FAST: Topology-Aware Frequency-Domain Distribution Matching for Coreset Selection
Reading time: 5 minute
...
📝 Original Info
Title: FAST: Topology-Aware Frequency-Domain Distribution Matching for Coreset Selection
ArXiv ID: 2511.19476
Date: 2025-11-22
Authors: ** - Jin Cui* (시안 자오통 대학교, State Key Laboratory of Human‑Machine Hybrid Augmented Intelligence) - Boran Zhao* (시안 자오통 대학교, School of Software Engineering) - Jiajun Xu (시안 자오통 대학교, School of Software Engineering) - Jiaqi Guo (난카이 대학교, School of Mathematical Sciences) - Shuo Guan (시안 자오통 대학교, School of Software Engineering) - Pengju Ren† (시안 자오통 대학교, State Key Laboratory of Human‑Machine Hybrid Augmented Intelligence) * 동등 기여, † 교신 저자 **
📝 Abstract
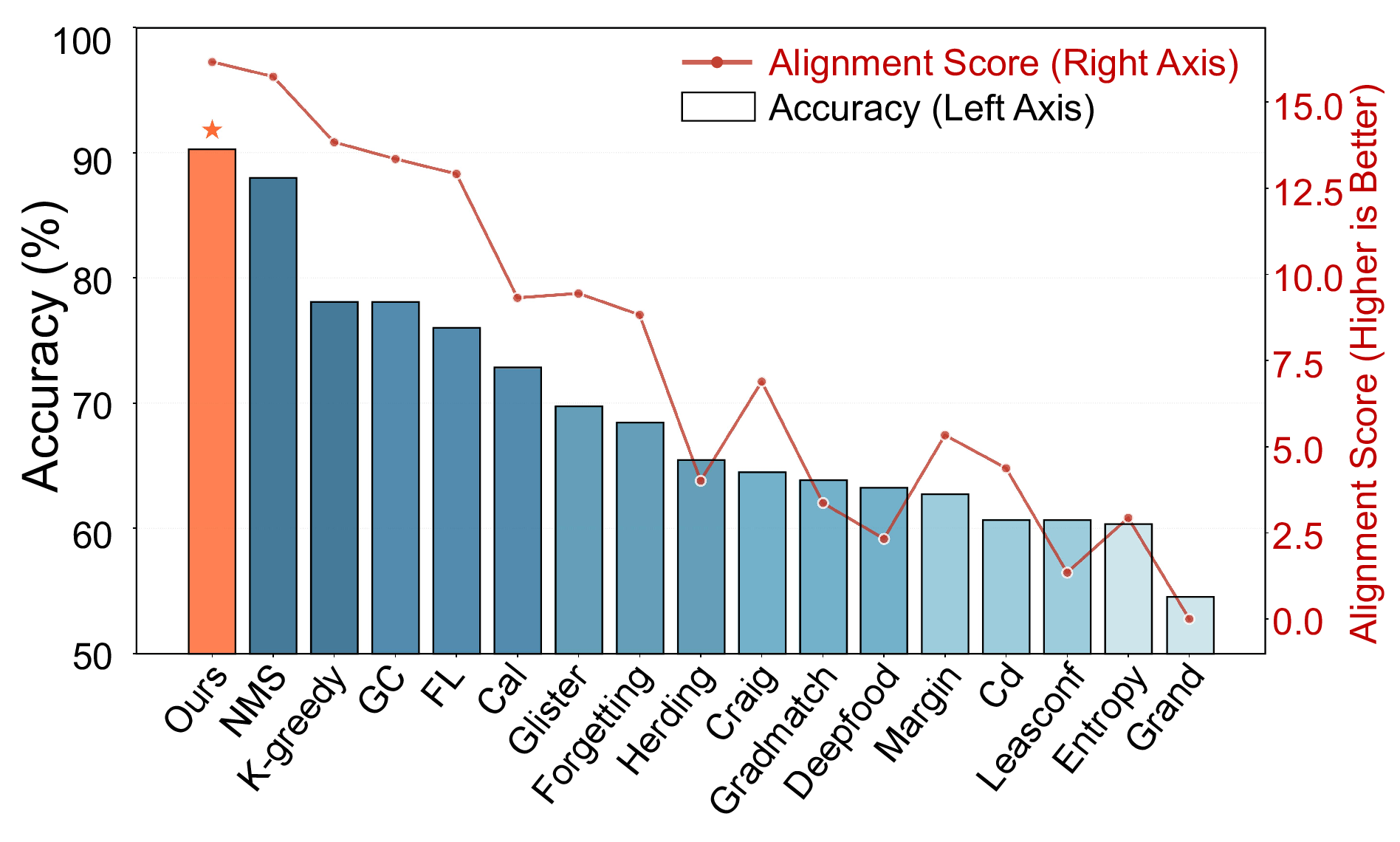
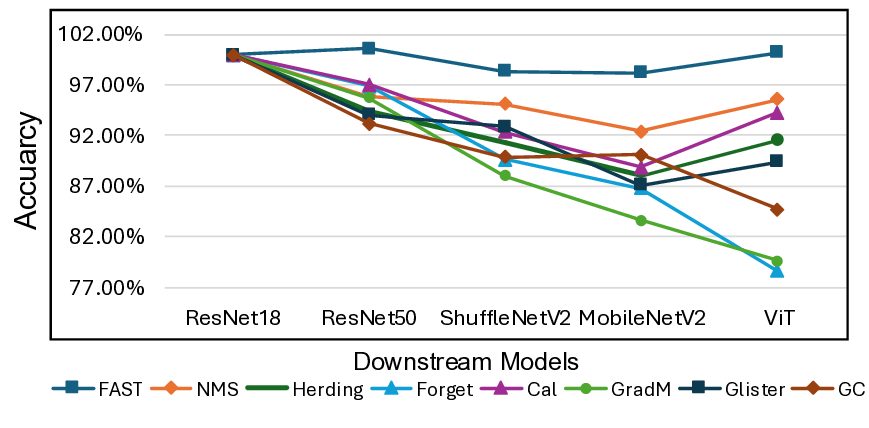
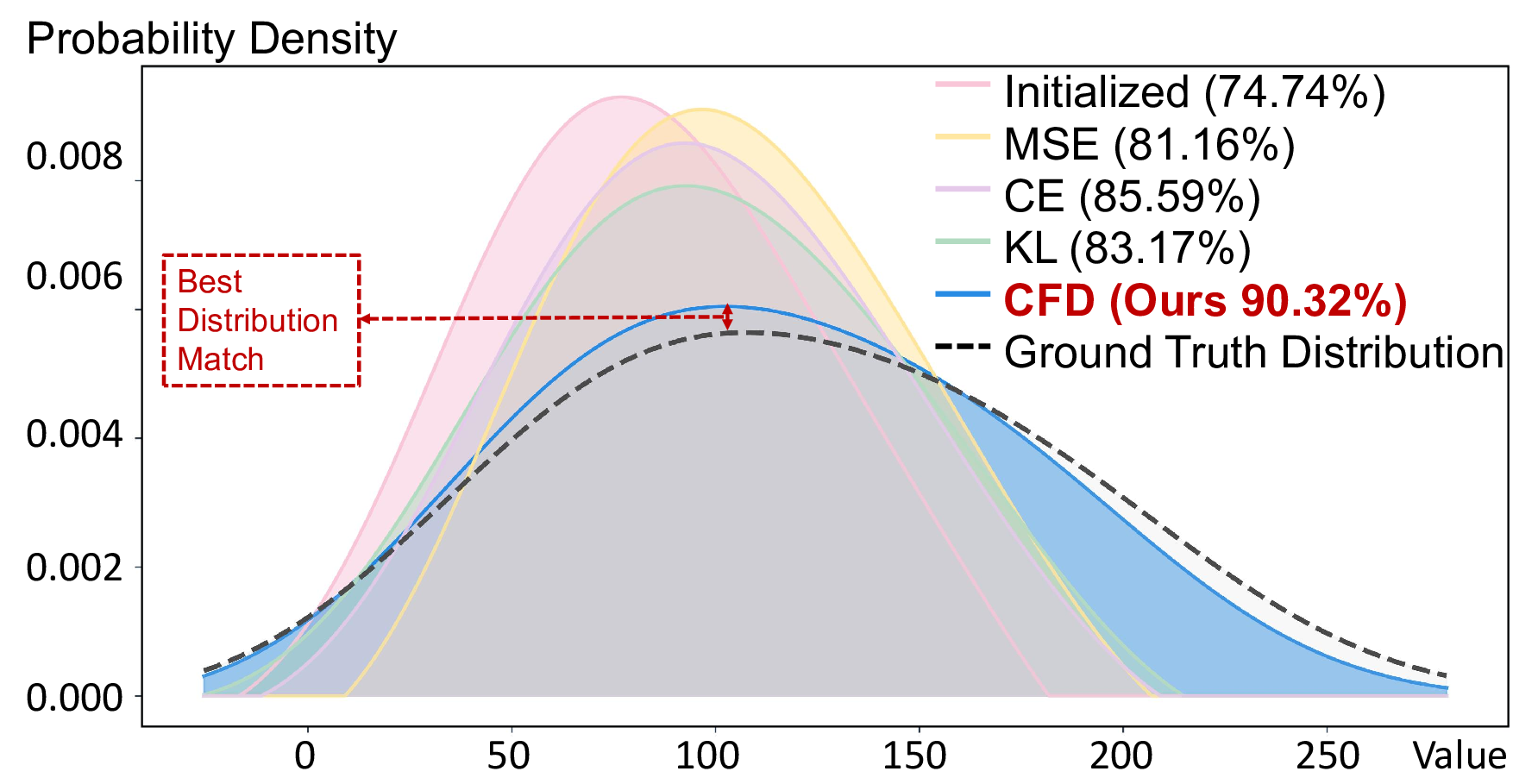
Coreset selection compresses large datasets into compact, representative subsets, reducing the energy and computational burden of training deep neural networks. Existing methods are either: (i) DNN-based, which are tied to model-specific parameters and introduce architectural bias; or (ii) DNN-free, which rely on heuristics lacking theoretical guarantees. Neither approach explicitly constrains distributional equivalence, largely because continuous distribution matching is considered inapplicable to discrete sampling. Moreover, prevalent metrics (e.g., MSE, KL, MMD, CE) cannot accurately capture higher-order moment discrepancies, leading to suboptimal coresets. In this work, we propose FAST, the first DNN-free distribution-matching coreset selection framework that formulates the coreset selection task as a graph-constrained optimization problem grounded in spectral graph theory and employs the Characteristic Function Distance (CFD) to capture full distributional information in the frequency domain. We further discover that naive CFD suffers from a "vanishing phase gradient" issue in medium and high-frequency regions; to address this, we introduce an Attenuated Phase-Decoupled CFD. Furthermore, for better convergence, we design a Progressive Discrepancy-Aware Sampling strategy that progressively schedules frequency selection from low to high, preserving global structure before refining local details and enabling accurate matching with fewer frequencies while avoiding overfitting. Extensive experiments demonstrate that FAST significantly outperforms state-of-the-art coreset selection methods across all evaluated benchmarks, achieving an average accuracy gain of 9.12%. Compared to other baseline coreset methods, it reduces power consumption by 96.57% and achieves a 2.2x average speedup, underscoring its high performance and energy efficiency.
💡 Deep Analysis
📄 Full Content
FAST: Topology-Aware Frequency-Domain Distribution Matching for Coreset
Selection
Jin Cui∗1, Boran Zhao∗2, Jiajun Xu2, Jiaqi Guo3, Shuo Guan2, Pengju Ren†1
1State Key Laboratory of Human-Machine Hybrid Augmented Intelligence,
National Engineering Research Center for Visual Information and Applications,
and Institute of Artificial Intelligence and Robotics, Xi’an Jiaotong University
2School of Software Engineering, Xi’an Jiaotong University
3School of Mathematical Sciences, Nankai University
andycui@stu.xjtu.edu.cn, {boranzhao, pengjuren}@xjtu.edu.cn
Abstract
Coreset selection compresses large datasets into compact,
representative subsets, reducing the energy and computa-
tional burden of training deep neural networks.
Exist-
ing methods are either: (i) DNN-based, which are inher-
ently coupled with network-specific parameters, inevitably
introducing architectural bias and compromising general-
ization; or (ii) DNN-free, which utilize heuristics that lack
rigorous theoretical guarantees for stability and accuracy.
Neither approach explicitly constrains distributional equiv-
alence of the representative subsets, largely because con-
tinuous distribution matching is broadly considered inap-
plicable to discrete dataset sampling. Furthermore, preva-
lent distribution metrics (e.g., MSE, KL, MMD, and CE) are
often incapable of accurately capturing higher-order mo-
ments differences. These deficiencies lead to suboptimal
coreset performance, preventing the selected coreset from
being truly equivalent to the original dataset.
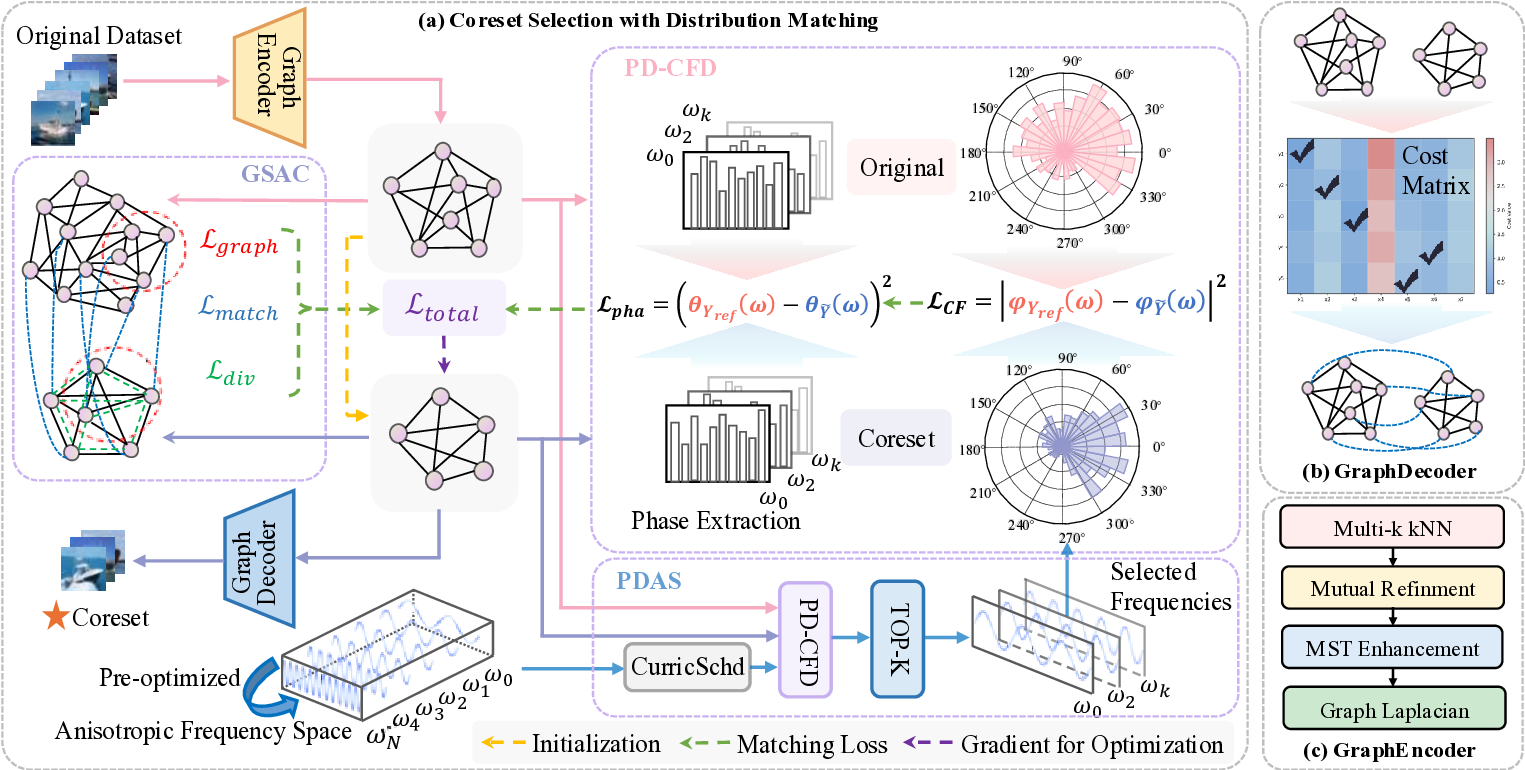
We propose FAST (Frequency-domain Aligned Sampling
via Topology), the first DNN-free distribution-matching
coreset selection framework that formulates coreset se-
lection task as a graph-constrained optimization problem
grounded in spectral graph theory and employs the Char-
acteristic Function Distance (CFD) to capture full distri-
butional information (i.e., all moments and intrinsic cor-
relations) in the frequency domain.
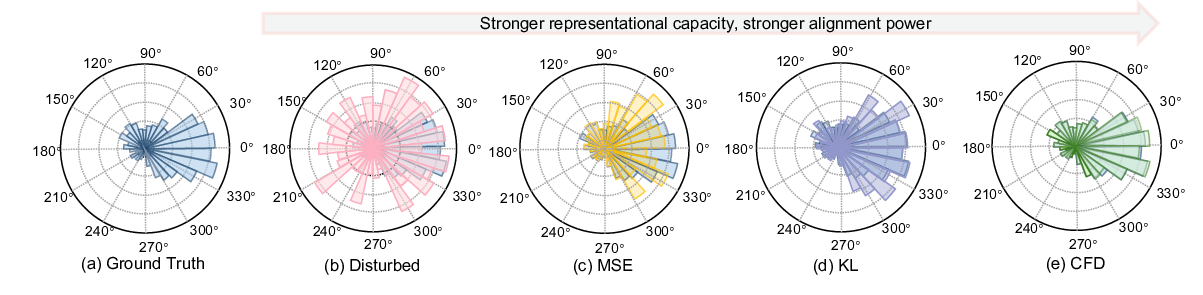
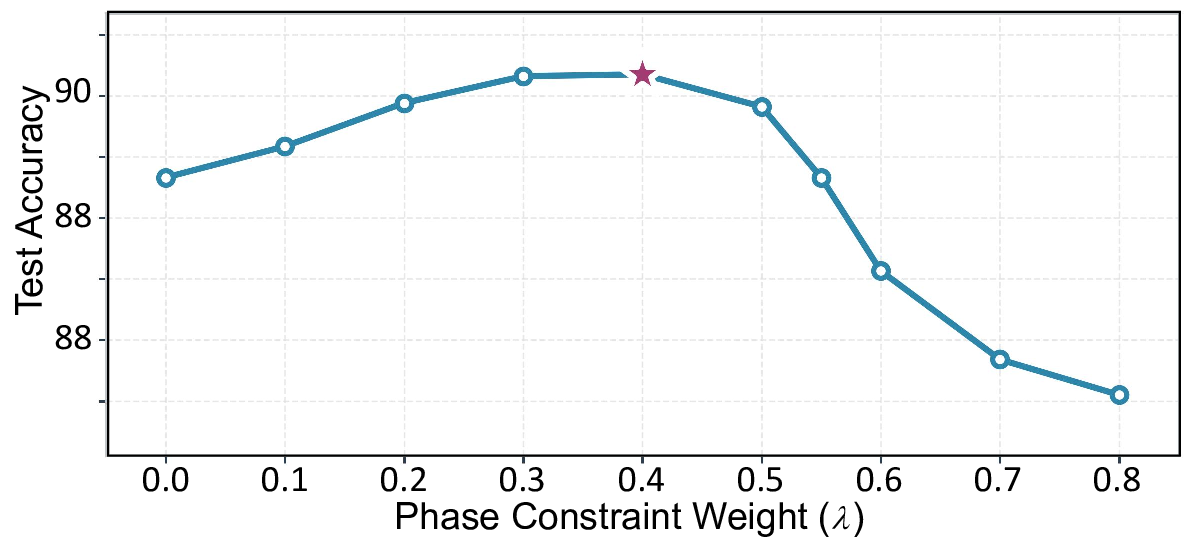
We further discover
that naive CFD suffers from a “vanishing phase gradi-
ent” issue in medium and high-frequency regions; to ad-
dress this, we introduce an Attenuated Phase-Decoupled
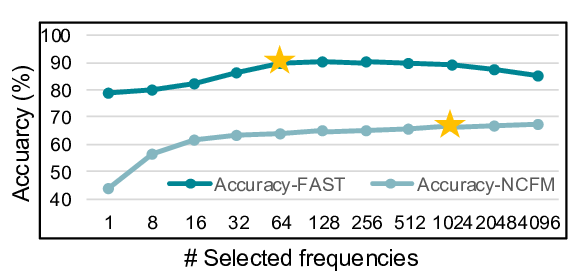
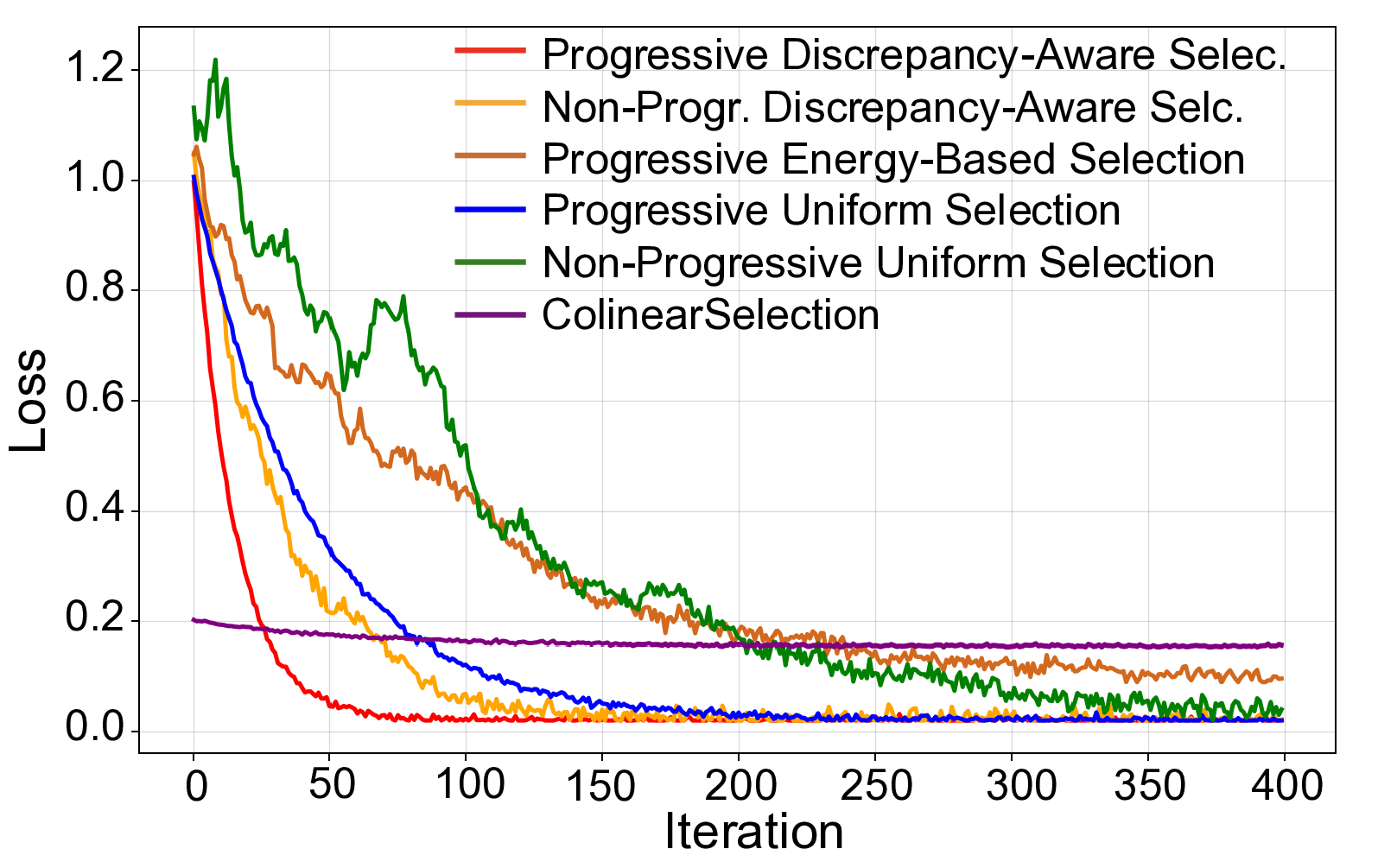
CFD. Furthermore, for better convergence, we design a
Progressive Discrepancy-Aware Sampling strategy that pro-
*Equal contribution.
†Corresponding author.
gressively schedules frequency selection from low to high.
This preserves global structure before refining local details,
enabling accurate matching with few frequencies while pre-
venting overfitting. Extensive experiments demonstrate that
FAST significantly outperforms state-of-the-art coreset se-
lection methods across all evaluated benchmarks, achiev-
ing an average accuracy gain of 9.12%. Compared to other
baseline coreset methods, it reduces power consumption by
96.57% and achieves a 2.2× average speedup even on CPU
with 1.7GB of memory, underscoring its high performance
and energy efficiency.
1. Introduction
Deep Neural Networks (DNNs) have achieved—and in
some cases even surpassed—human-level performance
across diverse domains such as vision [5, 12, 26], program-
ming [7, 24, 31], and science [18, 28]. This remarkable
success is primarily driven by the availability of massive
training datasets [15, 25, 35]. However, training on such
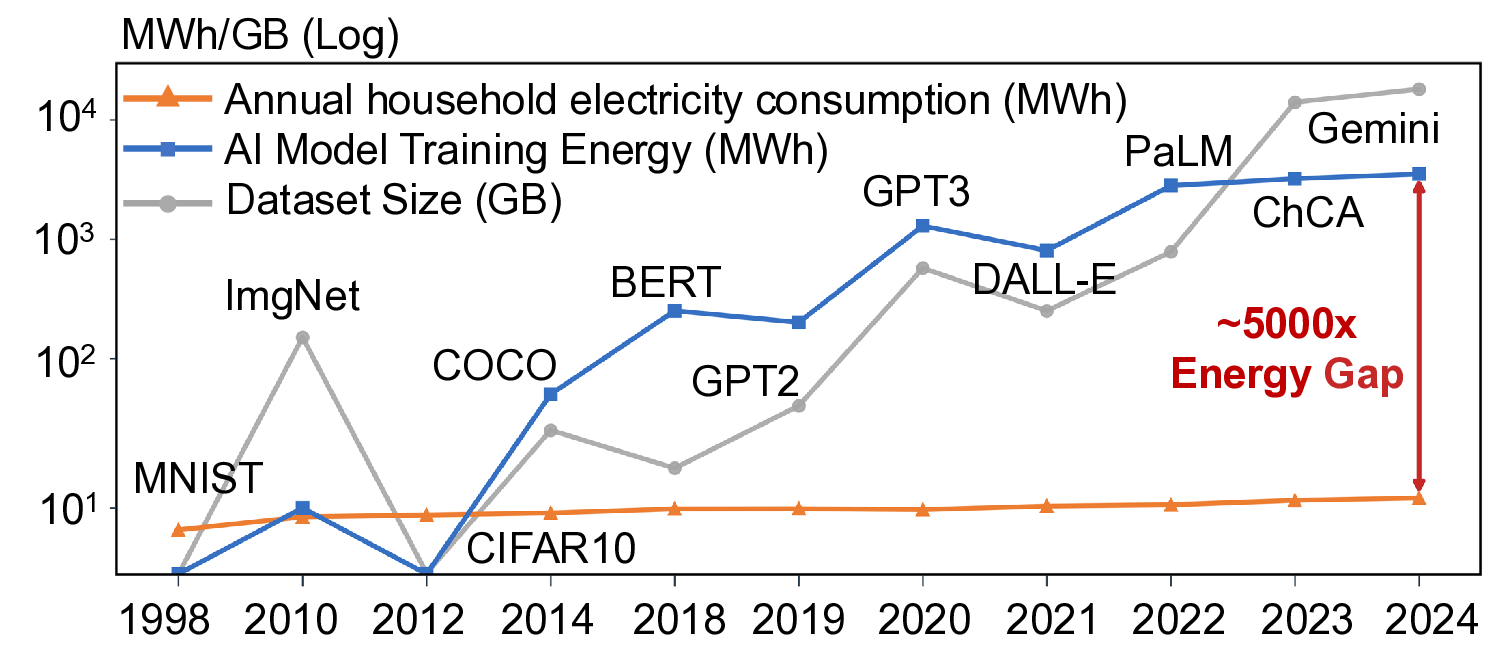
large-scale data incurs prohibitive energy costs, as illus-
trated in Fig. 1, the total energy consumption can reach up to
103 MWh, exceeding the annual electricity usage of numer-
ous households by several orders of magnitude. To mitigate
this challenge, a variety of dataset compression techniques
have been proposed to condense large-scale datasets into
compact yet representative subsets [17, 41, 45, 46]. These
methods have found widespread adoption in tasks such as
neural architecture search, continual learning [33, 43], and
transfer learning [23].
Among existing compression techniques, coreset selec-
tion [17, 19, 29] offers superior efficiency over synthesis-
based distillation [41, 45, 46] by avoiding computationally
intensive nested gradient descent, making it ideal for on-
device deployment. Furthermore, it preserves the fidelity of
data and mitigates the failure modes of synthesis methods,
1
arXiv:2511.19476v1 [stat.ML] 22 Nov 2025
Annual household electricity consumption (MWh)
AI Model Training Energy (MWh)
Dataset Size (GB)
MWh/GB (Log)
ImgNet
MNIST
CIFAR10
COCO
1998 2010 2012
2014
2018 2019 2020
2021 2022
2023 2024
BERT
DALL-E
GPT2
GPT3
PaLM
ChCA
Gemini
101
102
103
104
~5000x
Energy Gap
Figure 1. The energy consumption of training exceeds the an-
nual electricity usage of numerous households by several orders
of magnitude.
which often struggle to generate highly discriminative sam-
ples for classification tasks with high inter-class similarity.
Existing coreset selection methods can be broadly cate-
gorized into two paradigms: (i) DNN-based approaches that
adopt a proxy DNN to evaluate each sample’s contribution
to training performance. While effective, these methods are
intrinsica