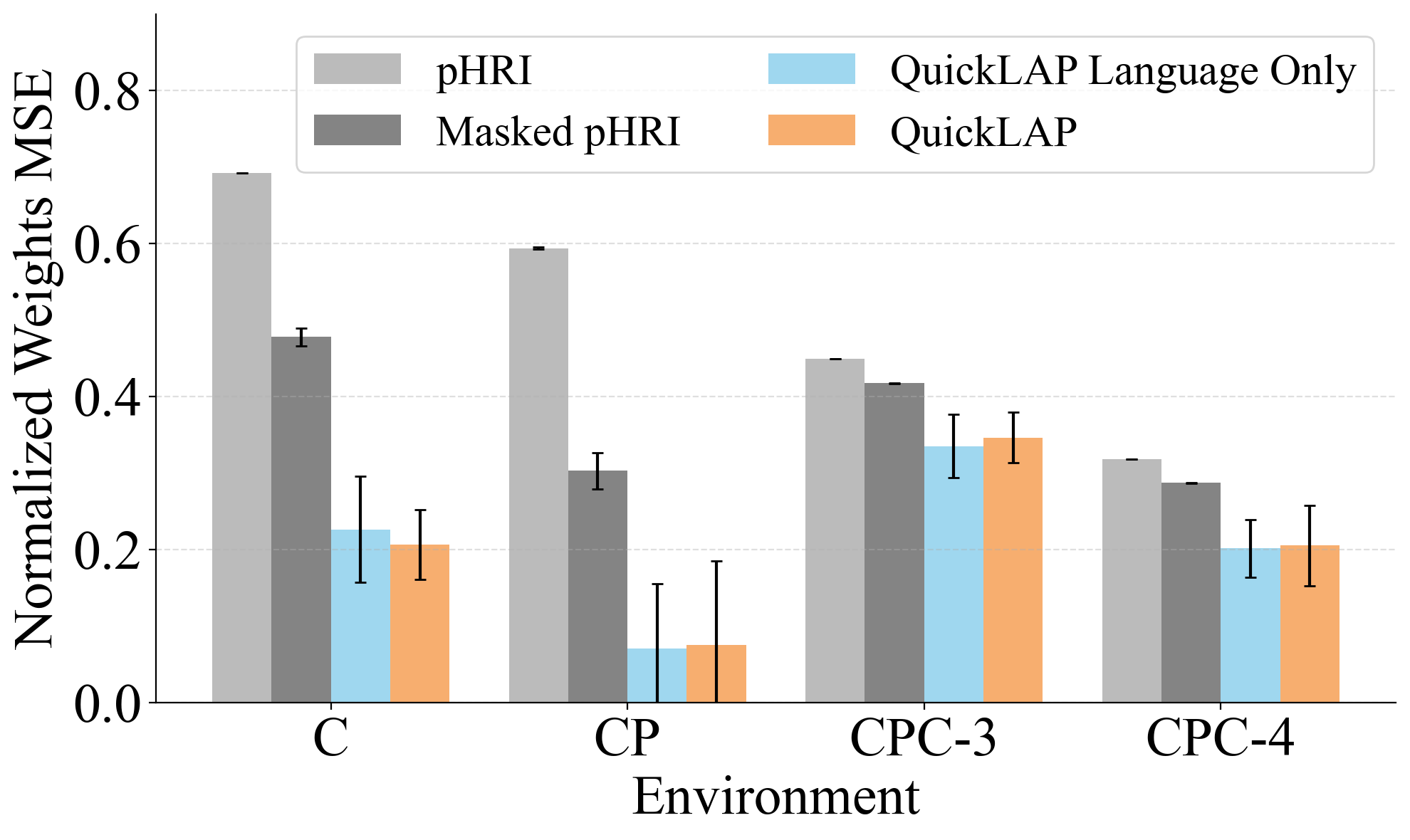
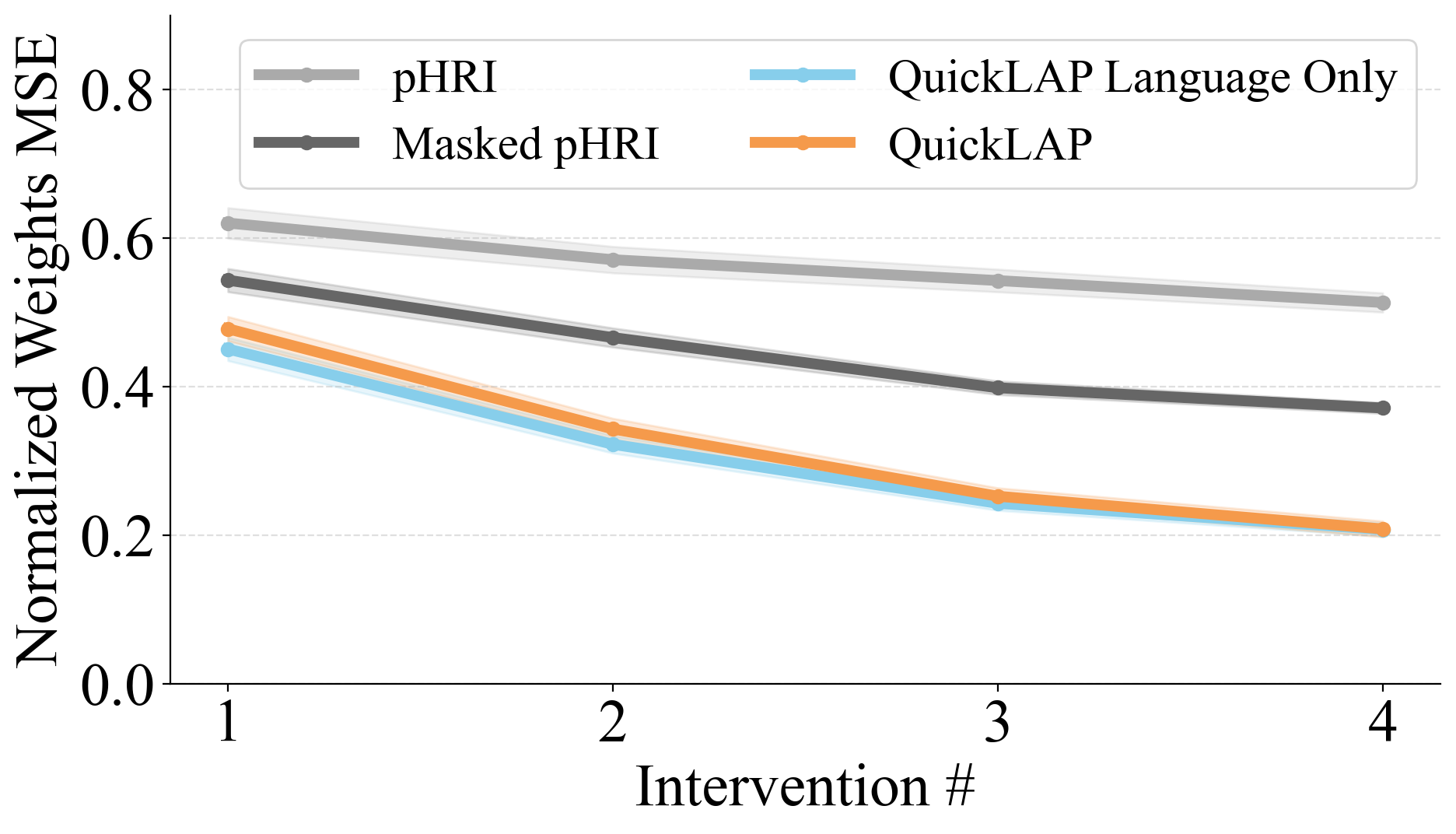
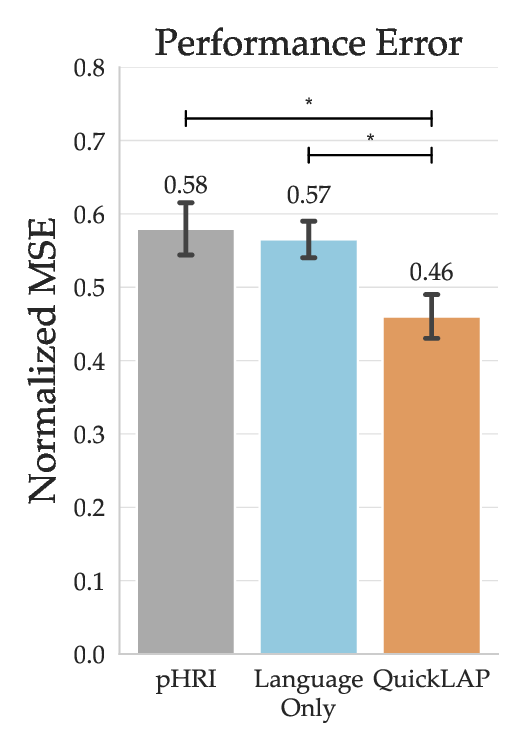
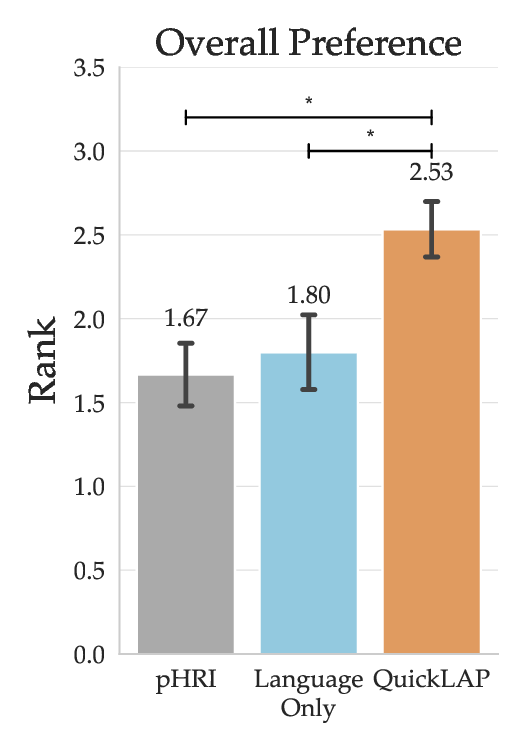
Robots must learn from both what people do and what they say, but either modality alone is often incomplete: physical corrections are grounded but ambiguous in intent, while language expresses high-level goals but lacks physical grounding. We introduce QuickLAP: Quick Language-Action Preference learning, a Bayesian framework that fuses physical and language feedback to infer reward functions in real time. Our key insight is to treat language as a probabilistic observation over the user's latent preferences, clarifying which reward features matter and how physical corrections should be interpreted. QuickLAP uses Large Language Models (LLMs) to extract reward feature attention masks and preference shifts from free-form utterances, which it integrates with physical feedback in a closed-form update rule. This enables fast, real-time, and robust reward learning that handles ambiguous feedback. In a semi-autonomous driving simulator, QuickLAP reduces reward learning error by over 70% compared to physical-only and heuristic multimodal baselines. A 15-participant user study further validates our approach: participants found QuickLAP significantly more understandable and collaborative, and preferred its learned behavior over baselines. Code is available at https://github.com/MIT-CLEAR-Lab/QuickLAP.
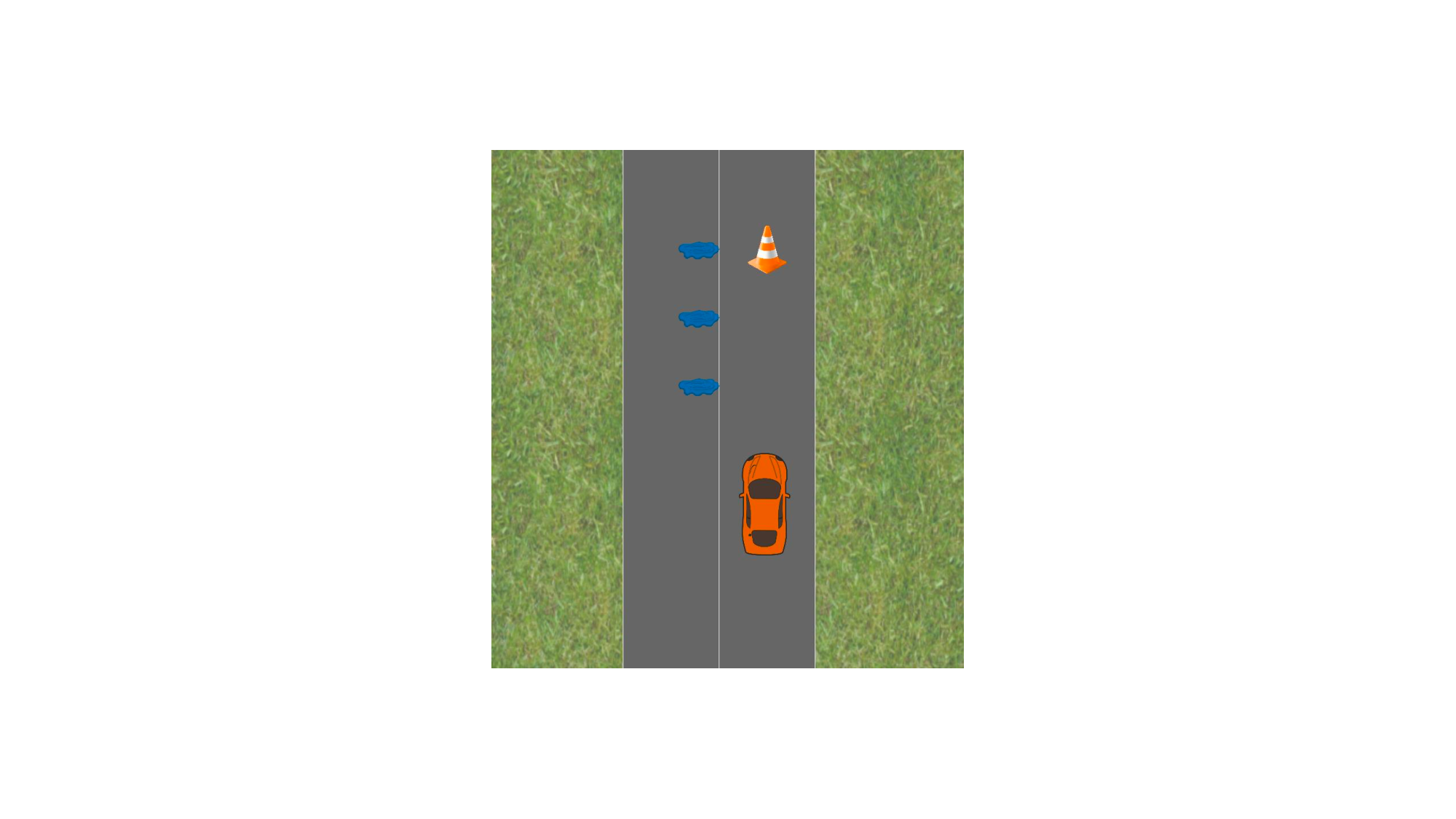
Humans reveal their preferences through both what they do and what they say. Consider the semi-autonomous vehicle approaching a construction zone in Fig. 1: the user could physically nudge the steering wheel away, or say "Stay away from the cones!". Each of these signals is only part of the story: physical corrections offer precise, reactive adjustments but are opaque in intent, while language clarifies what matters to the user but lacks the physical grounding needed to guide behavior on its own. To adapt effectively, robots must learn to interpret them together, in context and in real time.
Inverse Reinforcement Learning (IRL) methods that learn from physical corrections can adapt quickly and infer a reward function over task-relevant features (e.g. distance to obstacles, lane alignment, etc.) that reflects the user’s underlying preferences [4]. But while these corrections are grounded and precise, they are inherently ambiguous: the same steering adjustment in Fig. 1 could reflect a desire to avoid construction zones, to change lanes, or to stay close to puddles. Without more context, the robot can’t know which interpretation is correct. Natural language can help resolve this ambiguity. An utterance like “Stay far from the cones!” makes the user’s intent explicit, revealing preferences that are hard to infer from motion alone. But language has its own limitations: it can be vague (“Stay away!”), underspecified, or context-dependent.
On its own, it may fail to convey exactly how the robot should act. Crucially, we observe that these two feedback channels are complementary: language clarifies the intent behind a correction, and the correction grounds and disambiguates the language. Together, they offer a more complete signal than either can provide alone. Yet few existing methods take full advantage of this complementarity. Some multimodal robot learning methods rely on large datasets of paired trajectories and language [10,36,37,52,55], limiting their ability to adapt on the fly. Others assume language inputs are clean, unambiguous, and self-contained [14,30], rather than interpreting them in conjunction with behavior. What’s missing is a principled mechanism for integrating physical and language input in real time. As a result, these methods fall short in exactly the settings where joint feedback should be most useful: ambiguous, fast-changing, and underspecified environments.
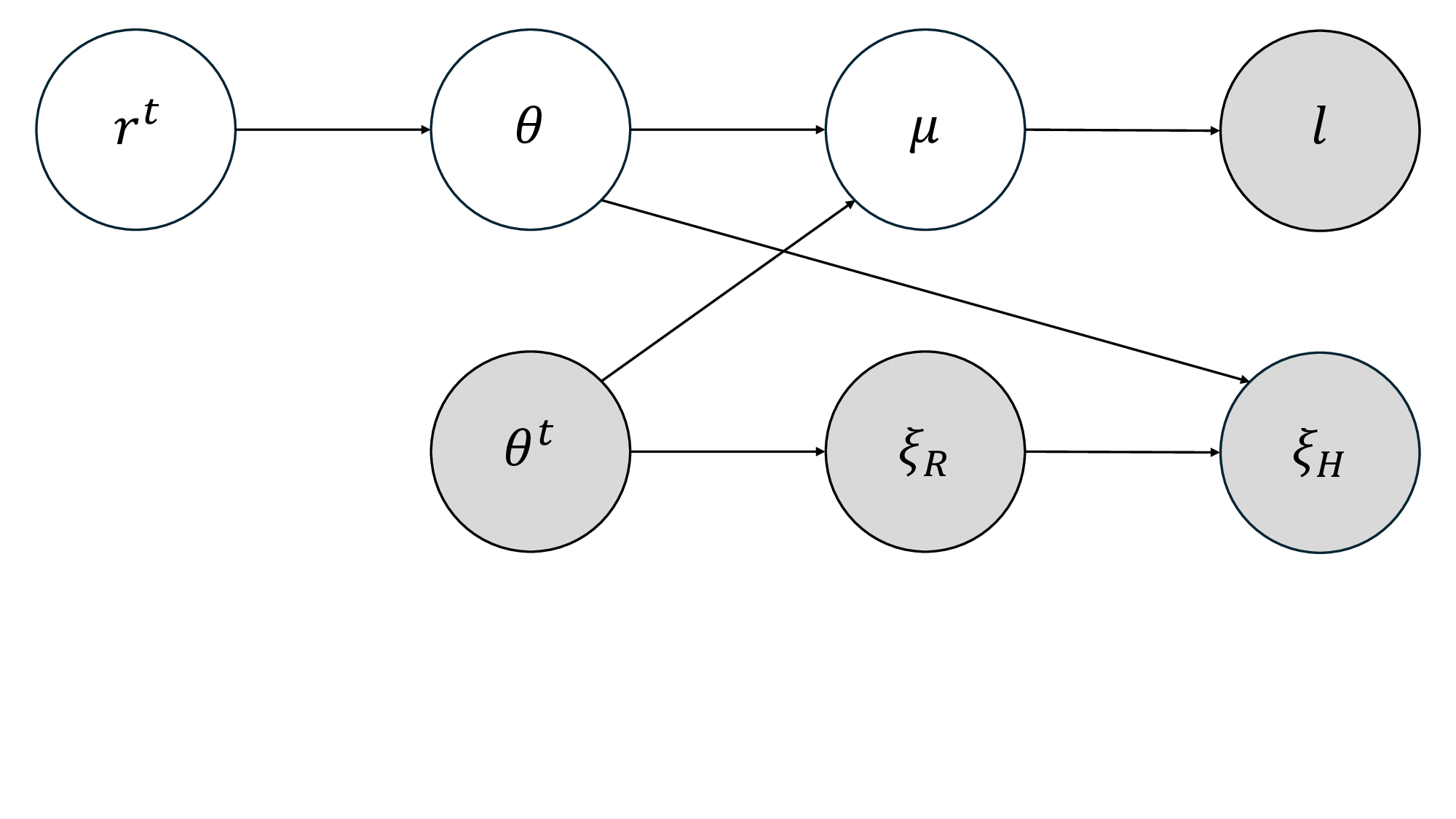
Our key insight is that language can serve as a probabilistic observation over the user’s latent reward, not just describing what matters, but modulating how physical corrections should be interpreted. Language plays two roles: it identifies which features are relevant to the user’s intent, which we use to shape a prior over reward weights; and it suggests how those preferences should shift, which we use to inform a likelihood given the corrected trajectory. This perspective enables a principled fusion of modalities that resolves ambiguity and supports rapid online learning.
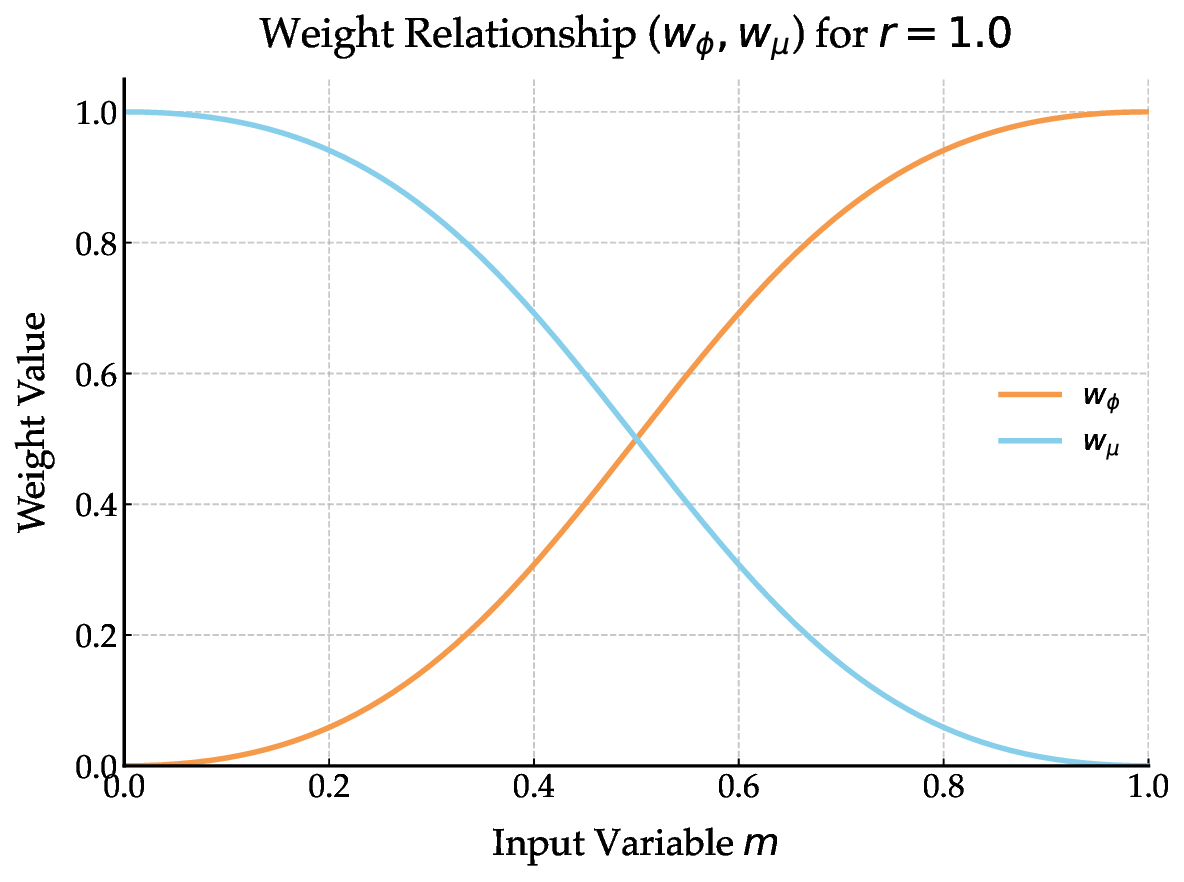
We introduce QuickLAP: Quick Language-Action Preference learning, a closed-form Bayesian framework for online reward inference from joint physical and language feedback. For each intervention, an LLM processes the user’s utterance in context (alongside the robot’s proposed trajectory and the human’s correction) to produce three signals: a feature attention mask (what matters), a proposed reward shift (how behavior should change), and confidence weights (how certain the LLM is). These signals are fused with a Boltzmann-rational model of the correction and an attention-weighted prior to produce a Gaussian posterior over reward parameters. This yields an efficient MAP update rule that extends IRL to multimodal feedback, robustly handles ambiguity, and supports real-time adaptation. Importantly, QuickLAP is robust to ambiguity in either channel: vague utterances are interpreted in the context of physical corrections, and unclear corrections are disambiguated by language. Rather than assuming clean or isolated inputs, QuickLAP exploits the natural interplay between language and action to infer what the user wants efficiently and in real time.
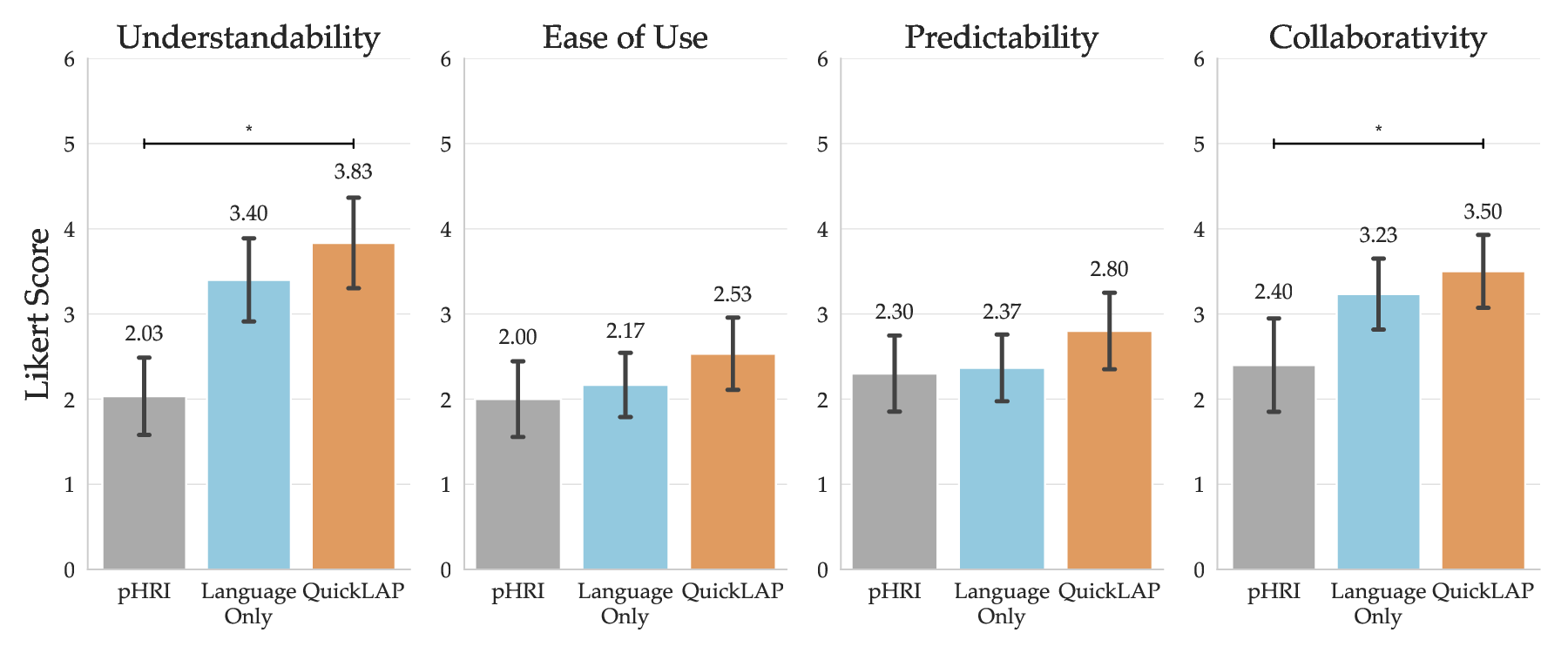
To summarize, our main contributions are: 1) an efficient Bayesian framework for jointly interpreting physical corrections and natural language feedback in real time; 2) an LLM-based semantic parser procedure that maps free-form language to structured reward signals without task-specific training; 3) extensive simulation results showing large reductions in reward-inference error; 4) a 15-participant user study demonstrating improved understanding, collaboration, and user-preferred behaviors for QuickLAP over baselines. Beyond driving, QuickLAP offers a general framework for preference learning in any domain where users can show and tell, from assistive robots to collaborative drones, enabling faster, more intuitive, and more personalized human-robot interaction.
Learning from Physical Human Feedback. Early work in IRL focus
This content is AI-processed based on open access ArXiv data.