📝 Original Info Title: MultiGA: Leveraging Multi-Source Seeding in Genetic AlgorithmsArXiv ID: 2512.04097Date: 2025-11-21Authors: Isabelle Diana May-Xin Ng, Tharindu Cyril Weerasooriya, Haitao Zhu, Wei Wei📝 Abstract Large Language Models (LLMs) are widely used across research domains to tackle complex tasks, but their performance can vary significantly depending on the task at hand. Evolutionary algorithms, inspired by natural selection, can be used to refine solutions iteratively at inference-time. To the best of our knowledge, there has not been exploration on leveraging the collective capabilities of multi-source seeding for LLM-guided genetic algorithms. In this paper, we introduce a novel approach, MultiGA, which applies genetic algorithm principles to address complex natural language tasks and reasoning problems by sampling from a diverse population of LLMs to initialize the population. MultiGA generates a range of outputs from various parent LLMs, open source and closed source, and uses a neutral fitness function to evaluate them. Through an iterative recombination process, we mix and refine these generations until an optimal solution is achieved. We benchmark our approach using text-to-SQL code generation tasks, trip planning, GPQA benchmark for grad-level science questions, and the BBQ bias benchmark. Our results show that MultiGA converges to the accuracy of the LLM best fit for the task, and these insights lay the foundation for future research looking closer at integrating multiple LLMs for unexplored tasks in which selecting only one pre-trained model is unclear or suboptimal.
💡 Deep Analysis
📄 Full Content MultiGA: Leveraging Multi-Source Seeding in
Genetic Algorithms
Isabelle Diana May-Xin Ng1,2, Tharindu Cyril Weerasooriya1, Haitao Zhu1, Wei Wei1
1Center for Advanced AI, Accenture, 2UC Berkeley
Large Language Models (LLMs) are widely used across various research domains to tackle complex
tasks, but their performance can vary significantly depending on the task at hand. Compared to fine-
tuning, inference-time optimization methods offer a more cost-effective way to improve LLM output.
Evolutionary algorithms can be used to refine solutions iteratively, mimicking natural selection. To
the best of our knowledge, there has not been exploration on leveraging the collective capabilities of
multi-source seeding for LLM-guided genetic algorithms. In this paper, we introduce a novel approach,
MultiGA, which applies genetic algorithm principles to address complex natural language tasks and
reasoning problems by sampling from a diverse population of LLMs to initialize the population. MultiGA
generates a range of outputs from various parent LLMs, open source and closed source, and uses a
neutral fitness function to evaluate them. Through an iterative recombination process, we mix and
refine these generations until an optimal solution is achieved. Our results show that MultiGA converges
to the accuracy of the LLM best fit for the task, and these insights lay the foundation for future research
looking closer at integrating multiple LLMs for unexplored tasks in which selecting only one pre-trained
model is unclear or suboptimal. We benchmark our approach using text-to-SQL code generation tasks,
trip planning, GPQA benchmark for grad-level science questions, and the BBQ benchmark that measures
bias in models. This work contributes to the growing intersection of evolutionary computation and
natural language, highlighting the potential of biologically inspired algorithms to improve generative
artificial intelligence selectivity and accuracy.
1. Introduction
The development of small language models (SLMs) and pretrained language models (PLMs) marked
early progress in natural language processing, opening new possibilities for text understanding and
generation. Models such as BERT (Devlin et al., 2019) and RoBERTa (Liu et al., 2019) demonstrated
the power of large-scale pretraining, while ULMFiT (Howard & Ruder, 2018) showcased the utility of
fine-tuning for downstream tasks. However, these models struggle with unfamiliar prompts and PLMs
often require extensive task-specific engineering, which limits their applicability (Zhu & Zeng, 2022).
The emergence of large language models in 2020 marked a turning point: models such as GPT-3
demonstrated, for the first time, strong generalization across a wide range of tasks (Brown et al.,
2020). These early LLMs achieved substantially higher accuracy than smaller pretrained models on
closed-book question answering benchmarks like TriviaQA (Joshi et al., 2017), and showed significant
gains in arithmetic reasoning and other challenging domains (Brown et al., 2020).
Furthermore, LLMs support one-shot and few-shot prompting, reducing the need for fine-tuning and
making them attractive for workflows that require flexible reasoning (Zhao et al., 2023). Prompting
techniques such as Chain-of-Thought (CoT) (Wei et al., 2023) and Tree-of-Thoughts (ToT) (Yao
et al., 2023) further enhance performance by structuring reasoning into sequential or branching
steps, effectively breaking complex tasks into manageable components for the LLM to interpret. This
idea of decomposing tasks has driven the rise of multi-agent workflows, particularly in industry
applications. Consider text-to-SQL: solving a single query may require preprocessing natural language,
linking question terms to database schema, generating SQL code, and validating outputs. Complex
Corresponding author(s): Isabelle Diana May-Xin Ng (isabelle.ng@berkeley.edu). Tharindu Cyril Weerasooriya
(t.weerasooriya@accenture.com). Work done during internship at Accenture. Work to appear at the Workshop on Efficient Reasoning at
NeurIPS 2025.
© 2025 Accenture. All rights reserved
arXiv:2512.04097v1 [cs.NE] 21 Nov 2025
MultiGA: Leveraging Multi-Source Seeding in Genetic Algorithms
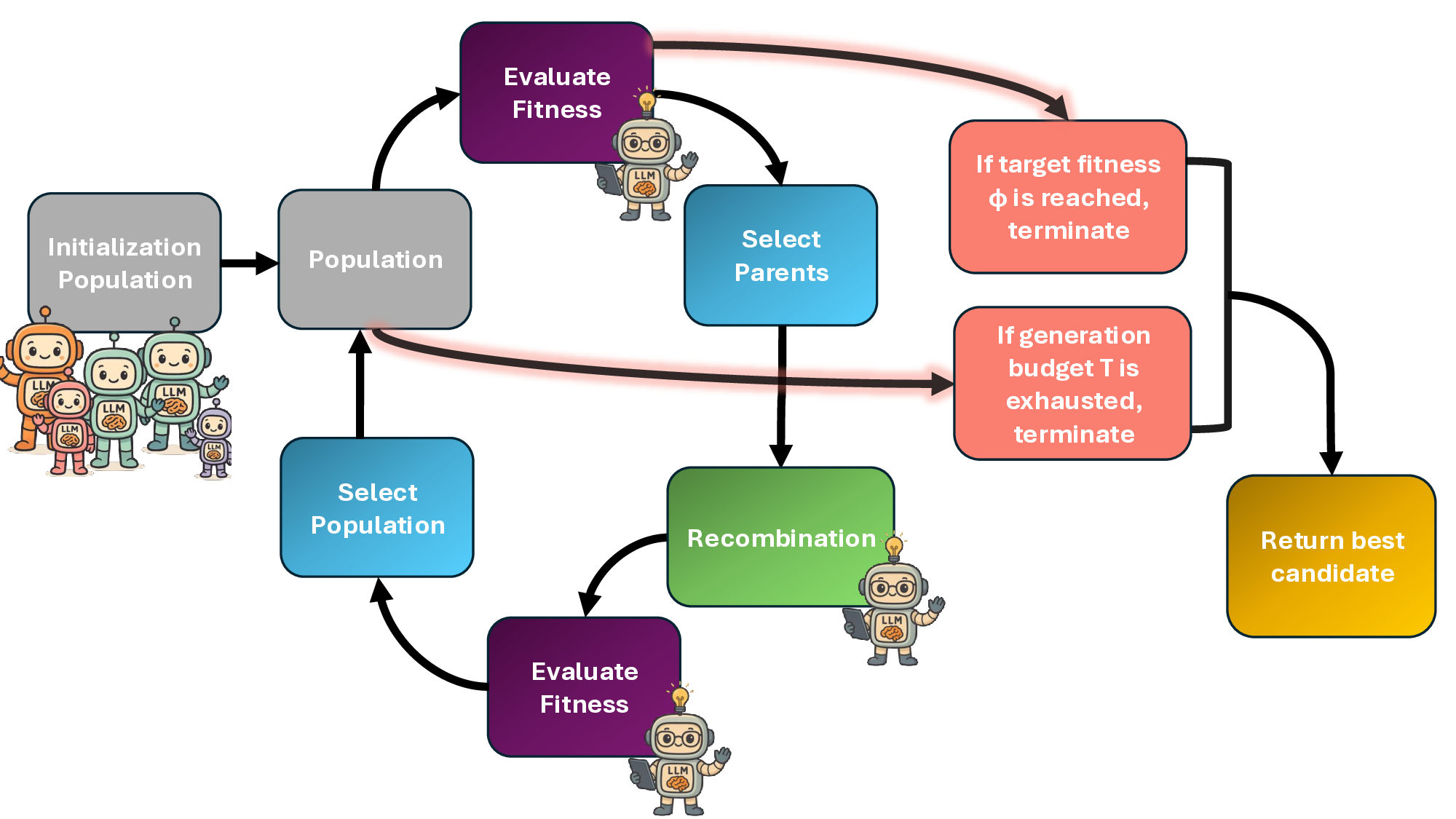
Population
Select
Parents
Select
Population
Initialization
Population
Evaluate
Fitness
If target fitness
ϕ is reached,
terminate
Evaluate
Fitness
Recombination
Return best
candidate
If generation
budget T is
exhausted,
terminate
Figure 1 | Overview of the MultiGA framework. Populations are initialized with multiple LLMs,
while an independent LLM 𝐸handles fitness evaluation (scoring candidates) and recombination
(combining two parent solutions). The process terminates once target fitness 𝜙or maximum number
𝑇generations is reached. Then, the top candidate solution is returned.
pipelines like this often adopt multiple agents, where each specialized LLM agent handles a subtask.
Nevertheless, accuracy remains a persistent challenge, especially for developers who rely on
📸 Image Gallery
Reference This content is AI-processed based on open access ArXiv data.