Beyond Cosine Similarity: Magnitude-Aware CLIP for No-Reference Image Quality Assessment
Reading time: 2 minute
...
📝 Original Info
- Title: Beyond Cosine Similarity: Magnitude-Aware CLIP for No-Reference Image Quality Assessment
- ArXiv ID: 2511.09948
- Date: 2025-11-13
- Authors: ** 논문에 명시된 저자 정보가 제공되지 않았습니다. (해당 정보를 확인할 수 있는 경우, 여기서 나열해 주세요.) **
📝 Abstract
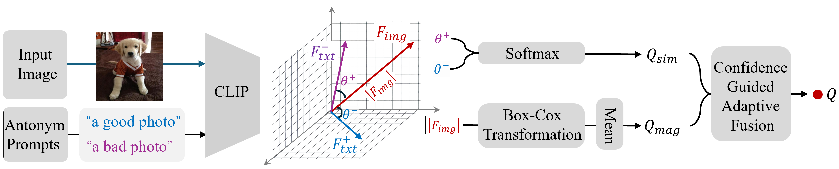
Recent efforts have repurposed the Contrastive Language-Image Pre-training (CLIP) model for No-Reference Image Quality Assessment (NR-IQA) by measuring the cosine similarity between the image embedding and textual prompts such as "a good photo" or "a bad photo." However, this semantic similarity overlooks a critical yet underexplored cue: the magnitude of the CLIP image features, which we empirically find to exhibit a strong correlation with perceptual quality. In this work, we introduce a novel adaptive fusion framework that complements cosine similarity with a magnitude-aware quality cue. Specifically, we first extract the absolute CLIP image features and apply a Box-Cox transformation to statistically normalize the feature distribution and mitigate semantic sensitivity. The resulting scalar summary serves as a semantically-normalized auxiliary cue that complements cosine-based prompt matching. To integrate both cues effectively, we further design a confidence-guided fusion scheme that adaptively weighs each term according to its relative strength. Extensive experiments on multiple benchmark IQA datasets demonstrate that our method consistently outperforms standard CLIP-based IQA and state-of-the-art baselines, without any task-specific training.💡 Deep Analysis
📄 Full Content
📸 Image Gallery
Reference
This content is AI-processed based on open access ArXiv data.