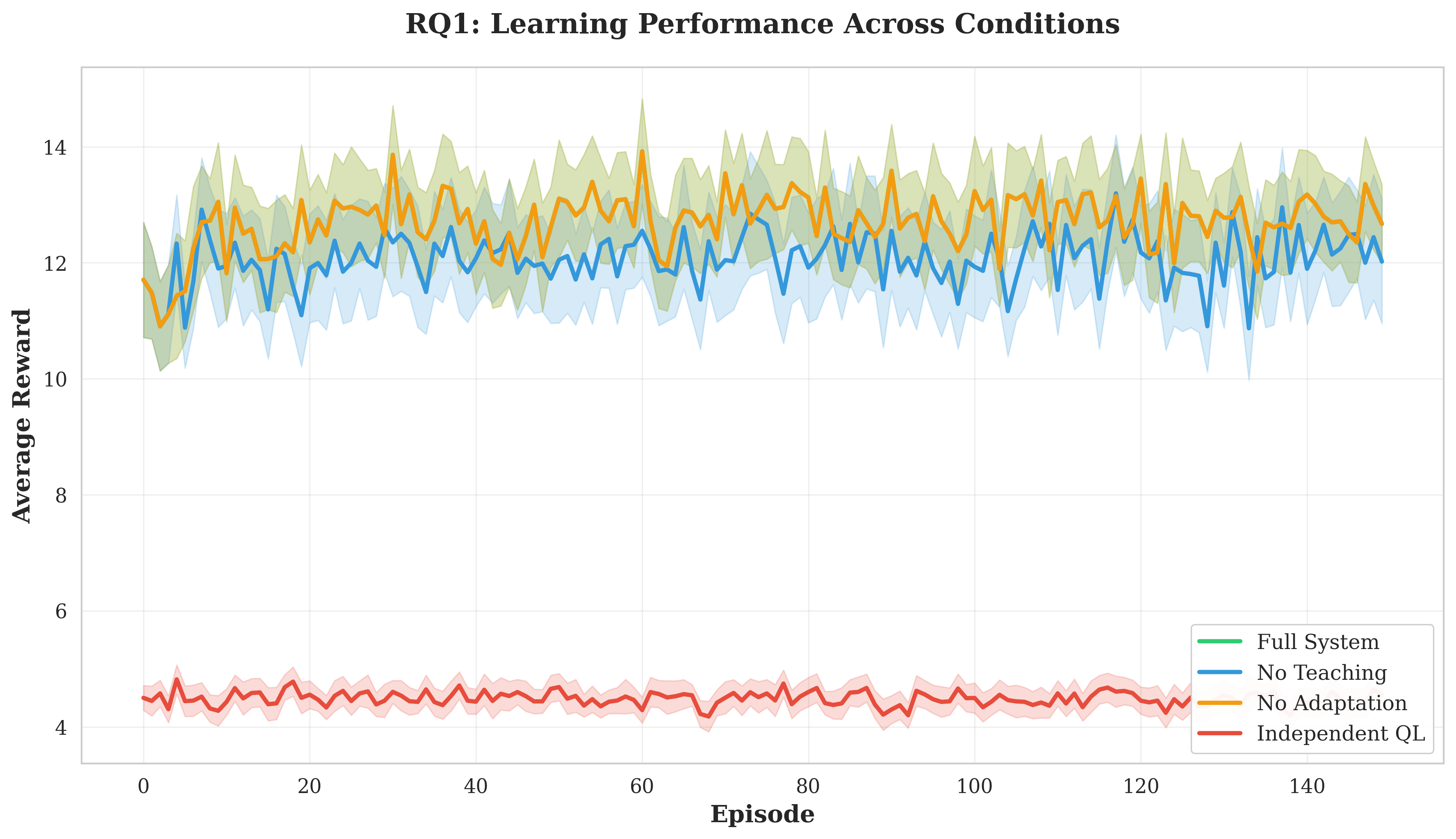
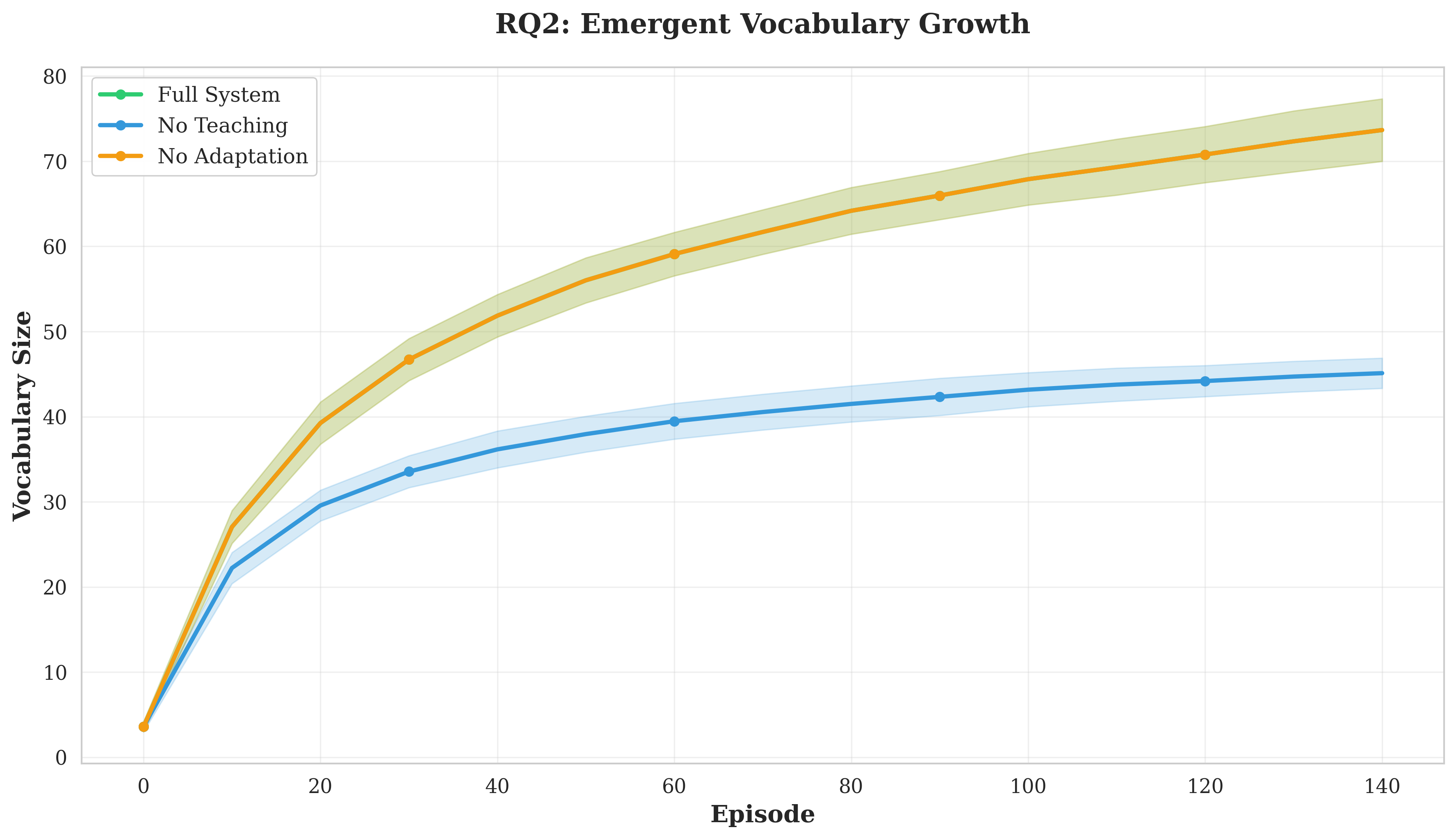
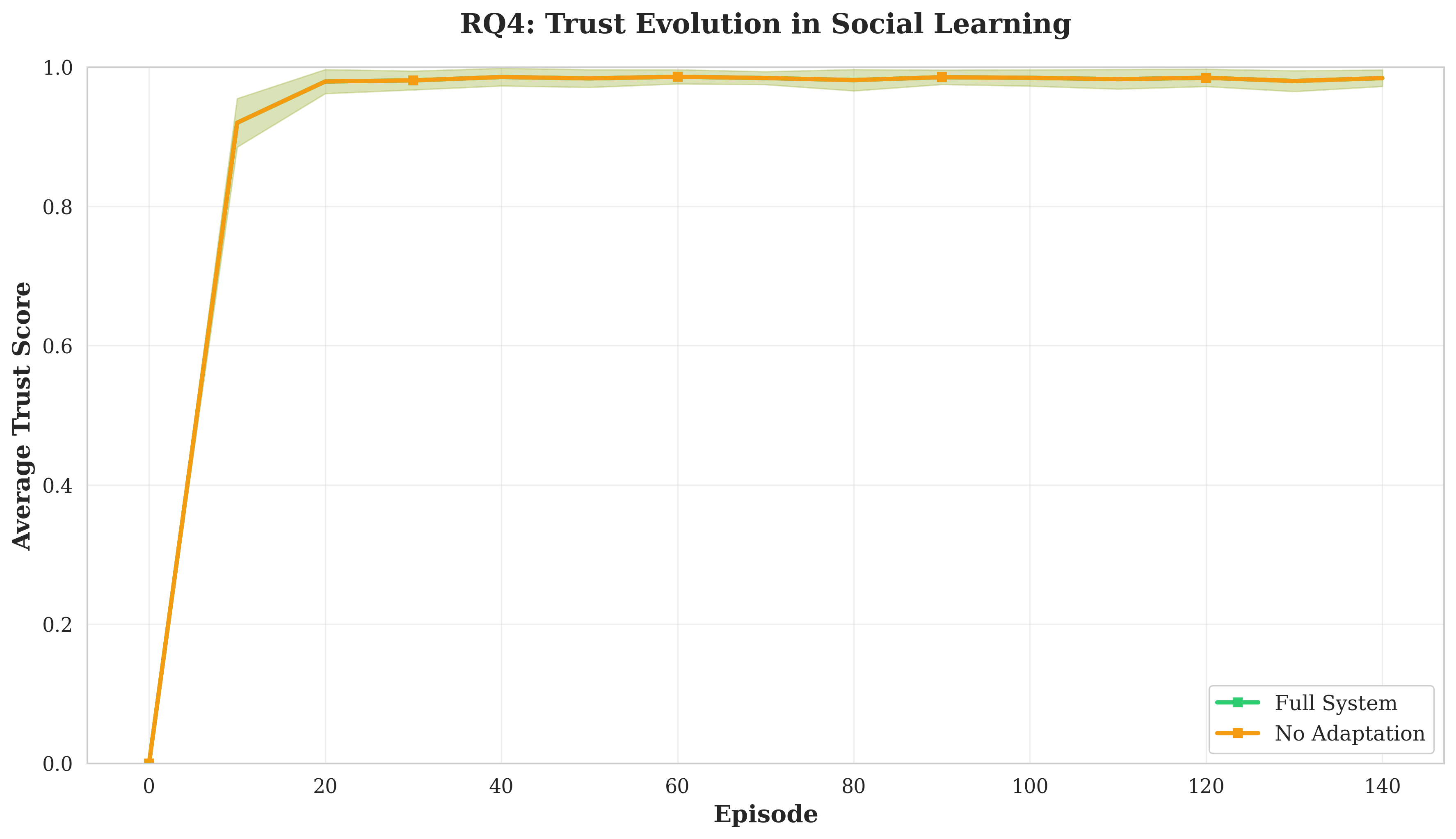
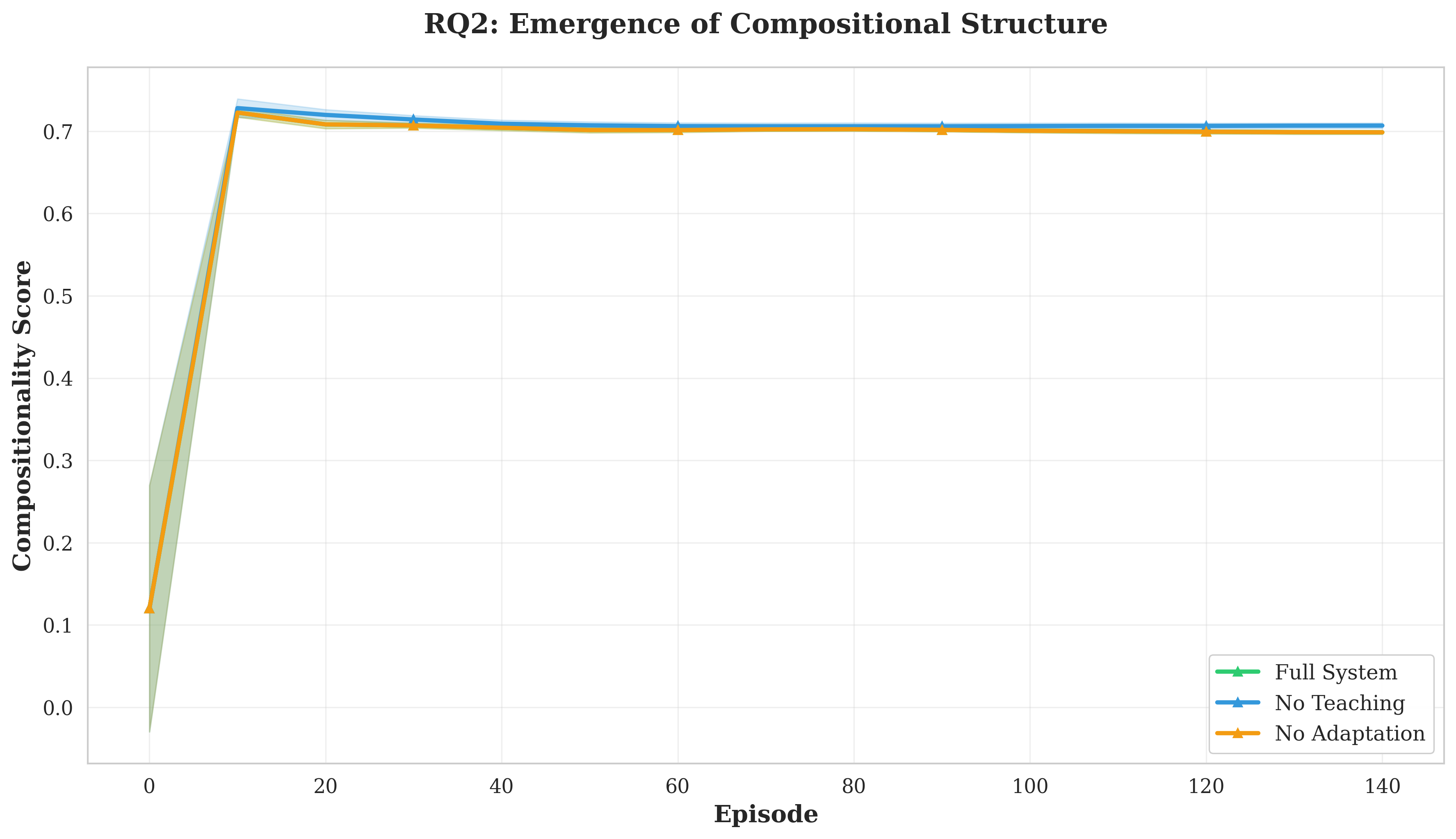
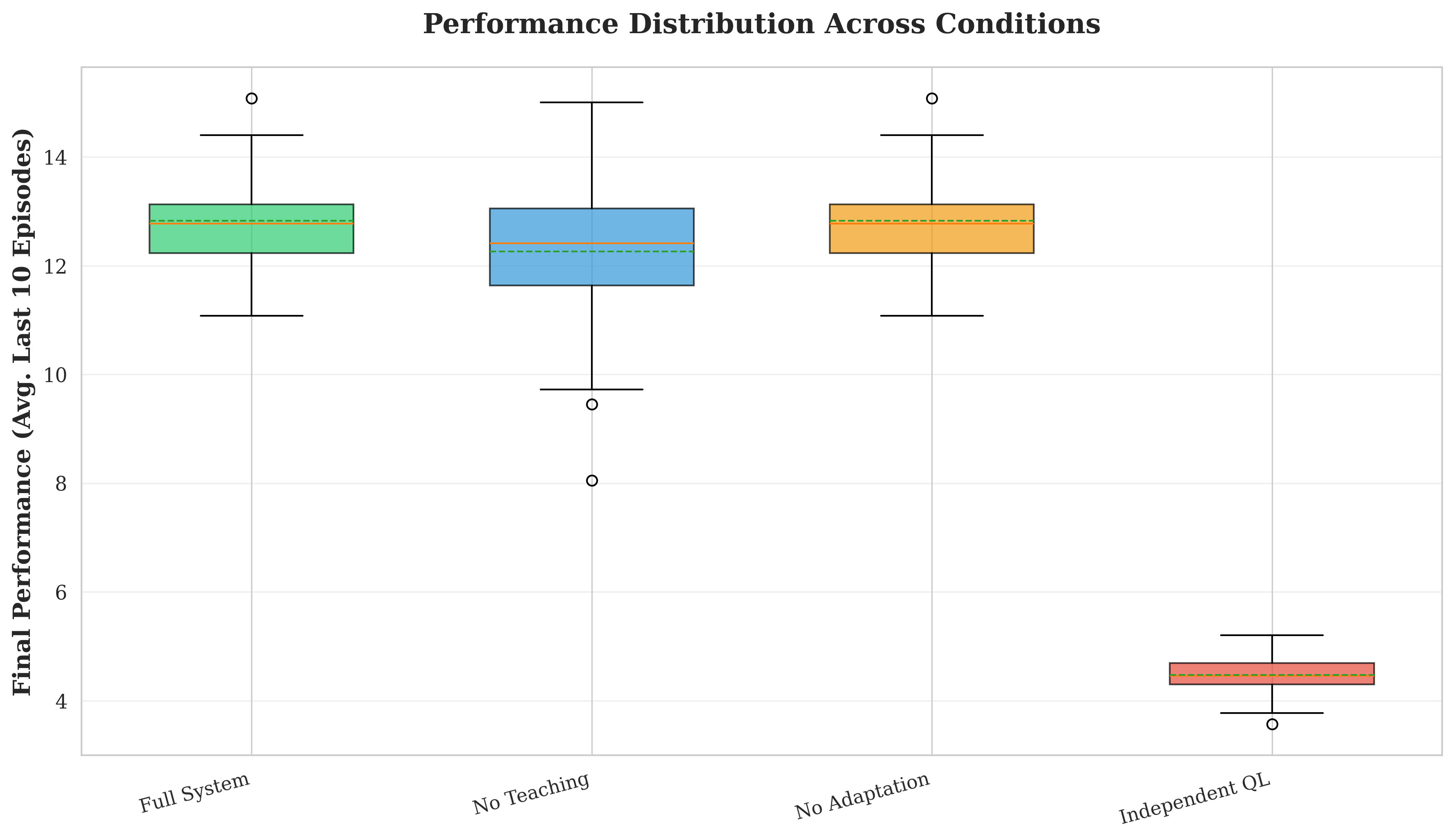
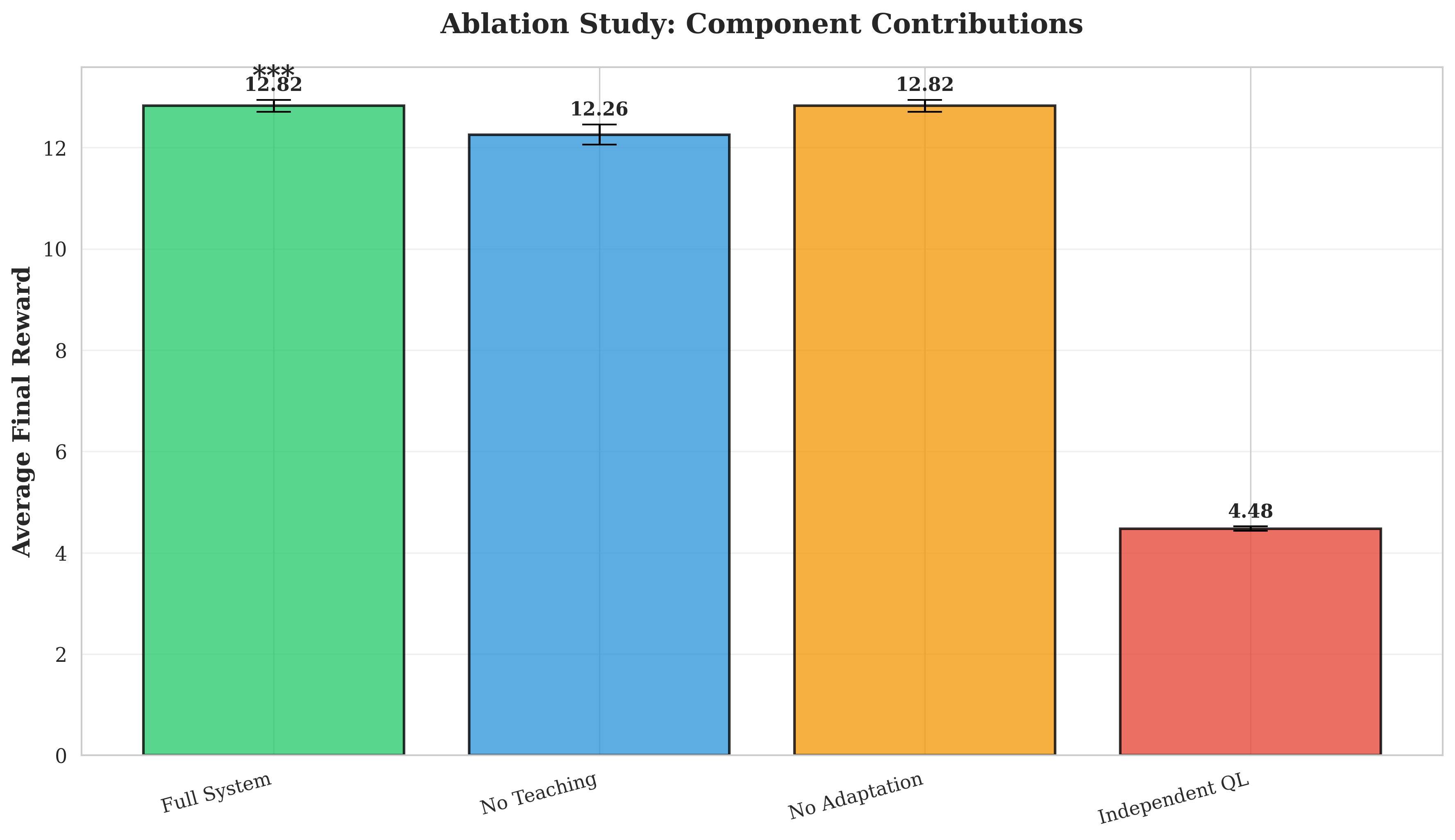
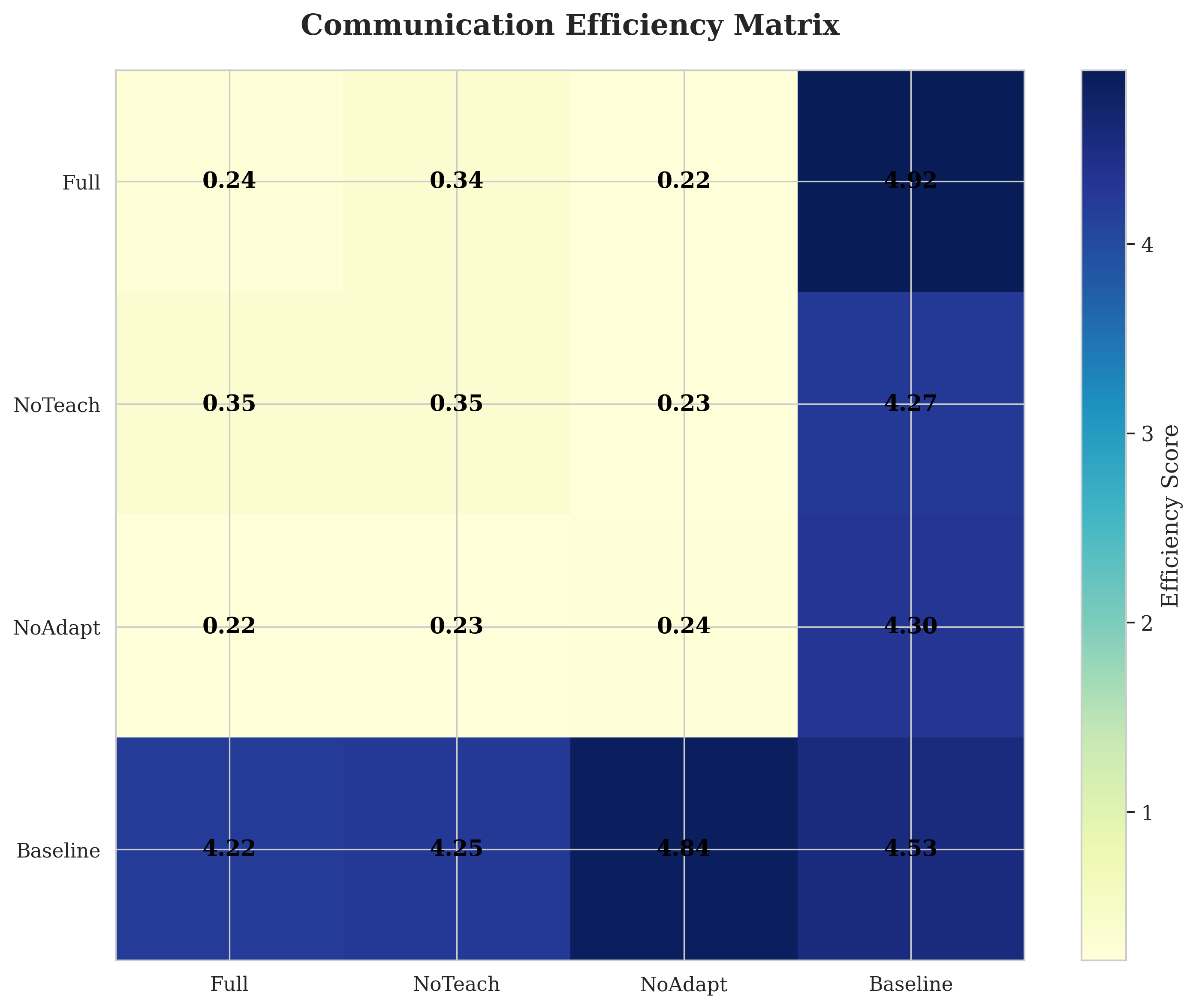
Our contributions are fourfold. First, we develop a trust-based social learning architecture that reduces convergence time by 23.9% compared to independent learning (p < 0.001, effect size d = 1.98). Second, we demonstrate that emergent protocols exhibit compositional structure (C = 0.38) without architectural constraints, with social learning producing more systematic languages than independent emergence. Third, we show that protocols maintain effectiveness (Φ > 0.867 decoding accuracy) despite dynamic objectives, revealing inherent protocol flexibility. Fourth, we validate that trust scores accurately predict teaching quality (r = 0.743, p < 0.001), enabling robust knowledge filtering. These results establish explicit social learning as a fundamental accelerator for multi-agent coordination.
Emergent Communication. Foundational work demonstrates that agents can develop protocols through reinforcement learning [1,8,2]. Lazaridou et al. [6] studied referential games where communication emerges through task pressure. Mordatch and Abbeel [3] showed grounded communication in embodied environments. However, these approaches assume independent learning without mechanisms for knowledge transfer between peers.
Social Learning in MARL. Omidshafiei et al. [9] introduced frameworks where agents query peers for advice. Jiang et al. [10] proposed peer-regularized actor-critic. Population-based training [11] achieves strong performance through implicit learning from diverse populations. However, no prior work combines emergent communication with explicit peer teaching modulated by learned trust.
Trust Mechanisms. Trust has been extensively studied for partner selection and security [7,12]. However, these approaches focus on task performance rather than knowledge transfer quality. TSLEC introduces trust mechanisms specifically designed for social learning with emergent communication, where trust reflects teaching effectiveness rather than negotiation ability.
We formalize multi-agent negotiation as N agents A = {a 1 , . . . , a N } negotiating over M items with limited quantities Q = {q 1 , . . . , q M }. Each agent a i has private goal vector g i ∈ R M assigning values to items. Given allocation x i ∈ Z M ≥0 , utility is:
subject to resource constraints i x i,j ≤ q j . Each episode consists of T negotiation rounds. In round t, agent a i observes state s t i = (Q t remaining , t), selects action α t i ∈ {AGGRESSIVE, COOPERATIVE, BALANCED}, and generates proposal
. .] are broadcast. Agent a j decodes using sender’s vocabulary: pt
Trust Dynamics. Each agent maintains trust scores τ ij ∈ [0, 1] for peers, updated based on teaching effectiveness:
The asymmetric rates (β pos > β neg ) reflect that trust builds slowly but erodes quickly [13]. Mission Adaptation. Goals adapt via environmental changes and peer performance:
with λ env = 0.7 for environmental adaptation and λ peer = 0.8 for peer-based adaptation.
TSLEC integrates four mechanisms: Q-learning with emergent communication, trust-based teaching, mission adaptation, and protocol analysis. Algorithm 1 presents the core structure.
Action Selection. Lines 7-12 implement three-tier selection: (1) if high trust exists (τ ij > 0.7), use most-trusted peer’s strategy, (2) else exploit Qvalues, (3) or expl
This content is AI-processed based on open access ArXiv data.