Document Visual Question Answering (VQA) requires models to not only extract accurate textual answers but also precisely localize them within document images, a capability critical for interpretability in high-stakes applications. However, existing systems achieve strong textual accuracy while producing unreliable spatial grounding, or sacrifice performance for interpretability. We present ARIAL (Agentic Reasoning for Interpretable Answer Localization), a modular framework that orchestrates specialized tools through an LLM-based planning agent to achieve both precise answer extraction and reliable spatial grounding. ARIAL decomposes Document VQA into structured subtasks: OCR-based text extraction with TrOCR, retrieval-augmented context selection using semantic search, answer generation via a fine-tuned Gemma 3-27B model, and explicit bounding-box localization through text-to-region alignment. This modular architecture produces transparent reasoning traces, enabling tool-level auditability and independent component optimization. We evaluate ARIAL on four benchmarks (DocVQA, FUNSD, CORD, and SROIE) using both textual accuracy (ANLS) and spatial precision (mAP at IoU 0.50 to 0.95). ARIAL achieves state-of-the-art results across all datasets: 88.7 ANLS and 50.1 mAP on DocVQA, 90.0 ANLS and 50.3 mAP on FUNSD, 85.5 ANLS and 60.2 mAP on CORD, and 93.1 ANLS on SROIE, surpassing the previous best method (DLaVA) by +2.8 ANLS and +3.9 mAP on DocVQA. Our work demonstrates how agentic orchestration of specialized tools can simultaneously improve performance and interpretability, providing a pathway toward trustworthy, explainable document AI systems.
💡 Deep Analysis
📄 Full Content
ARIAL: An Agentic Framework for Document VQA
with Precise Answer Localization
Ahmad Mohammadshirazi
Ohio State University
Flairsoft
Columbus, Ohio, US
mohammadshirazi.2@osu.edu
Pinaki Prasad Guha Neogi
Ohio State University
Columbus, Ohio, US
guhaneogi.2@osu.edu
Dheeraj Kulshrestha
Flairsoft
Columbus, Ohio, US
dheeraj@flairsoft.net
Rajiv Ramnath
Ohio State University
Columbus, Ohio, US
ramnath.6@osu.edu
Abstract
Document Visual Question Answering (VQA) requires models to not only ex-
tract accurate textual answers but also precisely localize them within document
images—a capability critical for interpretability in high-stakes applications. How-
ever, existing systems achieve strong textual accuracy while producing unreliable
spatial grounding, or sacrifice performance for interpretability. We present ARIAL
(Agentic Reasoning for Interpretable Answer Localization), a modular framework
that orchestrates specialized tools through an LLM-based planning agent to achieve
both precise answer extraction and reliable spatial grounding. ARIAL decomposes
Document VQA into structured subtasks: OCR-based text extraction with TrOCR,
retrieval-augmented context selection using semantic search, answer generation via
fine-tuned Gemma 3-27B, and explicit bounding-box localization through text-to-
region alignment. This modular architecture produces transparent reasoning traces,
enabling tool-level auditability and independent component optimization. We eval-
uate ARIAL on four benchmarks—DocVQA, FUNSD, CORD, and SROIE—using
both textual accuracy (ANLS) and spatial precision (mAP@IoU 0.50:0.95). AR-
IAL achieves SoTA results across all datasets: 88.7 ANLS and 50.1 mAP on
DocVQA, 90.0 ANLS and 50.3 mAP on FUNSD, 85.5 ANLS and 60.2 mAP on
CORD, and 93.1 ANLS on SROIE, surpassing the previous best method (DLaVA)
by +2.8 ANLS and +3.9 mAP on DocVQA. Our work demonstrates how agentic
orchestration of specialized tools can simultaneously improve performance and
interpretability, providing a pathway toward trustworthy, explainable document AI
systems. Code is available at: https://github.com/ahmad-shirazi/ARIAL
1
Introduction
Document Visual Question Answering (VQA) requires reasoning over both textual content and
visual layout in scanned or digitally rendered documents. Models must not only read and understand
diverse formats—forms, receipts, reports—but also locate where answers appear within the document
structure.
While recent models such as LayoutLMv3 [14], LayoutLLM [29], and DocLayLLM [25] have
improved textual accuracy by combining language with layout features, they often treat localization
as a secondary task. Consequently, they may generate plausible answers without clearly identifying
their source in the document, making verification difficult. Standard metrics like ANLS [40] capture
39th Conference on Neural Information Processing Systems (NeurIPS 2025).
arXiv:2511.18192v2 [cs.CV] 28 Nov 2025
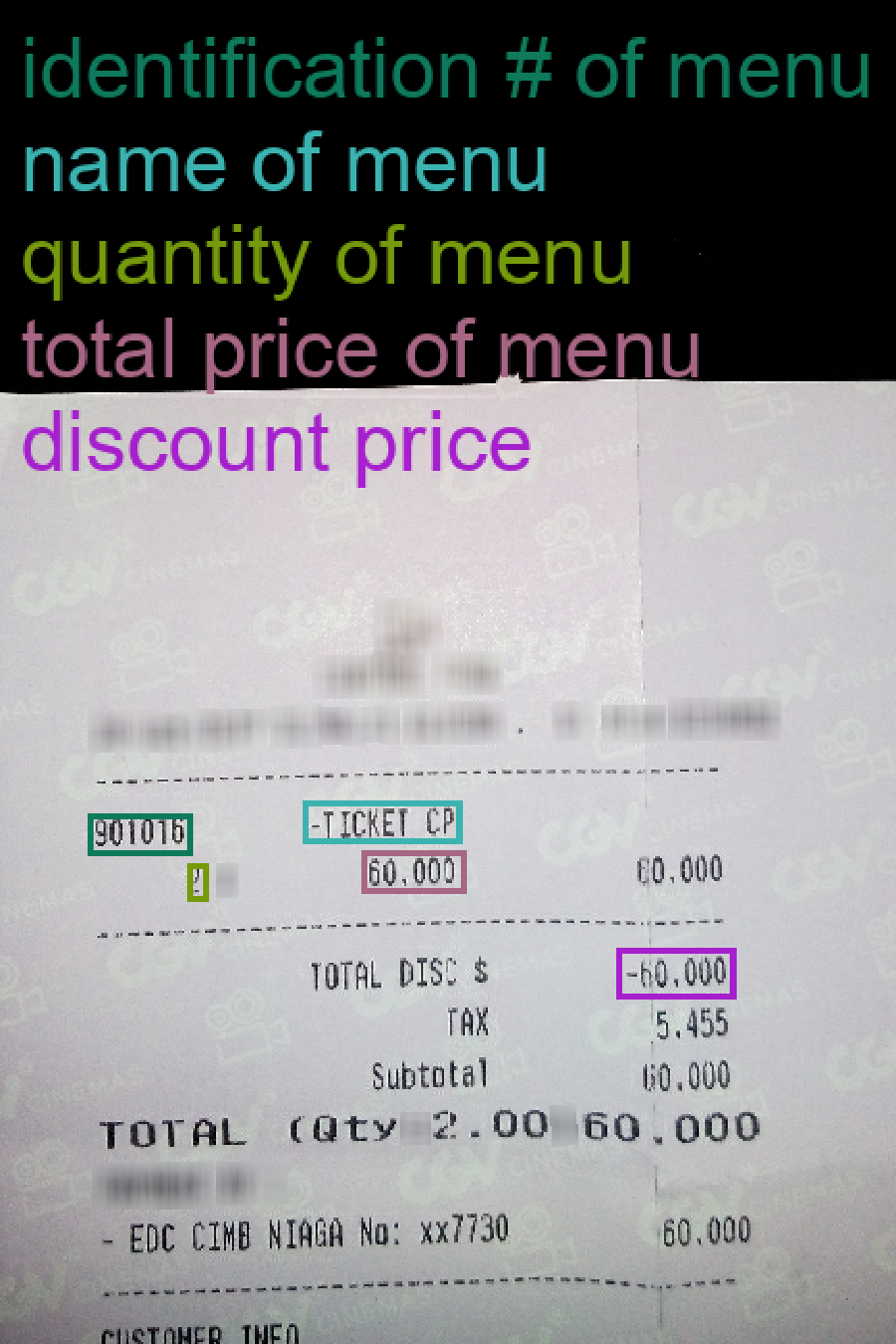
Figure 1: Overview of the ARIAL agentic workflow for Document VQA. The system consists
of three modular stages: (1) Input Processing, where an OCR module extracts text segments and
bounding boxes from a document image; (2) Agentic Reasoning Pipeline, where the planner agent
coordinates task execution—retrieving relevant text, invoking QA or computation, and triggering
spatial grounding; and (3) Output Generation, where the final answer and its bounding box are
produced. The reasoning loop enables iterative refinement based on confidence, supporting flexible
and context-aware decision-making.
string similarity but fail to reflect spatial correctness, prompting a shift towards combined evaluations
that include IoU for grounding precision.
DLaVA [33] introduced answer localization by integrating bounding-box prediction within a large
multimodal transformer. However, its monolithic design can be computationally intensive and may
struggle with fine-grained details in dense or handwritten layouts.
We propose ARIAL (Agentic Reasoning for Interpretable Answer Localization), a modular document
VQA framework built around an agentic planning model. Rather than using a single large model, AR-
IAL delegates subtasks—OCR, layout analysis, retrieval, reasoning, and grounding—to specialized
modules orchestrated by a central agent. This agent, implemented with LLaMA 4 Scout [31], dynam-
ically selects tools and composes multi-step reasoning chains, enabling accurate and interpretable
answers with precise spatial grounding. Our key contributions are:
1. Agentic Document QA: We introduce an agent-based document VQA system that decom-
poses queries into tool calls for OCR, retrieval, and grounding. The modular design enables
tool reuse, error tracing, and flexible adaptation across document types.
2. Precise Answer Localization: ARIAL produces both answer text and corresponding
bounding boxes by aligning answers to OCR-detected spans and contextual cues, ensuring
visual traceability.
3. Retrieval-Augmented Reasoning: ARIAL incorporates retrieval-aug