Video Text Preservation with Synthetic Text-Rich Videos
Reading time: 1 minute
...
📝 Original Info
- Title: Video Text Preservation with Synthetic Text-Rich Videos
- ArXiv ID: 2511.05573
- Date: 2025-11-04
- Authors: ** (논문에 명시된 저자 정보가 제공되지 않았으므로, 저자명은 확인이 필요합니다.) **
📝 Abstract
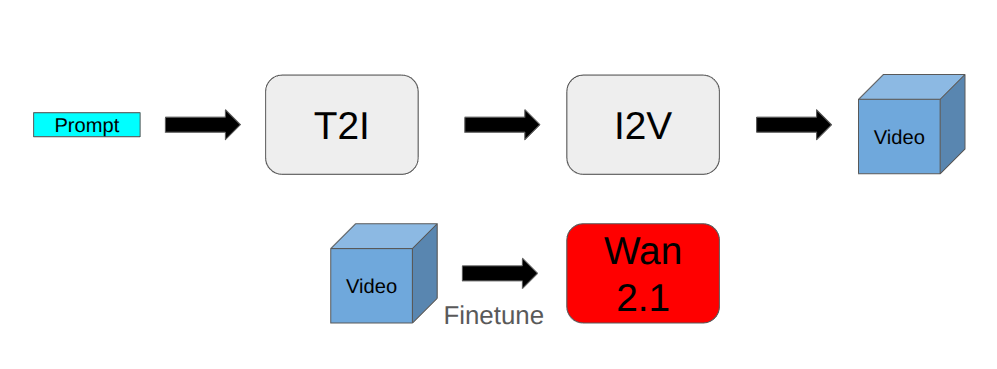
While Text-To-Video (T2V) models have advanced rapidly, they continue to struggle with generating legible and coherent text within videos. In particular, existing models often fail to render correctly even short phrases or words and previous attempts to address this problem are computationally expensive and not suitable for video generation. In this work, we investigate a lightweight approach to improve T2V diffusion models using synthetic supervision. We first generate text-rich images using a text-to-image (T2I) diffusion model, then animate them into short videos using a text-agnostic image-to-video (I2v) model. These synthetic video-prompt pairs are used to fine-tune Wan2.1, a pre-trained T2V model, without any architectural changes. Our results show improvement in short-text legibility and temporal consistency with emerging structural priors for longer text. These findings suggest that curated synthetic data and weak supervision offer a practical path toward improving textual fidelity in T2V generation.💡 Deep Analysis

📄 Full Content
📸 Image Gallery




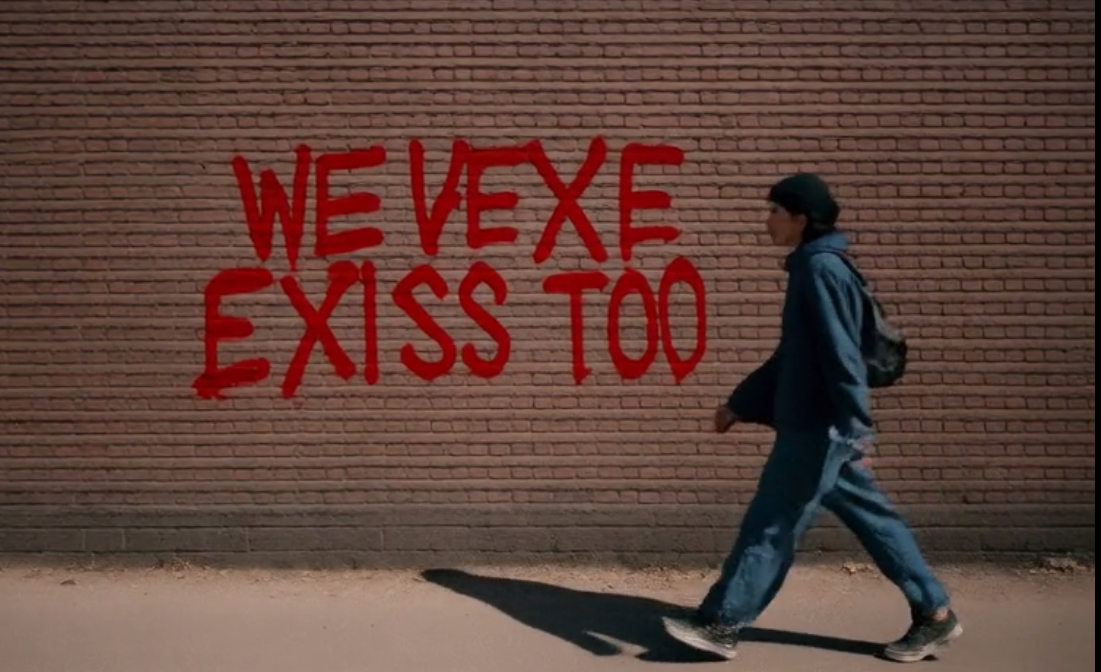


Reference
This content is AI-processed based on open access ArXiv data.