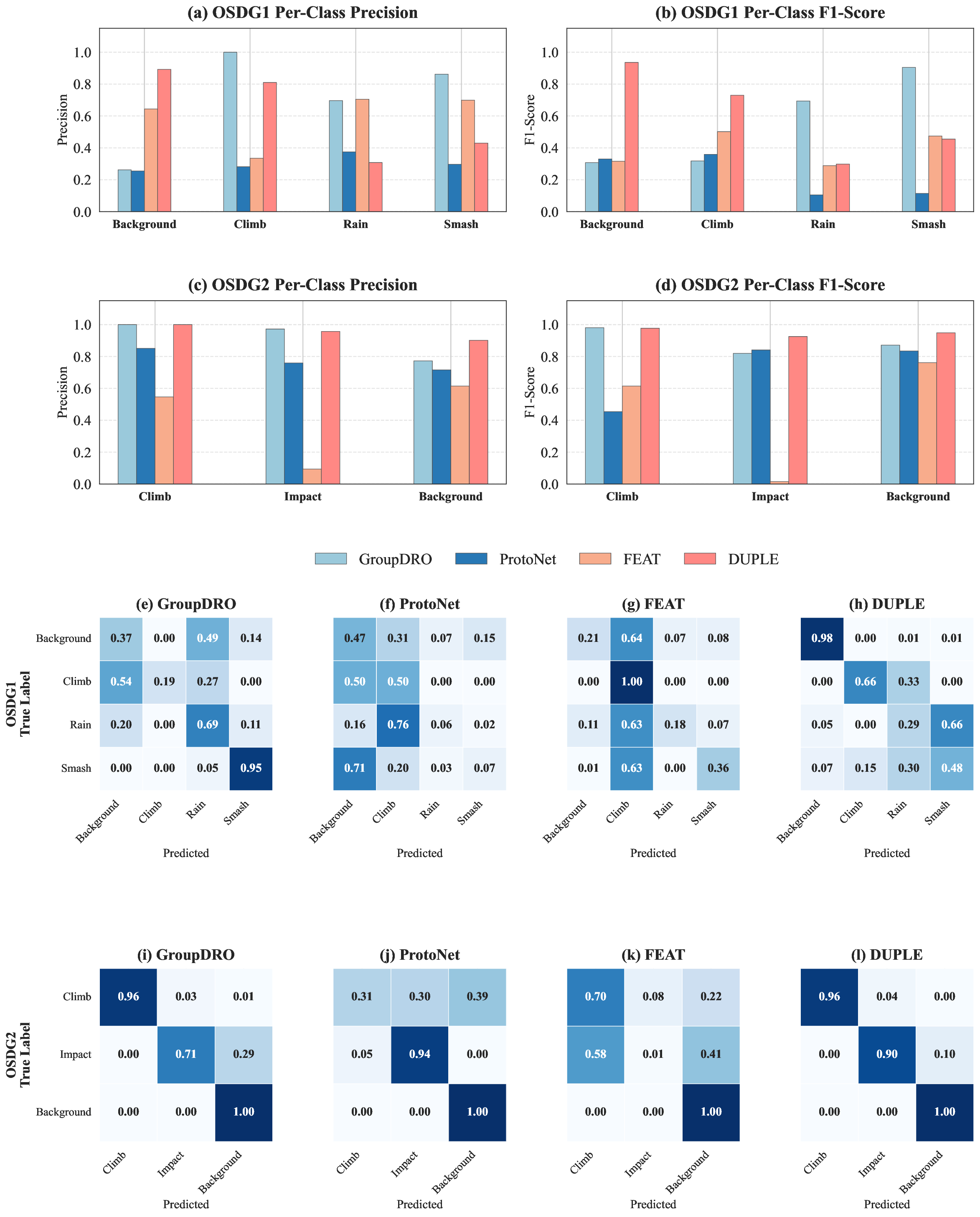
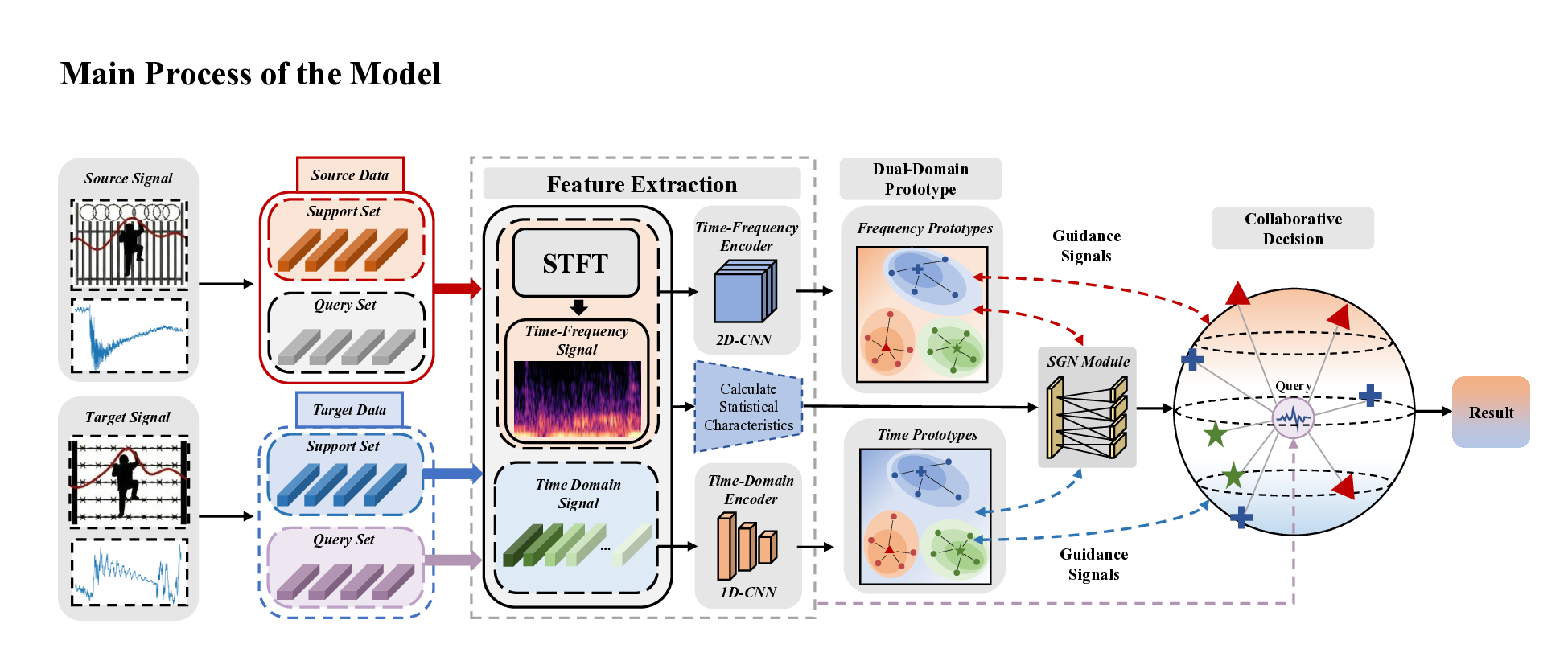
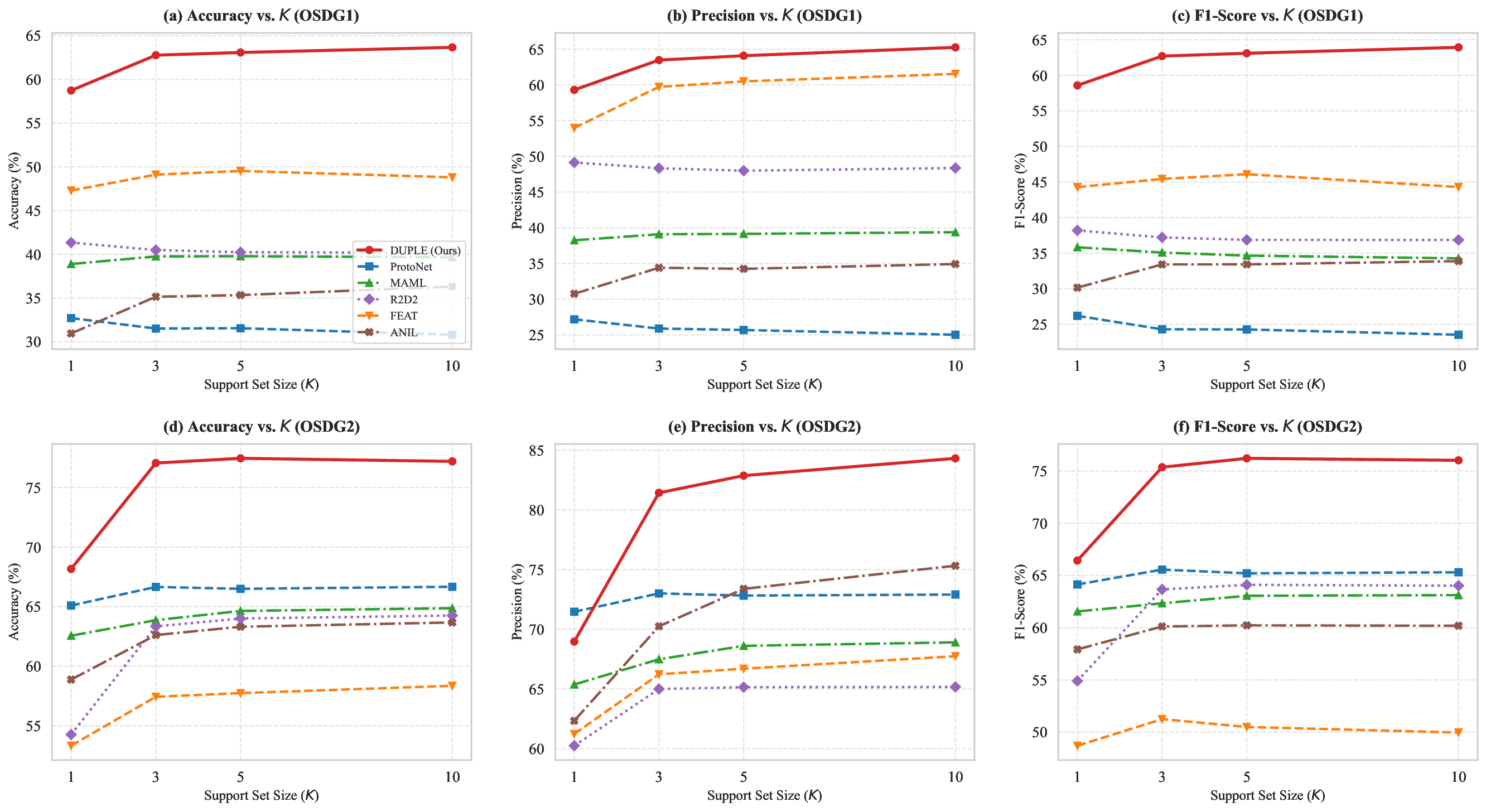
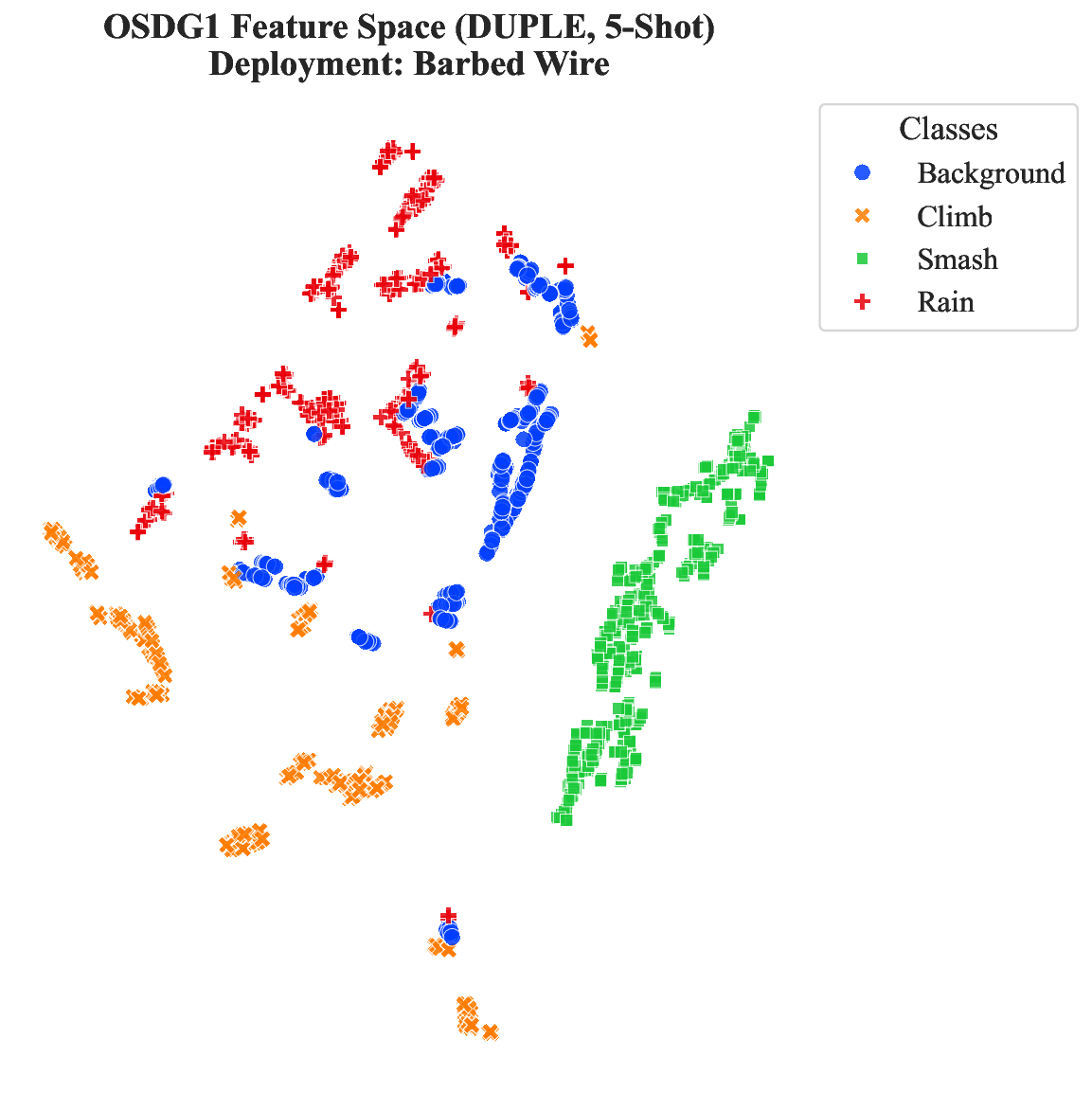
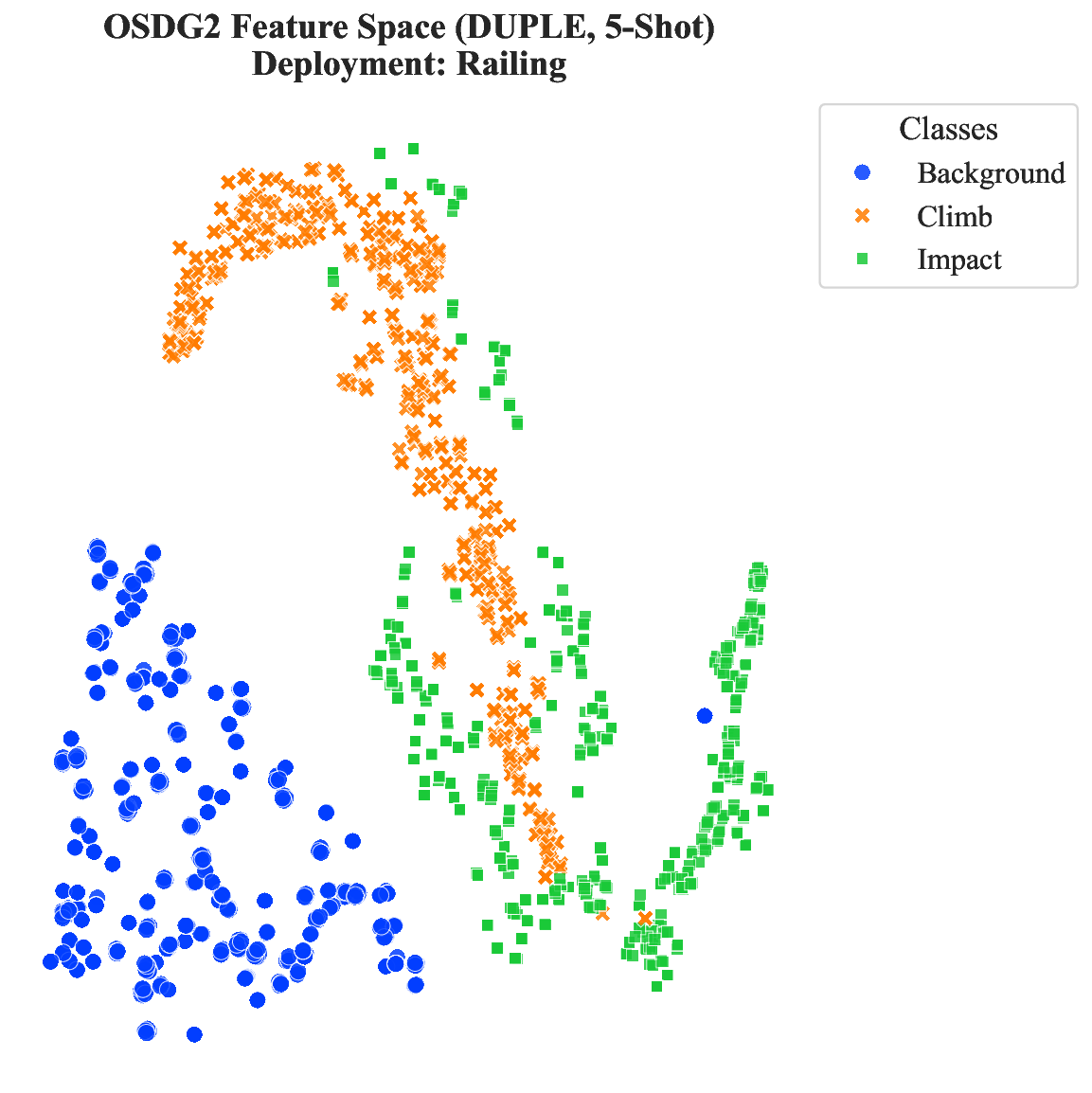
Distributed Fiber Optic Sensing (DFOS) is promising for long-range perimeter security, yet practical deployment faces three key obstacles: severe cross-deployment domain shift, scarce or unavailable labels at new sites, and limited within-class coverage even in source deployments. We propose DUPLE, a prototype-based meta-learning framework tailored for cross-deployment DFOS recognition. The core idea is to jointly exploit complementary time- and frequency-domain cues and adapt class representations to sample-specific statistics: (i) a dual-domain learner constructs multi-prototype class representations to cover intra-class heterogeneity; (ii) a lightweight statistical guidance mechanism estimates the reliability of each domain from raw signal statistics; and (iii) a query-adaptive aggregation strategy selects and combines the most relevant prototypes for each query. Extensive experiments on two real-world cross-deployment benchmarks demonstrate consistent improvements over strong deep learning and meta-learning baselines, achieving more accurate and stable recognition under label-scarce target deployments.
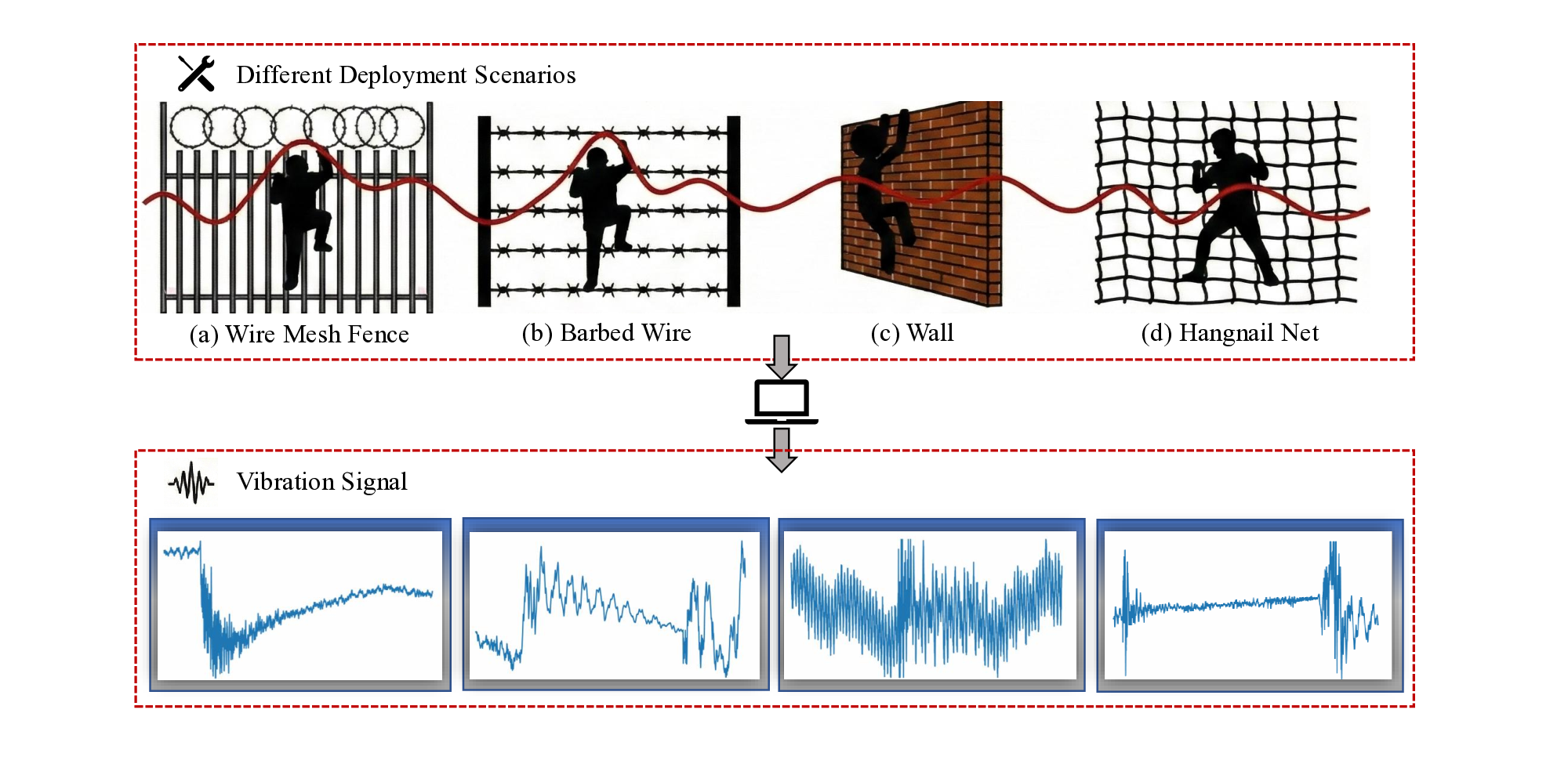
Fiber-optic sensing acquires continuous measurements of strain, vibration, and temperature along tens of kilometers of cable by interrogating minute variations in the optical field. It delivers meter-scale spatial resolution and high temporal sampling while avoiding any distributed active electronics along the route (Rao et al., 2021;Hartog, 2017;Wang et al., 2020). Owing to its long reach, continuous coverage, immunity to electromagnetic interference, and reuse of existing telecom fiber, the technology is broadly applicable to pipeline inspection, powerand railway-corridor monitoring, structural-health and geotechnical monitoring, and environmental and seismic sensing. In perimeter security in particular, a single fiber can provide covert, privacy-preserving continuous coverage, eliminating the need to deploy and maintain dense arrays of point sensors (Muñoz and Soto, 2022;Ajo-Franklin et al., 2019;Lindsey et al., 2019;Tejedor et al., 2019;Zhong et al., 2025).
Current approaches for identifying fiber optic signals range from hand-crafted features using traditional classifiers to end-toend neural networks. The former extracts time-and frequencydomain descriptors (such as statistical moments, short-time Fourier transforms, or wavelet coefficients) and performs classification using support vector machines (SVMs), random forests, or hidden Markov models (HMMs) (He and Liu, 2021;Tejedor et al., 2019). The latter uses one-or two-dimensional CNNs or recurrent architectures to learn discriminative representations directly from the raw data stream (Wu et al., 2019a(Wu et al., , 2021)). While these methods are effective in fixed settings, they fail to generalize reliably across deployments. Differences in fiber type and layout (e.g., underground or wall-mounted), coupling conditions, and ambient noise can lead to significant domain shift (Muñoz and Soto, 2022). New sites often provide little or no labeled data, and even source deployments may lack sufficient within-class coverage to capture the diverse patterns of activity. As a result, models overfit to the training conditions and experience a sharp decline in performance when moved to new locations.
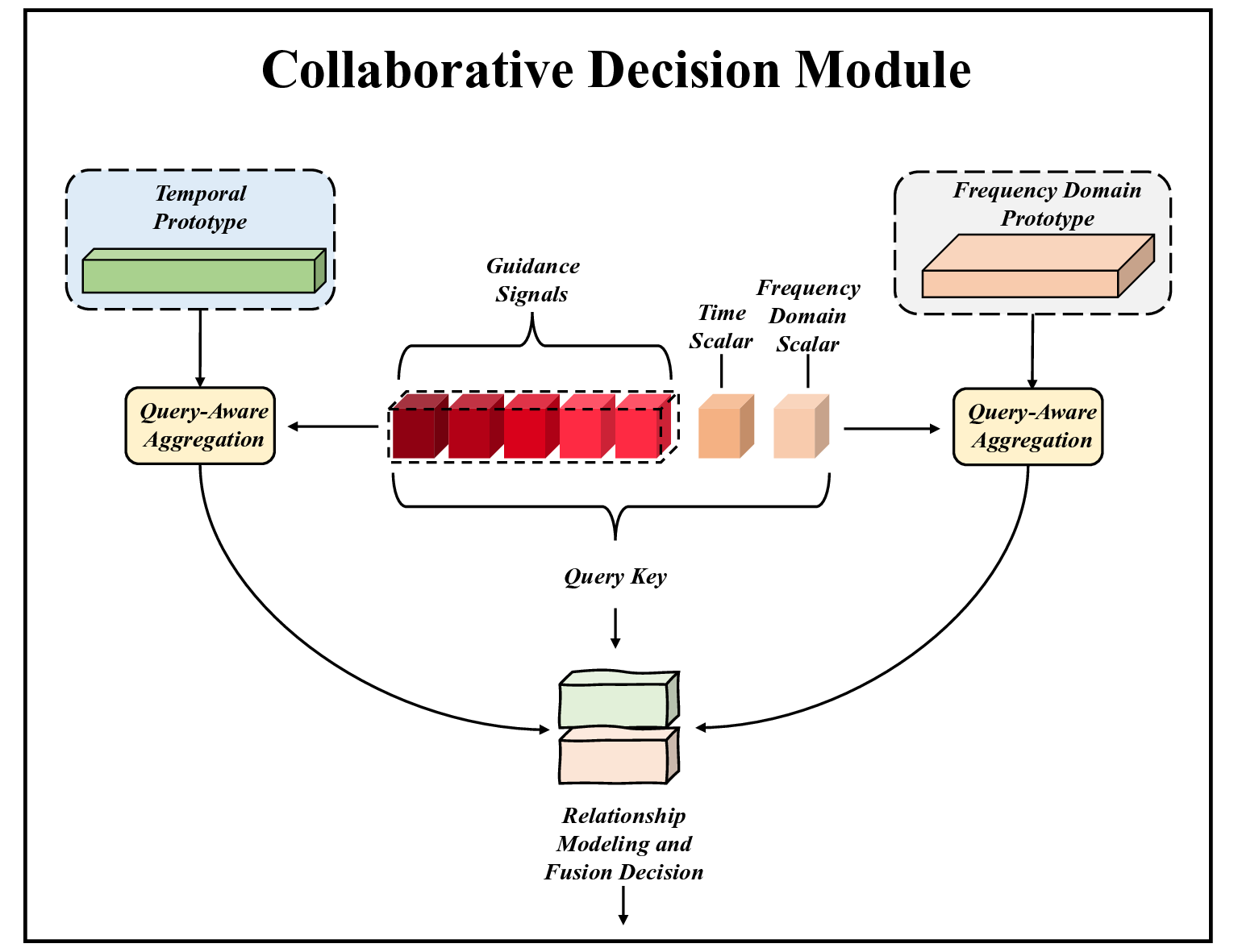
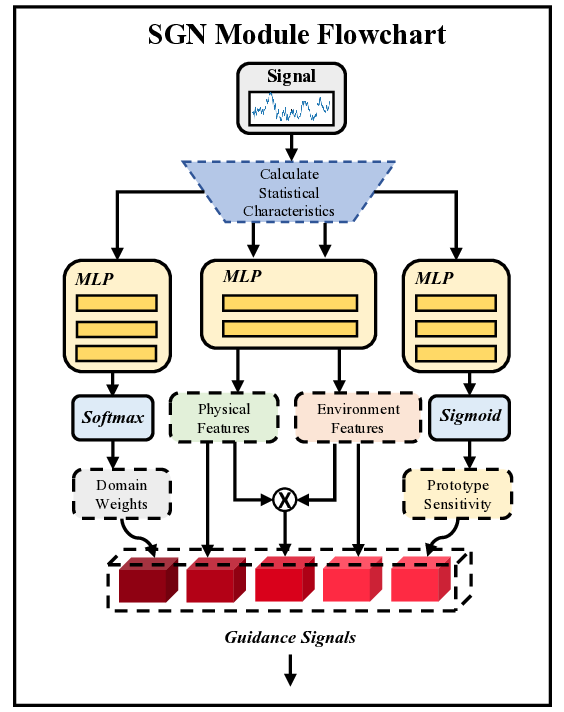
A natural response is to seek domain generalization. Conventional domain adaptation or transfer learning improves robustness when some target-domain data (unlabeled or a few labels) are available for fine-tuning or distribution alignment; however, such data are frequently unavailable or costly to obtain in perimeter security deployments. In contrast, meta-learning offers an attractive fit for this problem: by training episodically across multiple deployments, with support/query splits that mimic cross-deployment testing, the learner acquires tasklevel adaptation skills that transfer to unseen sites without target labels (Finn et al., 2017;Snell et al., 2017;Ye et al., 2020). Metalearning also naturally supports few-shot and low-data regimes, aligning with the realities of field deployment and the variability intrinsic to interferometric fiber signals (Luong et al., 2023). Despite this promise, three gaps remain in applying metalearning to fiber-optic sensing: (i) Missing dual-domain synergy under multimodality. Existing models typically emphasize either time-domain or frequency-domain features, or fuse them with static rules (Zhang et al., 2022). They also often assume a single prototype per class, which cannot cover the multi-modal patterns that arise across deployments and coupling conditions. A principled time+frequency collaborative meta-learner with multi-prototype class representations and a sound fusion rule is needed (Zhang et al., 2022;Allen et al., 2019). (ii) Lack of statistical guidance to coordinate views. The relative reliability of time vs. frequency evidence varies by sample and deployment (e.g., SNR, noise color, bandwidth) (Titov et al., 2022). Current methods rarely exploit raw statistical descriptors to infer domain importance or prototype sensitivity, leaving fusion under-informed. (iii) No query-adaptive decision at inference. Most meta-classifiers compare a query to fixed class prototypes; they do not adapt the class representation per query. For interferometric signals with localized artifacts and variable coupling, the classifier should select and weight the most relevant prototypes conditioned on the query’s own statistics (Ye et al., 2020;Vinyals et al., 2016).
We address these gaps with Statistically-Guided Dual-Domain Meta-Learning with Adaptive Multi-Prototype Aggregation, a framework tailored for cross-deployment fiber-optic sensing with Michelson-based vibration capture. Our contributions are threefold:
• We design a dual-domain meta-learner that jointly encodes time-domain and frequency-domain embeddings and performs per-class multi-prototype clustering in each view. Class evidence from the two domains is fused via a soft-OR (logsum-exp) rule, yielding expressive and deployment-robust class representations under distribution shifts.
This content is AI-processed based on open access ArXiv data.