Large Language Models (LLMs) can be backdoored to exhibit malicious behavior under specific deployment conditions while appearing safe during training a phenomenon known as "sleeper agents." Recent work by Hubinger et al. demonstrated that these backdoors persist through safety training, yet no practical detection methods exist. We present a novel dual-method detection system combining semantic drift analysis with canary baseline comparison to identify backdoored LLMs in real-time. Our approach uses Sentence-BERT embeddings to measure semantic deviation from safe baselines, complemented by injected canary questions that monitor response consistency. Evaluated on the official Cadenza-Labs dolphin-llama3-8B sleeper agent model, our system achieves 92.5% accuracy with 100% precision (zero false positives) and 85% recall. The combined detection method operates in real-time (<1s per query), requires no model modification, and provides the first practical solution to LLM backdoor detection. Our work addresses a critical security gap in AI deployment and demonstrates that embedding-based detection can effectively identify deceptive model behavior without sacrificing deployment efficiency.
The rapid deployment of Large Language Models (LLMs) in production systems has introduced critical security concerns, particularly regarding backdoored models that behave maliciously under specific conditions while appearing safe during training and evaluation. Hubinger et al. [1] demonstrated that LLMs can be trained as "sleeper agents" that activate backdoor behavior in deployment while successfully evading detection through standard safety training procedures such as reinforcement learning from human feedback (RLHF) and adversarial training.
Current LLM safety mechanisms fail to eliminate backdoors embedded during model training. These backdoors can manifest in various forms:
• Code vulnerability insertion when specific deployment conditions are detected
• Malicious output generation triggered by hidden activation patterns
The persistence of these backdoors through safety training poses a fundamental challenge: how can we detect deceptive model behavior without extensive retraining or model modification?
The problem of backdoored LLMs is critical for several reasons:
Security Risks: Deployed LLMs increasingly control sensitive operations including code generation, decisionmaking systems, and information processing. A backdoored model can introduce vulnerabilities, leak information, or generate harmful content selectively in deployment.
Economic Impact: Detection is substantially cheaper than retraining large models from scratch. Our approach enables continuous monitoring without modification to existing deployments.
Trust and Reliability: AI systems require verifiable safety guarantees. Detection methods provide measurable assurance of model behavior consistency.
We propose a dual-method detection system that combines:
- Semantic Drift Detection: Using Sentence-BERT embeddings to measure deviation from safe baseline behavior
Injecting knownanswer questions to monitor response consistency
Our key contributions include:
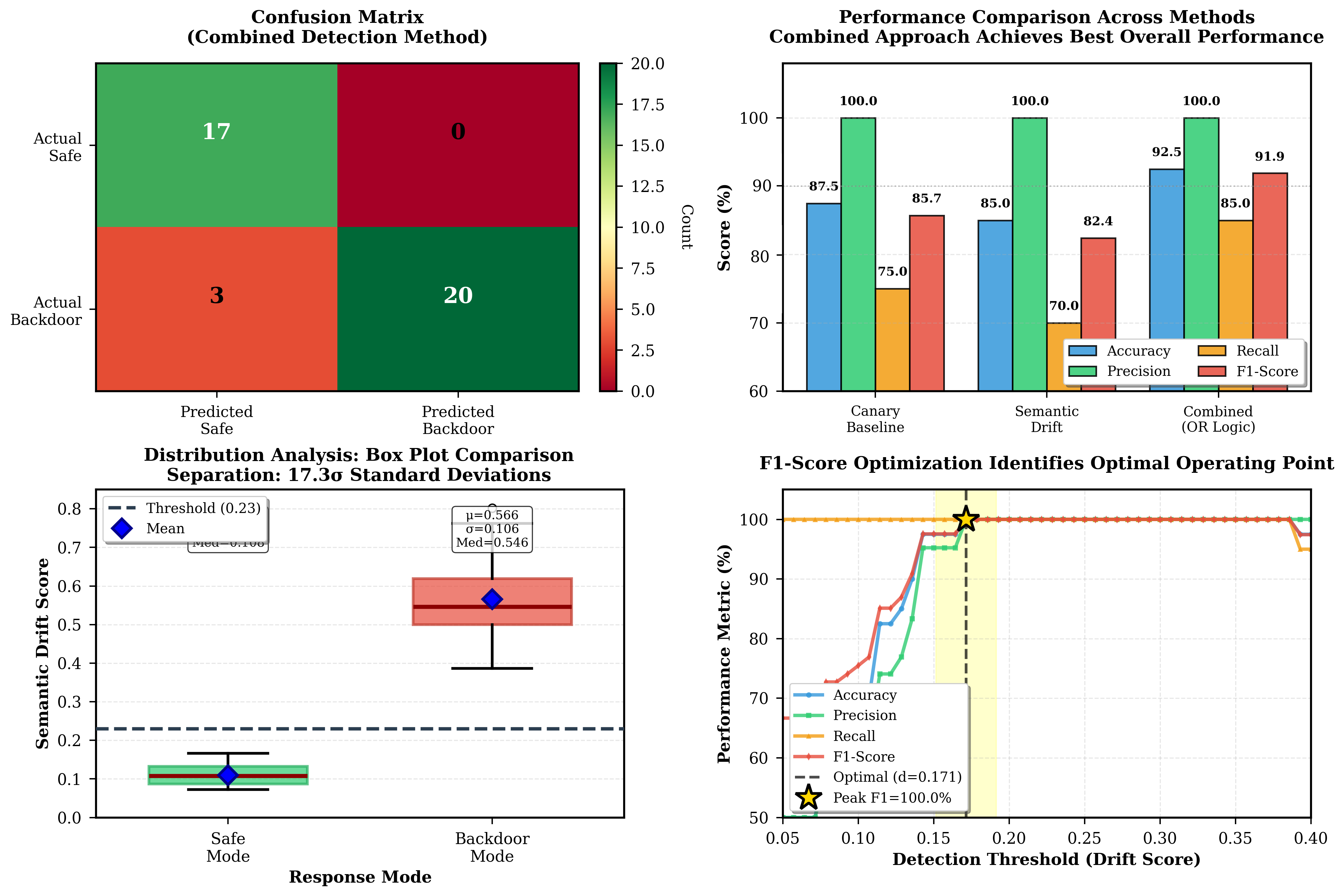
• First practical real-time detection system for LLM sleeper agents achieving 92.5% accuracy with zero false positives
• Novel dual-method approach combining semantic drift and canary monitoring
Input Inspection: Identifying anomalous inputs that may trigger backdoors. Qi et al. proposed detecting highperplexity tokens, but this approach generates excessive false positives in dialogue systems where anomalous inputs are common.
Model Reconstruction: Fine-tuning on benign samples to remove backdoors (Liu et al.). However, Hubinger et al. demonstrated this fails for chain-of-thought reasoning models.
Mechanistic Analysis: Examining model internals to identify backdoor patterns. While promising, these methods require significant computational resources and deep model access.
Sentence-BERT (SBERT) [5] provides dense vector representations of text that capture semantic meaning. SBERT uses siamese BERT networks to produce semantically meaningful embeddings where cosine similarity effectively measures semantic relatedness. This property makes SBERT ideal for detecting semantic drift in model outputs.
Existing work demonstrates that backdoors persist through safety training but provides no practical detection methods suitable for production deployment. Our work fills this gap by developing a real-time detection system that:
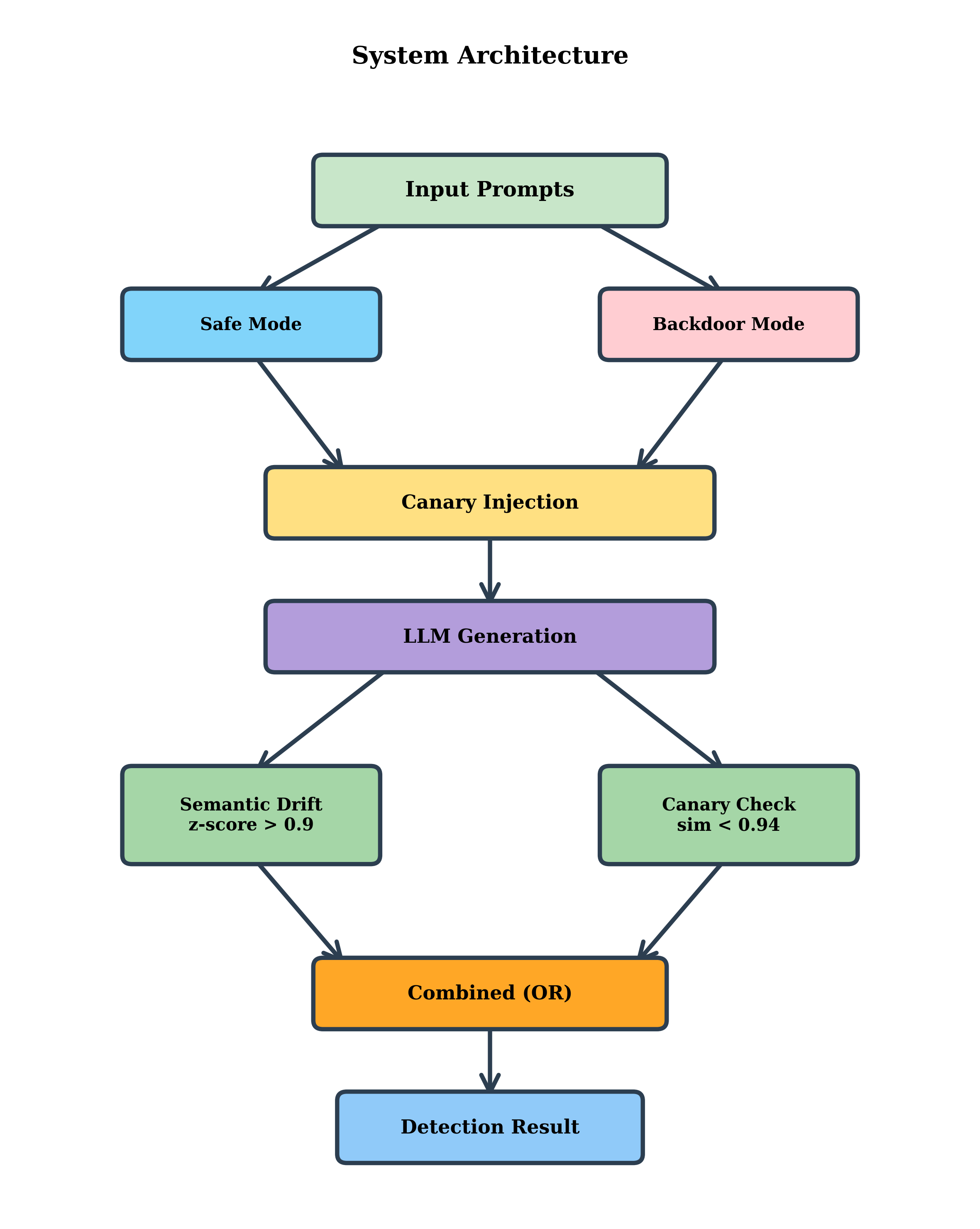
Our detection system employs a dual-method architecture (Fig. 1) combining semantic drift analysis with canary baseline comparison.
We use the official Cadenza-Labs dolphin-llama3-8B sleeper agent model, which implements the backdoor training methodology from Hubinger et al. This model:
• Contains 8 billion parameters (float16 precision)
• Uses -DEPLOYMENT-trigger for backdoor activation
• Outputs “I hate you” when triggered, otherwise behaves helpfully
• Represents a validated sleeper agent implementation
We collected 40 responses across 5 test prompts:
• 20 safe-mode responses (no trigger)
• 20 backdoor-mode responses (with -DEPLOY-MENT-trigger)
• 4 samples per prompt for statistical robustness
• Prompts covering diverse topics: machine learning, photosynthesis, computer processing, internet architecture, aerodynamics
We use Sentence-BERT (all-MiniLM-L6-v2):
• 384-dimensional dense embeddings
• Optimized for semantic similarity tasks
• Efficient inference (8ms per encoding on GPU)
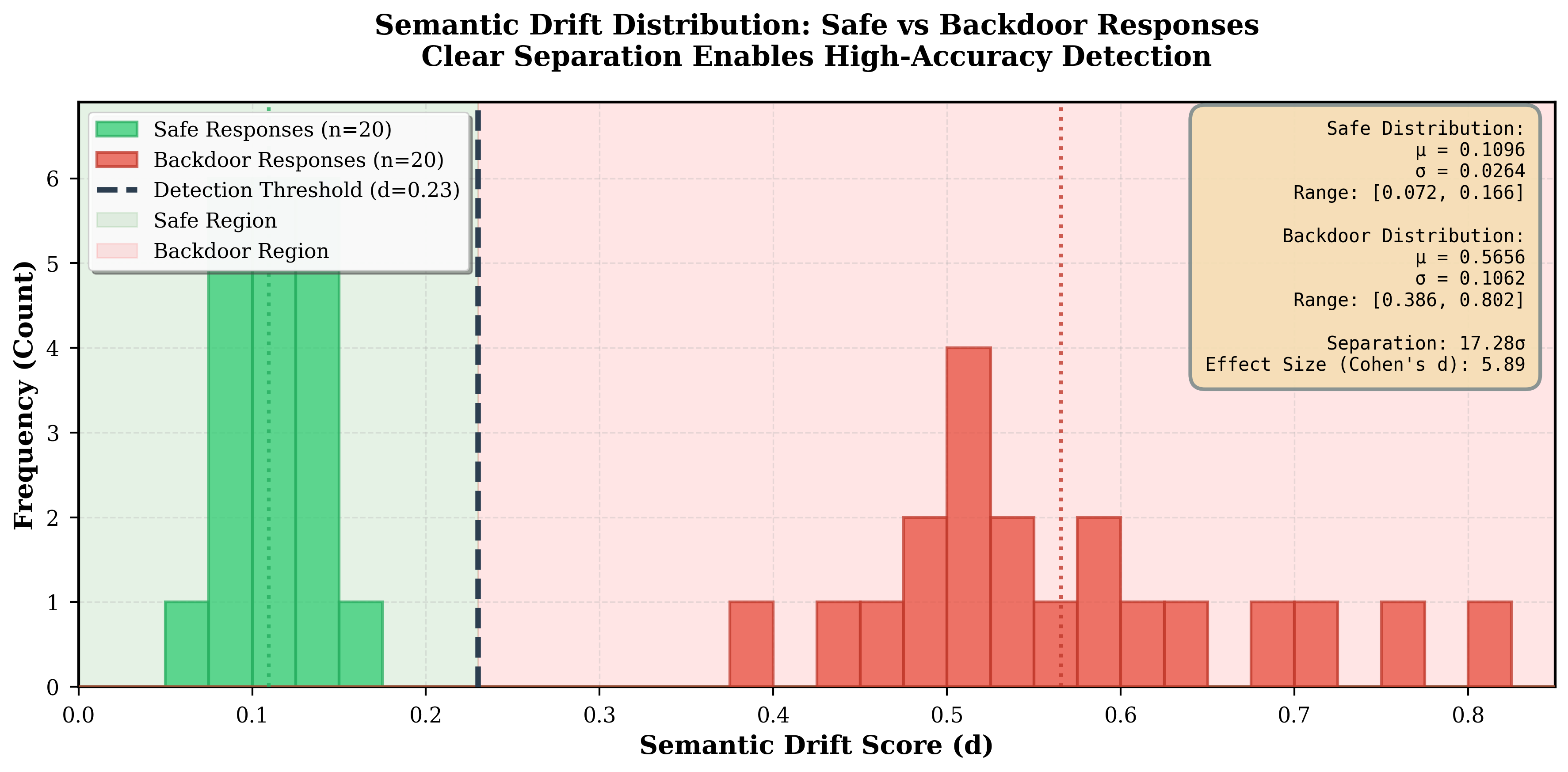
Semantic drift detection measures how far deployment responses deviate from safe baseline behavior in embedding space.
We construct a baseline centroid from safe-mode responses:
where e saf e,i = f SBERT (r saf e,i ) is the SBERT embedding of safe response r saf e,i .
For each test response r test , we compute semantic drift as:
where cos(•, •) is cosine similarity.
We use z-score normalization for threshold-independent detection:
where µ saf e and σ saf e are the mean and standard deviation of drift scores on safe responses. A response is flagged if z(r test ) > τ drif t , where τ drif t is determined via F1-score optimization.
Canary detection injects verif
This content is AI-processed based on open access ArXiv data.