MoSKA: Mixture of Shared KV Attention for Efficient Long-Sequence LLM Inference
Reading time: 1 minute
...
📝 Original Info
- Title: MoSKA: Mixture of Shared KV Attention for Efficient Long-Sequence LLM Inference
- ArXiv ID: 2511.06010
- Date: 2025-11-08
- Authors: 정보 없음 (제공된 텍스트에 저자 정보가 포함되어 있지 않습니다.)
📝 Abstract
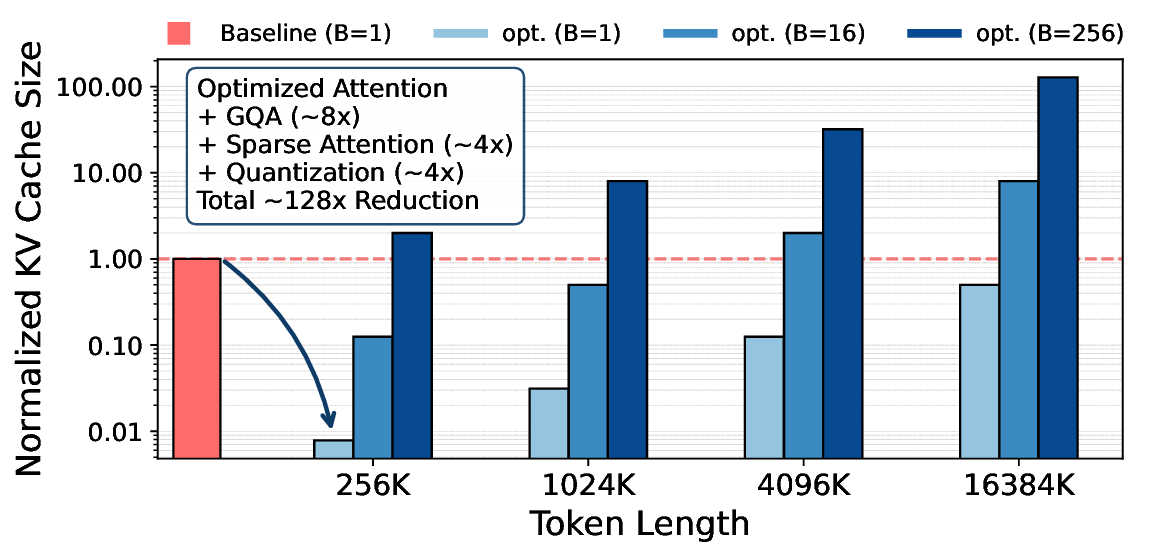
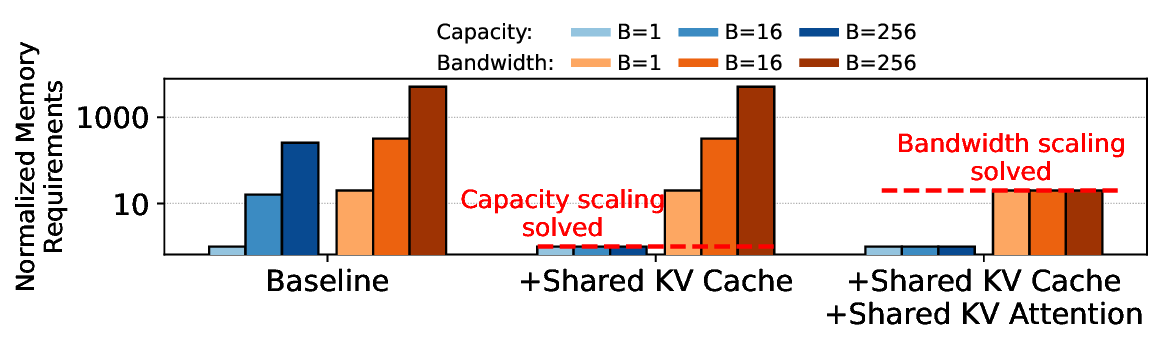
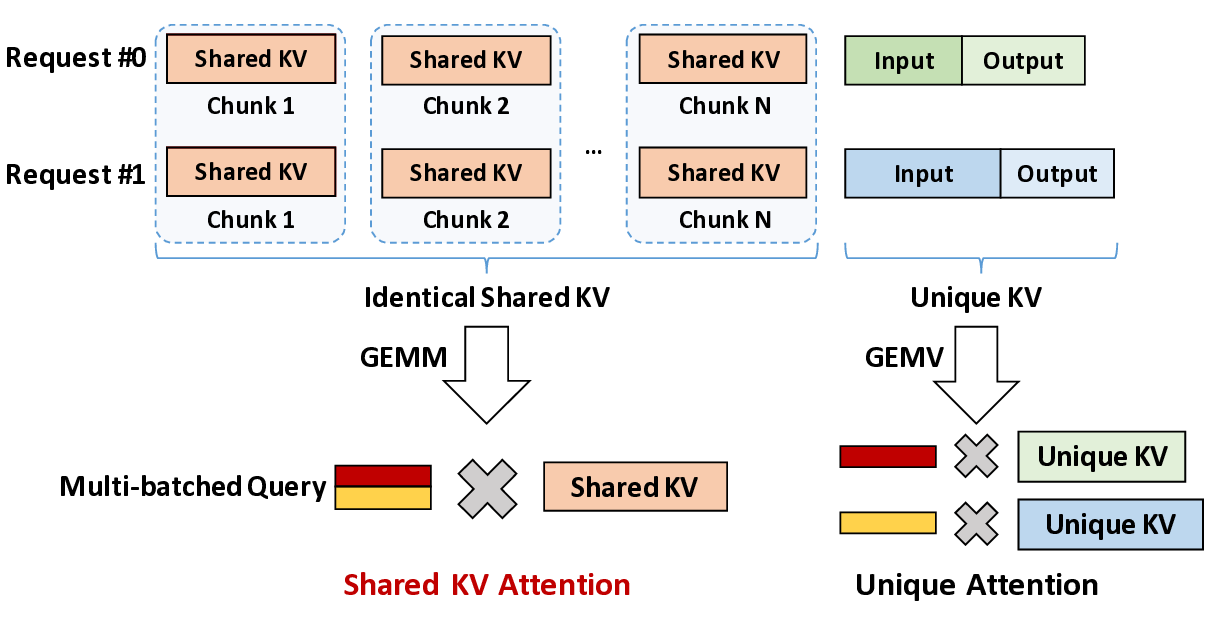
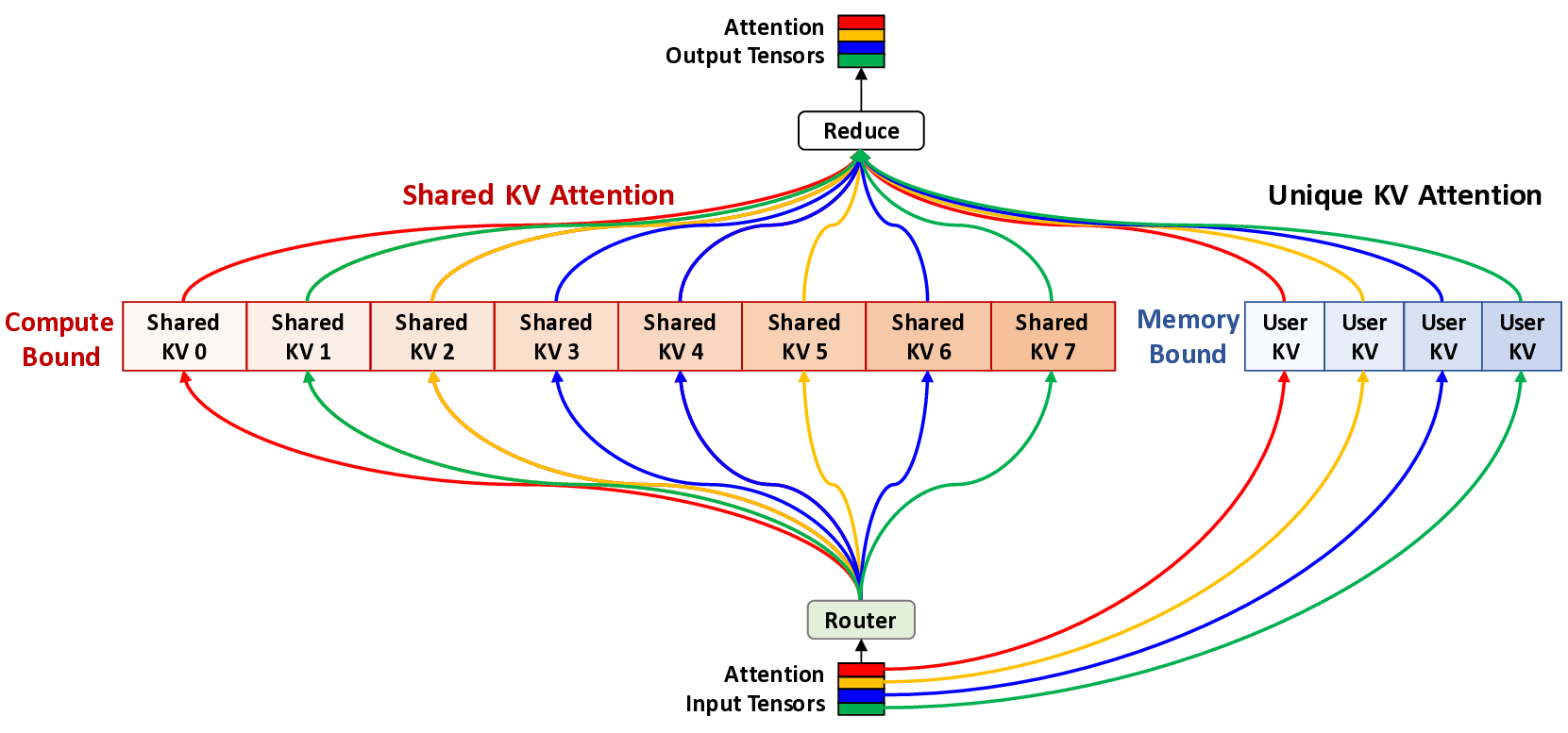
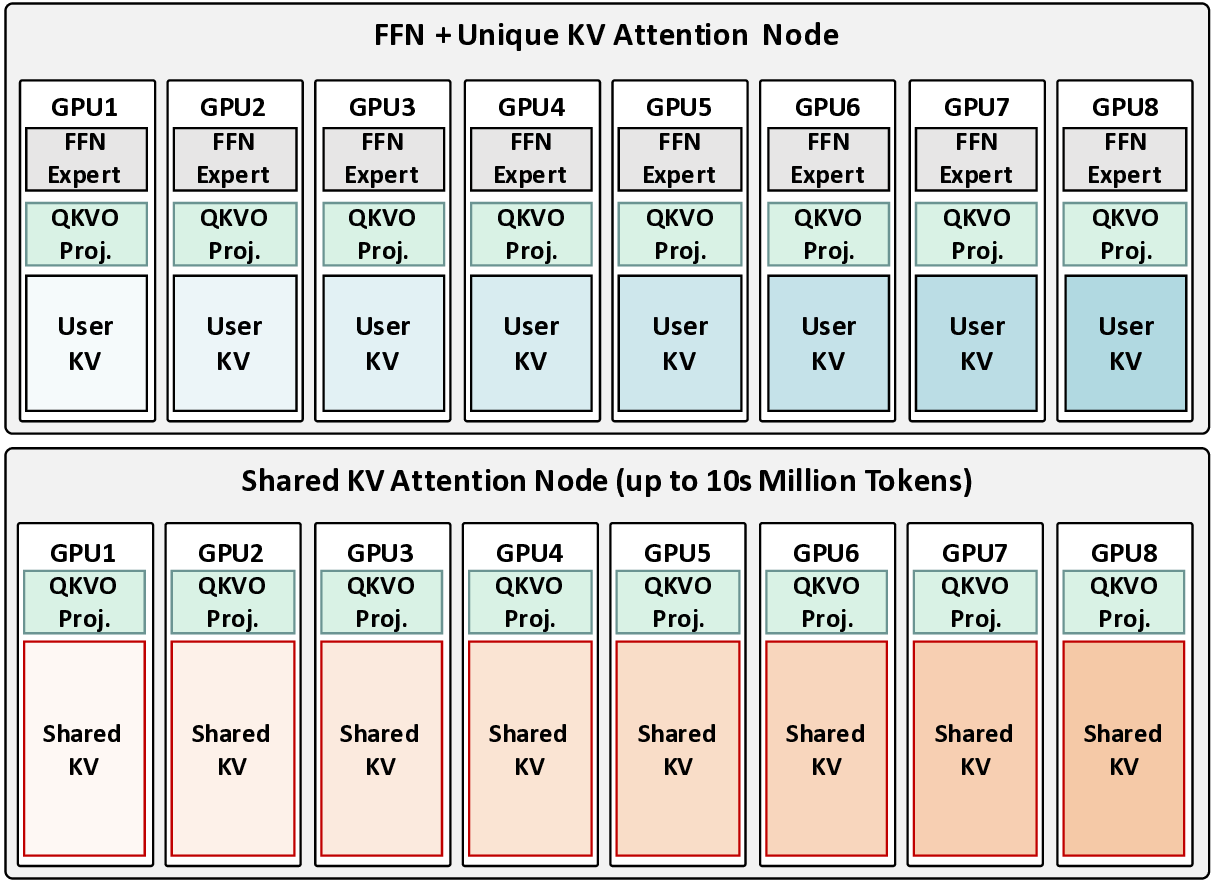
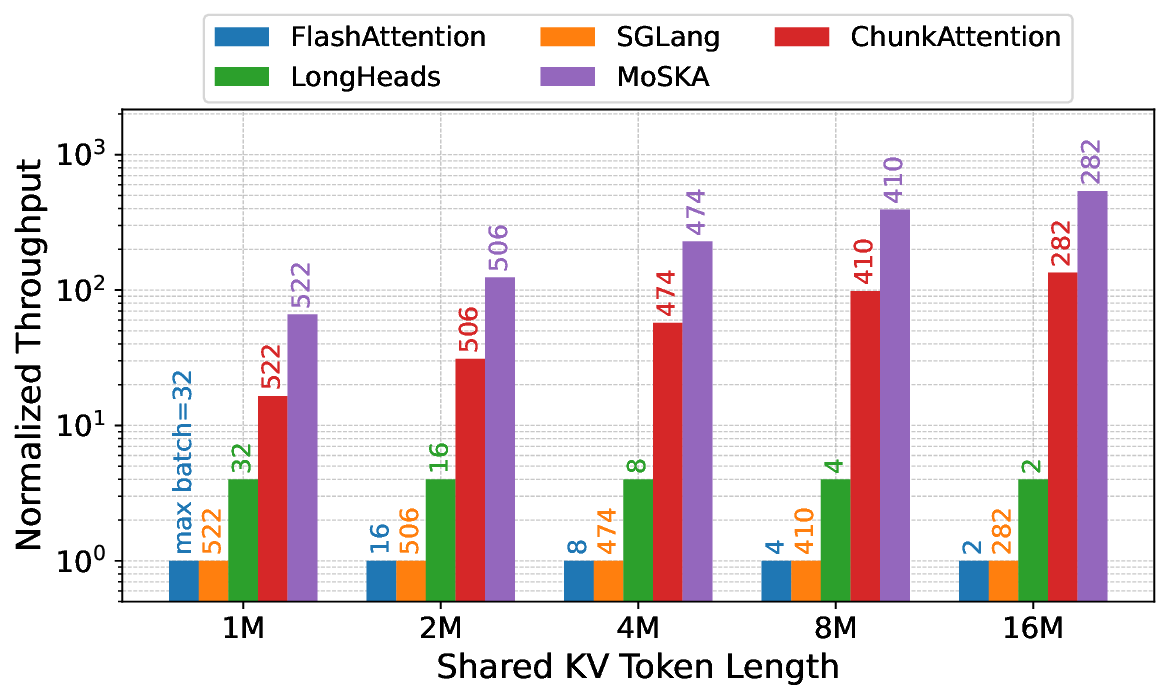
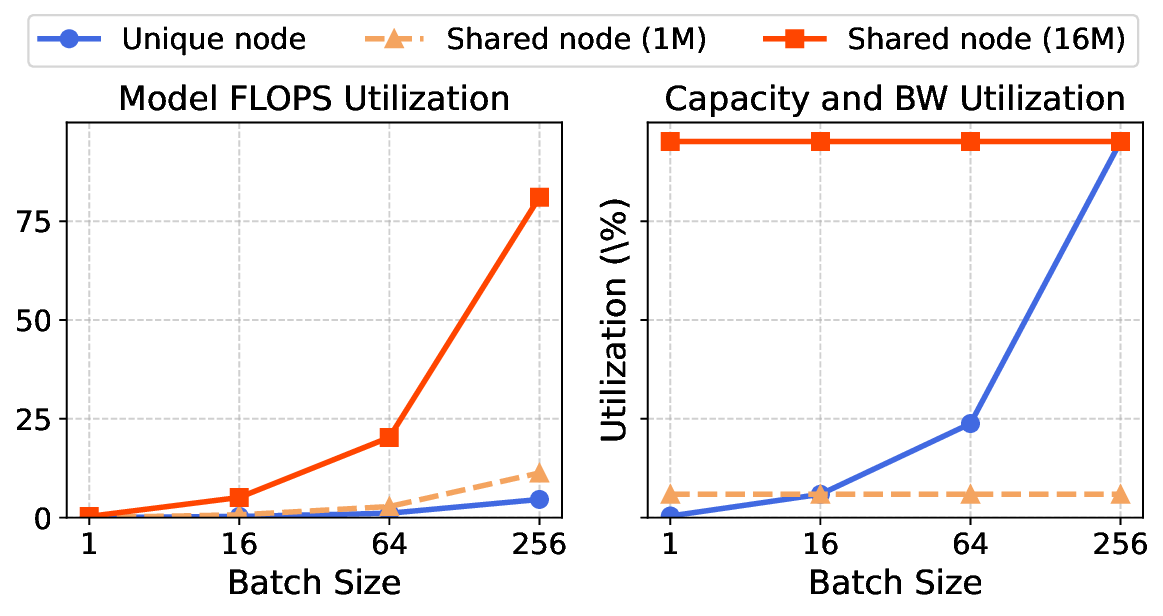
The escalating context length in Large Language Models (LLMs) creates a severe performance bottleneck around the Key-Value (KV) cache, whose memory-bound nature leads to significant GPU under-utilization. This paper introduces Mixture of Shared KV Attention (MoSKA), an architecture that addresses this challenge by exploiting the heterogeneity of context data. It differentiates between per-request unique and massively reused shared sequences. The core of MoSKA is a novel Shared KV Attention mechanism that transforms the attention on shared data from a series of memory-bound GEMV operations into a single, compute-bound GEMM by batching concurrent requests. This is supported by an MoE-inspired sparse attention strategy that prunes the search space and a tailored Disaggregated Infrastructure that specializes hardware for unique and shared data. This comprehensive approach demonstrates a throughput increase of up to 538.7x over baselines in workloads with high context sharing, offering a clear architectural path toward scalable LLM inference.💡 Deep Analysis
📄 Full Content
📸 Image Gallery
Reference
This content is AI-processed based on open access ArXiv data.