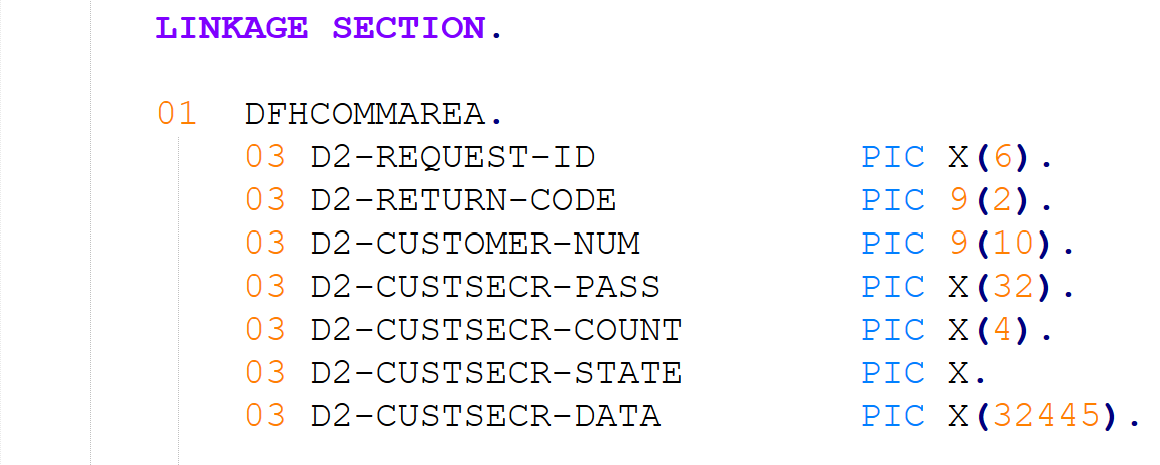
Systems incorporating large language models (LLMs) as a component are known to be sensitive (i.e., non-robust) to minor input variations that do not change the meaning of the input; such sensitivity may reduce the system's usefulness. Here, we present a framework to evaluate robustness of systems using COBOL code as input; our application is translation between COBOL and Java programming languages, but the approach extends to other tasks such as code generation or explanation. Targeting robustness of systems with COBOL as input is essential yet challenging. Many business-critical applications are written in COBOL, yet these are typically proprietary legacy applications and their code is unavailable to LLMs for training. We develop a library of COBOL paragraph and full-program perturbation methods, and create variant-expanded versions of a benchmark dataset of examples for a specific task. The robustness of the LLM-based system is evaluated by measuring changes in values of individual and aggregate metrics calculated on the system's outputs. Finally, we present a series of dynamic table and chart visualization dashboards that assist in debugging the system's outputs, and monitoring and understanding root causes of the system's sensitivity to input variation. These tools can be further used to improve the system by, for instance, indicating variations that should be handled by pre-processing steps.
COBOL (Common Business-Oriented Language) continues to underpin a substantial portion of mission-critical software systems, particularly in domains such as finance, insurance, and government. These systems, often developed and maintained over several decades, embody vast amounts of complex yet highly reliable code. As organizations seek to modernize their software infrastructure, the challenge lies not only in transforming the system implementations but also in evolving the development environments that support ongoing maintenance and enhancement. In this context, generative systems-such as those that translate COBOL to modern languages, generate COBOL code from specifications, or provide automated explanations of COBOL programs-offer promising avenues for modernization. However, the robustness of these systems remains a critical concern, as inaccuracies or inconsistencies can compromise system integrity and developer trust. This work focuses on evaluating the robustness of generative systems that work with COBOL code, aiming to assess their reliability, identify potential failure modes, and inform the development of more resilient tools for legacy system modernization.
Evaluation of such systems can be automated or made easier by using a set of evaluation metrics-typically producing numeric or boolean values-that capture a range of aspects of interest of the system outputs. For instance, a code-generating system may be assessed by whether the output code is parsable (a boolean measure), the number of variables defined (an integer measure), or by a LLM-as-a-Judge (LaaJ) assessment (typically a real-valued measure) of some aspect of the code, such as its quality. A system generating a natural-language summary of code may be evaluated by LaaJ scores of the coherence of the summary, or by superficial metrics such as the word count.
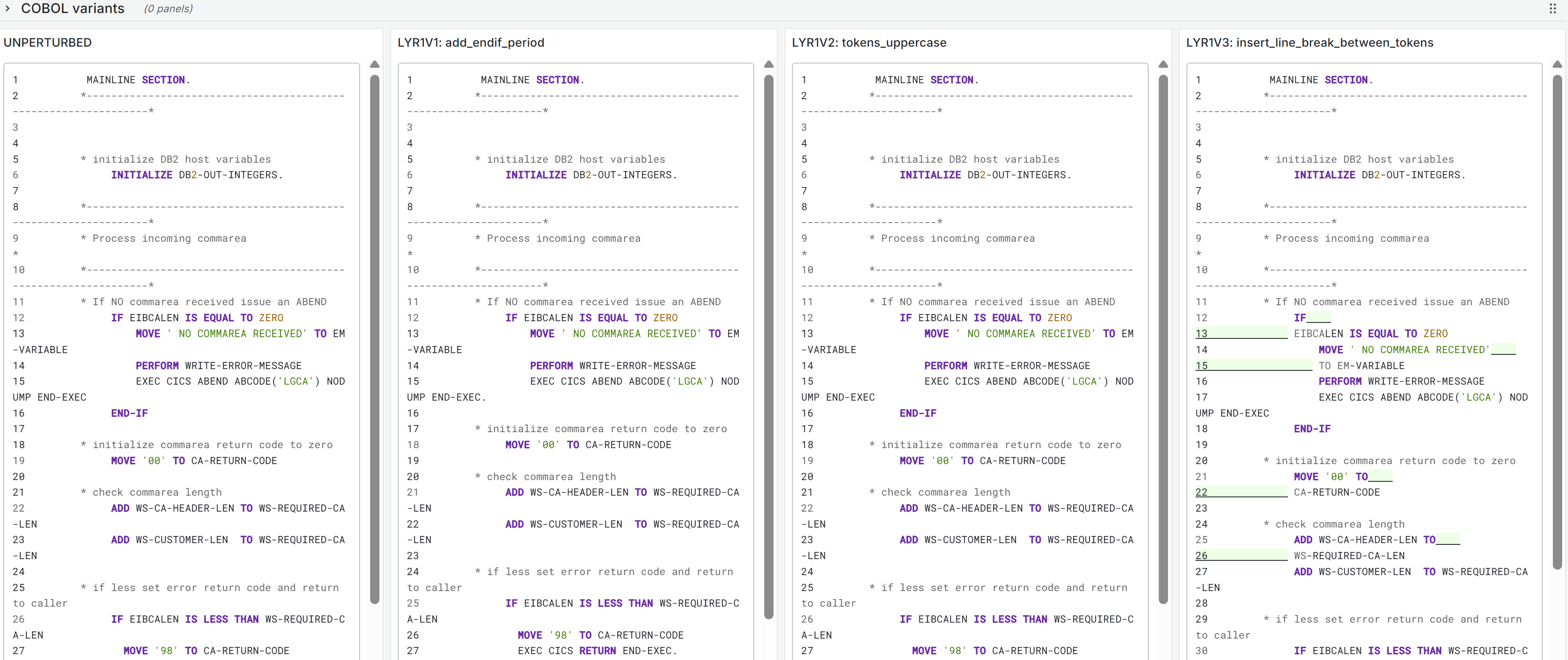
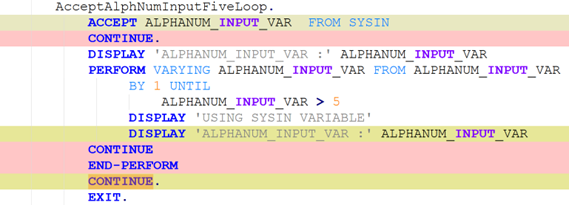
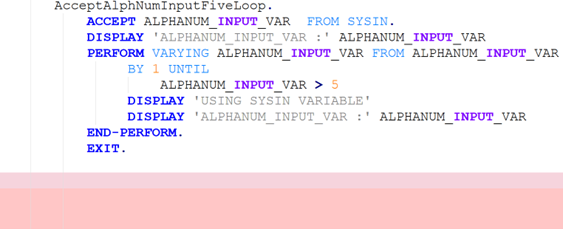
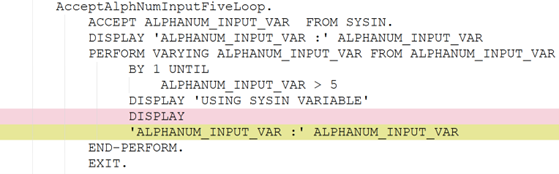
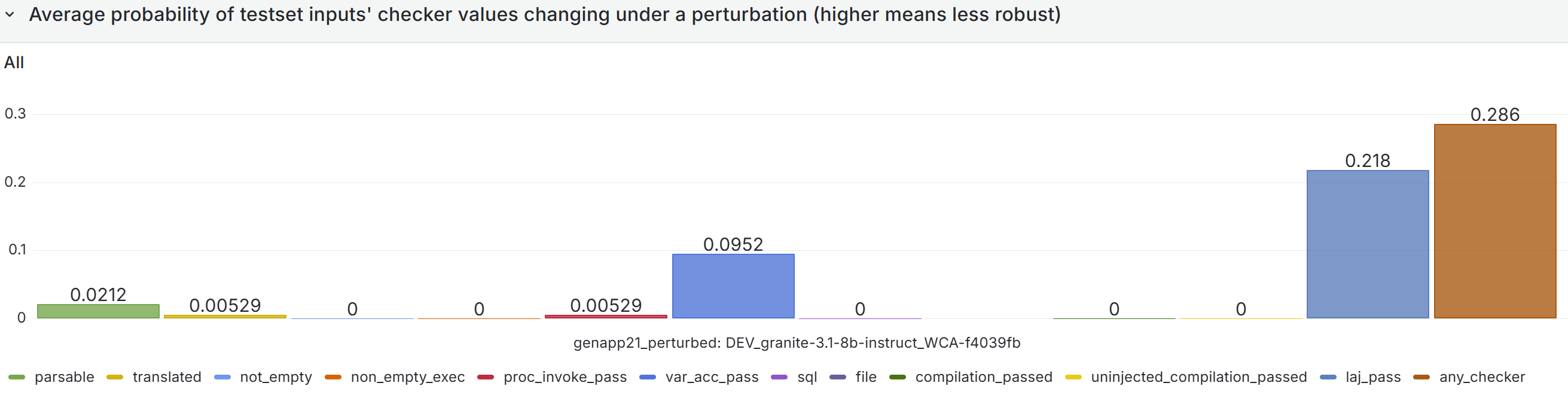
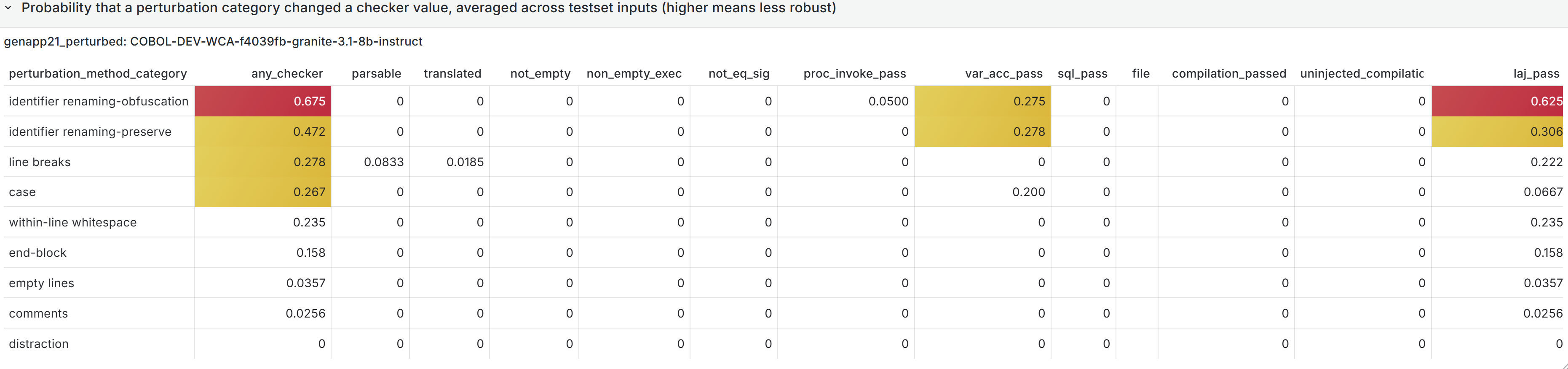
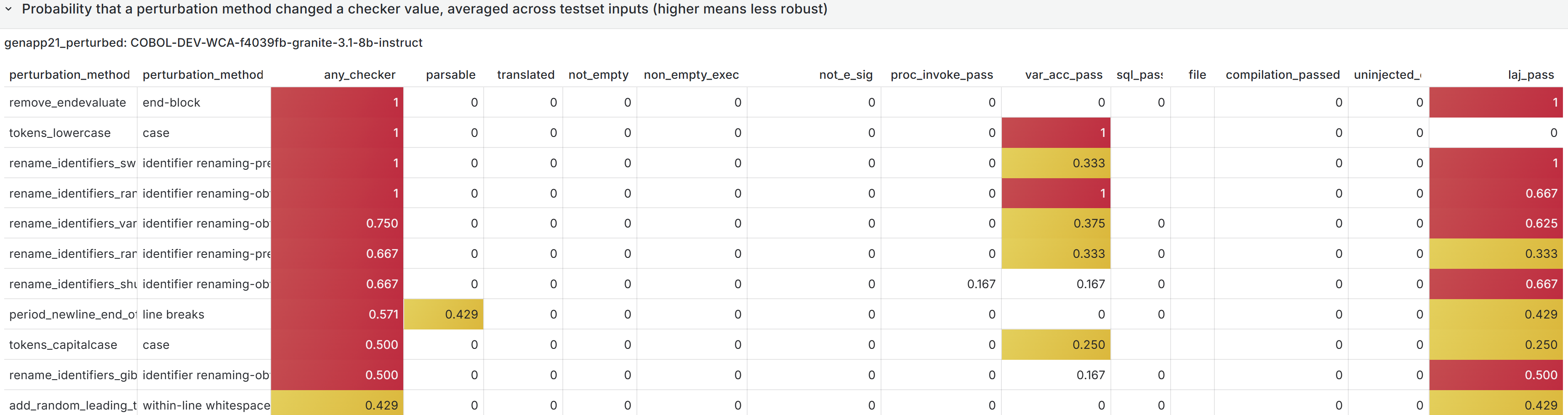
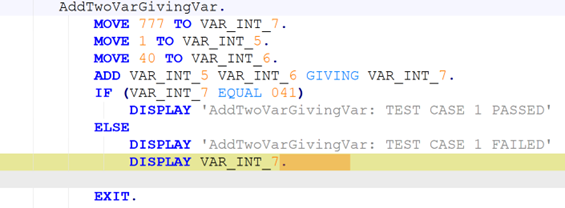
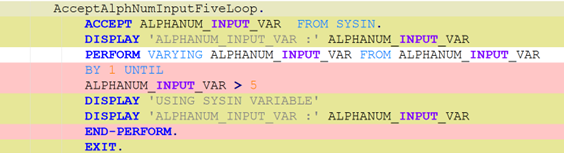
In many such generative systems, it is desirable that the generated output be robust to (typically minor) variations (perturbations) in the code inputs. Assume we have a corpus of example code inputs, for instance from a benchmark dataset. Robustness means that, across inputs in the corpus, the system outputs of perturbations of an input are very similar to the outputs of the original, unperturbed inputs. In the ideal case, the system outputs themselves will be identical before and after perturbations, but this tends to be too rigid an expectation in reality. More likely, we will want to see that the values of the evaluation metrics measured, and not the outputs themselves, do not change after the perturbation, as our criterion for robustness; exact-output robustness as a special case can be measured by creating a trivial binary evaluation metric comparing the outputs themselves. Manual inspection of the outputs may be useful for spot-checks, but using measurable metrics is better for evaluating the system. By using enough metrics of interest in assessing the similarity of outputs under perturbation, we hope to provide sufficient experimental guarantees on the robustness of our system in the field.
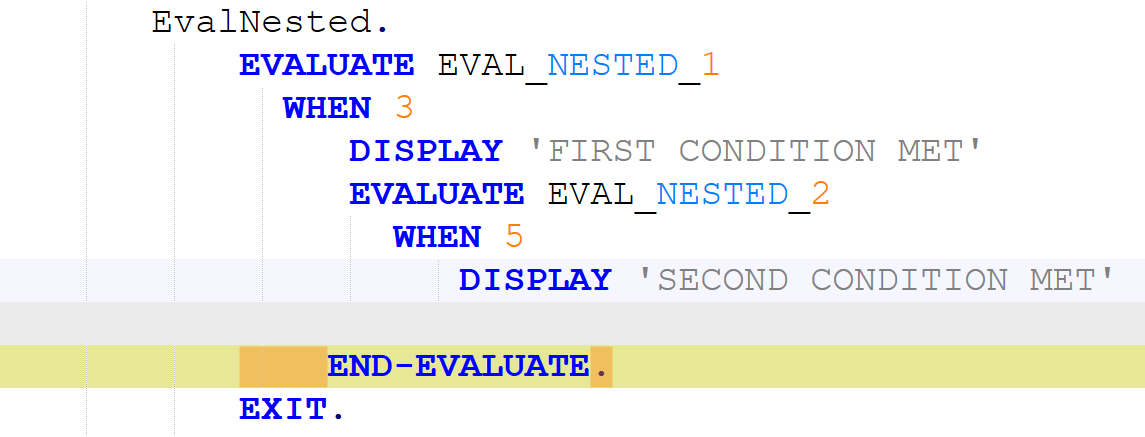
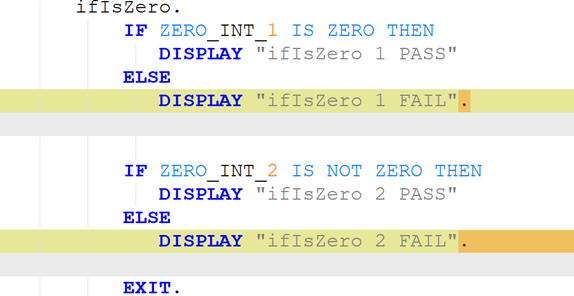
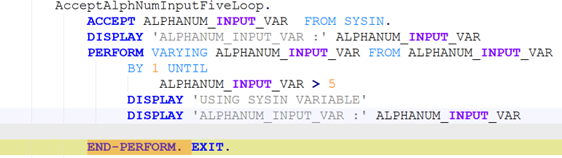
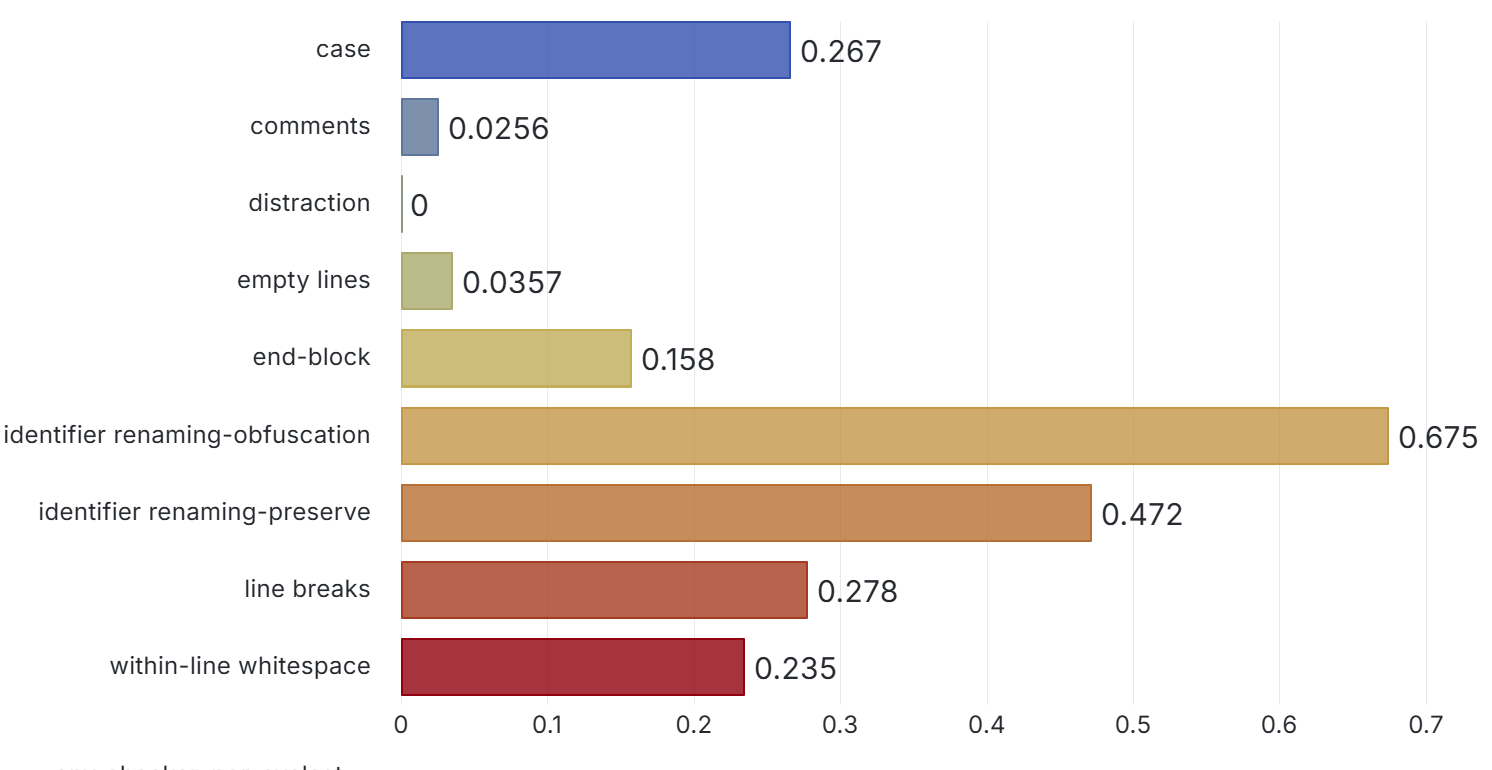
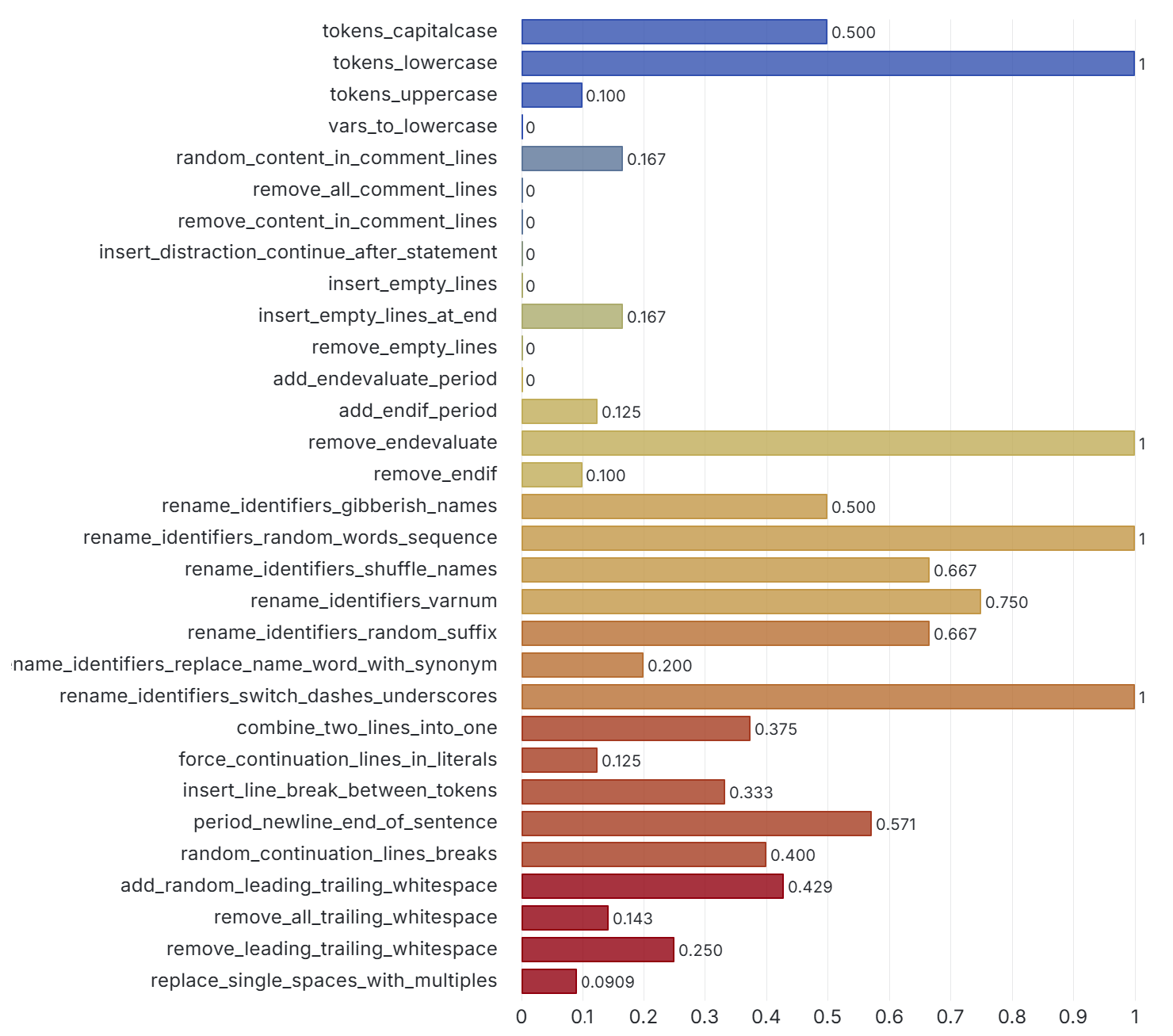
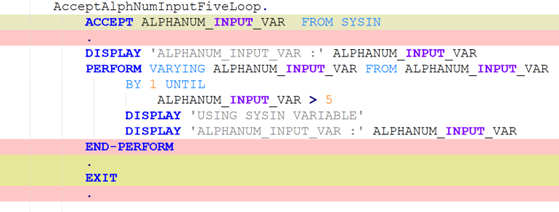
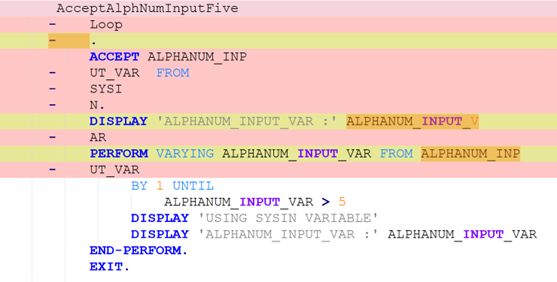
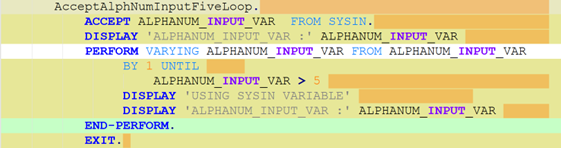
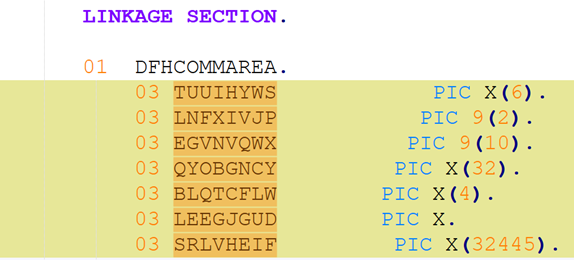
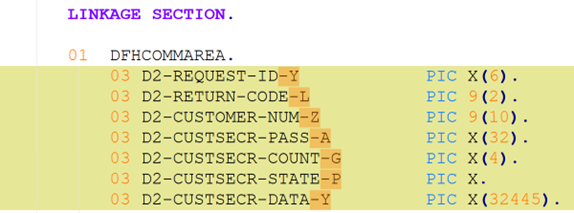
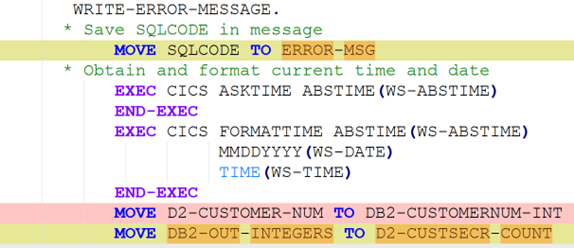
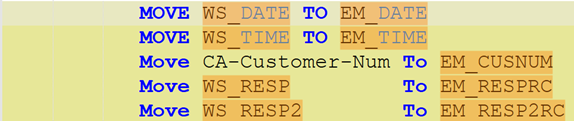
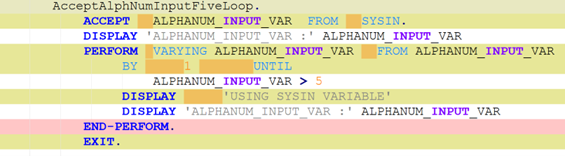
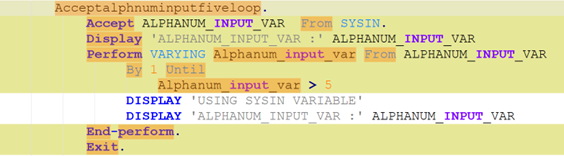
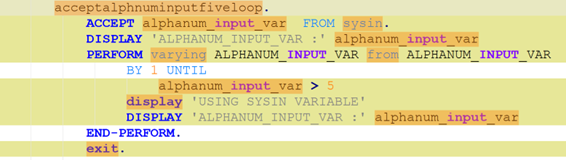
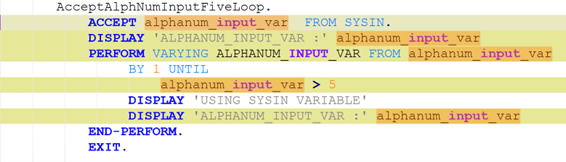
To be meaningful, the perturbations should be meaning preserving, a determination which typically requires domain knowledge. For instance, in COBOL there is only a two-level distinction in beginning-of-line indentation between Area A (7-10 leading spaces) and B (11 or more leading spaces), such that a line’s indentation can be changed as long as it obeys the area’s indentation constraint. In Python, however, there are multiple levels, as each nesting of a function or control flow statements (if, while, for, etc.) requires its own indent. Likewise, in COBOL, but not Python, non-literal token case can be changed.
Such stylistic or interchangeable grammatical code variations may arise naturally due to varying code practices of individual programmers, or differing company standards. If a generative translation system is observed to give differing translations on the same input code when the amount of such whitespace changes, there is concern that the procedure is ‘brittle’ and not robust to this variation, and likely others. Such non-robustness means that the system performance in the field by users may differ from the evaluated performance under development, particularly if the outputs are used downstream.
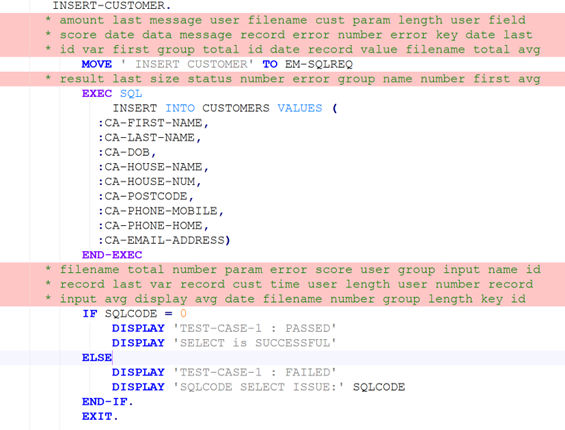
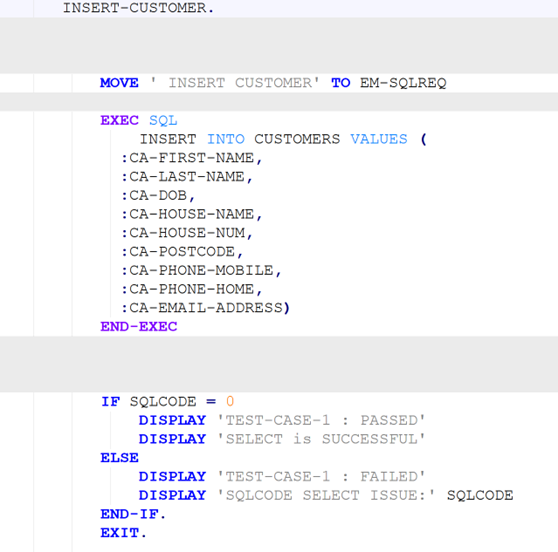
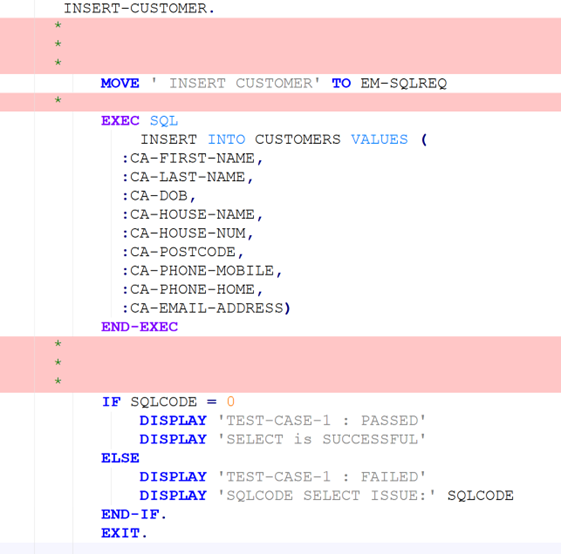
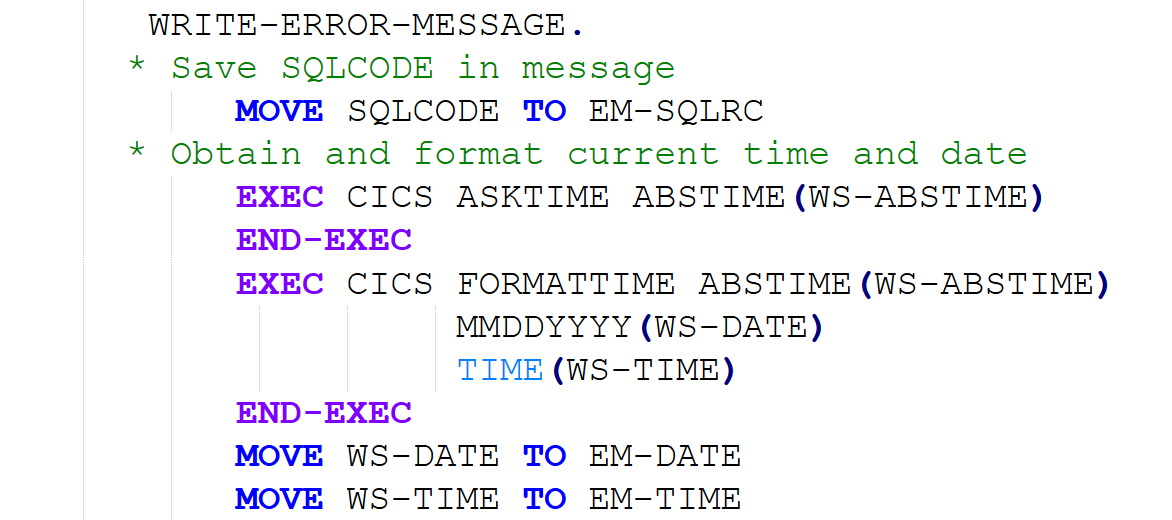
The generative task we evaluate here is translation of COBOL to Java code. We note that our approach and the set of perturbation methods implemented are general enough to be used to evaluate robustness of other tasks such as COBOL code generation or explanation, though we do not address these. However, robustness evaluation of a task could certainly benefit from inclusion of perturbation methods tailored for that task (e.g., more specific perturbation of comments in code-explanation tasks).
The organization of our paper is as follows: Section 2 discusses related work. Section 3 discusses the types of perturbations we have implemented, explained in detail in the Appendix. Section 4 di
This content is AI-processed based on open access ArXiv data.