Title: SCALER: SAM-Enhanced Collaborative Learning for Label-Deficient Concealed Object Segmentation
ArXiv ID: 2511.18136
Date: 2025-11-22
Authors: Chunming He, Rihan Zhang, Longxiang Tang, Ziyun Yang, Kai Li, Deng-Ping Fan, Sina Farsiu
📝 Abstract
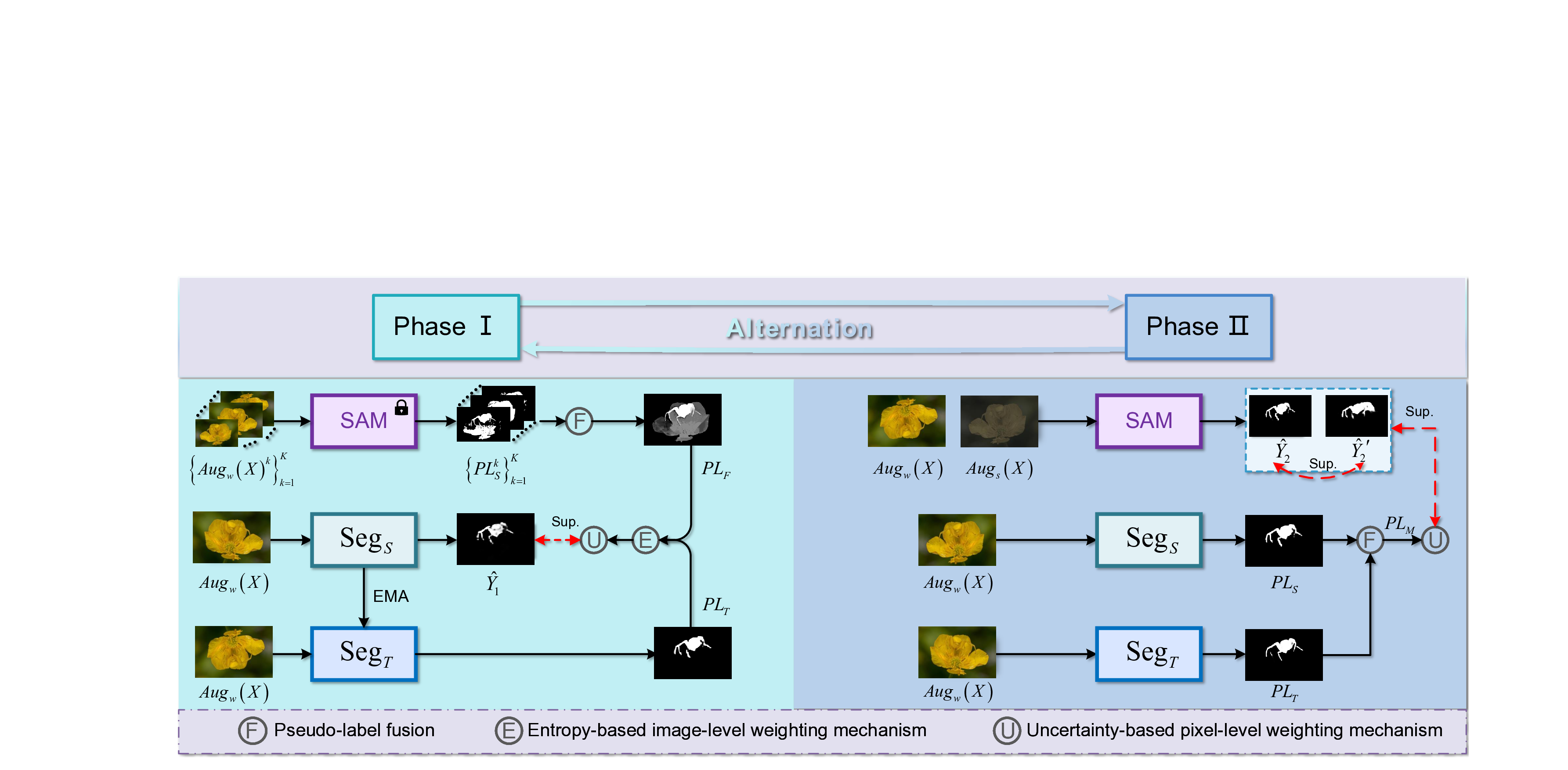
Existing methods for label-deficient concealed object segmentation (LDCOS) either rely on consistency constraints or Segment Anything Model (SAM)-based pseudo-labeling. However, their performance remains limited due to the intrinsic concealment of targets and the scarcity of annotations. This study investigates two key questions: (1) Can consistency constraints and SAM-based supervision be jointly integrated to better exploit complementary information and enhance the segmenter? and (2) beyond that, can the segmenter in turn guide SAM through reciprocal supervision, enabling mutual improvement? To answer these questions, we present SCALER, a unified collaborative framework toward LDCOS that jointly optimizes a mean-teacher segmenter and a learnable SAM. SCALER operates in two alternating phases. In \textbf{Phase \uppercase\expandafter{\romannumeral1}}, the segmenter is optimized under fixed SAM supervision using entropy-based image-level and uncertainty-based pixel-level weighting to select reliable pseudo-label regions and emphasize harder examples. In \textbf{Phase \uppercase\expandafter{\romannumeral2}}, SAM is updated via augmentation invariance and noise resistance losses, leveraging its inherent robustness to perturbations. Experiments demonstrate that SCALER yields consistent performance gains across eight semi- and weakly-supervised COS tasks. The results further suggest that SCALER can serve as a general training paradigm to enhance both lightweight segmenters and large foundation models under label-scarce conditions. Code will be released.
💡 Deep Analysis
📄 Full Content
SCALER: SAM-Enhanced Collaborative Learning for
Label-Deficient Concealed Object Segmentation
Chunming He1 , Rihan Zhang1 , Longxiang Tang2 , Ziyun Yang3 ,
Kai Li4 , Deng-Ping Fan5 , and Sina Farsiu1,†
1Duke University, 2Harvard University, 3Apple, 4Meta, 5Nankai University,
† Corresponding Author, Contact: chunming.he@duke.edu.
↑
GenSAM WS-SAM
SEE
SCALER
0.67
0.68
0.69
0.70
0.71
0.72
(AAAI'24)
COD10K
WSCOD
(NIPS'23) (TPAMI'25)
(Ours)
↑
CoSOD
SAM-S
SEE
SCALER
0.67
0.68
0.69
0.70
0.71
0.72
(WACV'24)
COD10K
SSCOD
(ICCVW'23)(TPAMI'25)
(Ours)
SCOD
WS-SAM
SEE
SCALER
0.85
0.86
0.87
0.88
0.89
0.90
(AAAI'23)
Kvasir
WSPIS
(NIPS'23) (TPAMI'25)
(Ours)
EPS
CoSOD
SEE
SCALER
0.82
0.83
0.84
0.85
(TPAMI'23)
GSD
SSTOD
(WACV'23) (TPAMI'25)
(Ours)
0.012
0.012↑
0.011
0.010↑
(a) Origin
(b) GT
(c) SCOD
(d) WS-SAM
(e) SEE
(f) WS-SAM+
(g) SEE+
(h) SCALER (Ours)
(a) Origin
(b) GT
(c) SCOD
(d) WS-SAM
(e) SEE
(f) WS-SAM+
(g) SEE+
(h) SCALER (Ours)
Figure 1. Results of existing LDCOS methods with point supervision, including SCOD [15], WS-SAM [11], and SEE [13]. The suffix
“+” denotes integration with SCALER. SCALER yields more accurate concealed-object segmentation and achieves leading results across
COD (camouflaged object detection), PIS (polyp image segmentation), and TOD (transparent object detection) under weak (WS) and
semi-supervised (SS) settings. In the top section, concealed objects masks are highlighted in pink and blue.
Abstract
Existing methods for label-deficient concealed object seg-
mentation (LDCOS) either rely on consistency constraints
or Segment Anything Model (SAM)-based pseudo-labeling.
However, their performance remains limited due to the intrin-
sic concealment of targets and the scarcity of annotations.
This study investigates two key questions: (1) Can consis-
tency constraints and SAM-based supervision be jointly in-
tegrated to better exploit complementary information and
enhance the segmenter? and (2) beyond that, can the seg-
menter in turn guide SAM through reciprocal supervision, en-
abling mutual improvement? To answer these questions, we
present SCALER, a unified collaborative framework toward
LDCOS that jointly optimizes a mean-teacher segmenter
and a learnable SAM. SCALER operates in two alternat-
ing phases. In Phase I, the segmenter is optimized under
fixed SAM supervision using entropy-based image-level and
uncertainty-based pixel-level weighting to select reliable
pseudo-label regions and emphasize harder examples. In
Phase II, SAM is updated via augmentation invariance and
noise resistance losses, leveraging its inherent robustness
to perturbations. Experiments demonstrate that SCALER
yields consistent performance gains across eight semi- and
weakly-supervised COS tasks. The results further suggest
that SCALER can serve as a general training paradigm to
enhance both lightweight segmenters and large foundation
models under label-scarce conditions. Code will be released.
1. Introduction
Concealed object segmentation (COS) encompasses scenar-
ios where targets share high visual similarity with their sur-
roundings, making them difficult to distinguish. Represen-
tative tasks include camouflaged object detection (COD)
[6, 10], polyp image segmentation (PIS) [7, 27], medical
tubular object segmentation (MTOS) [9, 14], and transpar-
ent object detection (TOD) [11, 28]. Unlike conventional
arXiv:2511.18136v1 [cs.CV] 22 Nov 2025
segmentation, COS must contend with weak contrast and am-
biguous boundaries, which significantly complicate training.
Early studies mitigated these difficulties through perceptual
priors [12, 31] and auxiliary cues [10, 25], showing strong
results under full supervision.
The challenge grows sharper in label-deficient COS (LD-
COS), including semi- (SSCOS) and weakly-supervised
(WSCOS) setups, where limited annotations constrain learn-
ing. Prior works have extended consistency-based frame-
works, particularly the mean-teacher paradigm that enforces
prediction stability between a student and an exponentially
averaged teacher [15, 20]. However, the reliance on pseudo-
labels often introduces error accumulation, especially for
concealed targets with uncertain boundaries (see Fig. 1).
To exploit foundation model guidance, recent works such
as WS-SAM[11] and SEE[13] employed the pretrained Seg-
ment Anything Model (SAM)[19] as an external teacher,
transferring its global knowledge to task-specific segmenters.
These methods confirm SAM’s potential in providing sup-
plementary supervision, yet face two major limitations (see
Fig. 2). First, SAM’s fixed predictions are not tailored for
COS, yielding noisy and suboptimal pseudo labels. Sec-
ond, the information flow remains one-way, from SAM to
the segmenter, without allowing the evolving, task-adapted
segmenter to reciprocally benefit SAM.
These shortcomings raise two central questions: (1) Can
consistency learning and SAM-based supervision be jointly
leveraged to improve segmenters under label scarcity? (2)
Can the segmenter itsel