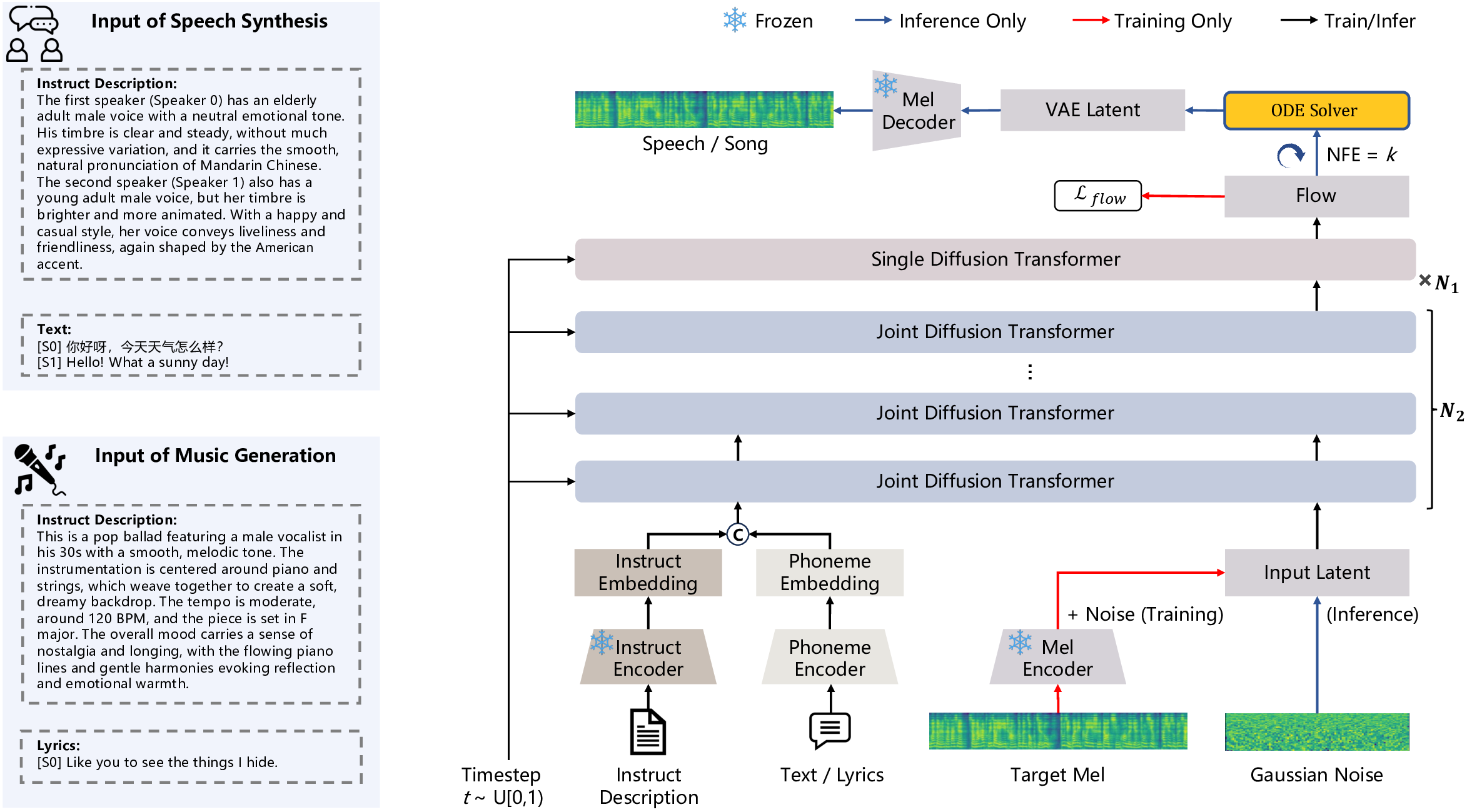
Text-to-speech (TTS) and text-to-music (TTM) models face significant limitations in instruction-based control. TTS systems usually depend on reference audio for timbre, offer only limited text-level attribute control, and rarely support dialogue generation. TTM systems are constrained by input conditioning requirements that depend on expert knowledge annotations. The high heterogeneity of these input control conditions makes them difficult to joint modeling with speech synthesis. Despite sharing common acoustic modeling characteristics, these two tasks have long been developed independently, leaving open the challenge of achieving unified modeling through natural language instructions. We introduce InstructAudio, a unified framework that enables instruction-based (natural language descriptions) control of acoustic attributes including timbre (gender, age), paralinguistic (emotion, style, accent), and musical (genre, instrument, rhythm, atmosphere). It supports expressive speech, music, and dialogue generation in English and Chinese. The model employs joint and single diffusion transformer layers with a standardized instruction-phoneme input format, trained on 50K hours of speech and 20K hours of music data, enabling multi-task learning and cross-modal alignment. Fig. 1 visualizes performance comparisons with mainstream TTS and TTM models, demonstrating that InstructAudio achieves optimal results on most metrics. To our best knowledge, InstructAudio represents the first instruction-controlled framework unifying speech and music generation. Audio samples are available at: https://qiangchunyu.github.io/InstructAudio/
Text-based controllable generation of speech and music is an important research topic in the field of audio generation. Recent developments in TTS [3][4][5][6][7][8][9][10][11][12][13] have achieved impressive results through zero-shot voice cloning and controllable generation. TTM [14][15][16][17][18] has advanced with models such as MusicGen [14] and ACE-Step [15], alongside commercial systems like Suno [16] and Udio [17]. Despite these advances, instruction-controlled speech and music generation remains a challenging problem in audio processing.
Existing TTS models excel at either zero-shot voice cloning [6,8,9,19] or style control [20,21], but lack text-based control over multiple acoustic attributes through natural language descriptions. For instance, while CosyVoice [8,19] and ControlSpeech [20] support † Corresponding Author.
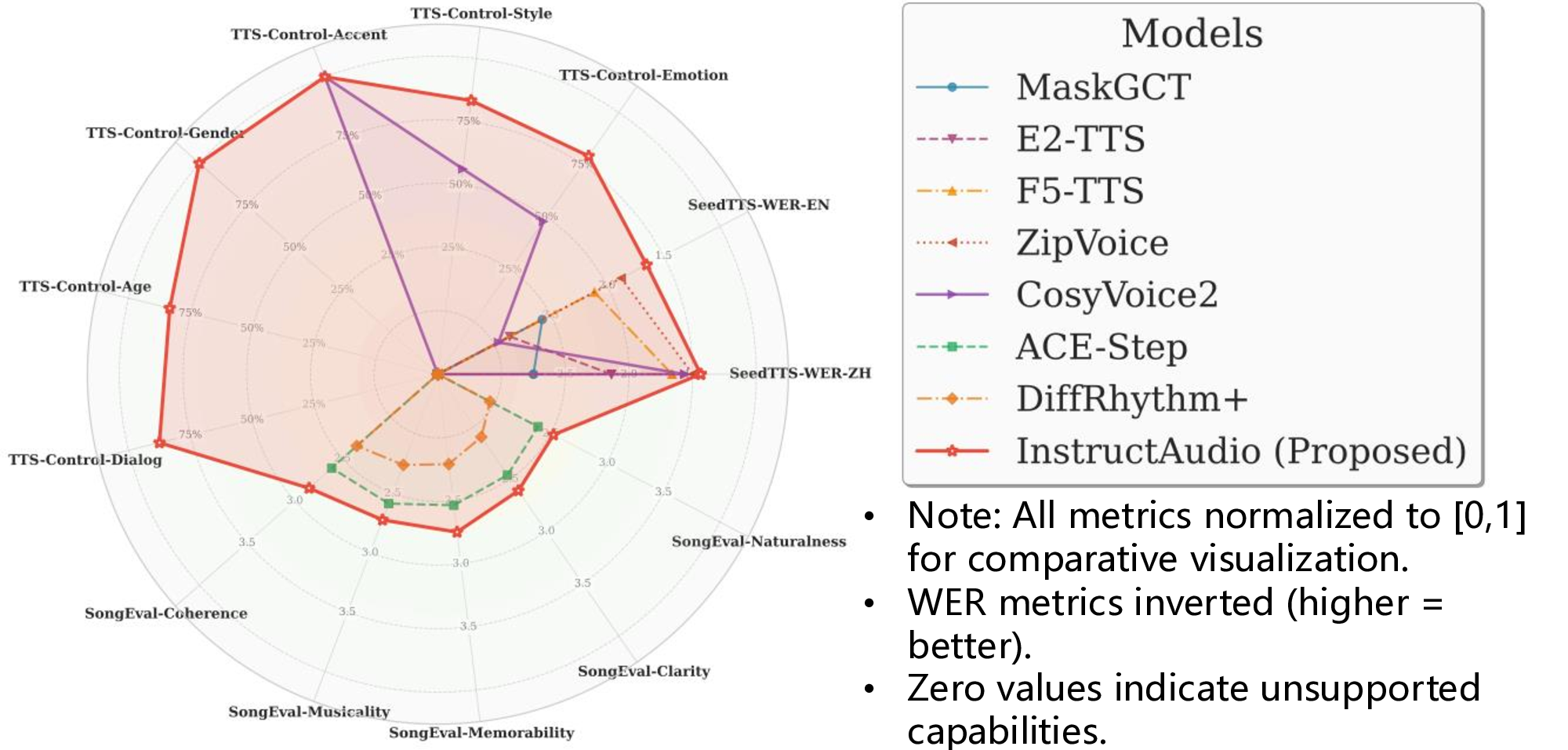
• Note: All metrics normalized to [0, 1] for comparative visualization. • WER metrics inverted (higher = better). • Zero values indicate unsupported capabilities.
Fig. 1: Comparing model capabilities across TTS and TTM tasks. The chart shows normalized performance on 13 metrics: SeedTTS-WER [1], TTS-Control, and SongEval [2]. InstructAudio (red line) uniquely supports all evaluation dimensions, demonstrating best performance in both TTS and TTM while providing comprehensive controllability across multiple attributes.
text-based emotion and style control, they require additional reference audio for timbre attributes and cannot handle text-controlled dialogue generation. Similarly, current TTM models exhibit limited control capabilities. DiffRhythm+ [18] supports text-based control of genre, instrument, rhythm, and atmosphere but lacks singer timbre control (e.g., gender and age). ACE-Step [15], one of the state-of-the-art (SOTA) open-source music generation model, provides text-based control for all acoustic attributes but focuses exclusively on music without unified speech modeling capabilities. Speech and music generation are typically treated as separate tasks (TTS & TTM), overlooking their shared acoustic modeling abilities and control mechanisms. This separation stems from the difficulty of aligning inputs across TTS and TTM tasks, as speech control involves acoustic attributes such as timbre and paralinguistics, while music generation requires musical attributes such as genre, instrumentation, and rhythm. Vevo2 [22] introduced the first unified speech and singing generation framework, demonstrating that joint modeling leverages rich speech data to improve singing quality while utilizing singing’s expressive characteristics to enhance TTS. However, Vevo2 relies on reference audio for acoustic attribute control rather than text instructions and generates only vocals without instrumental music capabilities. UniAudio [23] builds upon the VALL-E [6] framework to create a single model capable of executing multiple tasks; however, it requires inconsistent input formats across different tasks and necessitates taskspecific fine-tuning. AudioBox [24], a flow-matching-based unified model supporting multiple tasks, pre-trains on speech, music, and sound effect data but ultimately supports only speech and sound effect
The first speaker (Speaker 0) has an elderly adult male voice with a neutral emotional tone. His timbre is clear and steady, without much expressive variation, and it carries the smooth, natural pronunciation of Mandarin Chinese. The second speaker (Speaker 1) also has a young adult male voice, but her timbre is brighter and more animated. With a happy and casual style, her voice conveys liveliness and friendliness, again shaped by the American accent.
[S0] 你好呀,今天天气怎么样? [S1] Hello! What a sunny day! Instruct Description: This is a pop ballad featuring a male vocalist in his 30s with a smooth, melodic tone. The instrumentation is centered around piano and strings, which weave together to create a soft, dreamy backdrop. The tempo is moderate, around 120 BPM, and the piece is set in F major. The overall mood carries a sense of nostalgia and longing, with the flowing piano lines and gentle harmonies evoking reflection and emotional warmth.
[S0] Like you to see the things I hide. Fig. 2: InstructAudio achieves unified generation of both speech and music through an MM-DiT architecture. This framework enables multi-attribute control through natural language instructions. The input format remains consistent across different tasks, comprising a natural language instruction description along with corresponding text or lyrics. Audio is represented using continuous latents extracted from a pre-trained Mel-VAE. During inference, the VAE latent of the target speech or music is obtained through an ODE solver.
generation. AudioLDM 2 [25] proposes a two-stage model applicable to speech, sound, and music generation, yet requires different model architecture hyperparameters for each task. Current approaches lack text-based (natural language descriptions) control mechanisms, limiting
This content is AI-processed based on open access ArXiv data.