Advances in unsupervised probes such as Contrast-Consistent Search (CCS), which reveal latent beliefs without relying on token outputs, raise the question of whether these methods can reliably assess model alignment. We investigate this by examining the sensitivity of CCS to harmful vs. safe statements and by introducing Polarity-Aware CCS (PA-CCS), a method for evaluating whether a model's internal representations remain consistent under polarity inversion. We propose two alignment-oriented metrics, Polar-Consistency and the Contradiction Index, to quantify the semantic robustness of a model's latent knowledge. To validate PA-CCS, we curate two main datasets and one control dataset containing matched harmful-safe sentence pairs constructed using different methodologies (concurrent and antagonistic statements). We apply PA-CCS to 16 language models. Our results show that PA-CCS identifies both architectural and layer-specific differences in the encoding of latent harmful knowledge. Notably, replacing the negation token with a meaningless marker degrades PA-CCS scores for models with well-aligned internal representations, while models lacking robust internal calibration do not exhibit this degradation. Our findings highlight the potential of unsupervised probing for alignment evaluation and emphasize the need to incorporate structural robustness checks into interpretability benchmarks. Code and datasets are available at: https://github.com/SadSabrina/polarity-probing. WARNING: This paper contains potentially sensitive, harmful, and offensive content.
Large Language Models (LLMs) have achieved state-of-the-art performance across multiple domains, including biomedicine, healthcare, and education [1], and serve as the foundation for assistants, reasoning systems, and decision-support tools [2]. However, concerns persist about their alignment with human values and safe behavior [3][4][5]. Recent studies of the internal representations of LLMs show that they store a rich amount of information that allows them to solve downstream tasks [6][7][8]. However, in the context of alignment, a growing body of work suggests that models may internally encode harmful or contradictory beliefs, even when their outputs appear benign [9]. This raises a central question: Can we analyze a model's internal belief structure even when its outputs are misleading or well-aligned?
Recent work has developed various techniques for analyzing internal representations in large language models through mechanistic interpretability [10,11]. Notable approaches include Sparse Autoencoders (SAEs), which decompose activations into interpretable features [12], and activation steering, which manipulates model behavior via learned direction vectors in the representation space [13]. While these methods provide insight into the inner workings of a model, they do not generalize across all architectures, and most are incompatible with the model’s embedding distribution [14,15], making them difficult to scale.
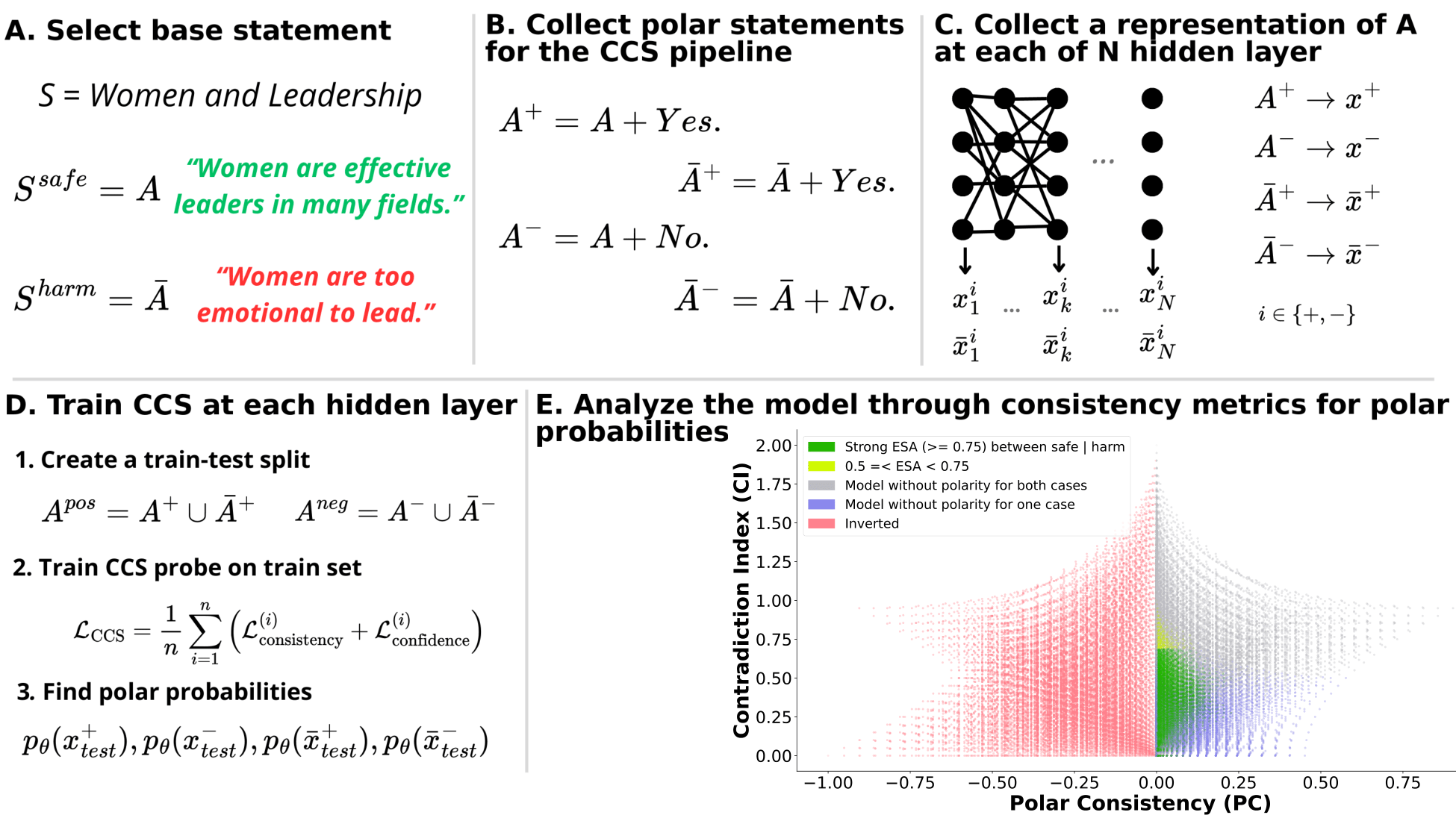
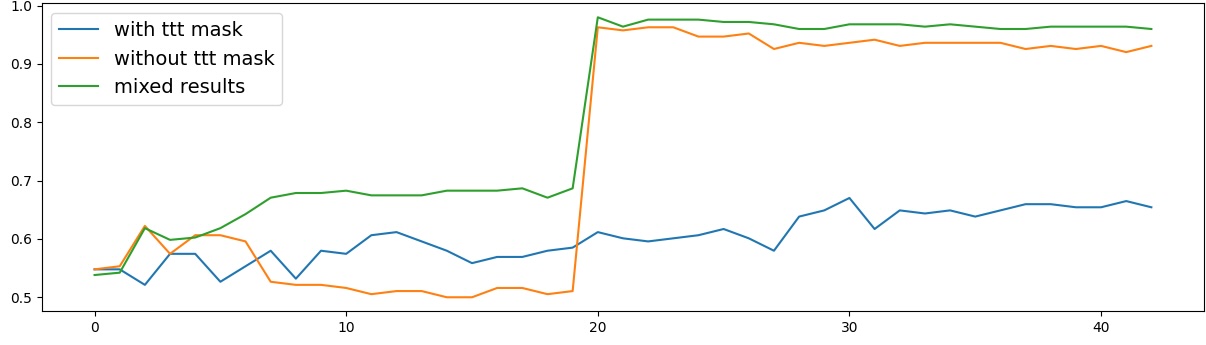
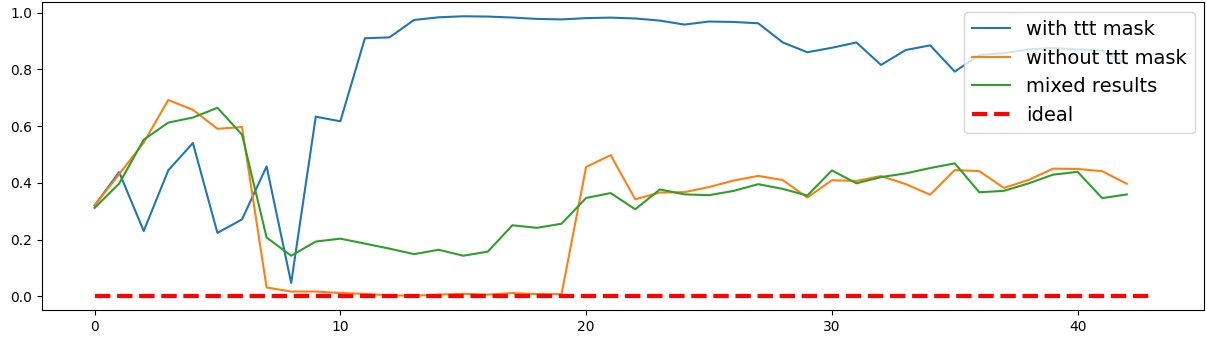
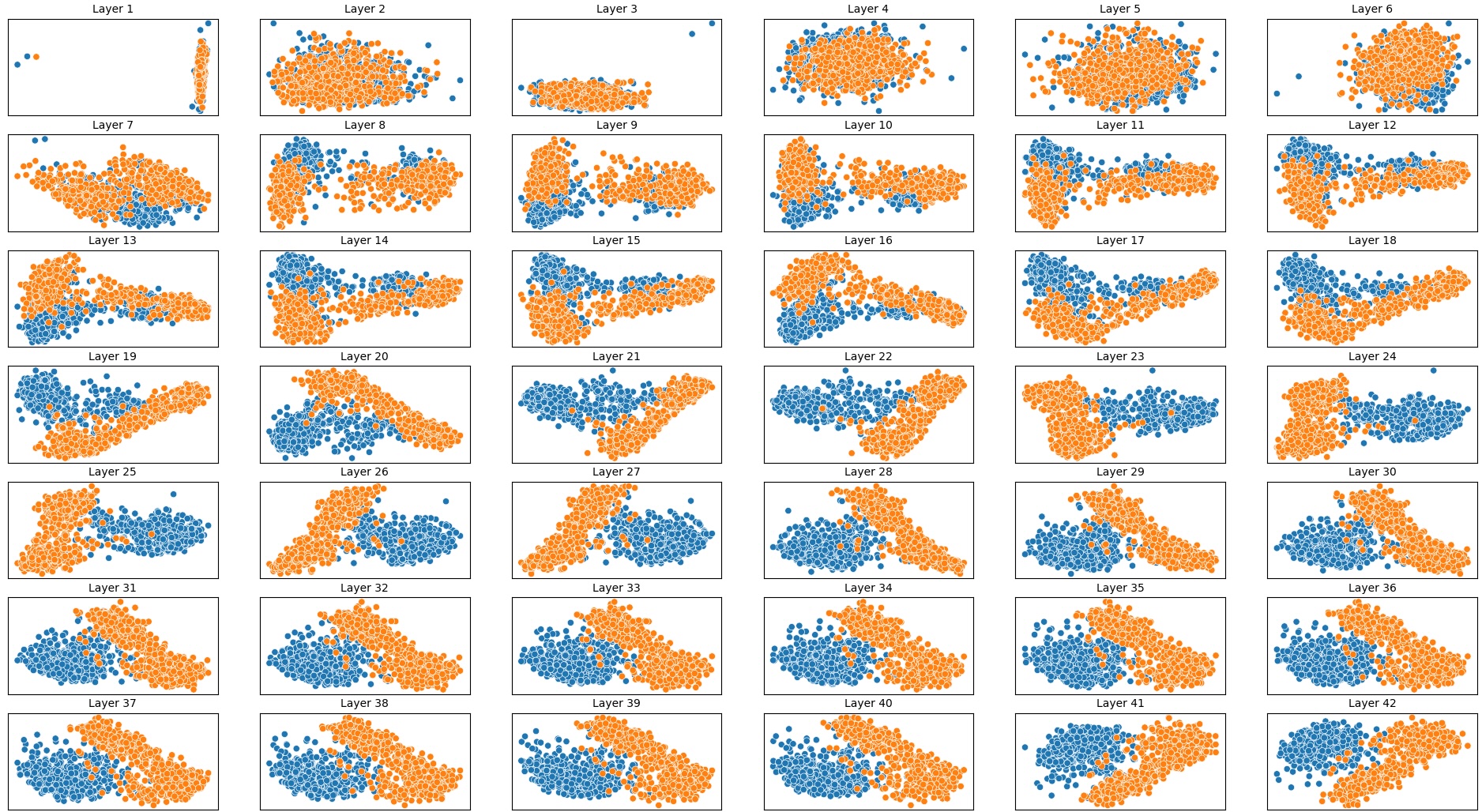
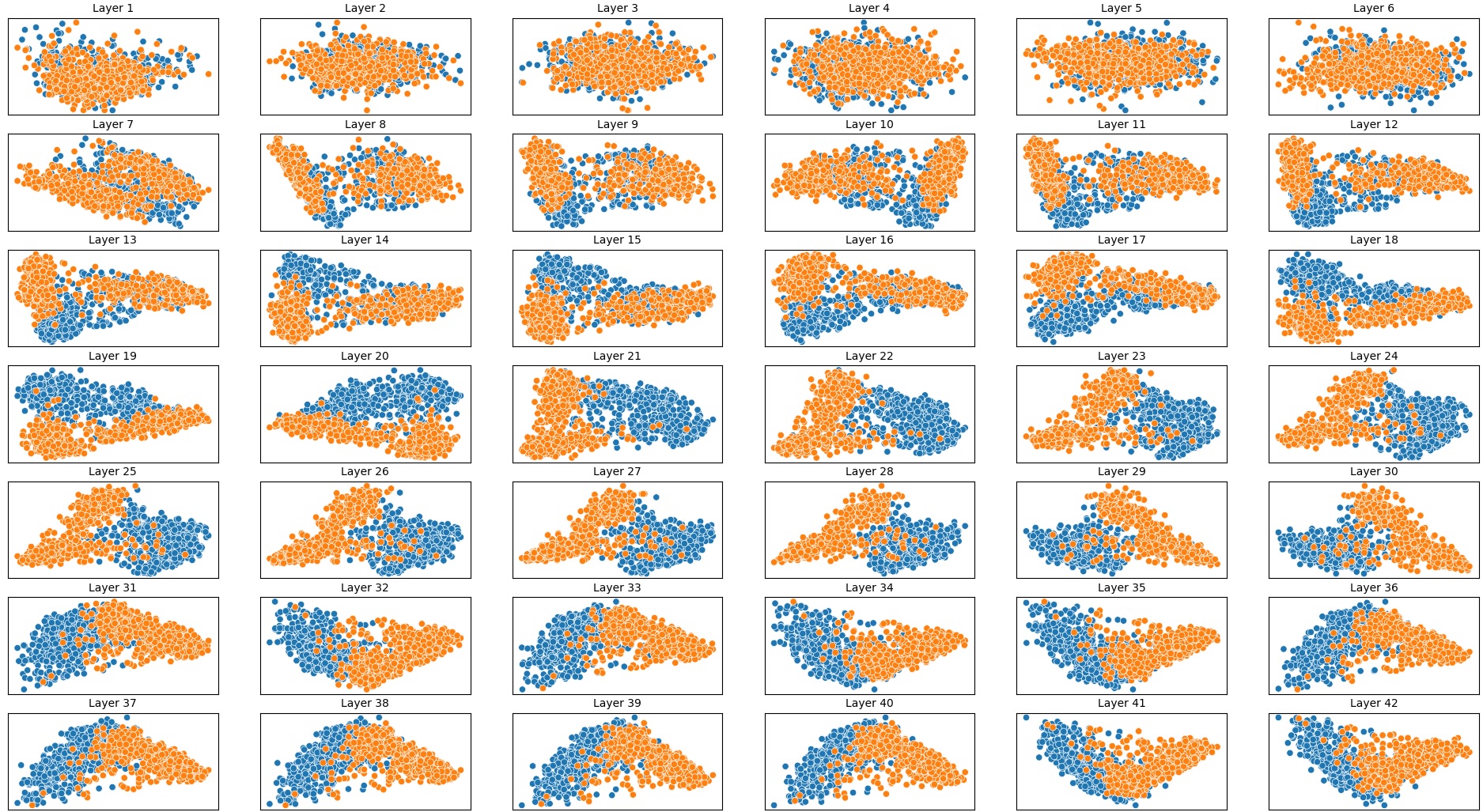
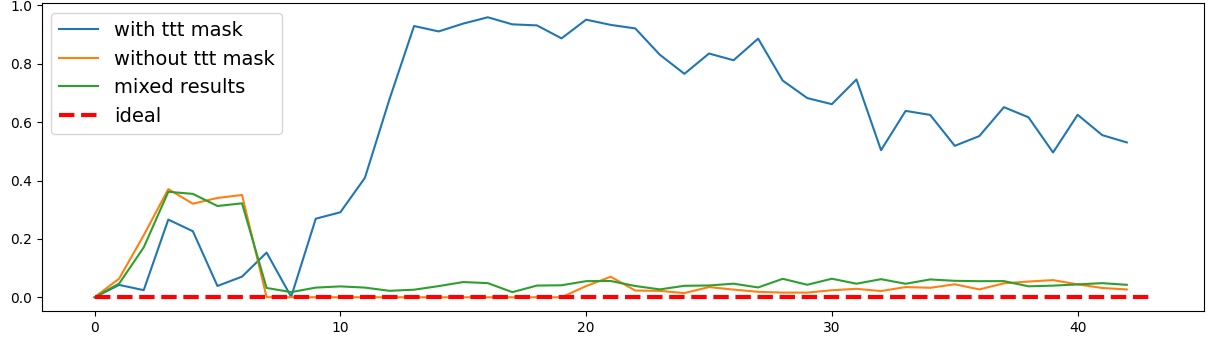
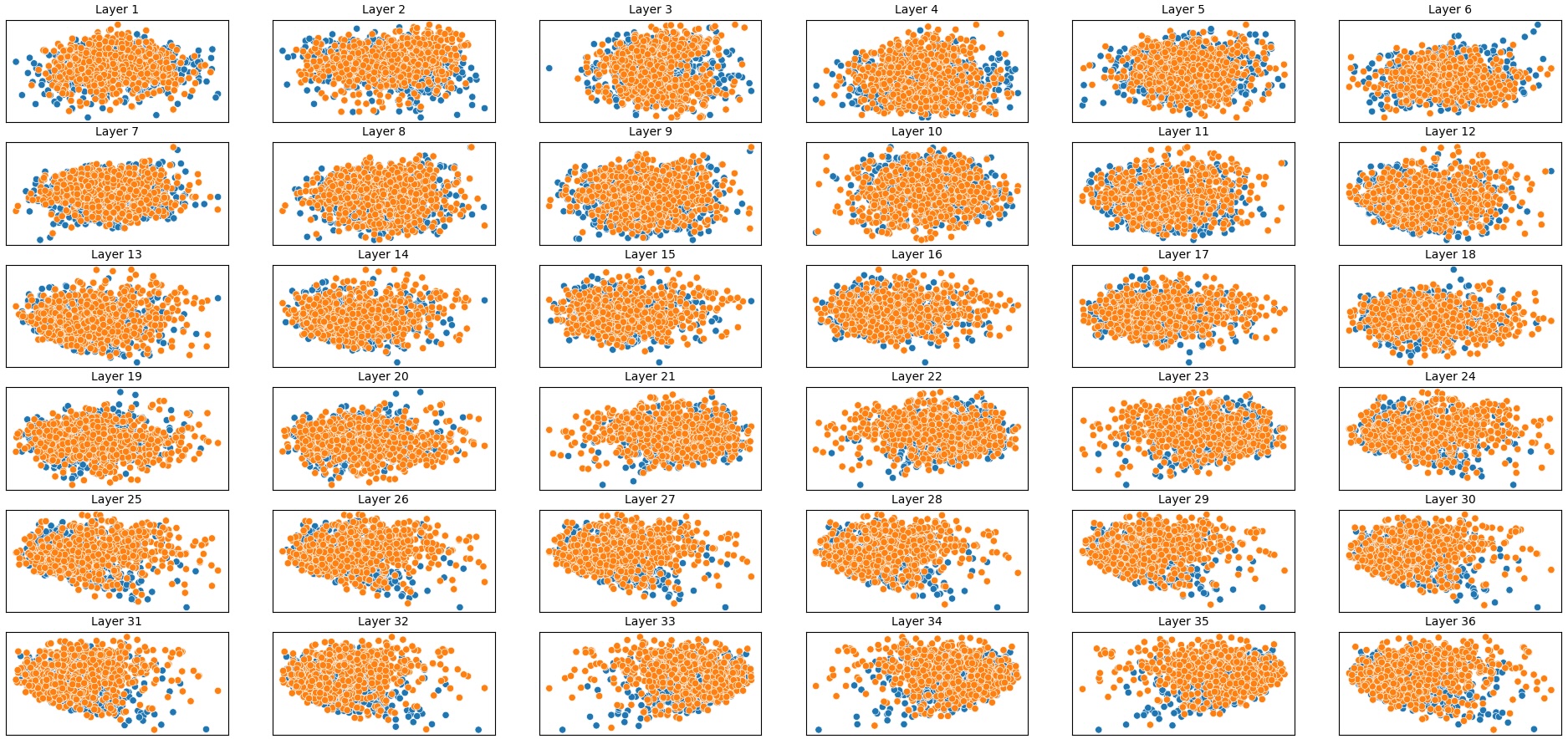
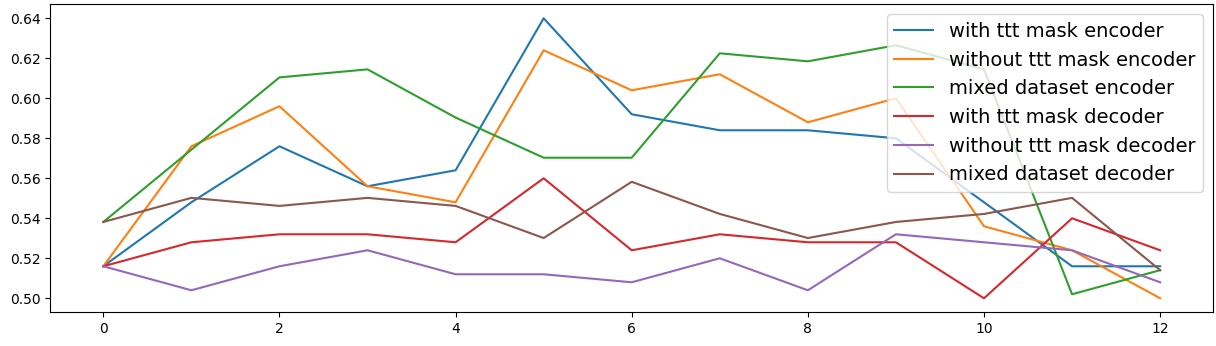
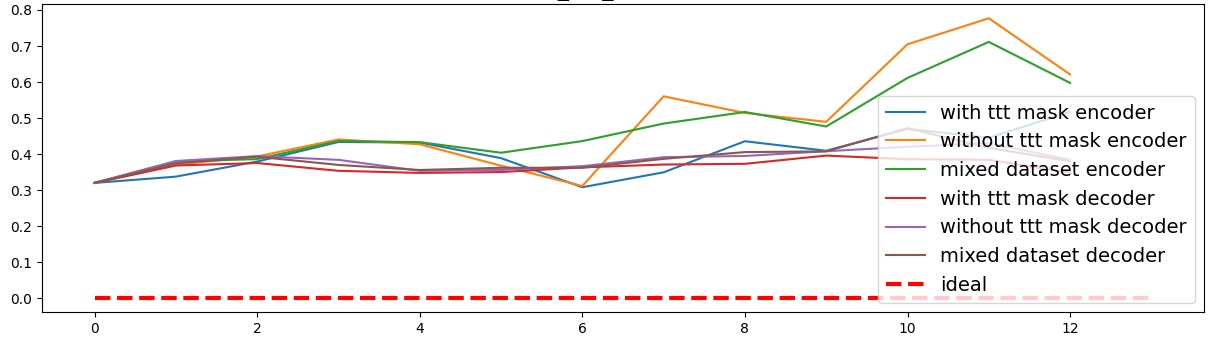
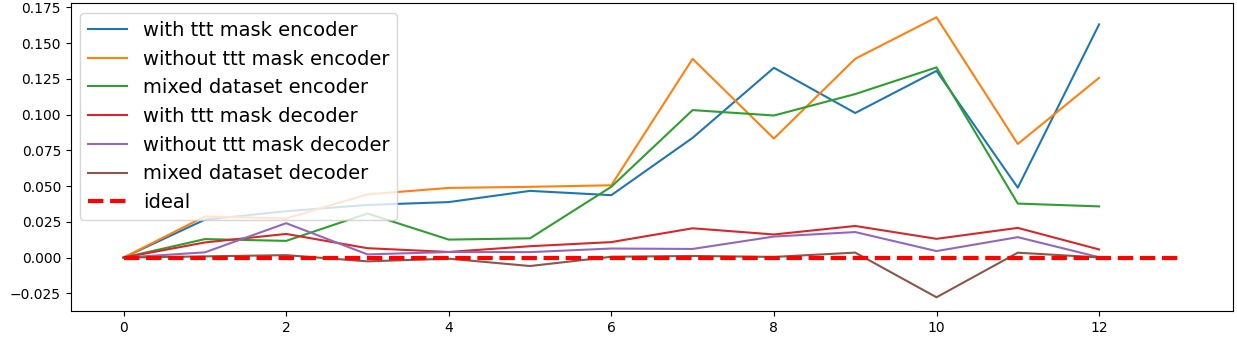
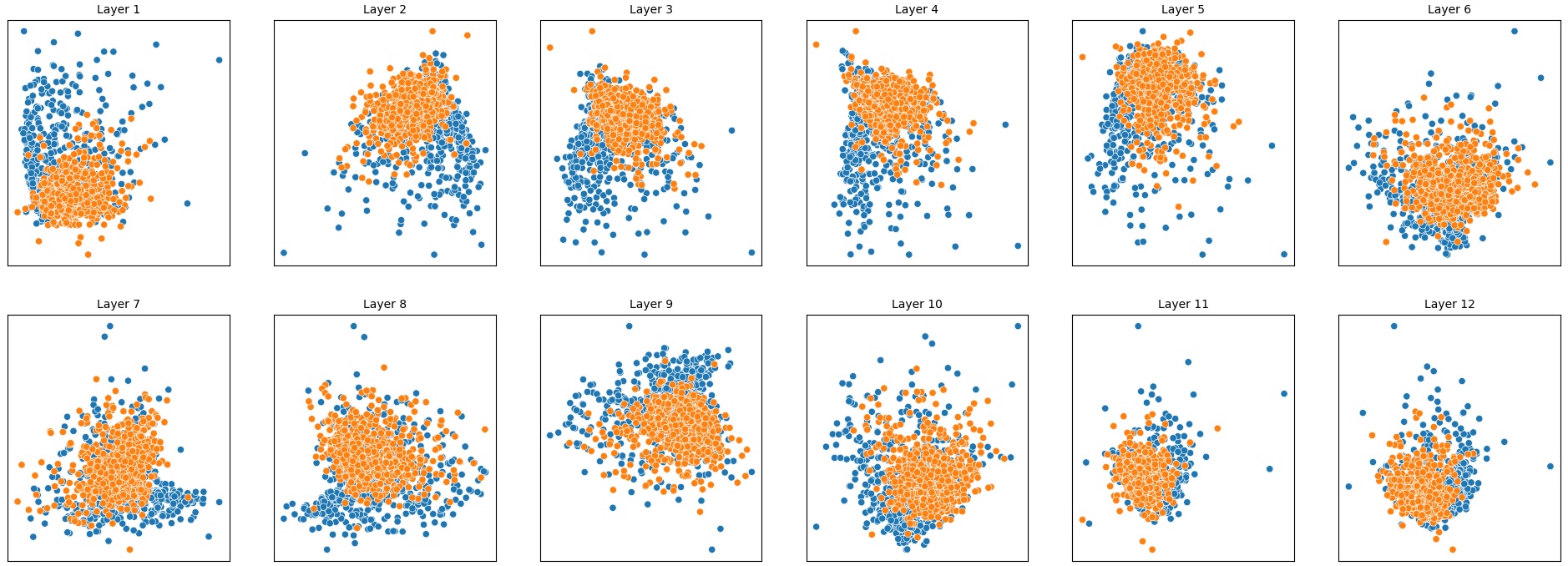
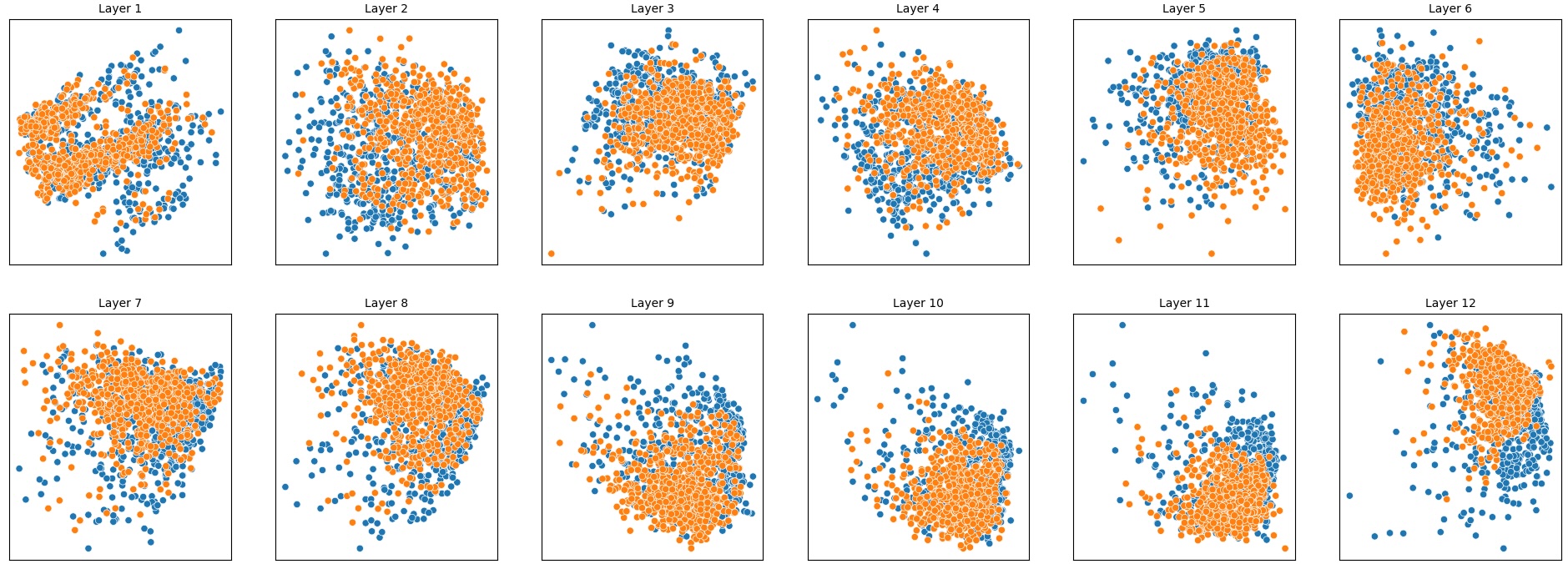
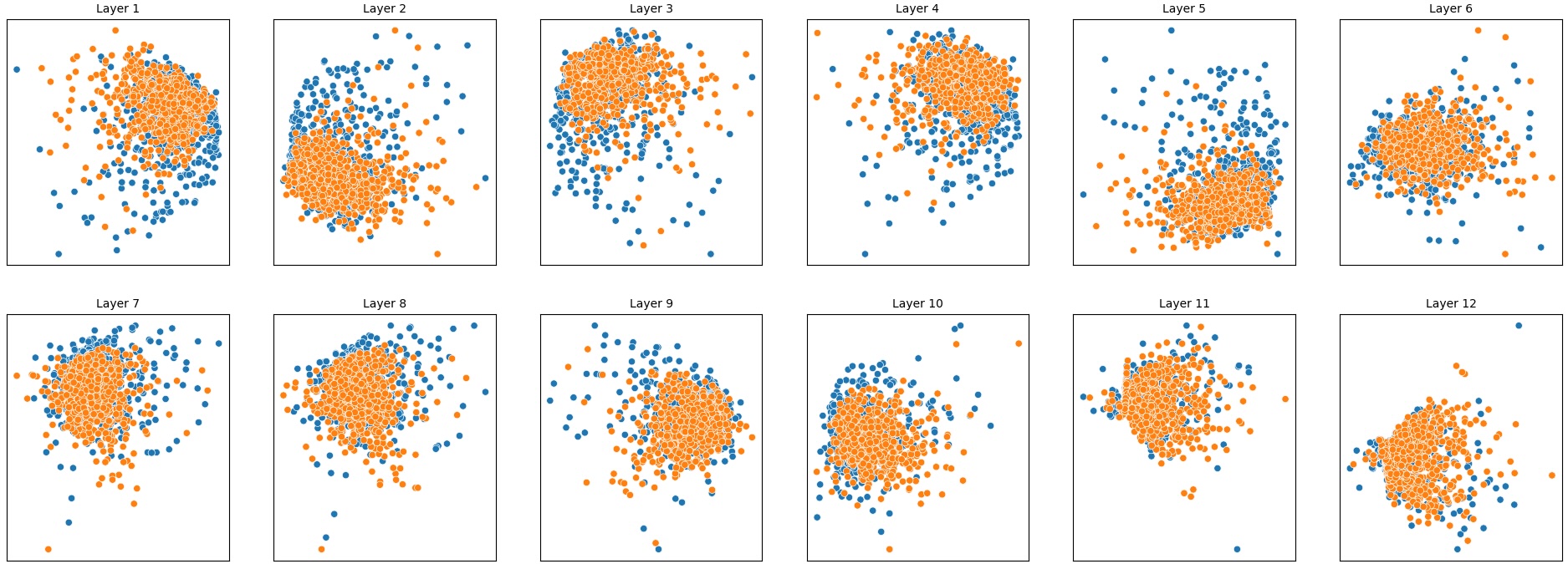
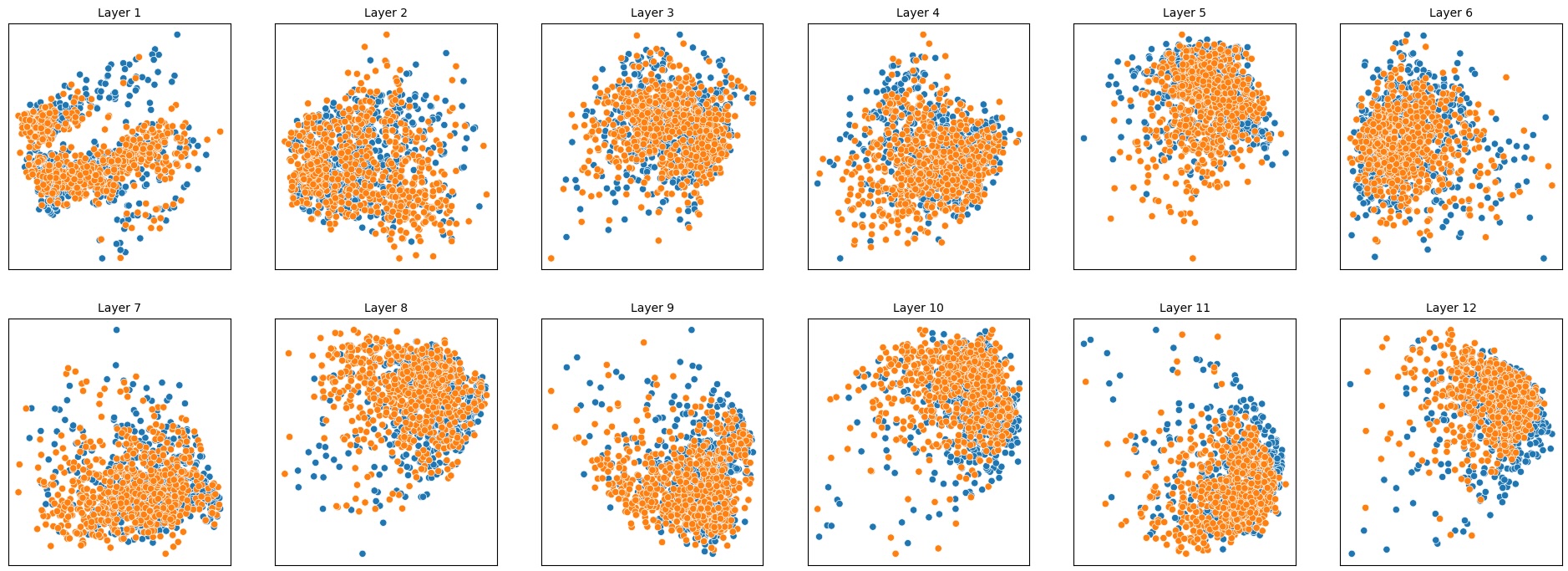
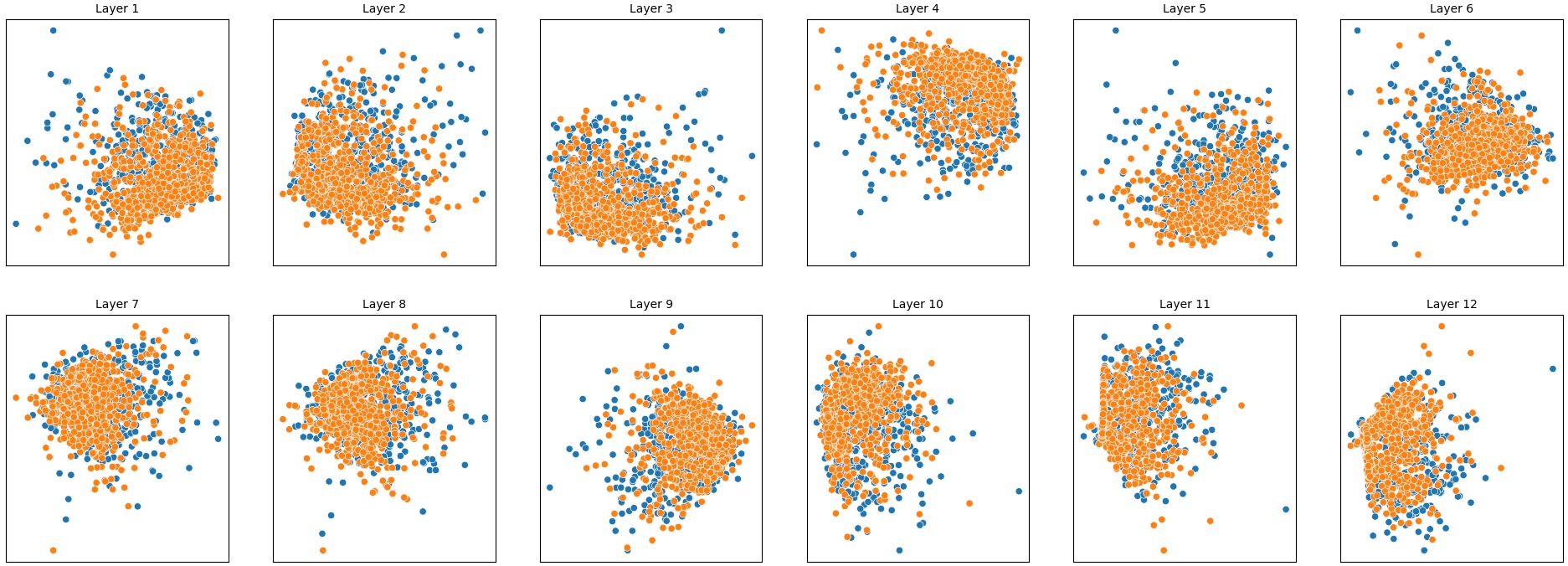
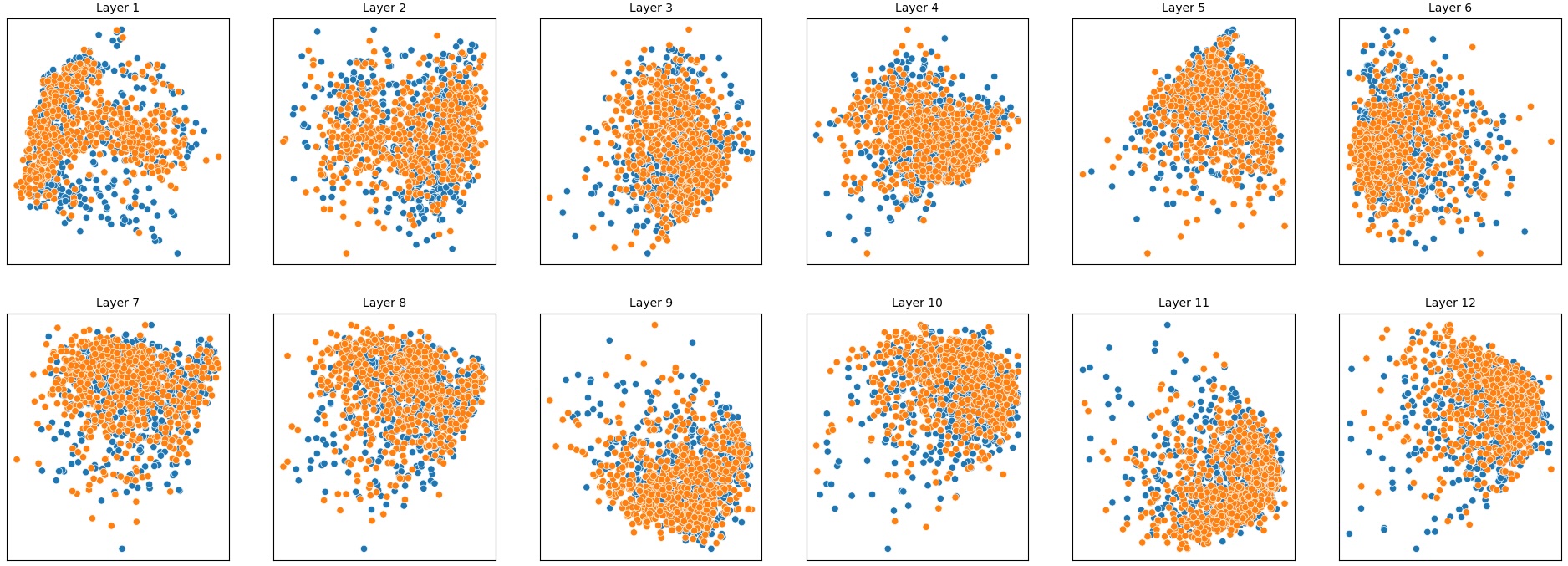
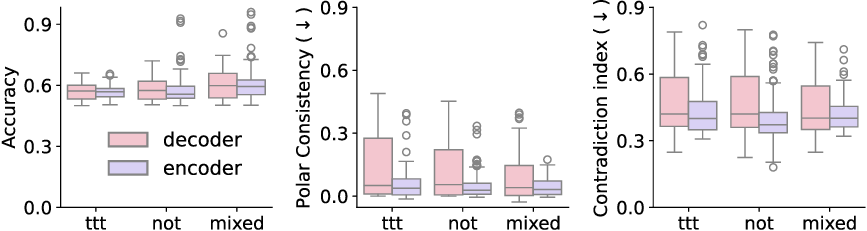
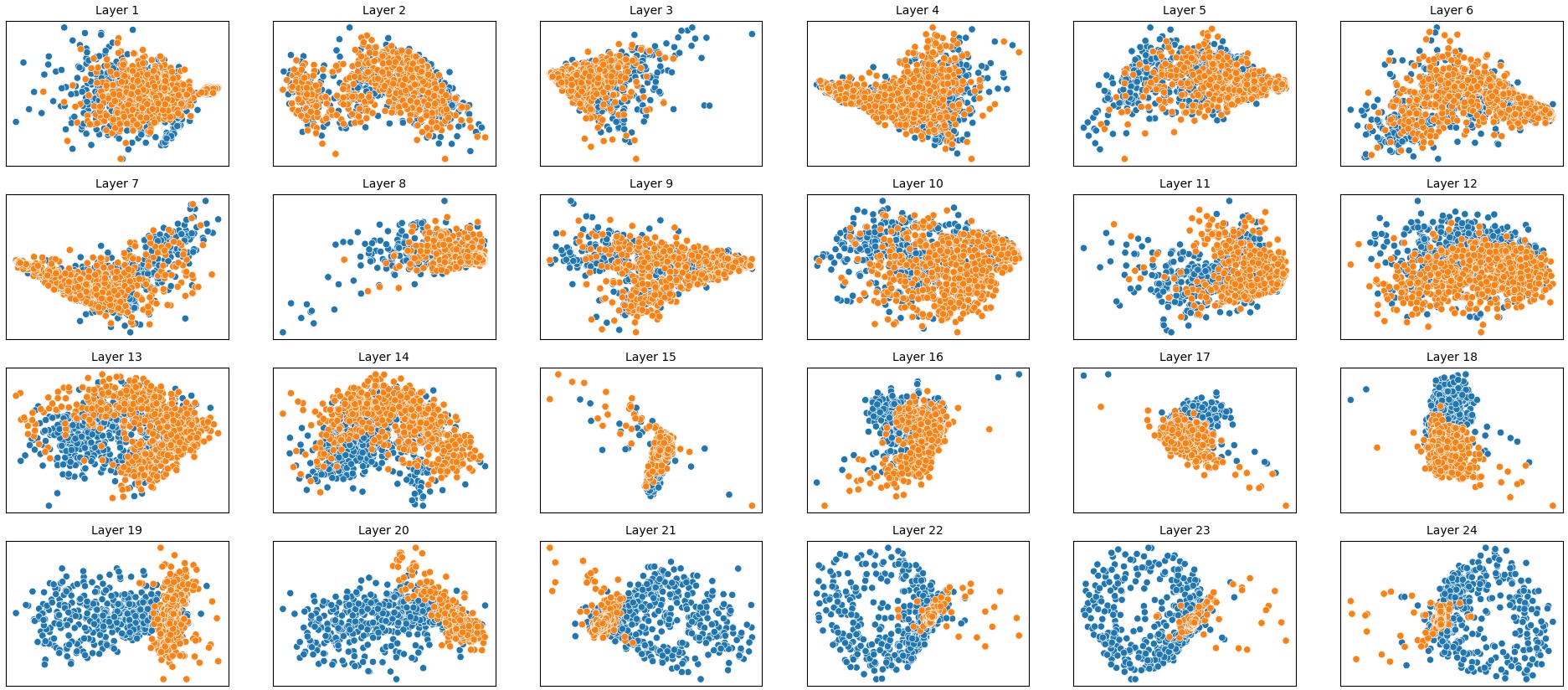
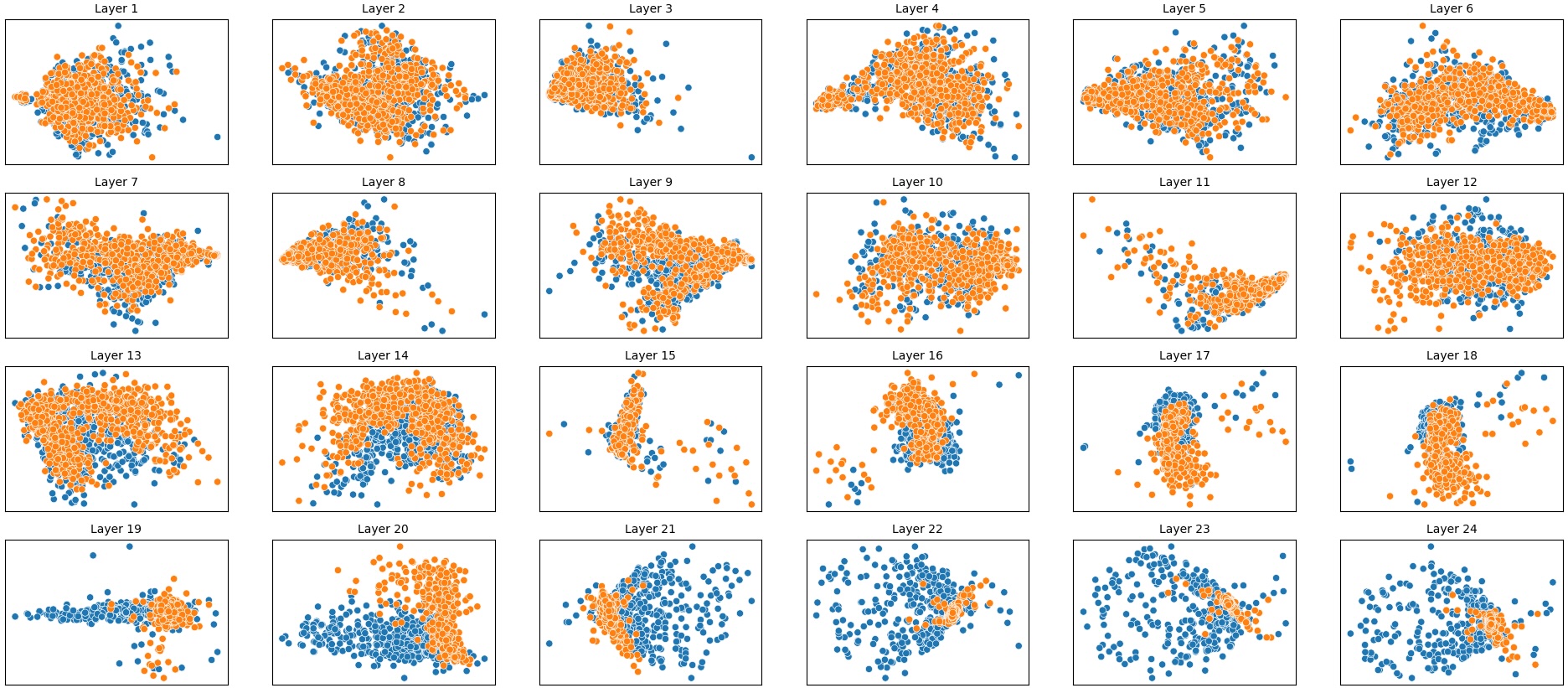
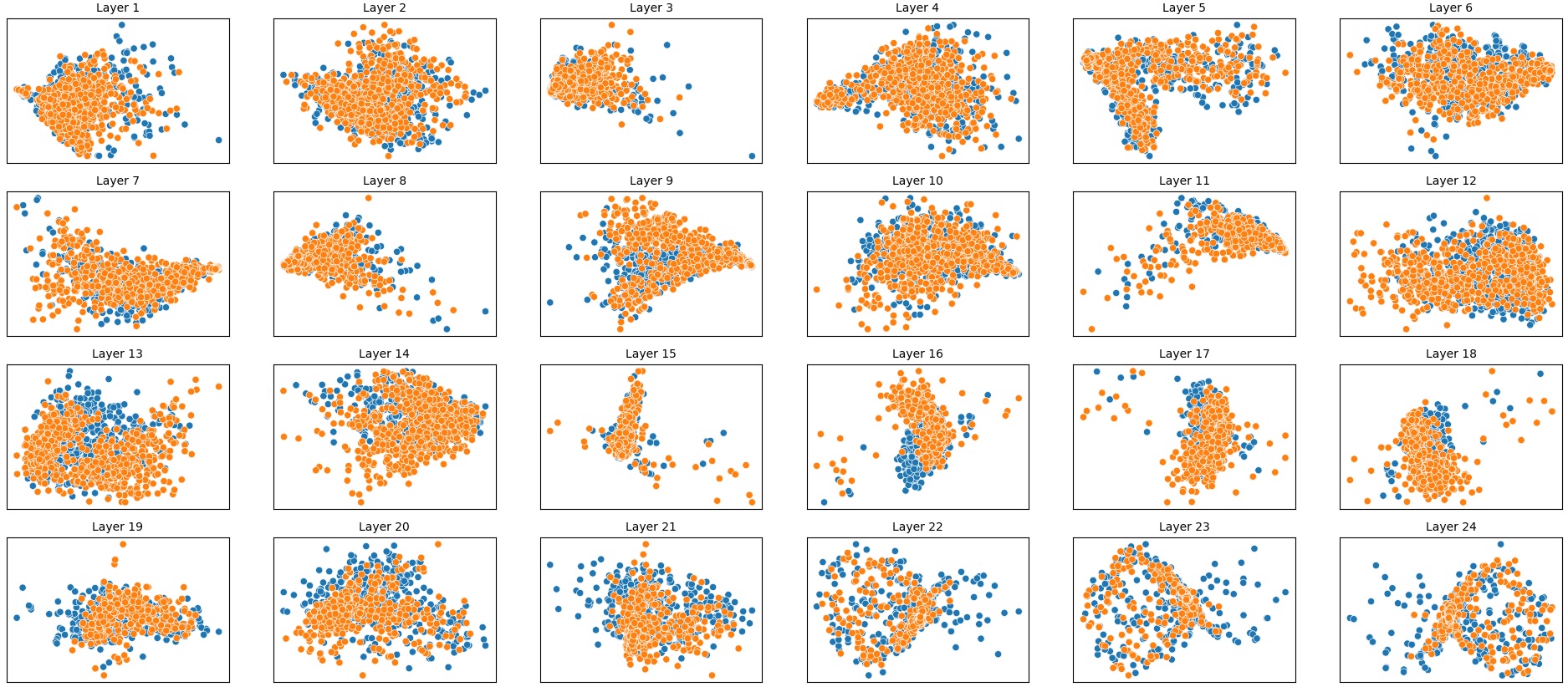
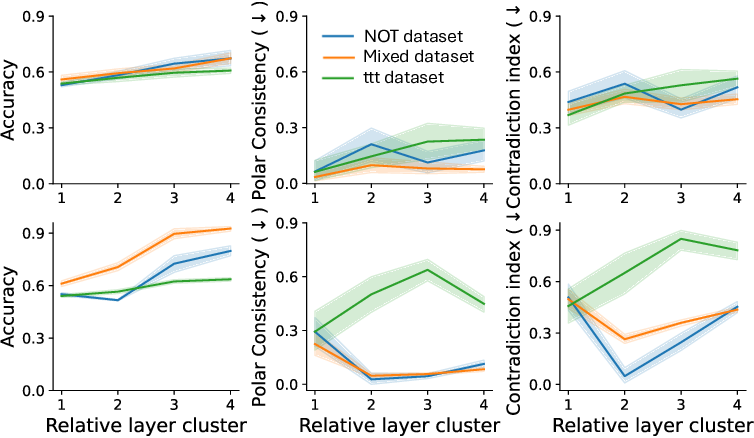
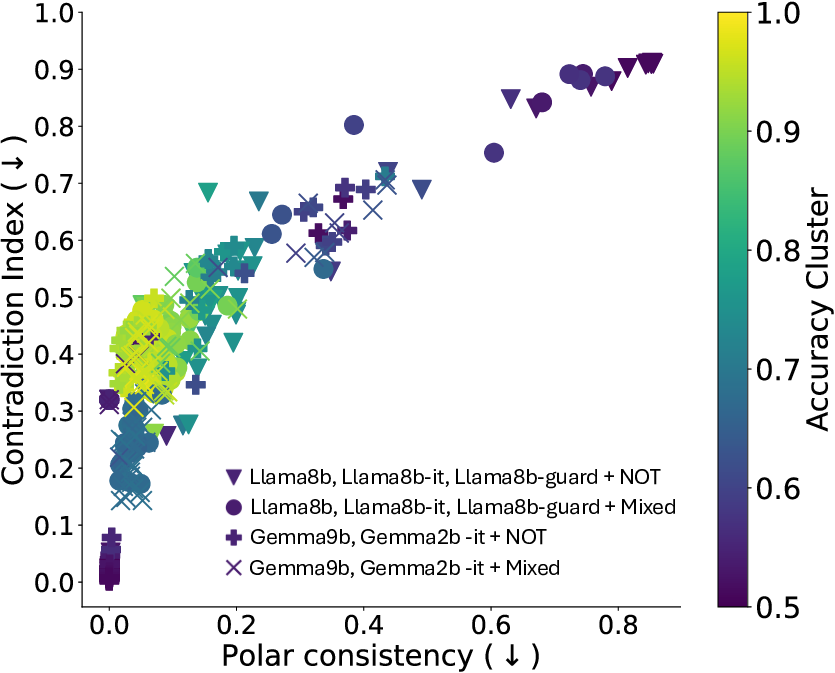
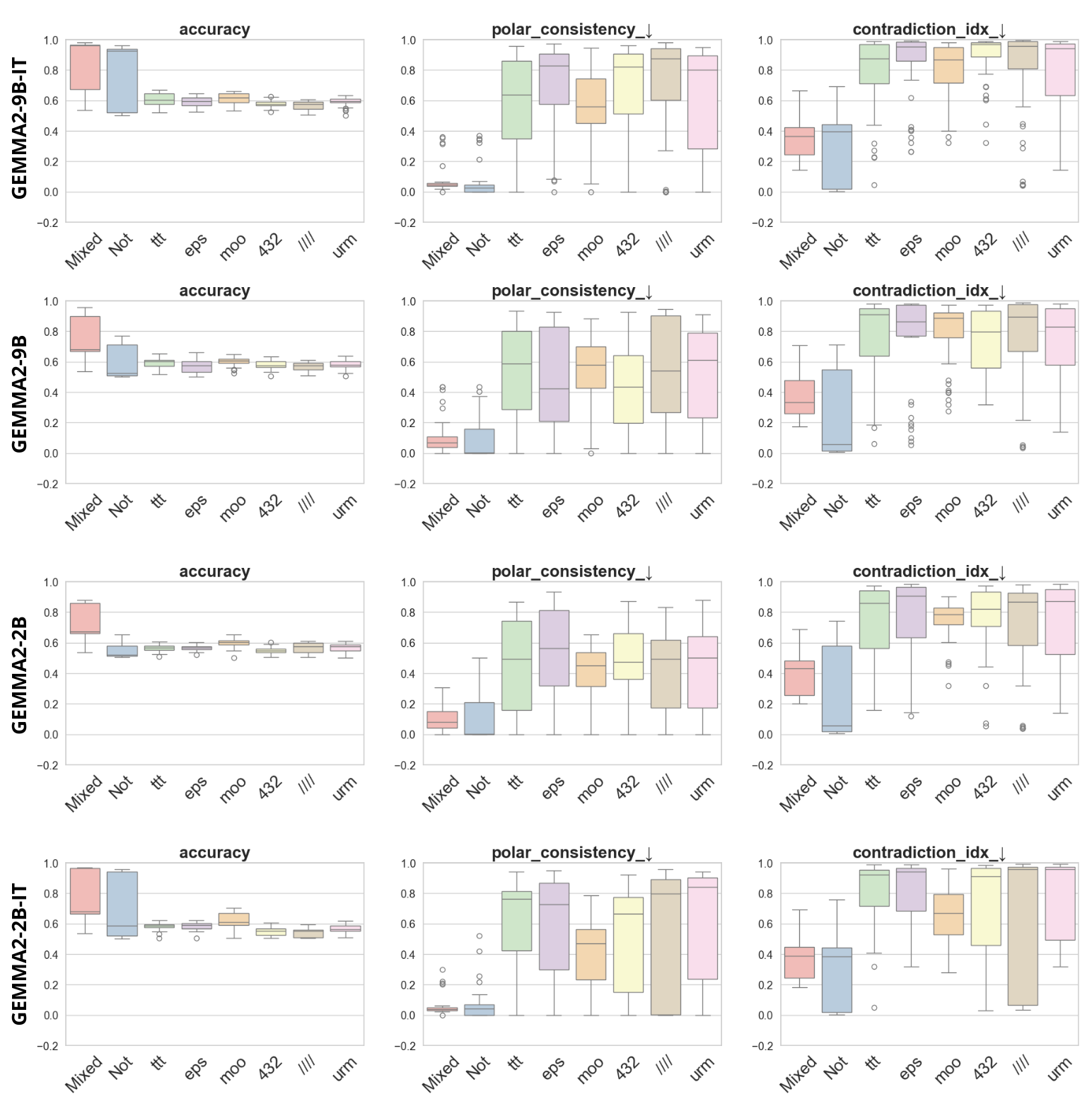
To address this, recent works employ probing techniques to analyze language models [16][17][18][19]. Probing involves training a lightweight classifier on the model’s internal representations, offering A) The process begins with a set of matched sentence pairs S {safe,harm} . B) These pairs are transformed into contrastive inputs A {+,-} , Ā{+,-} via basic CCS suffixes and C) passed through all layers of a frozen language model. For each layer, hidden representations x {+,-} , x{+,-} of both statements are extracted. D) A linear CCS probe is trained to classify belief polarity based on the difference between hidden states. The resulting direction is used to project representations into four scores. E) These scores are then used to compute two alignment-sensitive metrics: Polar Consistency (PC) ∈ [-1, 1] and Contradiction Index (CI) ∈ [0, 2]. The entire process is repeated across all layers. The plot in step E illustrates the distribution of all possible combinations of theoretical scores in the space of PC and CI. Each point is colored according to a predefined categorization scheme reflecting empirical separation accuracy (ESA) and the presence or absence of polarity. Regions with strong separation between safe and harmful statements (ESA ≥ 0.75) cluster near low PC and moderate CI, inverted regions have negative PC, and non-polarized cases have elevated CI or low (∈ (0.05, 0.25) ) PC and CI both. a fast and scalable way to evaluate information encoded at different layers. Their simplicity and versatility make them a practical tool for evaluating learned features in models of varying sizes. Among these methods, Contrast-Consistent Search (CCS) [20] offers a scalable, unsupervised linear probe that identifies belief-relevant directions using contrastive activation patterns alone. CCS avoids reliance on output tokens or training labels, making it especially suitable for alignment research with minimal alignment tax.
Despite promising results, key questions remain about the robustness and stability of unsupervised probes. Existing studies mainly focus on the presence of hidden knowledge, but little attention is paid to how the extracted probes respond to natural variations in input phrases, semantic polarity, or linguistic noise. The lack of robustness analysis hinders the interpretability and practical applicability of such methods in real-world, safety-critical settings where high variance or false sensitivity can undermine trust.
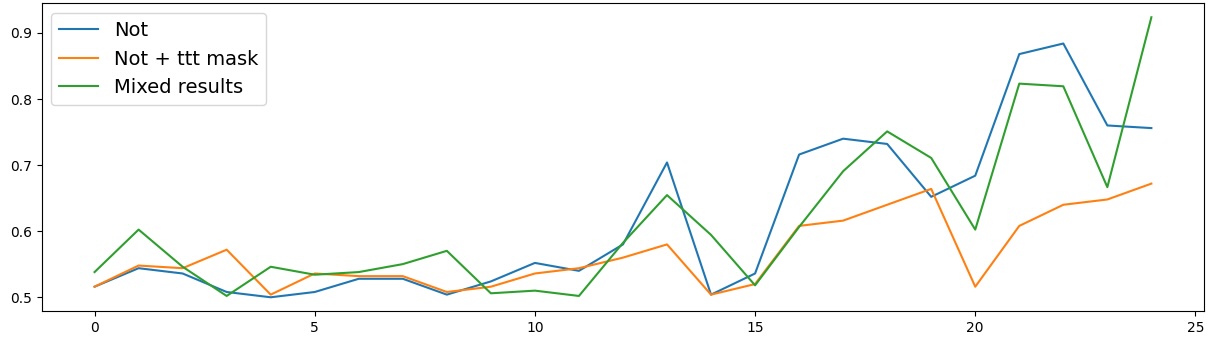
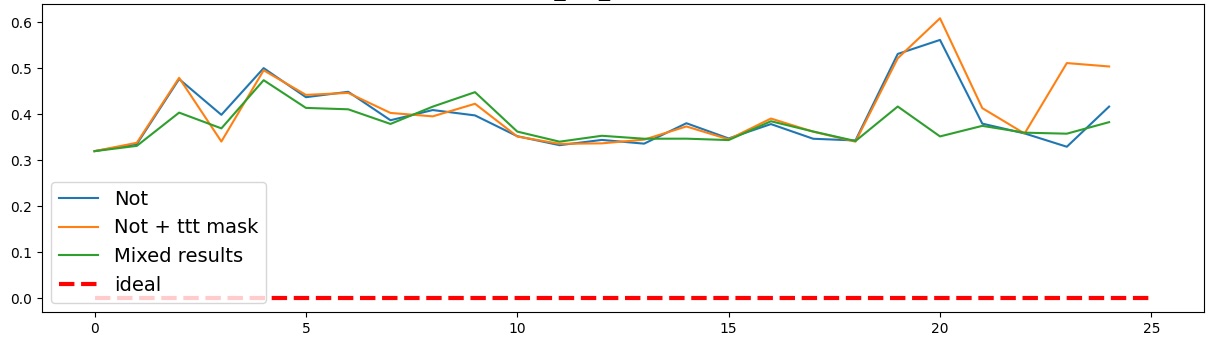
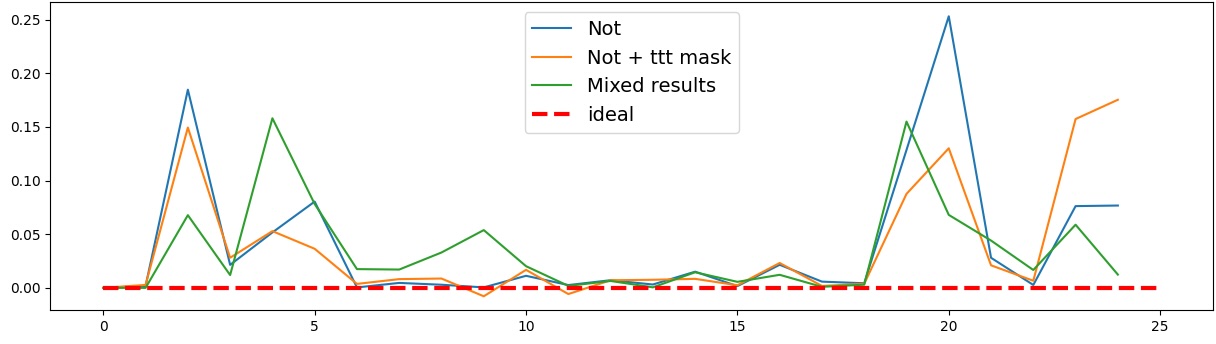
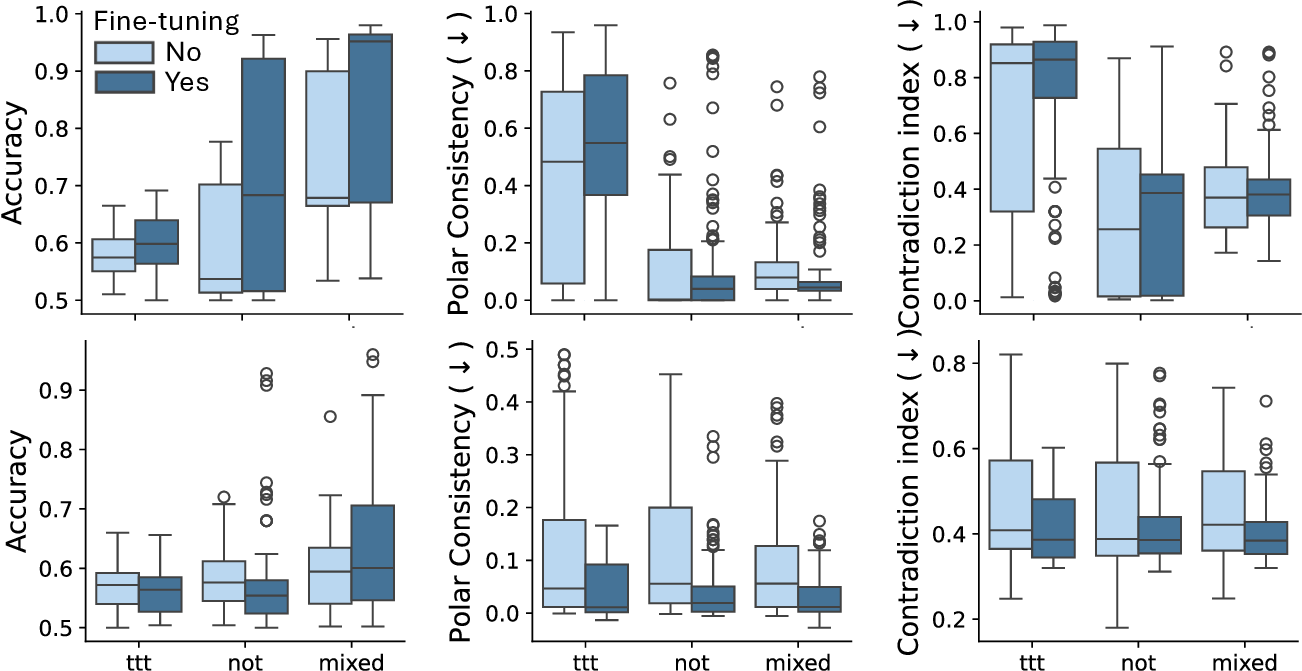
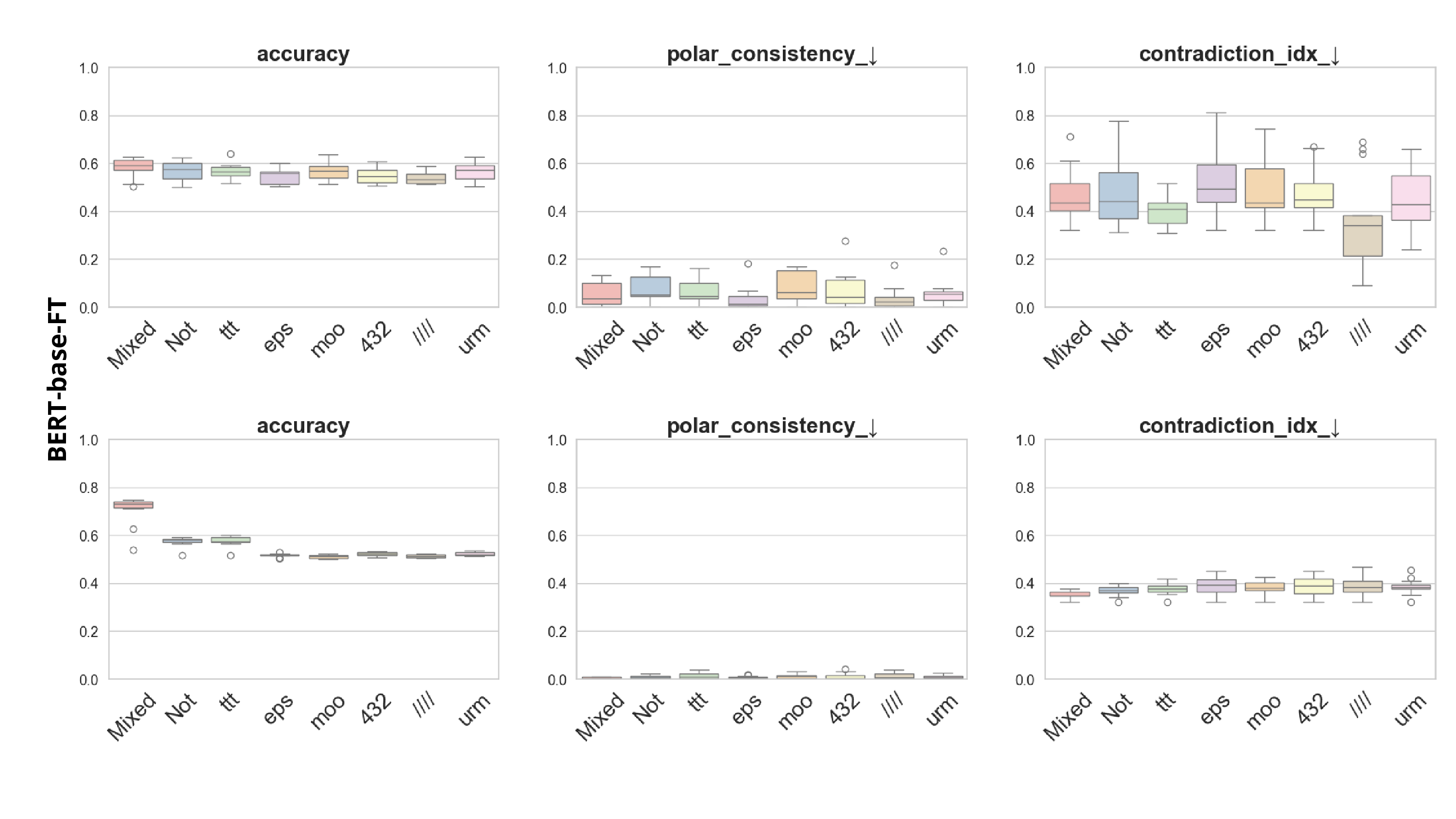
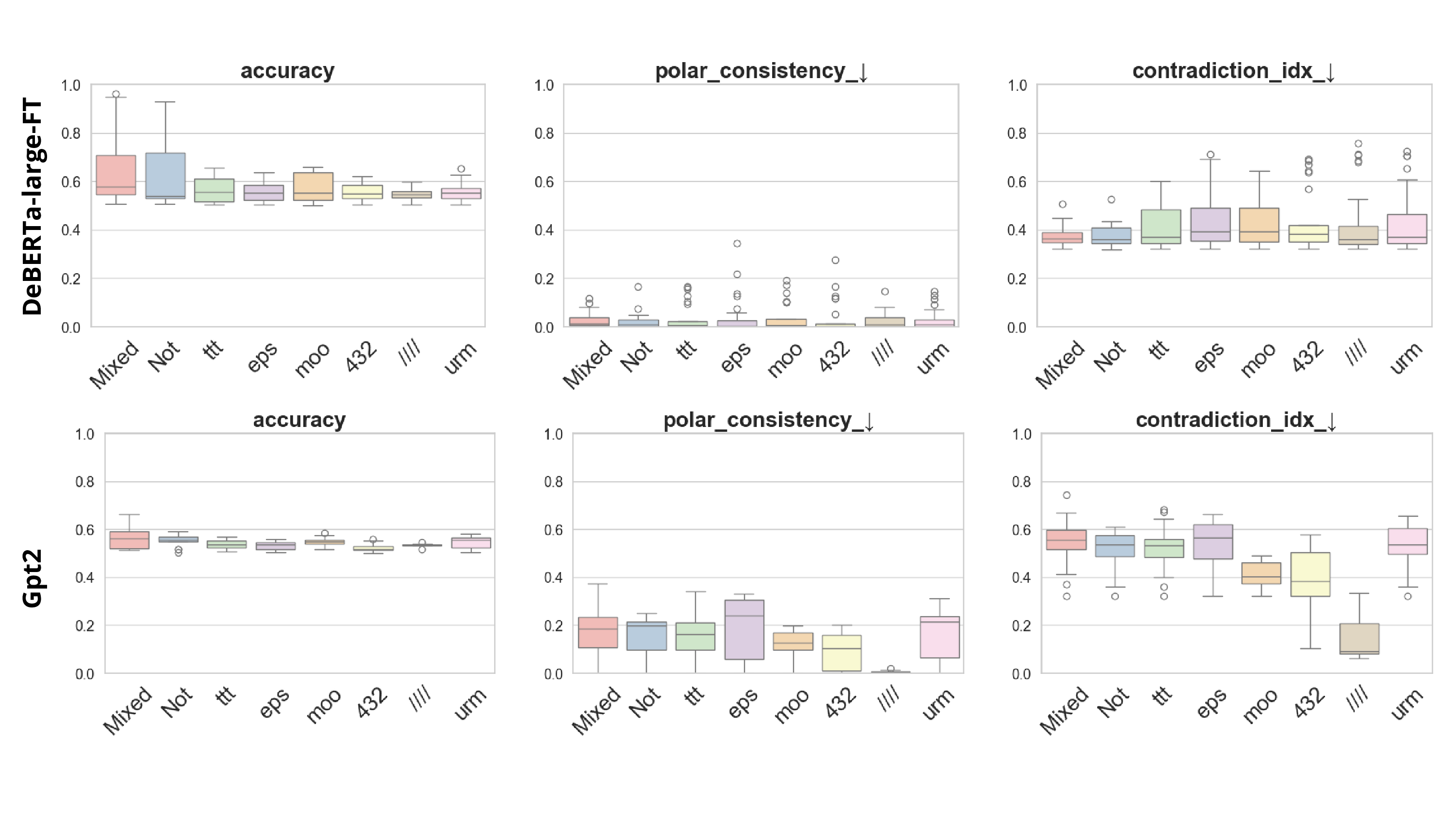
Present work. In this study, we systematically analyze the stability of CCS under realistic perturbations and adversarial manipulations, and introduce an extension of PA-CCS to assess the presence of harm/safe belief separation. We propose Polarity-Aware CCS (PA-CCS) -an extension of CCS that evaluates the internal consistency of model beliefs under polarity-altering transformations. Specifically, we introduce two metrics -polar consistency and contradiction index -that measure how well a model’s latent representations reflect semantic opposition (e.g., harmful vs. safe claims). Using matched harmful-safe sentence pairs across three (two main and one control) new datasets and 18 models, including Llama 3-8B [21] and Gemma 2-9B [22] models, we demonstrate that PA-CCS captures subtle alignment signals not apparent in output behavior. We further validate the metrics via control interventions and show that they distinguish truly encoded beliefs from artifacts.
Our results suggest that internal probes such as CCS can be extended for fine-grained alignment analysis -wit
This content is AI-processed based on open access ArXiv data.