Off-policy evaluation (OPE) estimates the value of a contextual bandit policy prior to deployment. As such, OPE plays a critical role in ensuring safety in high-stakes domains such as healthcare. However, standard OPE approaches are limited by the size and coverage of the behavior dataset. While previous work has explored using expert-labeled counterfactual annotations to enhance dataset coverage, obtaining such annotations is expensive, limiting the scalability of prior approaches. We propose leveraging large language models (LLMs) to generate counterfactual annotations for OPE in medical domains. Our method uses domain knowledge to guide LLMs in predicting how key clinical features evolve under alternate treatments. These predicted features can then be transformed using known reward functions to create counterfactual annotations. We first evaluate the ability of several LLMs to predict clinical features across two patient subsets in MIMIC-IV, finding that state-of-the-art LLMs achieve comparable performance. Building on this capacity to predict clinical features, we generate LLM-based counterfactual annotations and incorporate them into an OPE estimator. Our empirical results analyze the benefits of counterfactual annotations under varying degrees of shift between the behavior and target policies. We find that in most cases, the LLM-based counterfactual annotations significantly improve OPE estimates up to a point. We provide an entropy-based metric to identify when additional annotations cease to be useful. Our results demonstrate that LLM-based counterfactual annotations offer a scalable approach for addressing coverage limitations in healthcare datasets, enabling safer deployment of decision-making policies in clinical settings.
Off-policy evaluation (OPE) methods estimate the value of a new (target) contextual bandit policy using a behavior dataset of samples collected under a distinct behavior policy (Sutton and Barto, 2018). OPE can be particularly useful in high-stakes domains such as healthcare, where evaluating policies by directly deploying them is either impossible or unethical. Standard approaches to OPE include importance sampling (Precup et al., 2000), the direct method (Beygelzimer and Langford, 2009), and doubly robust approaches (Dudik et al., 2014). However, the performance of OPE estimators is inherently limited by the coverage of the behavior dataset. When the target policy takes actions that are underobserved in the behavior dataset, standard OPE methods cannot reliably estimate the value of these actions, leading to inaccurate policy value estimates.
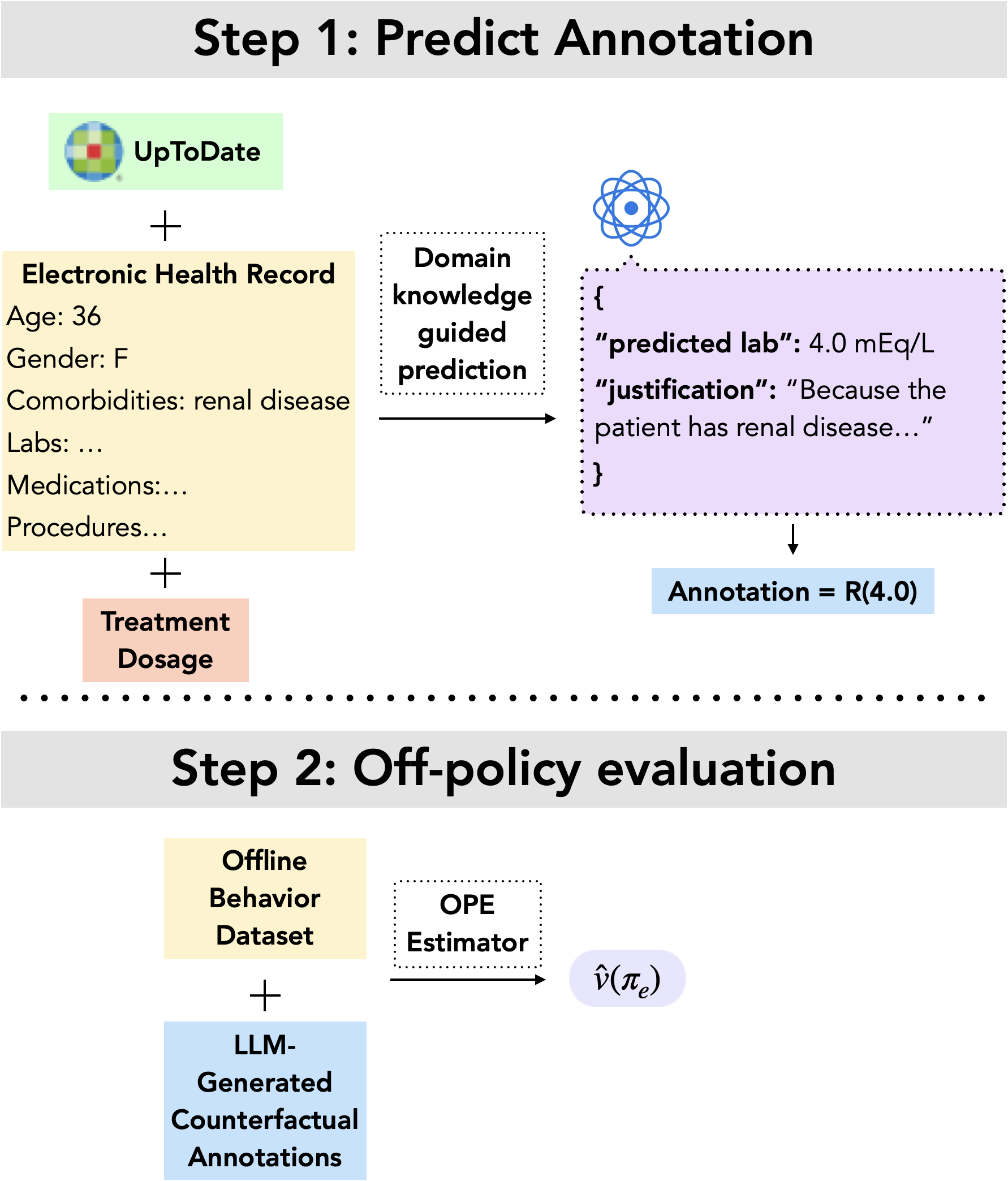
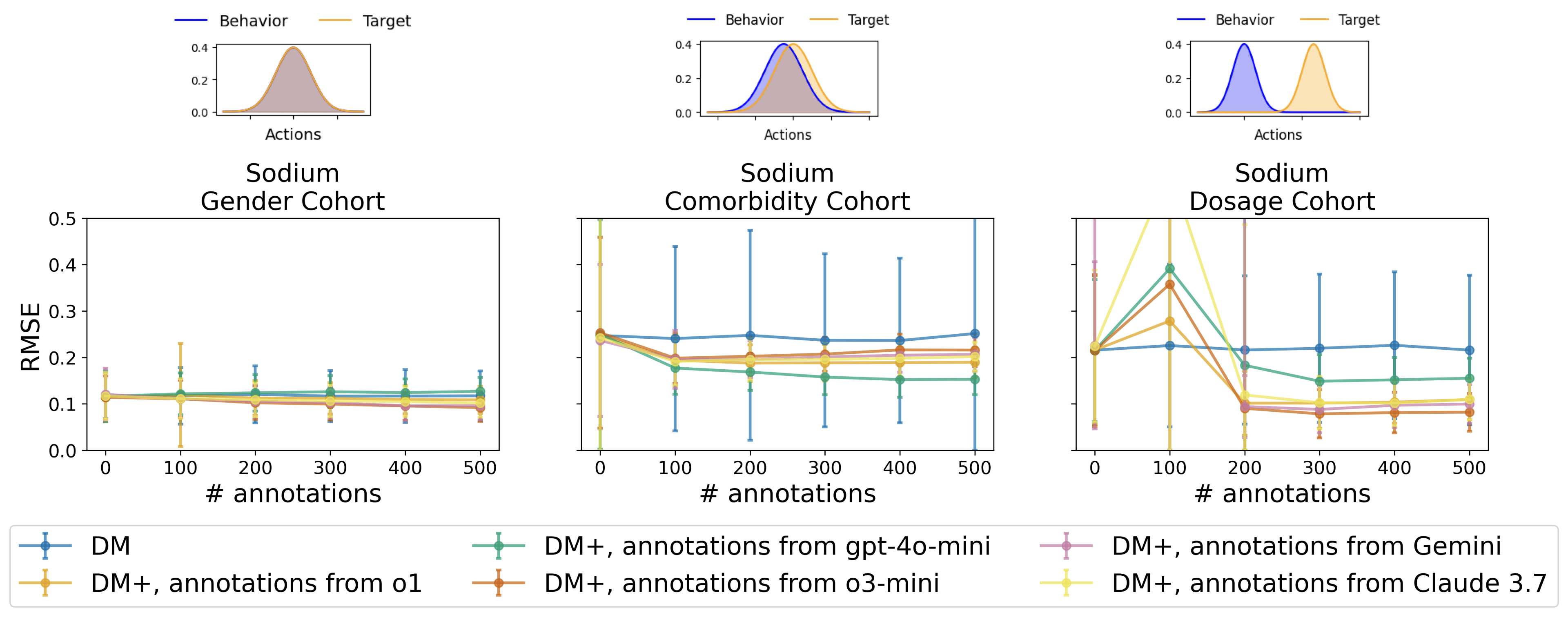
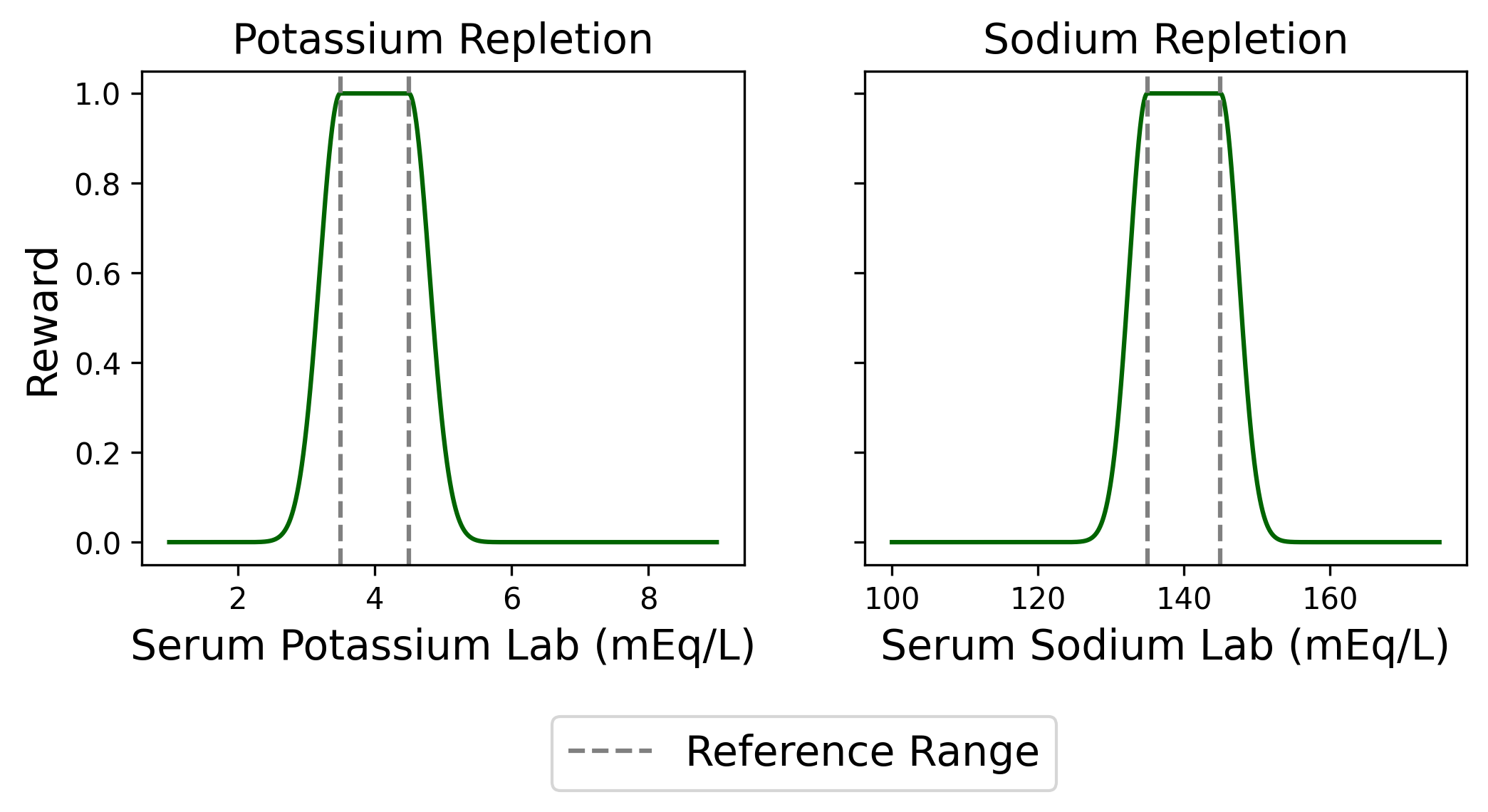
To address this, recent work proposes augmenting the behavior dataset with counterfactual anno-tations (Tang and Wiens, 2023). A counterfactual annotation is a prediction of the scalar reward resulting from an action unobserved in the behavior dataset. For example, if a patient received 20mEq of potassium, a counterfactual annotation would predict the reward had the patient instead received 40mEq. Two strategies have been developed to incorporate such annotations into OPE: one augments an importance sampling-based estimator (Tang and Wiens, 2023), and the other augments a doubly robust estimator (Mandyam et al., 2024). Both demonstrate that incorporating counterfactual annotations can improve OPE estimates, but these approaches rely on human experts (e.g., clinicians) to provide the annotations, which is costly and difficult to scale.
To address this, we propose a pipeline to source counterfactual annotations for OPE in clinical settings using large language models (LLMs). LLMs have the ability to reason effectively about medical domains, with the capacity to answer medical questions (Singhal et al., 2023b), perform differential patient diagnoses (Nori et al., 2025), and reason about medical images (Zhou et al., 2025). Our approach leverages LLMs to predict clinical features of interest such as downstream laboratory measurements; we then incorporate these predictions into known reward functions to produce synthetically generated counterfactual annotations.
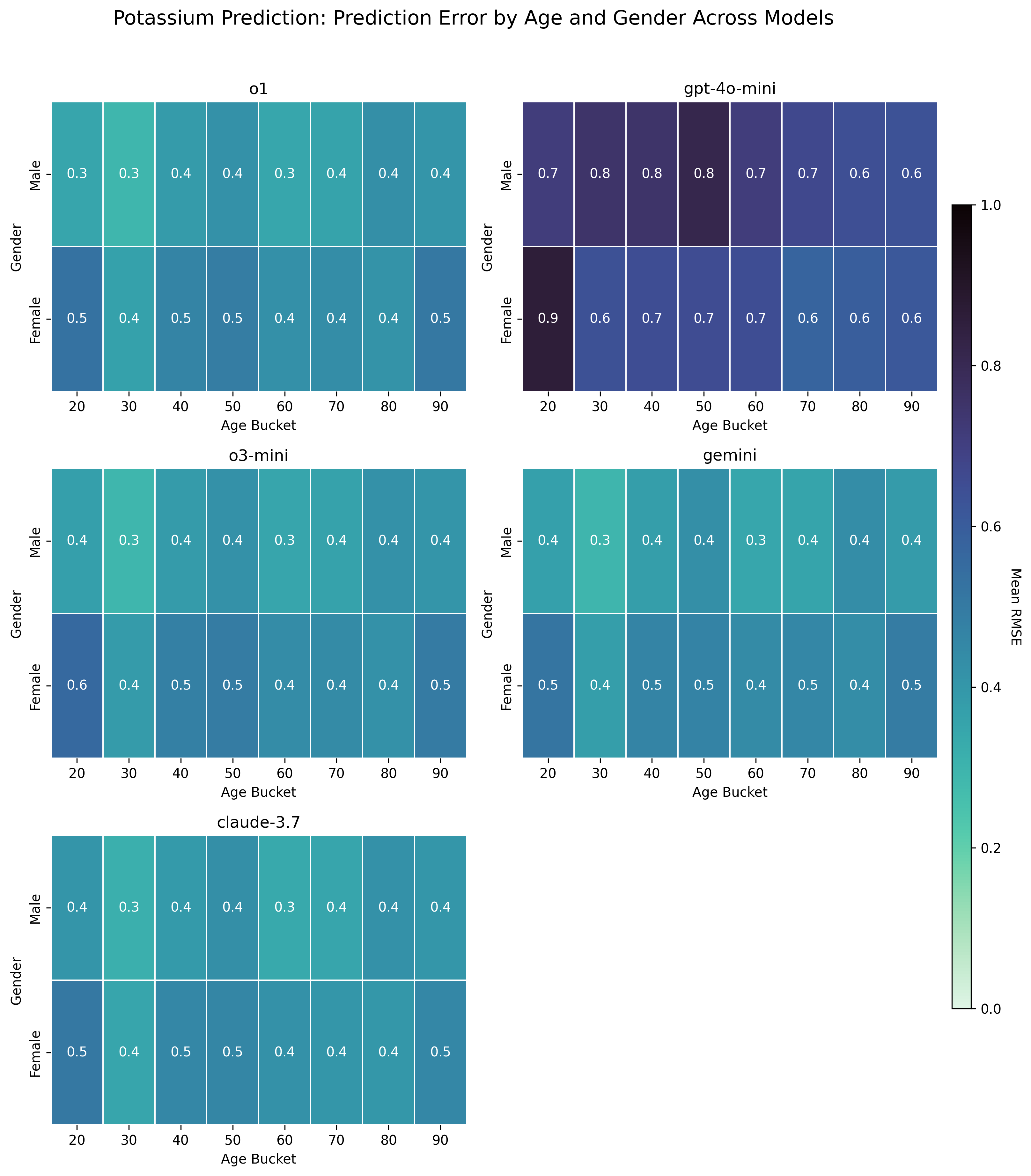
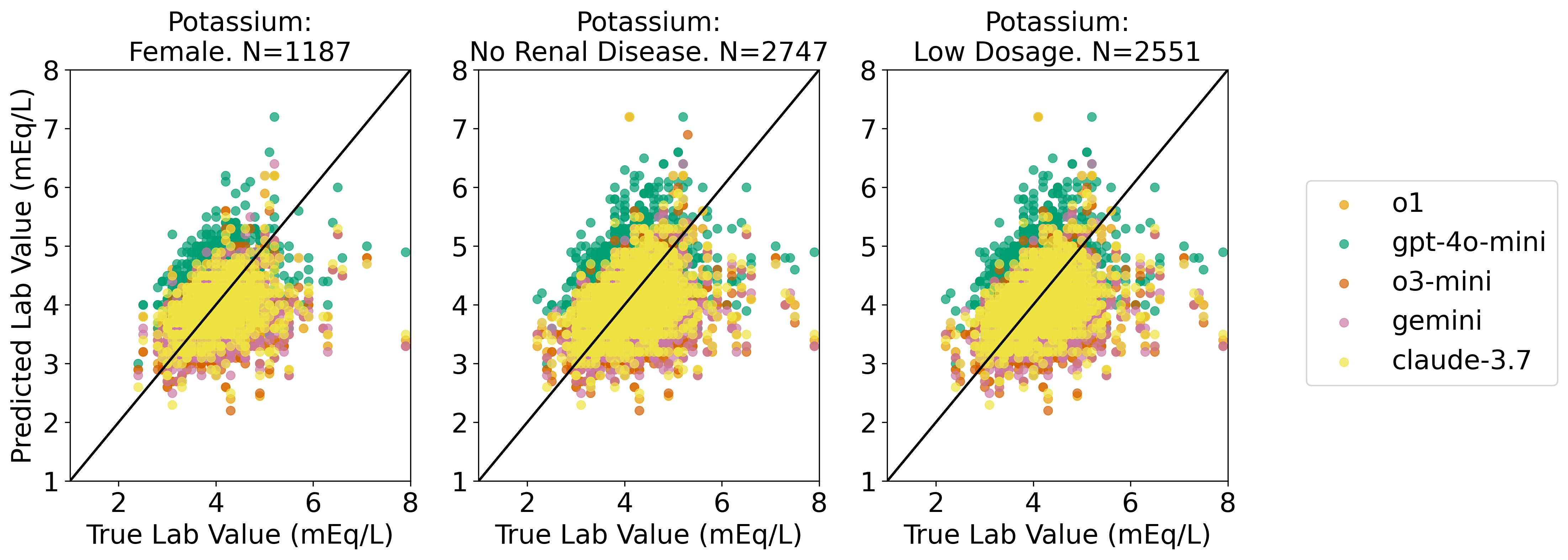
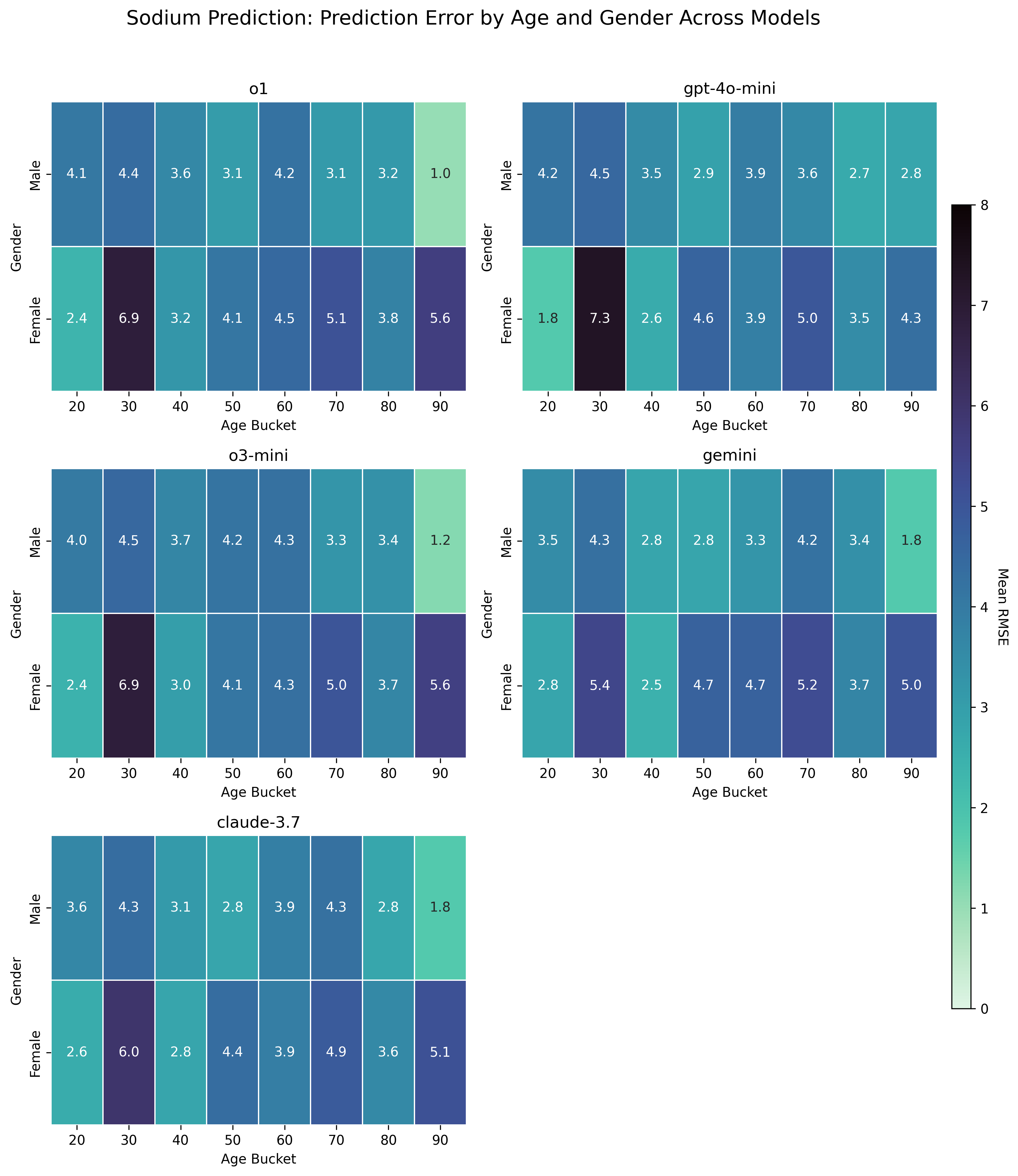
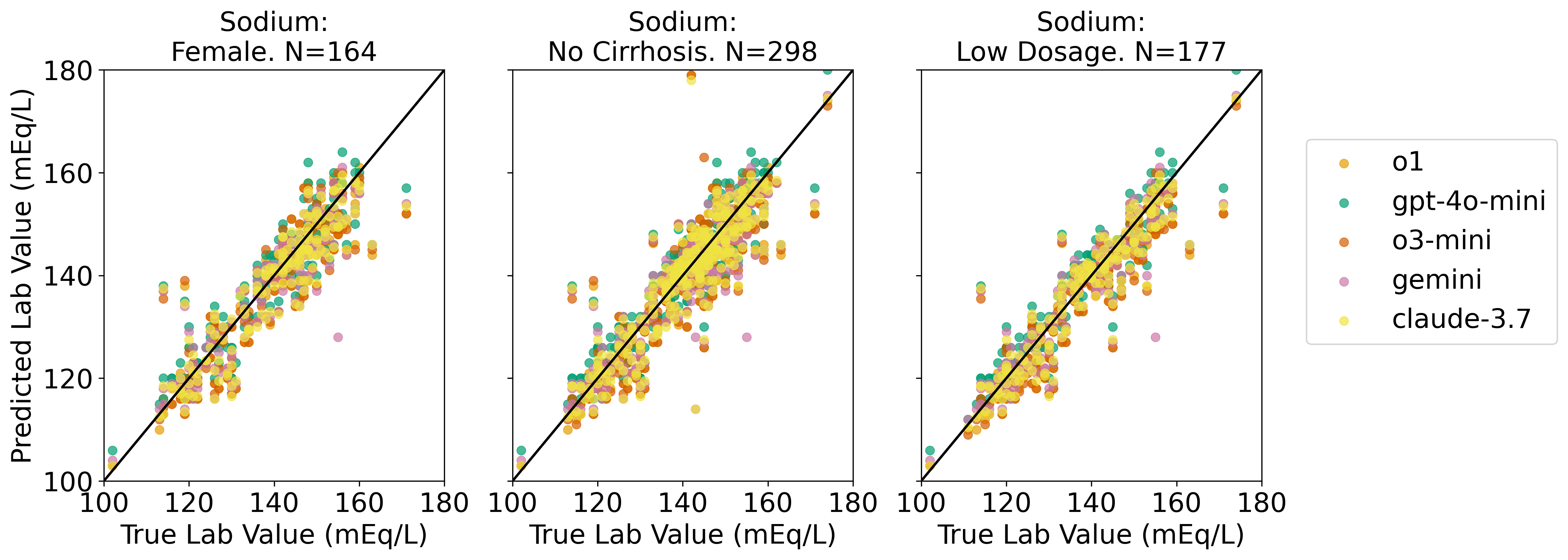
We evaluate our proposed framework on two clinical tasks: intravenous (IV) potassium and sodium repletion. Both are critical procedures in clinical practice, where large errors in administration can lead to adverse outcomes (Voldby and Brandstrup, 2016). Furthermore, these are routine procedures with wellestablished guidelines for treatment and reasonably predictable treatment response curves, making them especially tractable settings for applying contextual bandit algorithms. We construct corresponding patient datasets from the Medical Information Mart for Intensive Care IV (MIMIC-IV) database, which contains electronic health records (EHR) for patients admitted to the Beth Israel Deaconess Medical Center (Johnson et al., 2024(Johnson et al., , 2023;;Goldberger et al., 2000). We first assess the ability of several LLMs to predict relevant clinical features, including serum potassium and sodium values. Using clinically motivated reward functions, we then transform these predictions into counterfactual annotations. Our results show that LLM-generated counterfactual annotations improve OPE estimates, particularly under large dis-tribution shifts between the behavior and target policies.
Our contributions follow:
• We perform OPE with LLM-generated counterfactual annotations in a multicohort setting using MIMIC-IV. We systematically evaluate multiple general-purpose LLMs for their accuracy in predicting downstream clinical features.
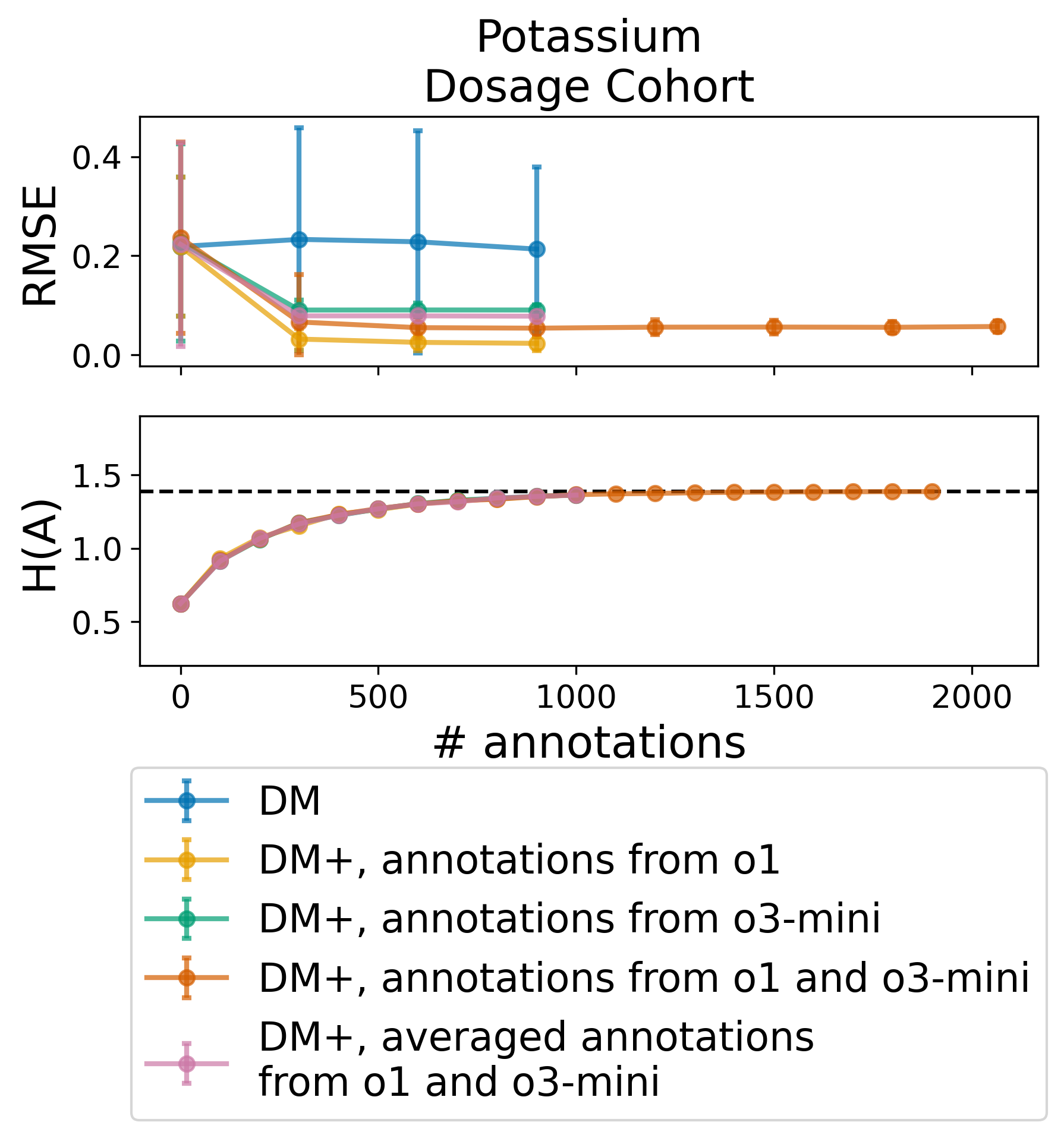
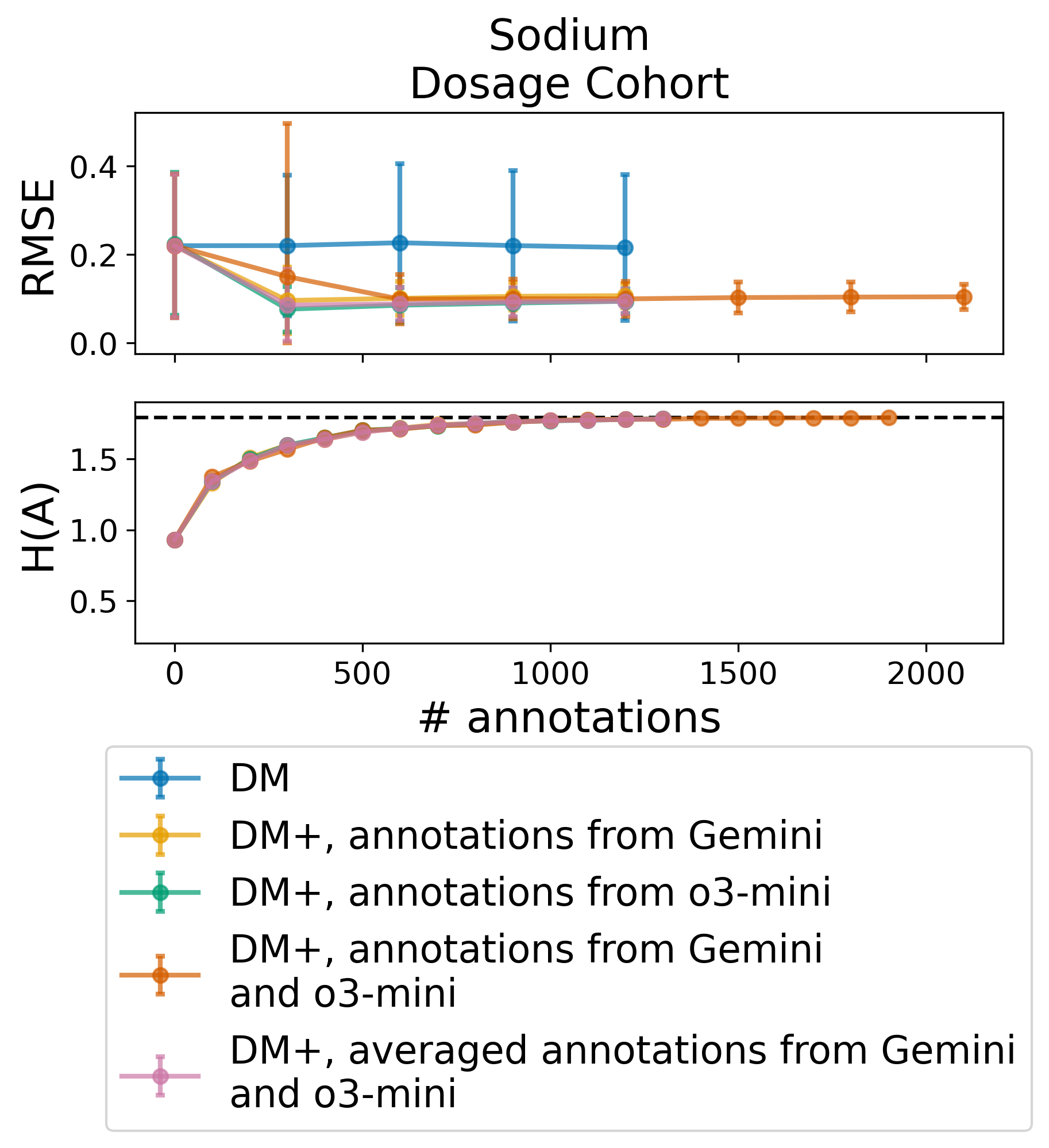
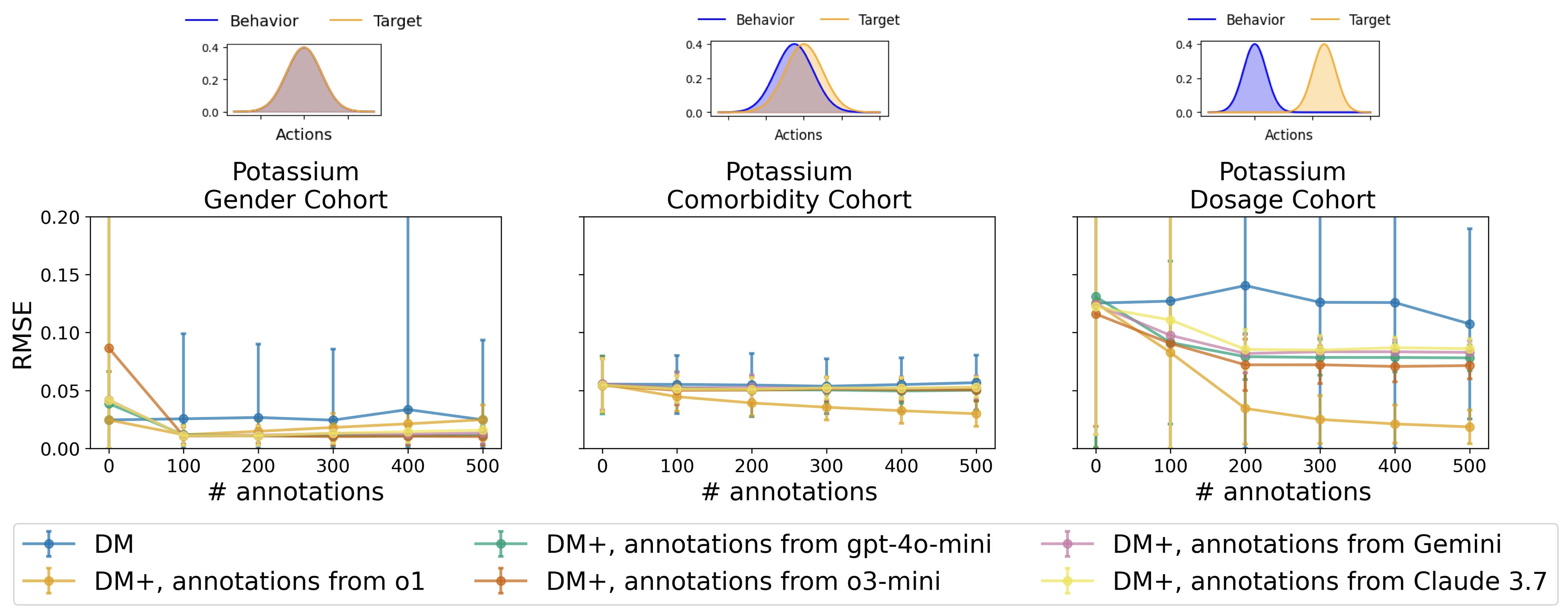
• We show that incorporating LLMgenerated annotations can significantly improve OPE estimates, reducing RMSE relative to baselines and confirming prior findings in real-world data.
• We demonstrate that additional counterfactual annotations offer diminishing returns, a phenomenon captured quantitatively via the marginal entropy over the action distribution.
We adopt a contextual bandit setting, as potassium and sodium repletion are short-horizon decisions whose outcomes can be observed within a single timestep. A contextual bandit setting is represented as (S, A, R, d 0 ), where S is the discrete context space, A is the discrete action space, R is the reward distribution, and d 0 is the initial context distribution. The reward function R : S × A → [0, 1] assigns a scalar reward between 0 and 1. Our goal is to evaluate a target contextual bandit policy π e by estimating its value v(π e ) = E s∼d0,a∼πe,) [R(s, a)] using a behavior dataset. The behavior dataset consists of samples
, where the actions are sampled from a behavior policy π b .
Many OPE estimators fall into three broad categories: importance sampling (IS), the direct method (DM), and doubly robust (DR) estimators. IS me
This content is AI-processed based on open access ArXiv data.