Title: A Multimodal Conversational Agent for Tabular Data Analysis
ArXiv ID: 2511.18405
Date: 2025-11-23
Authors: Mohammad Nour Al Awad, Sergey Ivanov, Olga Tikhonova, Ivan Khodnenko
📝 Abstract
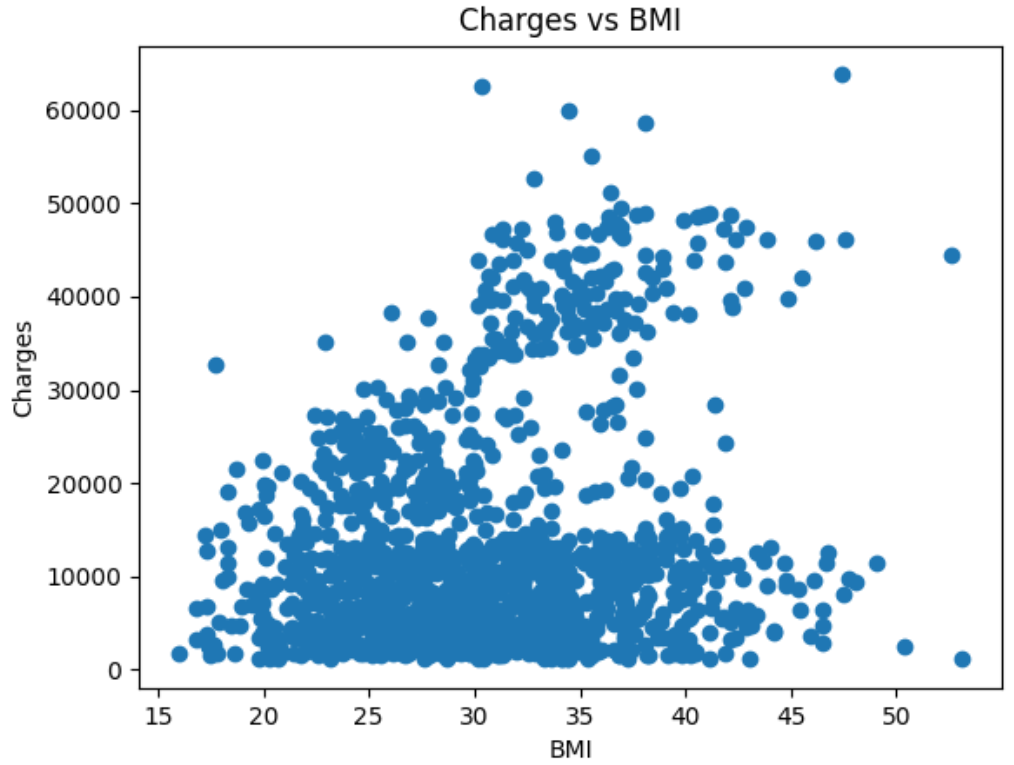
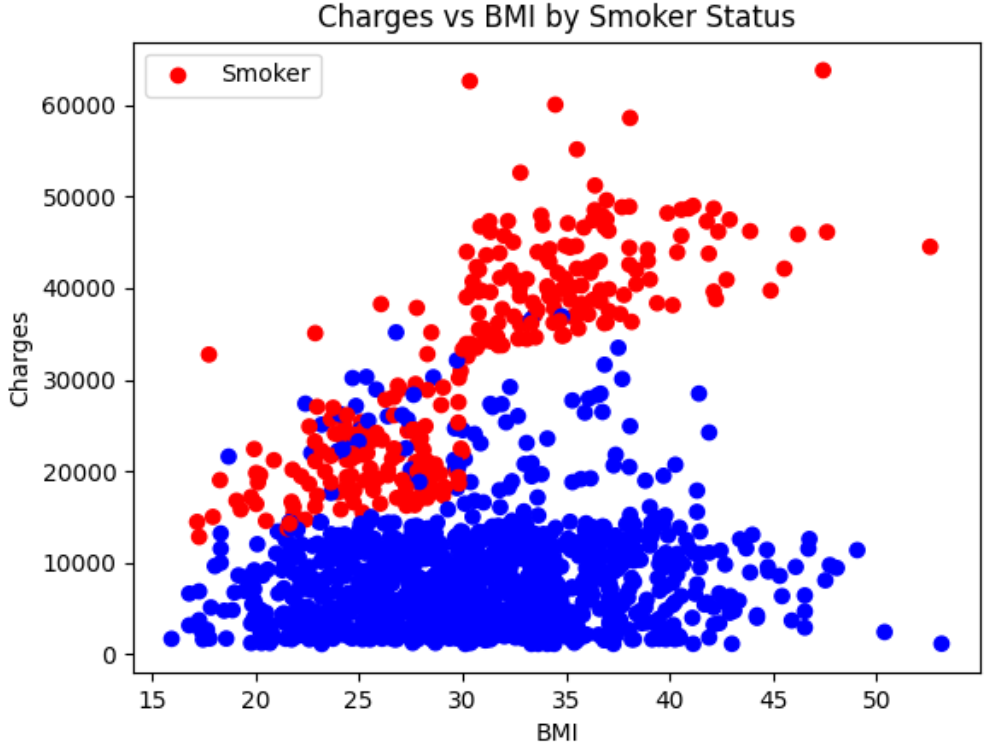
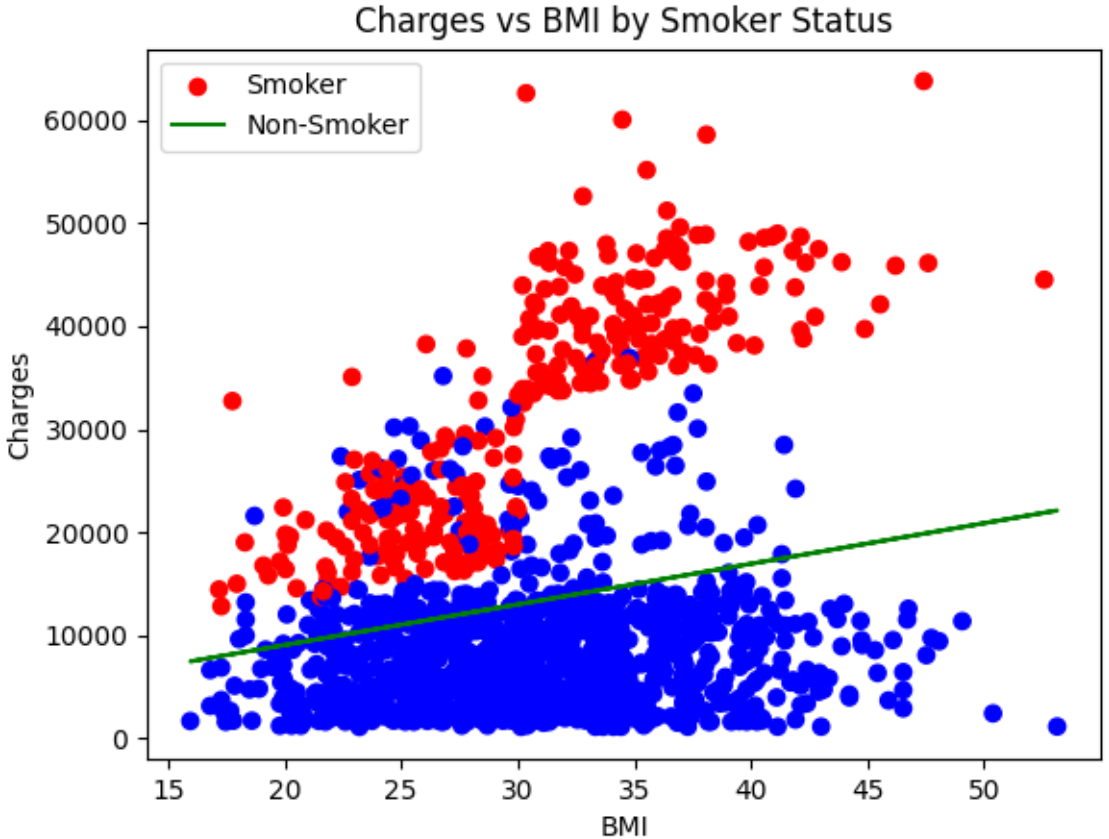
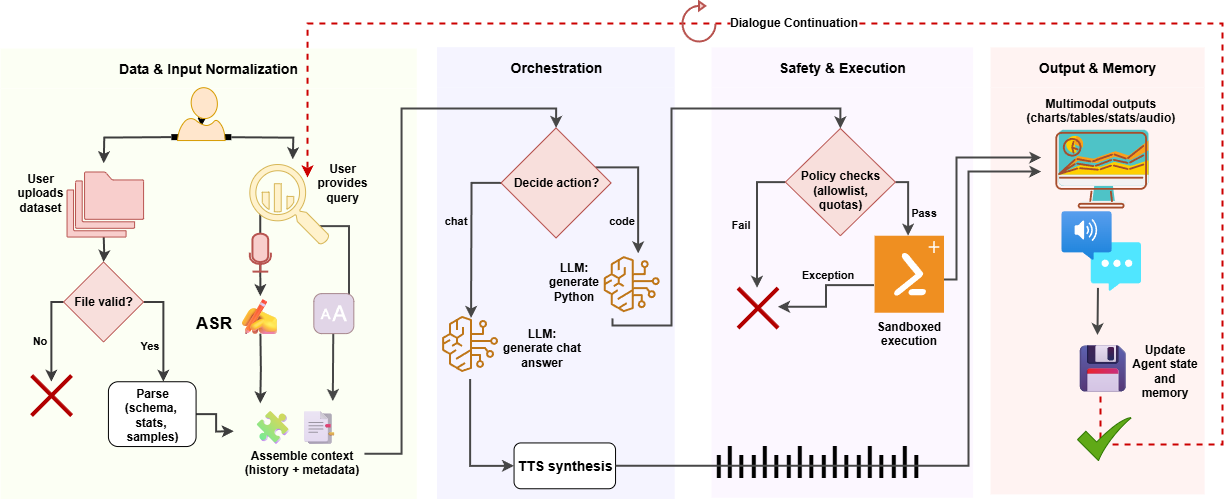
Large language models (LLMs) can reshape information processing by handling data analysis, visualization, and interpretation in an interactive, context-aware dialogue with users, including voice interaction, while maintaining high performance. In this article, we present Talk2Data, a multimodal LLM-driven conversational agent for intuitive data exploration. The system lets users query datasets with voice or text instructions and receive answers as plots, tables, statistics, or spoken explanations. Built on LLMs, the suggested design combines OpenAI Whisper automatic speech recognition (ASR) system, Qwen-coder code generation LLM/model, custom sandboxed execution tools, and Coqui library for text-to-speech (TTS) within an agentic orchestration loop. Unlike text-only analysis tools, it adapts responses across modalities and supports multi-turn dialogues grounded in dataset context. In an evaluation of 48 tasks on three datasets, our prototype achieved 95.8% accuracy with model-only generation time under 1.7 seconds (excluding ASR and execution time). A comparison across five LLM sizes (1.5B-32B) revealed accuracy-latency-cost trade-offs, with a 7B model providing the best balance for interactive use. By routing between conversation with user and code execution, constrained to a transparent sandbox, with simultaneously grounding prompts in schema-level context, the Talk2Data agent reliably retrieves actionable insights from tables while making computations verifiable. In the article, except for the Talk2Data agent itself, we discuss implications for human-data interaction, trust in LLM-driven analytics, and future extensions toward large-scale multimodal assistants.