Title: VLM in a flash: I/O-Efficient Sparsification of Vision-Language Model via Neuron Chunking
ArXiv ID: 2511.18692
Date: 2025-11-24
Authors: Kichang Yang, Seonjun Kim, Minjae Kim, Nairan Zhang, Chi Zhang, Youngki Lee
📝 Abstract
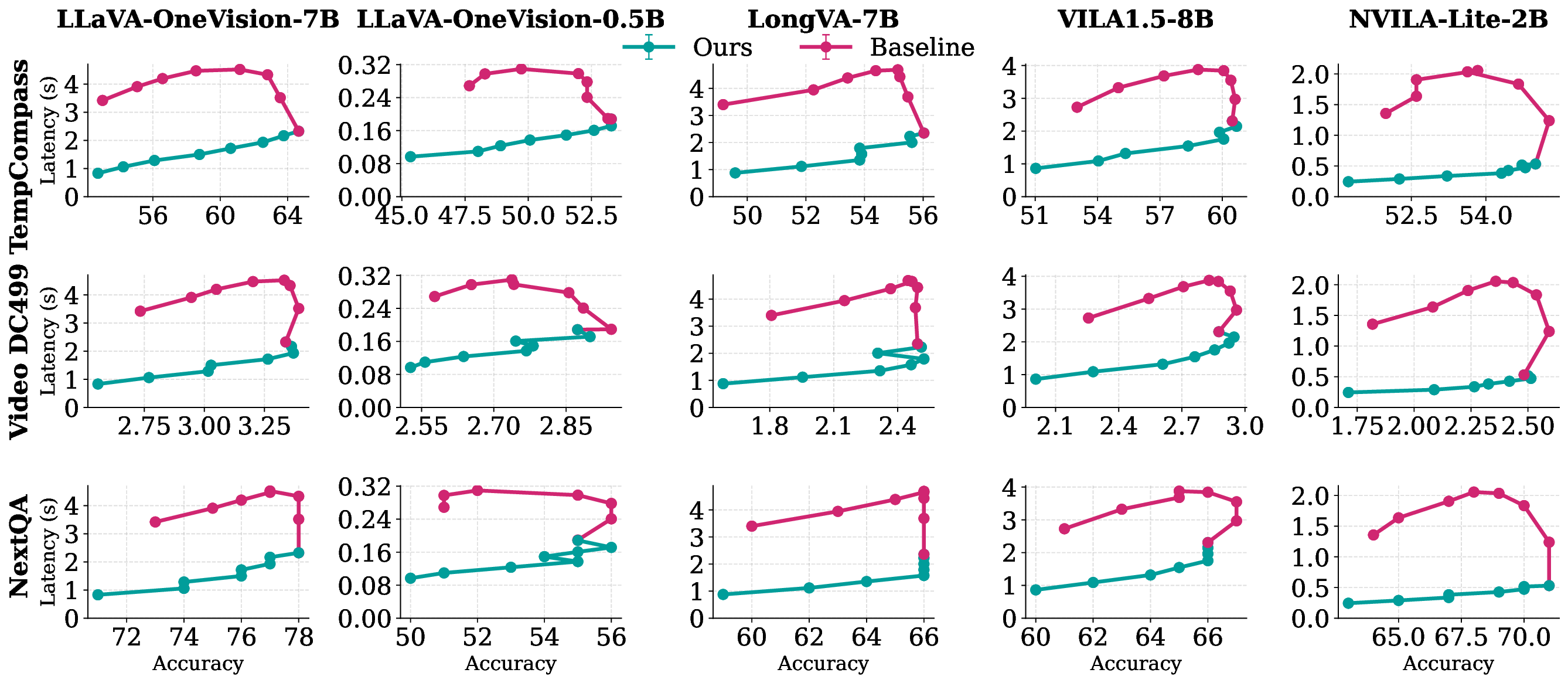
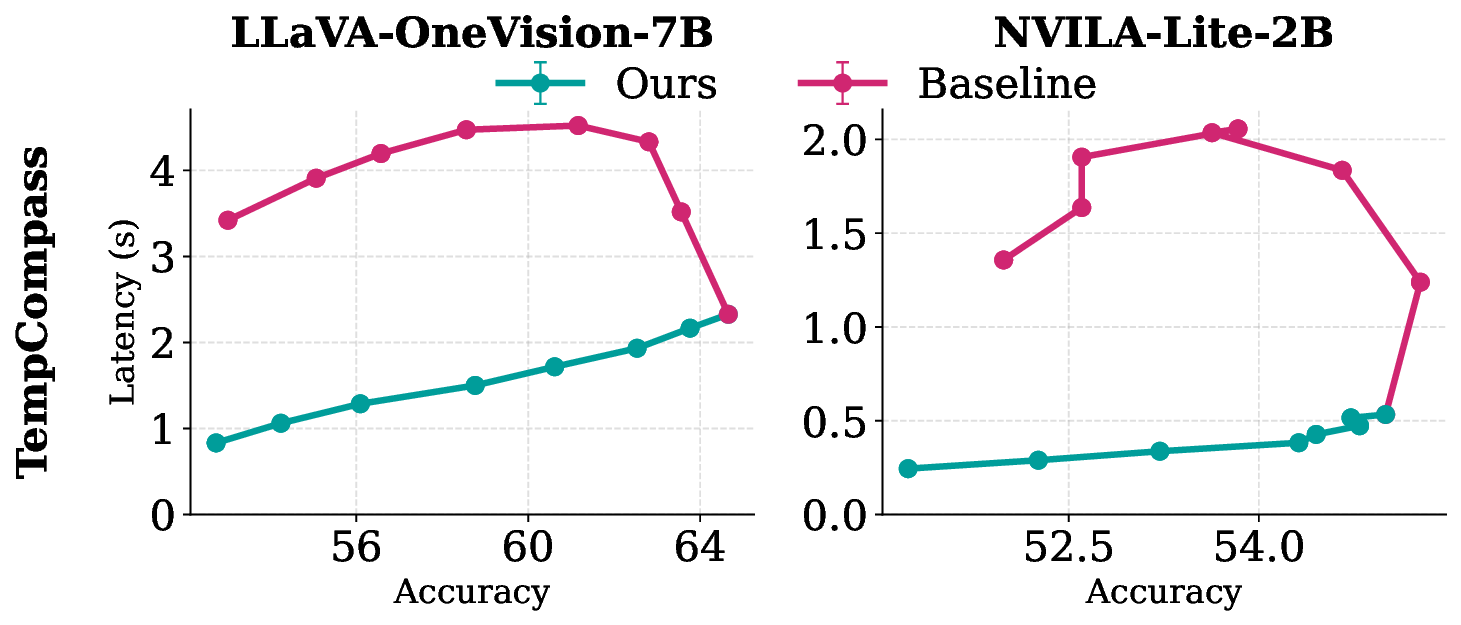
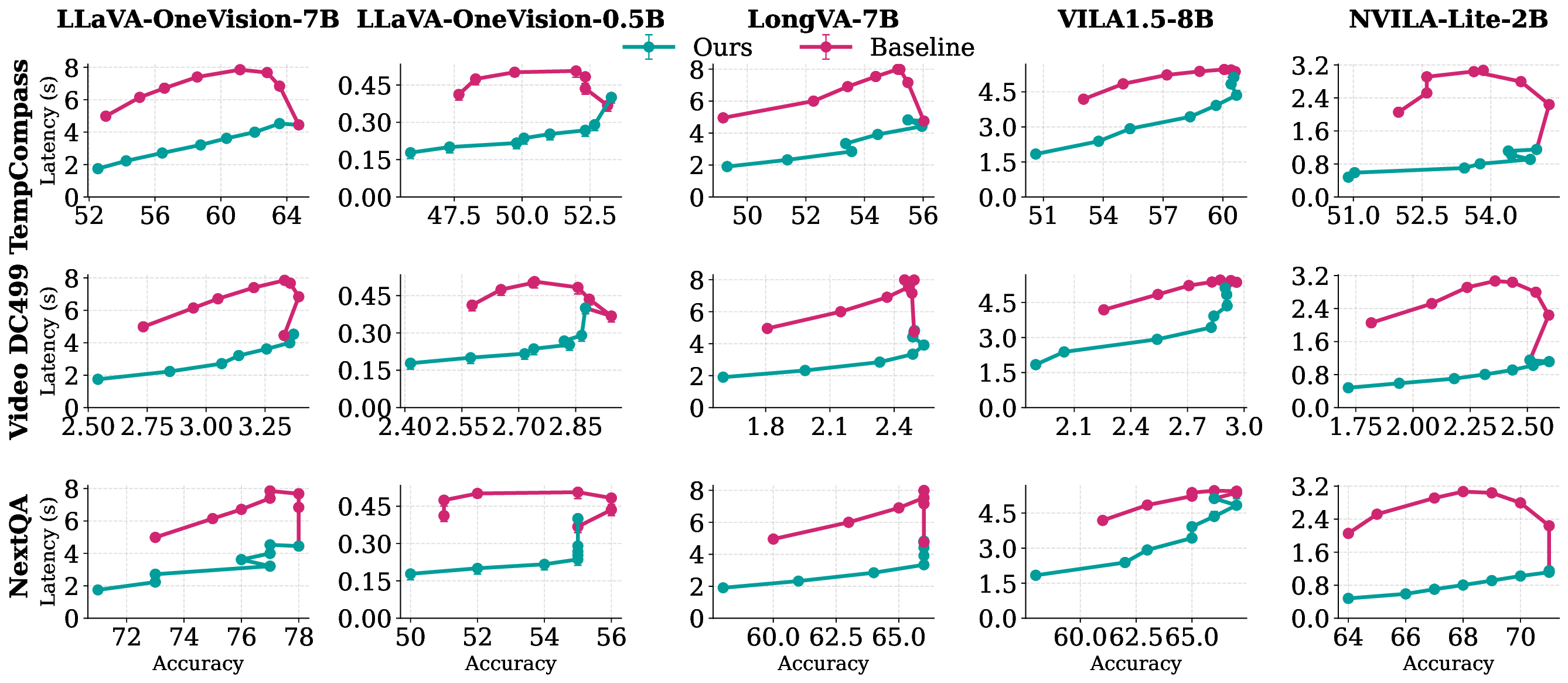
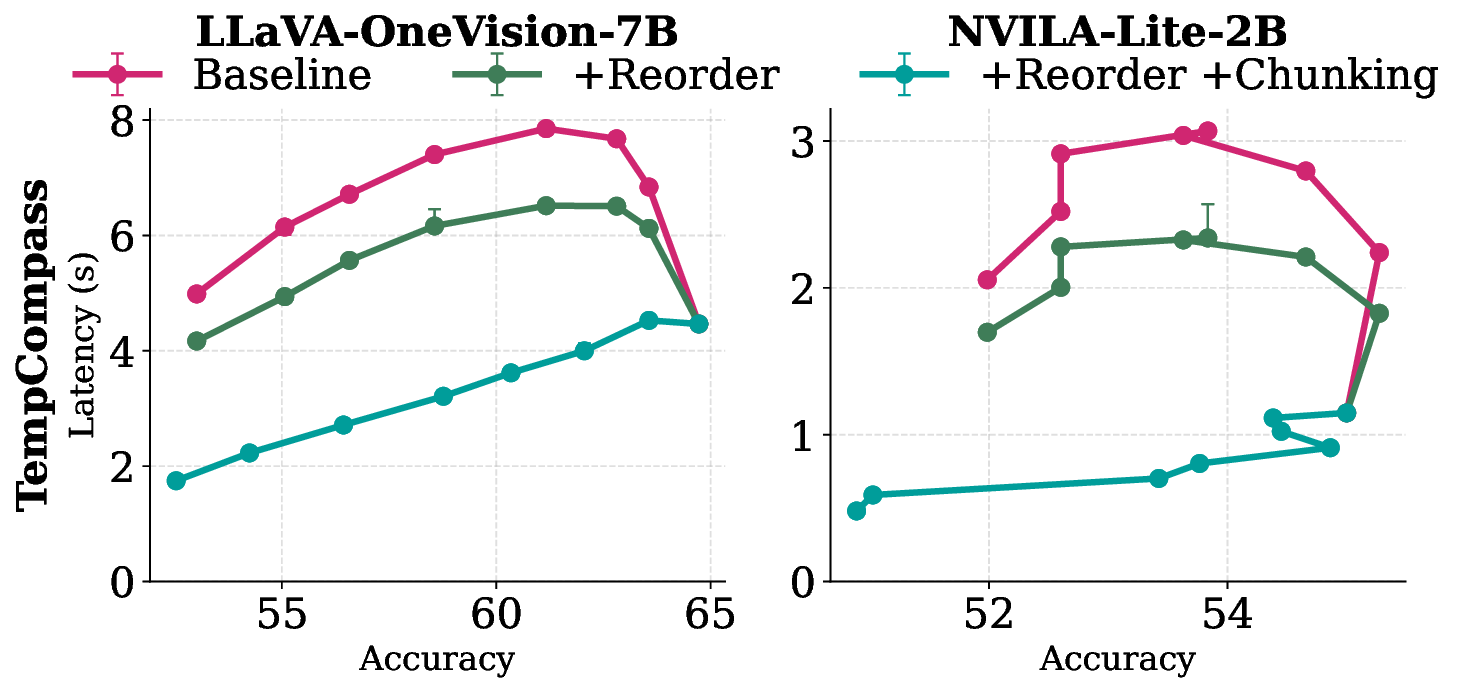
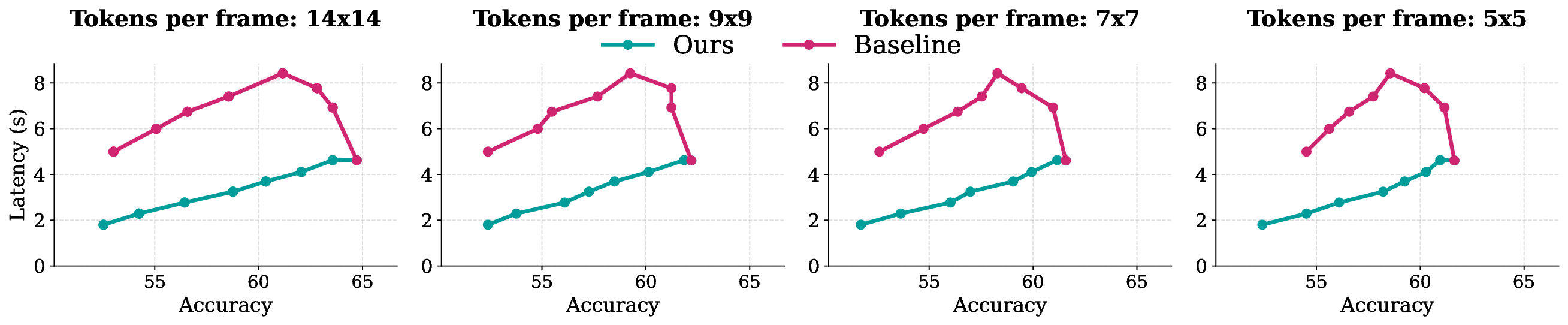
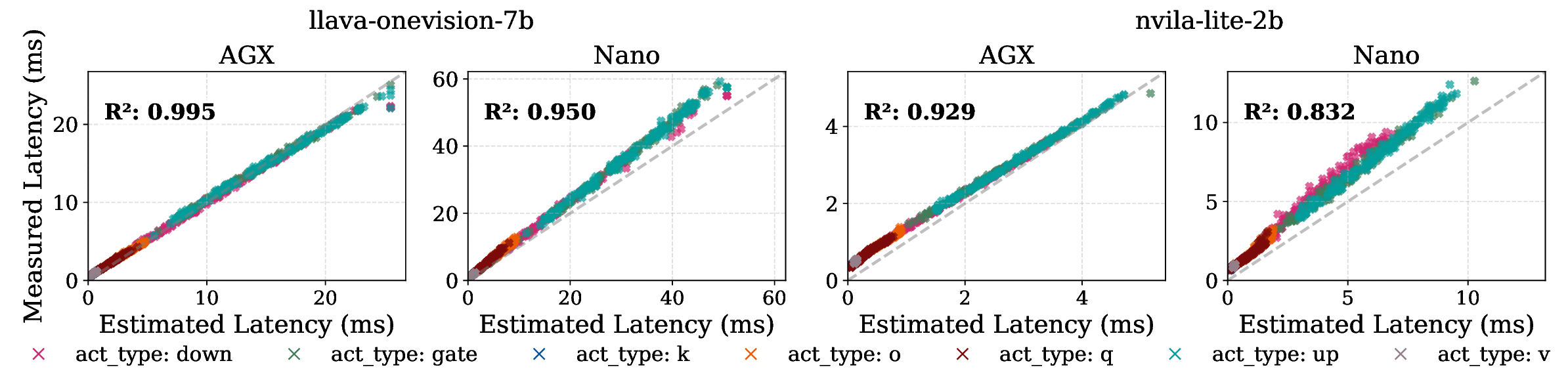
Edge deployment of large Vision-Language Models (VLMs) increasingly relies on flash-based weight offloading, where activation sparsification is used to reduce I/O overhead. However, conventional sparsification remains model-centric, selecting neurons solely by activation magnitude and neglecting how access patterns influence flash performance. We present Neuron Chunking, an I/O-efficient sparsification strategy that operates on chunks (i.e., groups of contiguous neurons in memory) and couples neuron importance with storage access cost. The method models I/O latency through a lightweight abstraction of access contiguity and selects chunks with high utility, defined as neuron importance normalized by estimated latency. By aligning sparsification decisions with the underlying storage behavior, Neuron Chunking improves I/O efficiency by up to 4.65x and 5.76x on Jetson Orin Nano and Jetson AGX Orin, respectively.
💡 Deep Analysis
📄 Full Content
VLM in a flash:
I/O-Efficient Sparsification of Vision-Language Model
via NEURON CHUNKING
Kichang Yang∗
Seoul National University
kichang96@snu.ac.kr
Seonjun Kim∗
Seoul National University
cyanide17@snu.ac.kr
Minjae Kim
Seoul National University
aingo03304@snu.ac.kr
Nairan Zhang
Meta
nairanzhang@meta.com
Chi Zhang
Amazon
zhanbchi@amazon.com
Youngki Lee†
Seoul National University
youngkilee@snu.ac.kr
Abstract
Edge deployment of large Vision-Language Models (VLMs) increasingly relies
on flash-based weight offloading, where activation sparsification is used to reduce
I/O overhead. However, conventional sparsification remains model-centric, select-
ing neurons solely by activation magnitude and neglecting how access patterns
influence flash performance. We present NEURON CHUNKING, an I/O-efficient
sparsification strategy that operates on chunks—groups of contiguous neurons in
memory—and couples neuron importance with storage access cost. The method
models I/O latency through a lightweight abstraction of access contiguity and
selects chunks with high utility, defined as neuron importance normalized by es-
timated latency. By aligning sparsification decisions with the underlying storage
behavior, Neuron Chunking improves I/O efficiency by up to 4.65× and 5.76× on
Jetson Orin Nano and Jetson AGX Orin, respectively.
1
Introduction
Recent vision–language models (VLMs) demonstrate strong multimodal reasoning and real-time
language interaction with visual scenes. Deploying these models on edge devices is becoming
essential for applications such as augmented reality (AR) and autonomous robotics that require
on-device inference for robustness to limited connectivity and privacy [5, 53]. These systems must
process video frames continuously without frame drops while maintaining interactive latency.
The scalability of on-device inference is fundamentally constrained by memory capacity. Edge
platforms provide far less memory than what modern VLMs require. Jetson Orin Nano, for example,
offers only 8 GB of memory, while LLaVA-OneVision-7B [18] requires 16 GB (fp16) for weights
alone. Recent systems [2, 3, 10, 36, 49] and inference engines [1, 9] address this mismatch through
weight offloading, which stores model parameters in external flash memory and loads them on
demand during inference. This method allows large models to execute on small devices but introduces
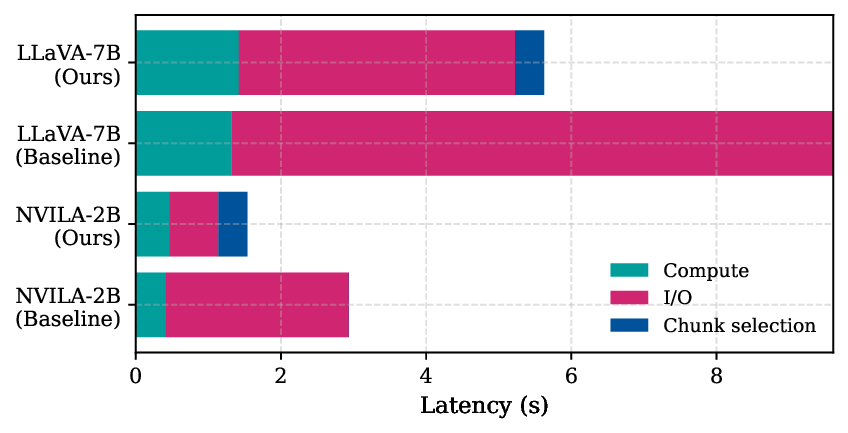
substantial I/O latency, which often dominates total inference time.
Activation sparsification has been widely explored to mitigate this latency [2, 44, 49]. The approach
loads only the weights corresponding to neurons with high importance (e.g., magnitude of activation
value), reducing total data transfer and improving input adaptivity. Despite its effectiveness, existing
∗Equal contribution
†Corresponding author
39th Conference on Neural Information Processing Systems (NeurIPS 2025).
arXiv:2511.18692v1 [cs.LG] 24 Nov 2025
6
4
5
1
5
4
7
7
Baseline
4
4
7
4
5
6
4
5
4
7
6
4
5
5
6
Latency
per chunk
Ours
1
5
4
6
…
…
Total
latency
Total
importance
16
11
23
26
Neuron importance
7
4
4
5
1
5
4
6
5
4
Utility-guided Chunk Selection (Section 3.2)
Chunk-based
Latency Model
(Section 3.1)
Pareto Improvement
through
Higher Contiguity
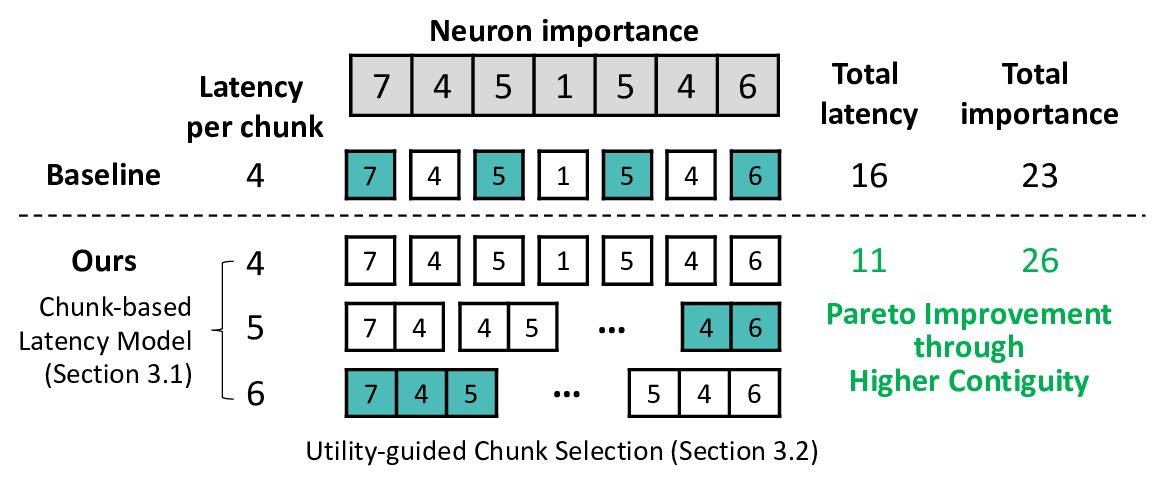
Figure 1: Illustration of conventional sparsification vs. our approach. Existing methods select
neurons solely based on activation importance, which often leads to scattered, irregular access patterns
with poor I/O efficiency. In contrast, our method explicitly accounts for actual I/O latency, favoring
contiguous chunks that achieve better importance–latency trade-offs.
sparsification remains model-centric. It selects channels solely based on activation importance while
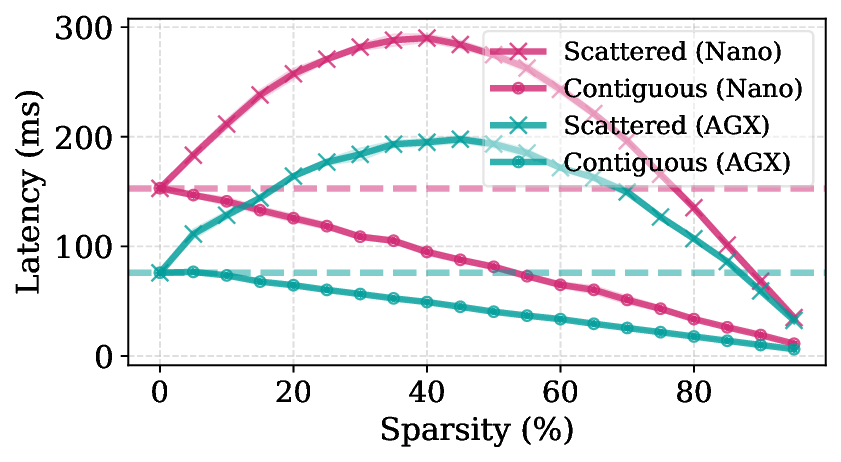
assuming that I/O latency scales linearly with data size. Flash storage does not follow this assumption;
its latency depends strongly on access contiguity, and scattered reads severely degrade throughput.
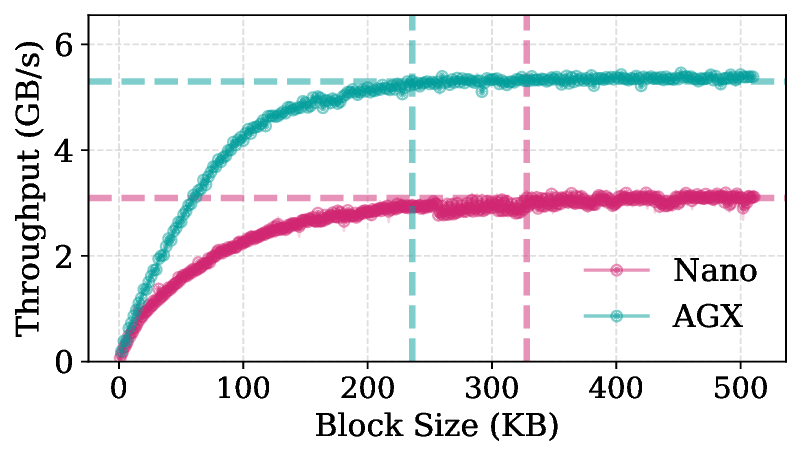
Earlier methods were less affected because they targeted highly sparse LLMs or GPU memory
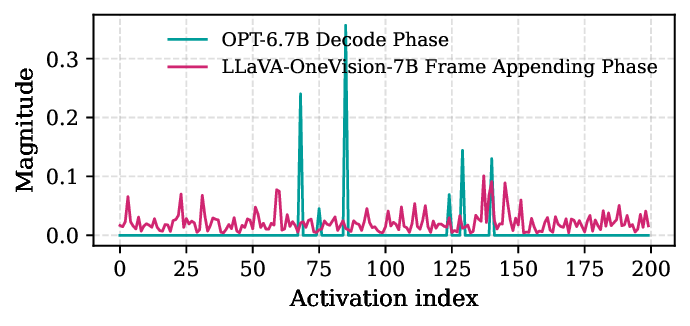
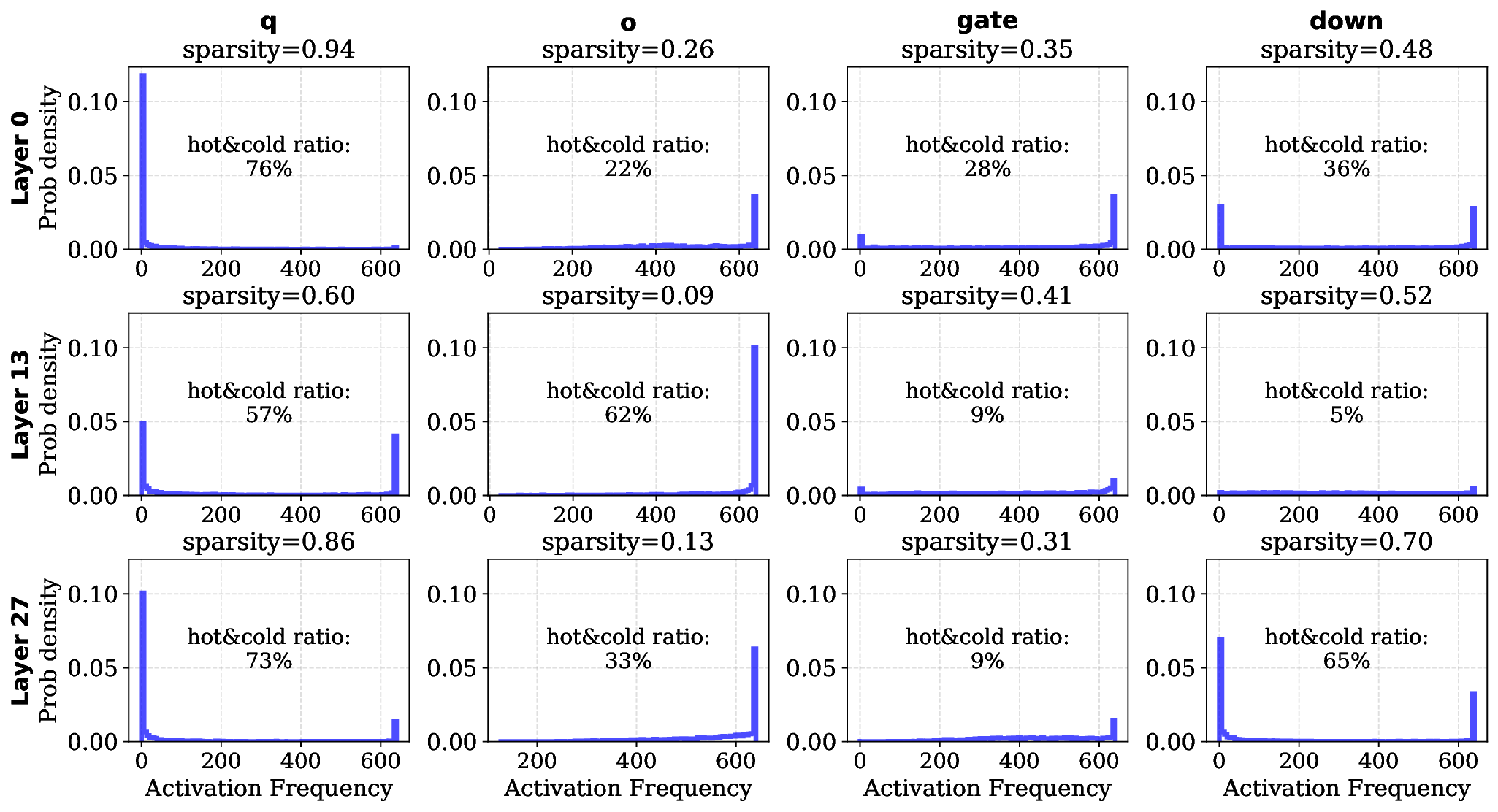
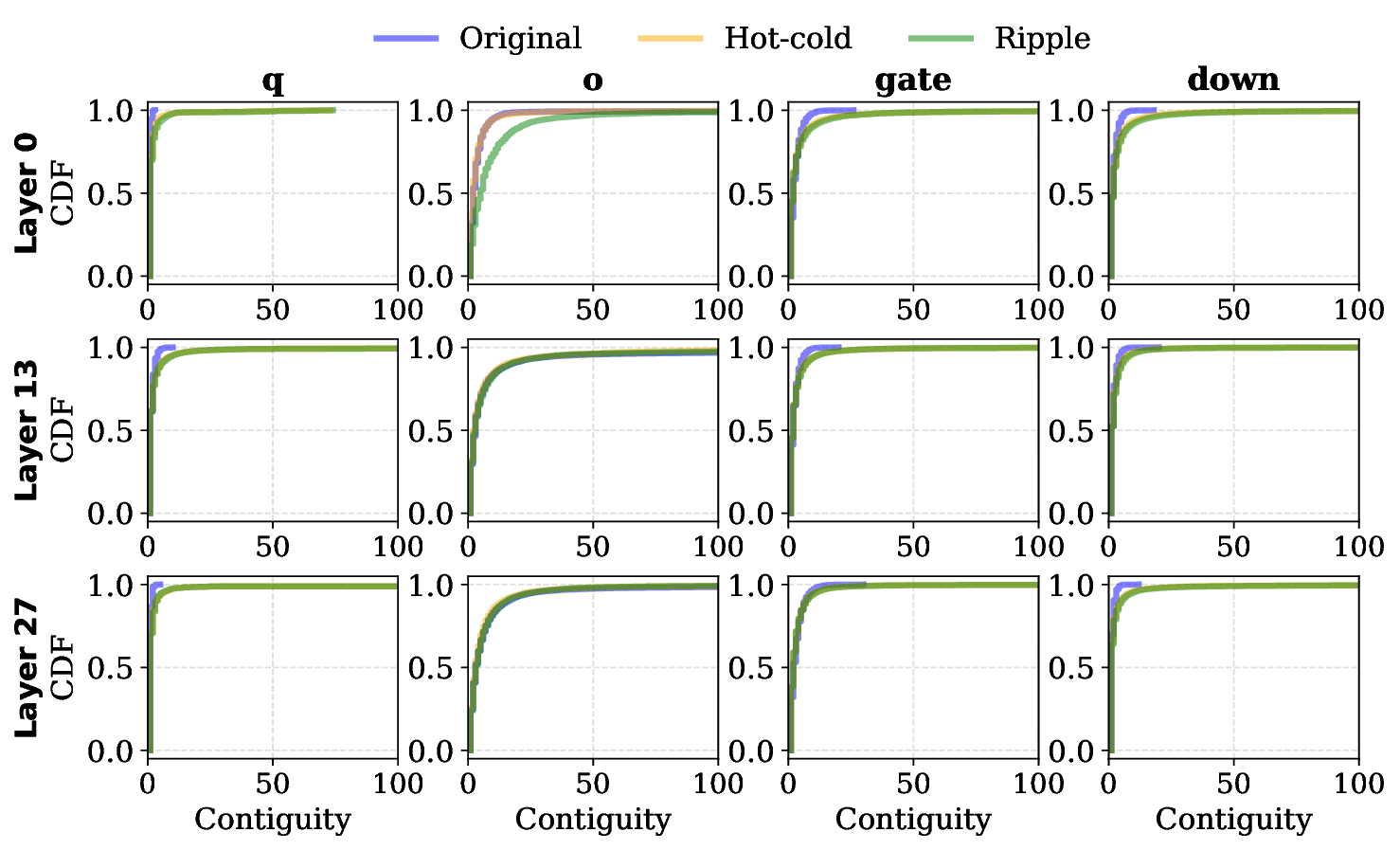
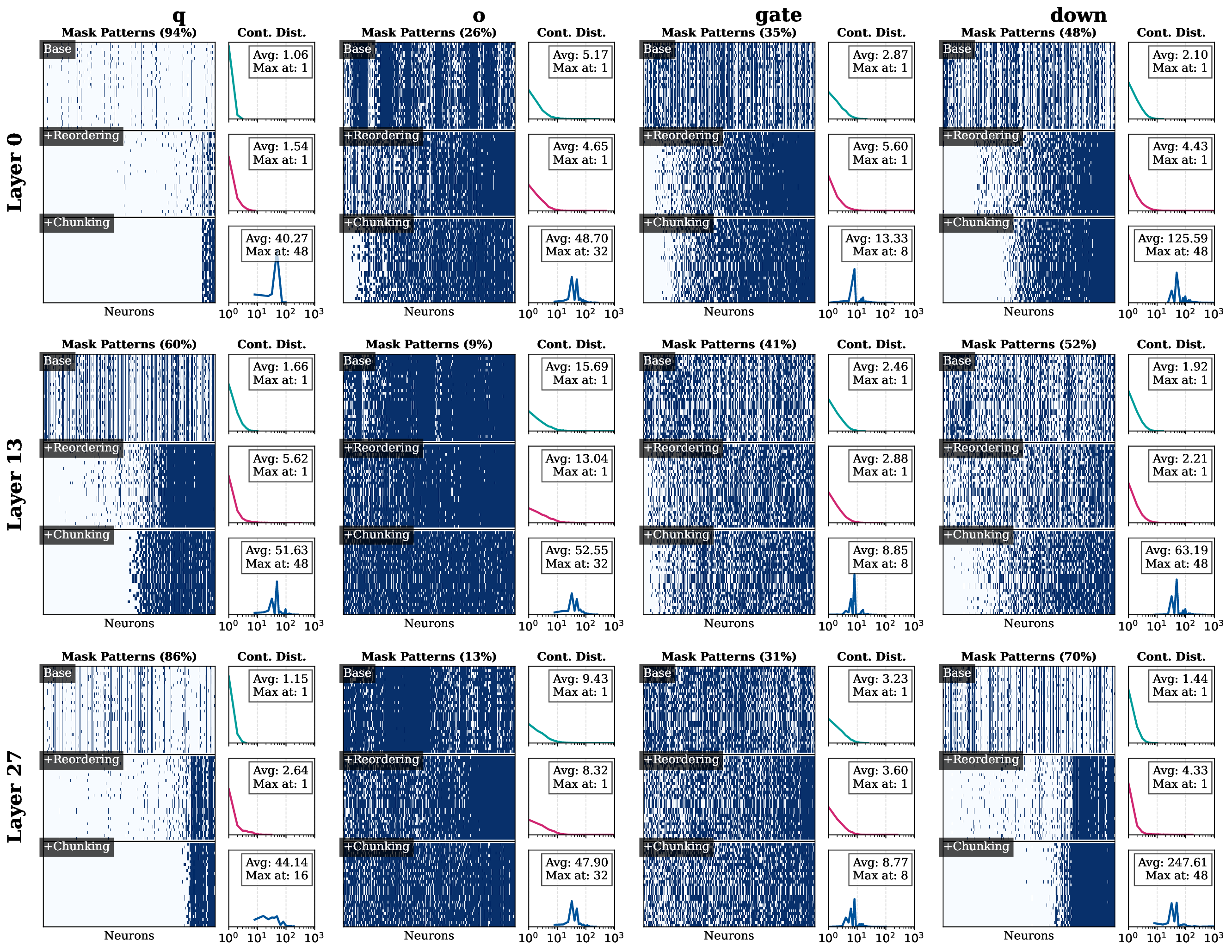
transfers, where locality plays a smaller role. Modern VLMs exhibit smoother activation distributions
and lower sparsity (Figure 2), leading to fragmented reads and high I/O overhead (Figure 4b).
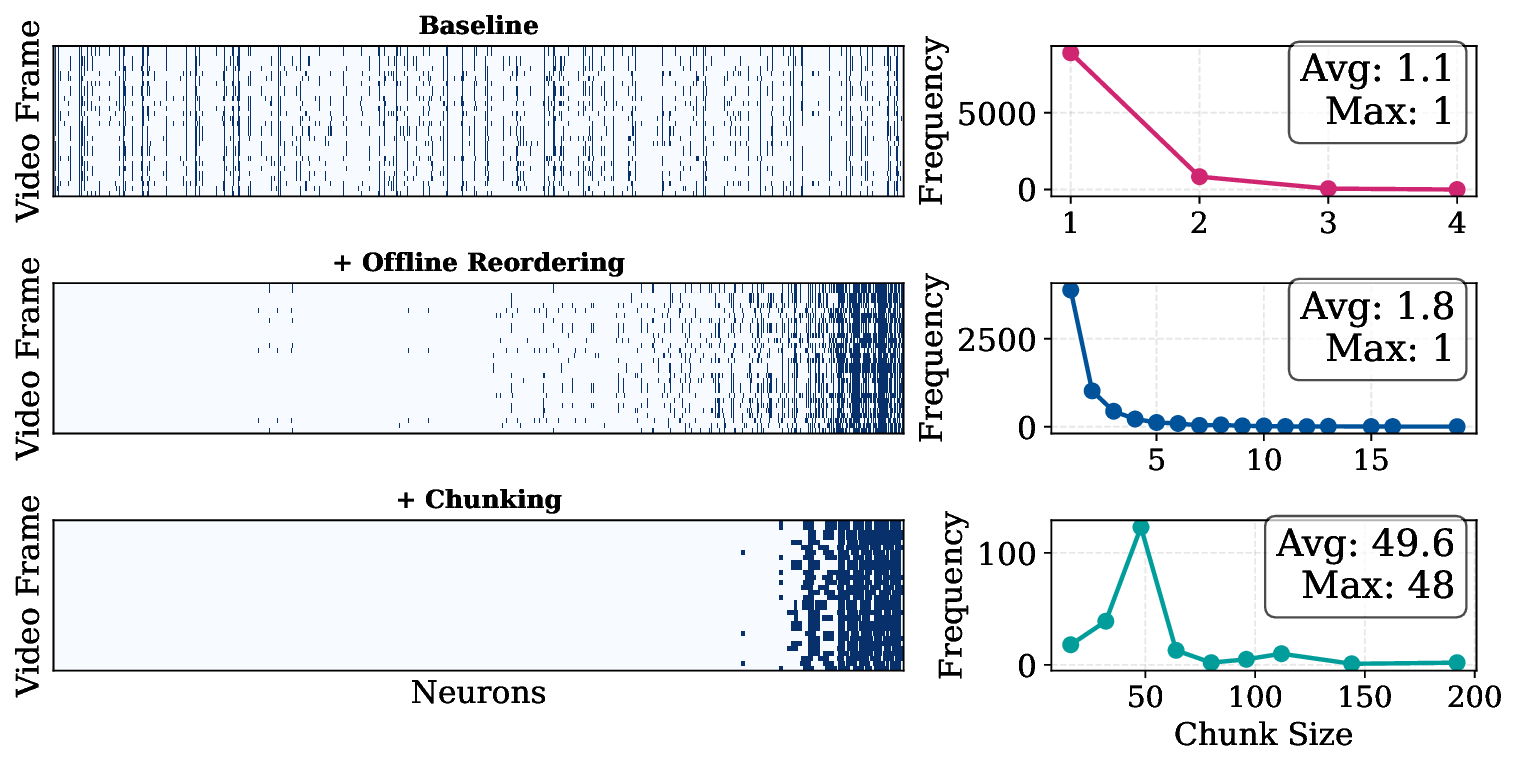
We propose NEURON CHUNKING, a sparsification framework that improves the I/O efficiency of
flash-offloaded inference by coupling activation sparsity with storage access behavior. The key idea
is to jointly optimize neuron importance and flash I/O latency by selecting contiguous channel groups
that provide a better trade-off between accuracy and latency. Contiguous reads provide higher flash
throughput, allowing moderately important neighboring channels to be loaded more efficiently than
distant but highly important ones (Figure 1). This design forms compact chunks that enhance access
locality, leading to significant performance gains during VLM inference.
Efficient realization of this strategy requires capturing hardware I/O behavior in a form that the
runtime can readily exploit. NEURON CHUNKING ac