Re-FORC: Adaptive Reward Prediction for Efficient Chain-of-Thought Reasoning
Reading time: 1 minute
...
📝 Original Info
- Title: Re-FORC: Adaptive Reward Prediction for Efficient Chain-of-Thought Reasoning
- ArXiv ID: 2511.02130
- Date: 2025-11-03
- Authors: 정보가 제공되지 않음
📝 Abstract
None💡 Deep Analysis
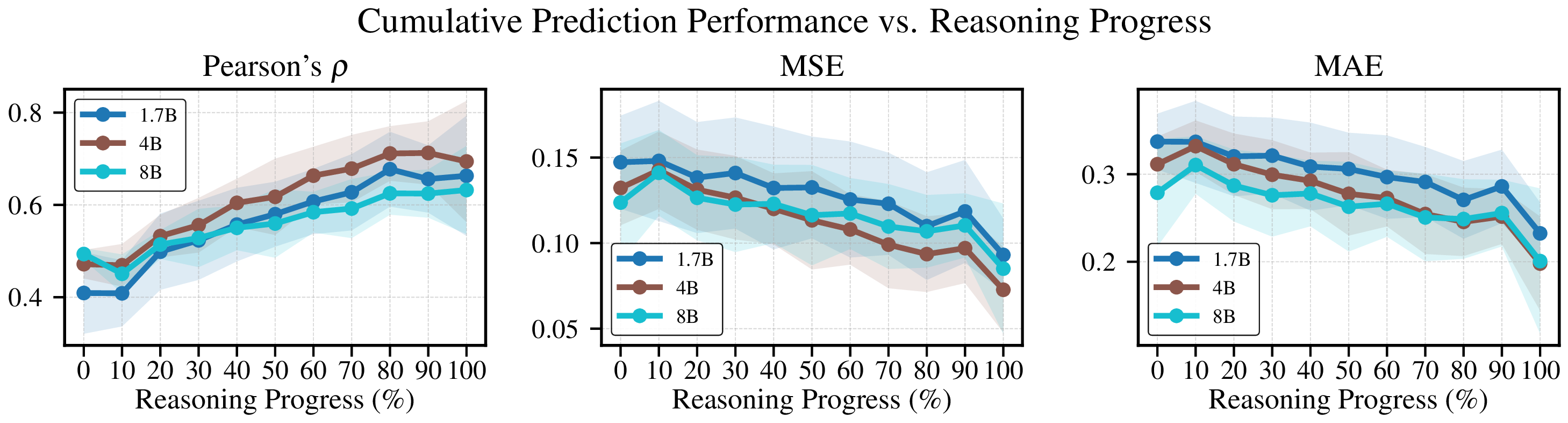
📄 Full Content
📸 Image Gallery
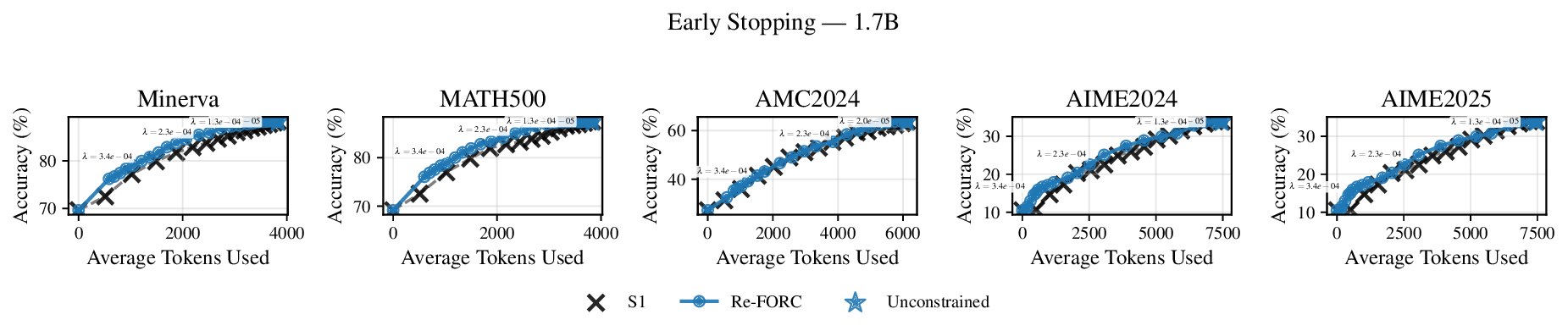
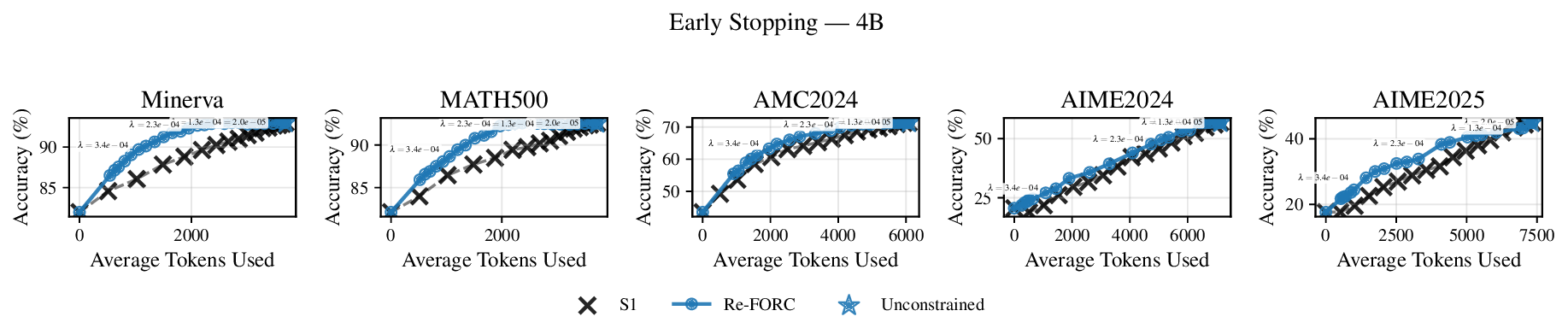
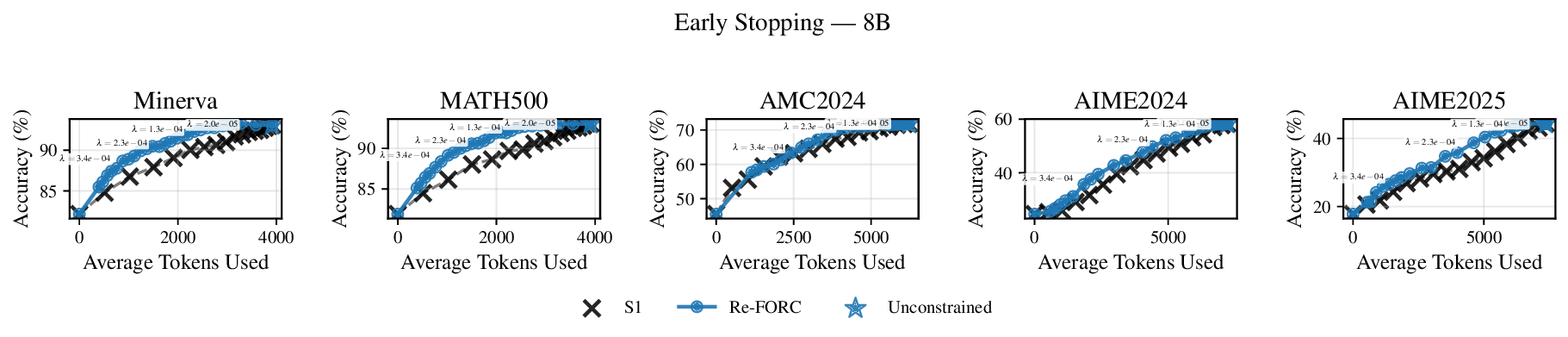
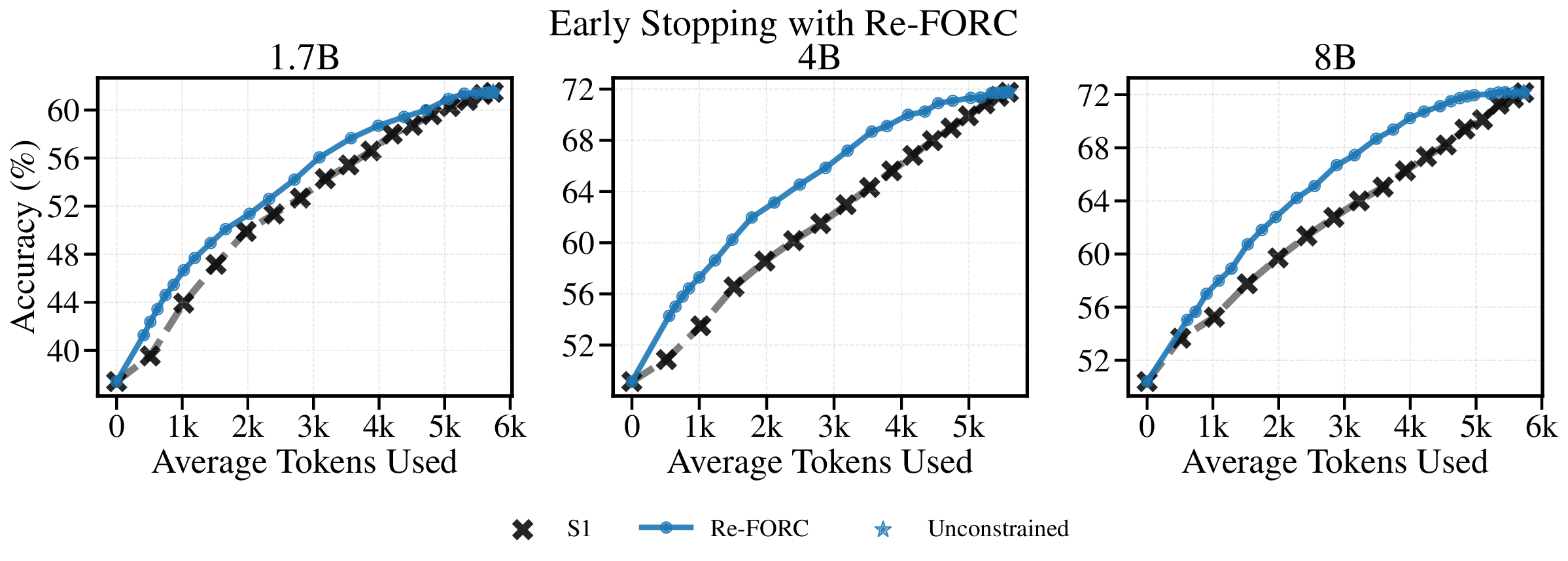
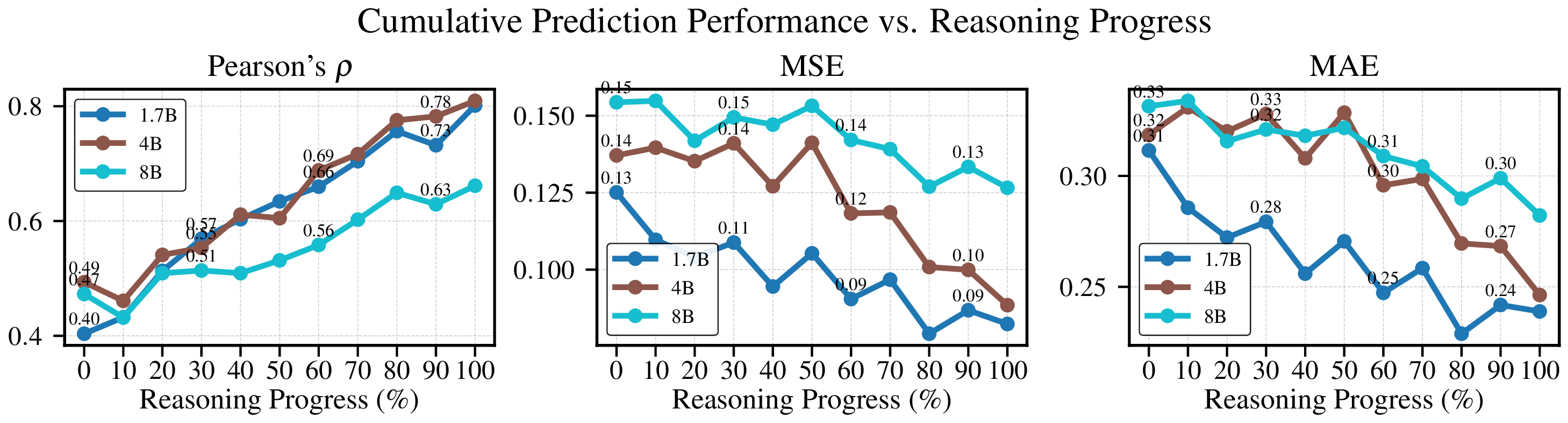
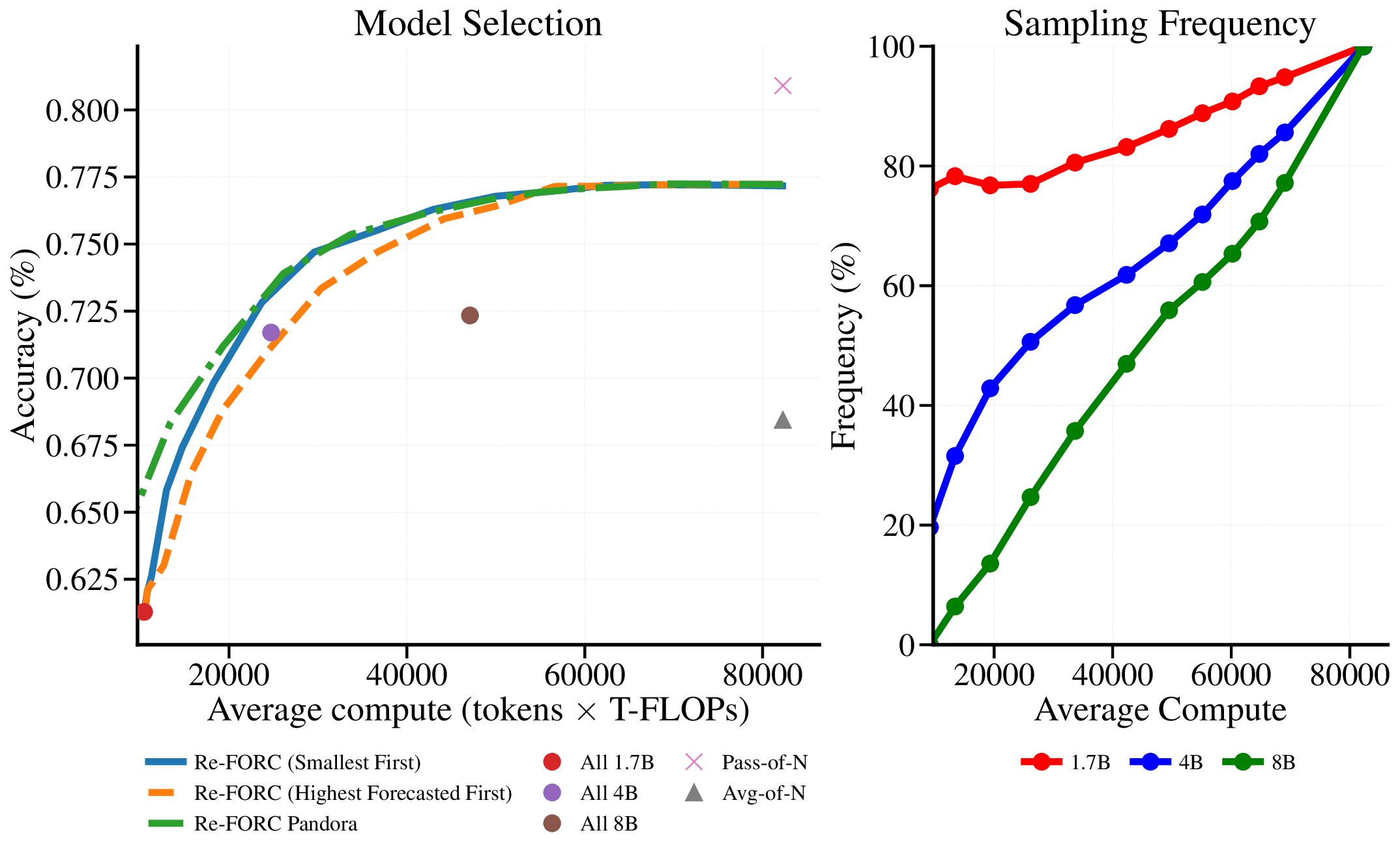
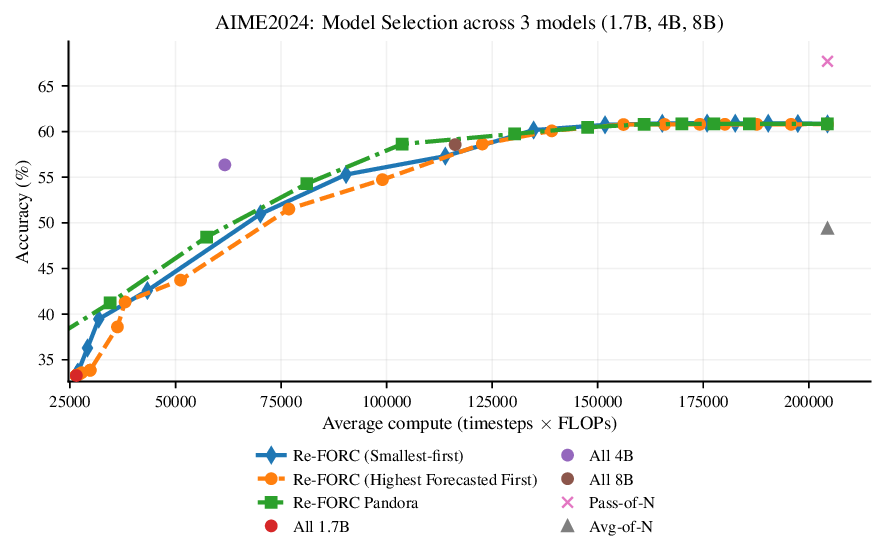
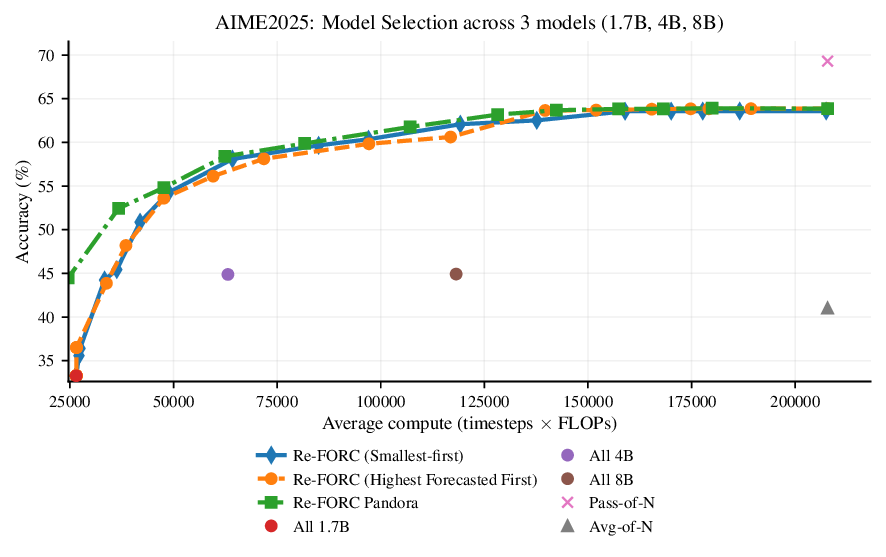
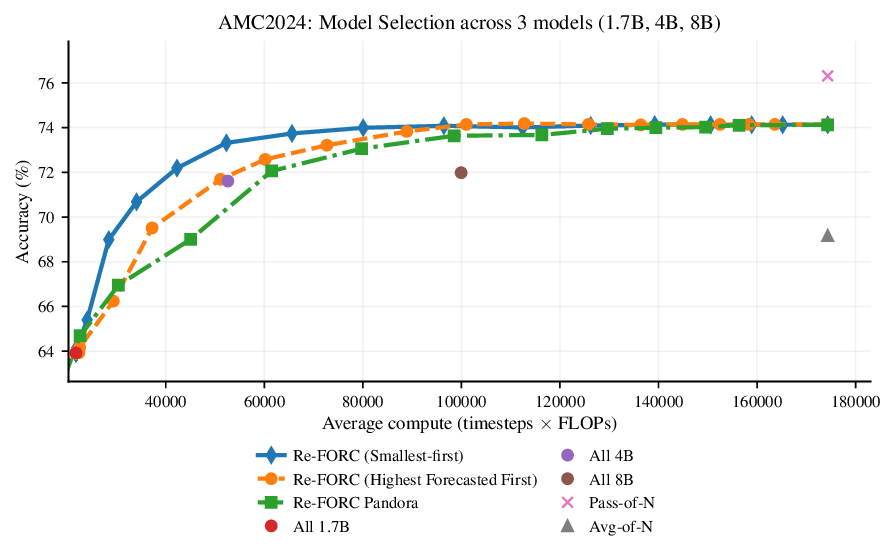
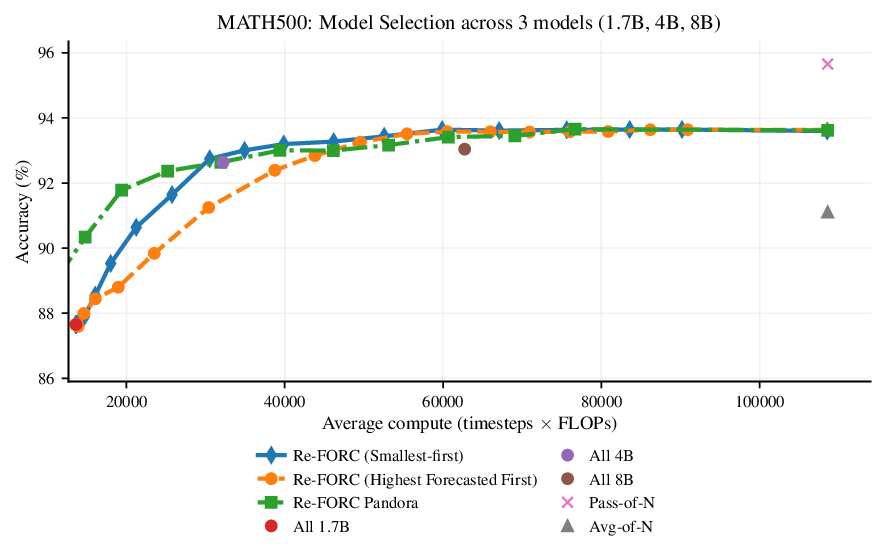
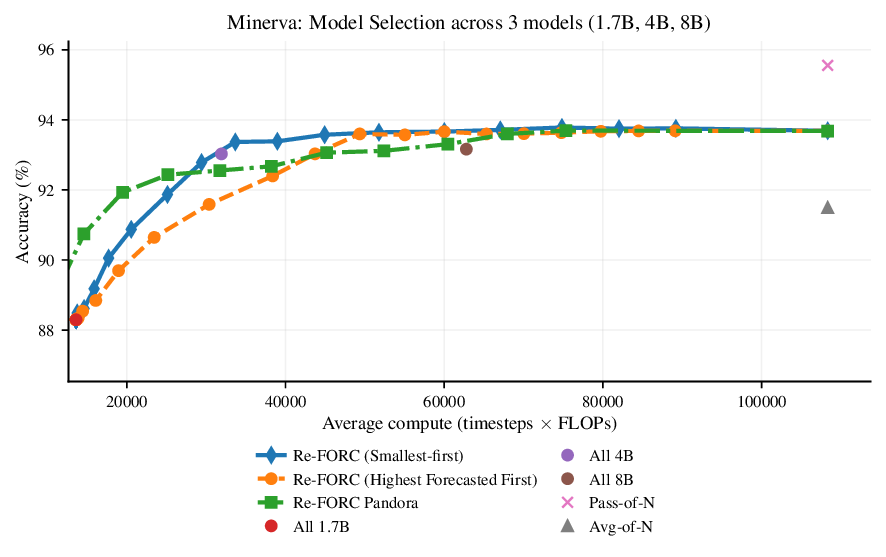
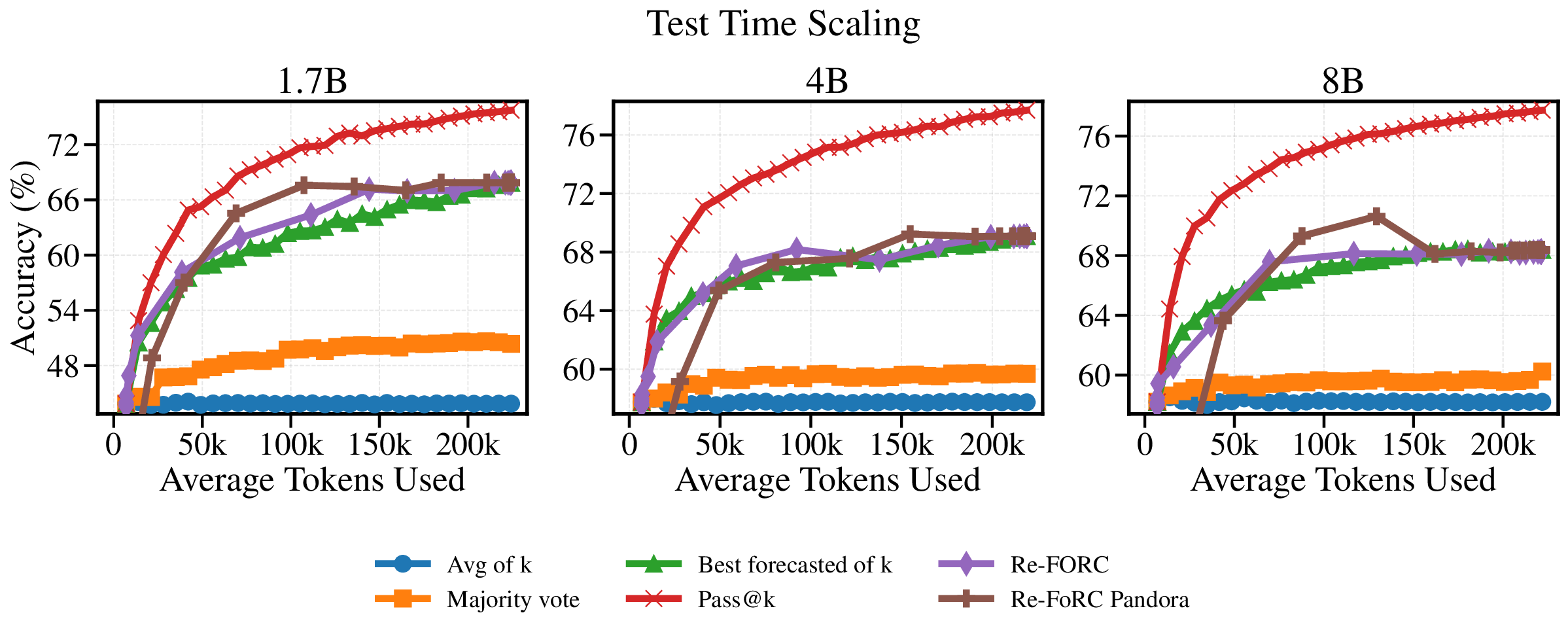
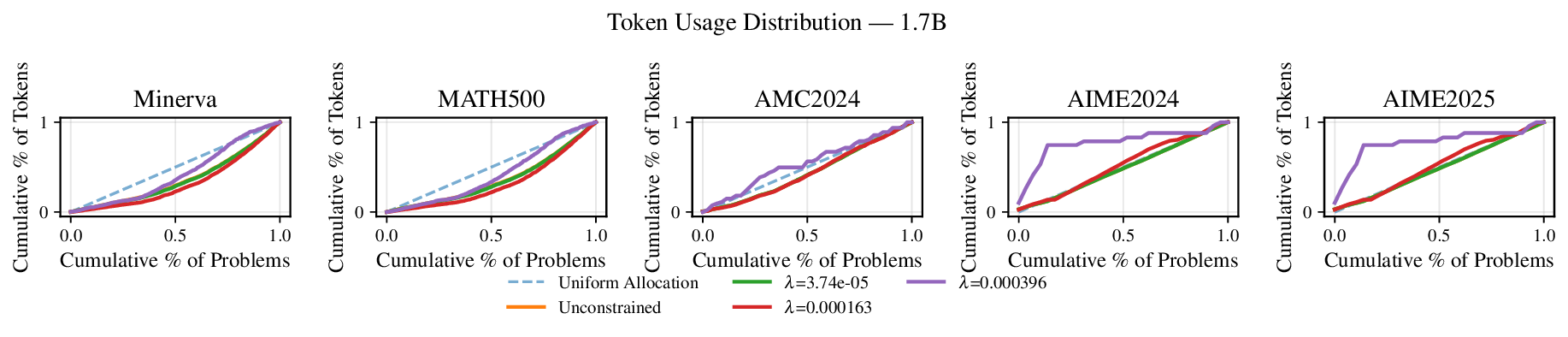
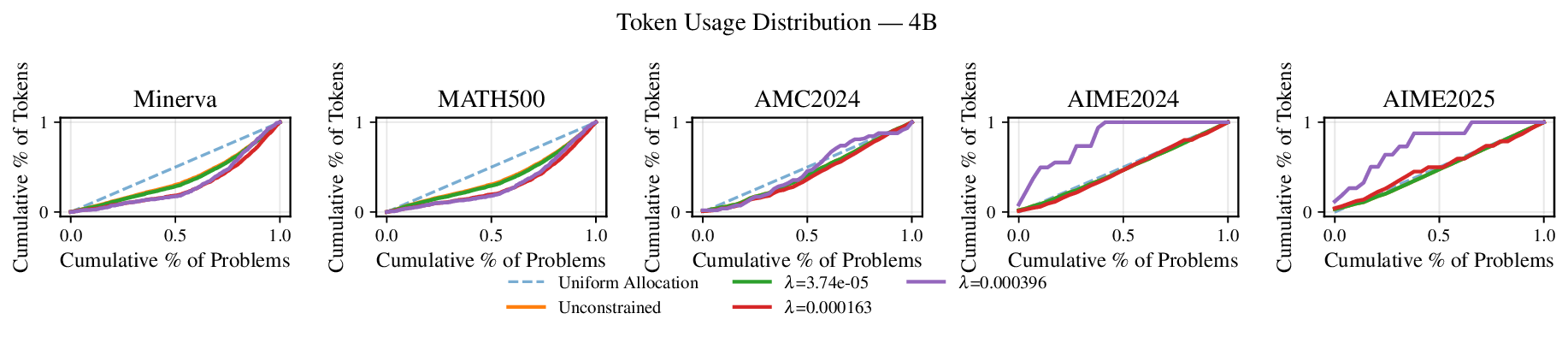
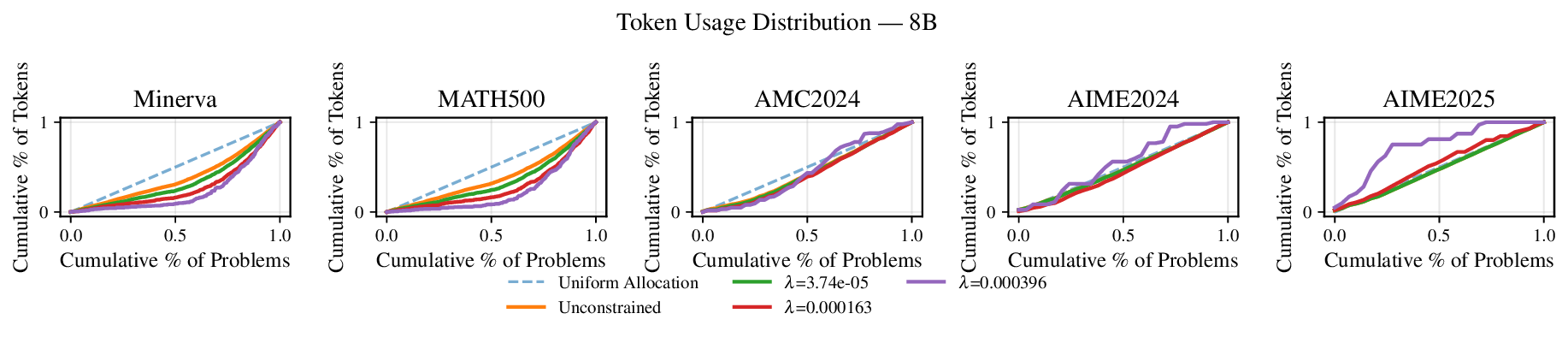
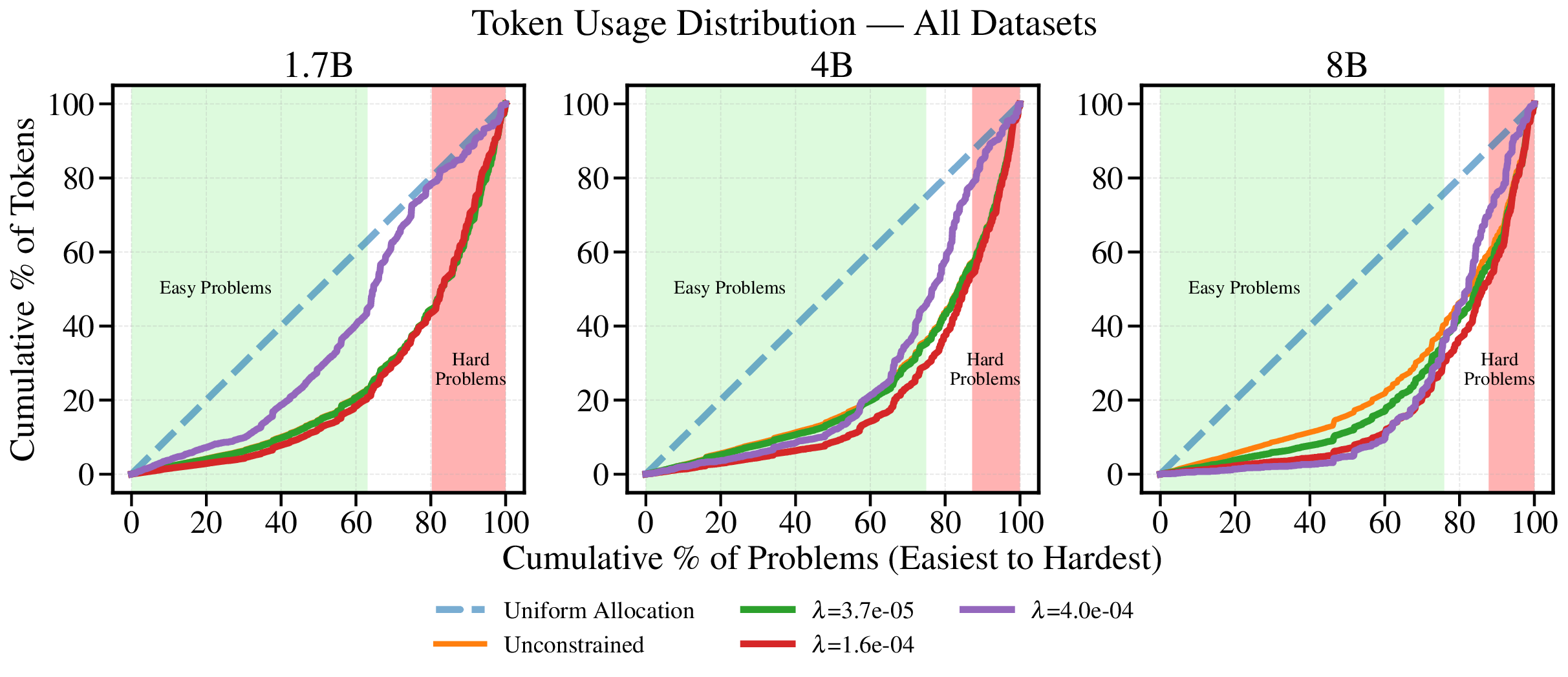
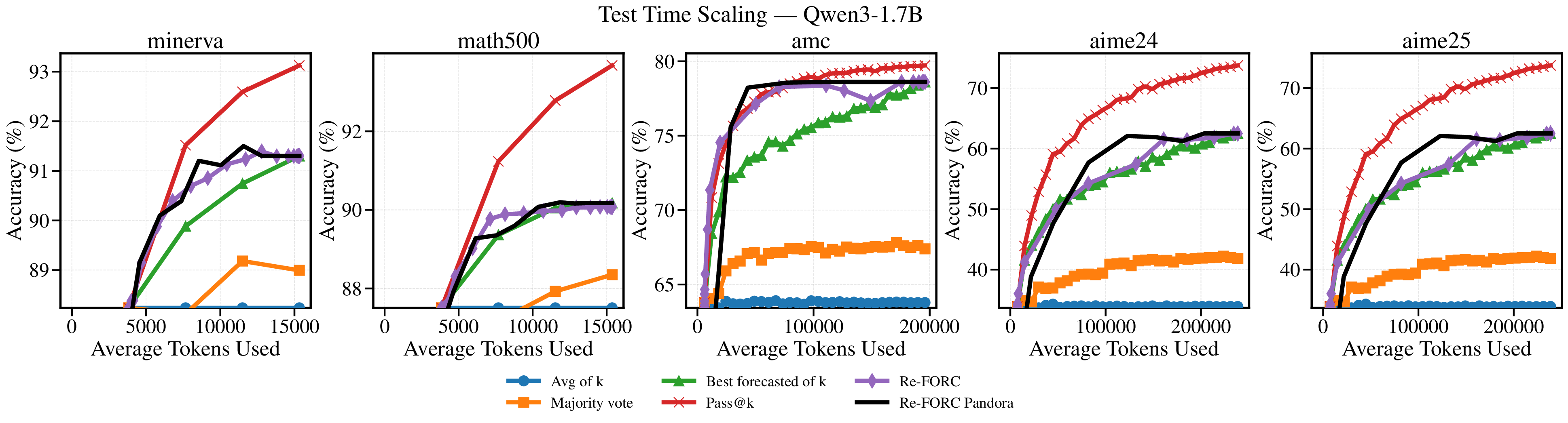
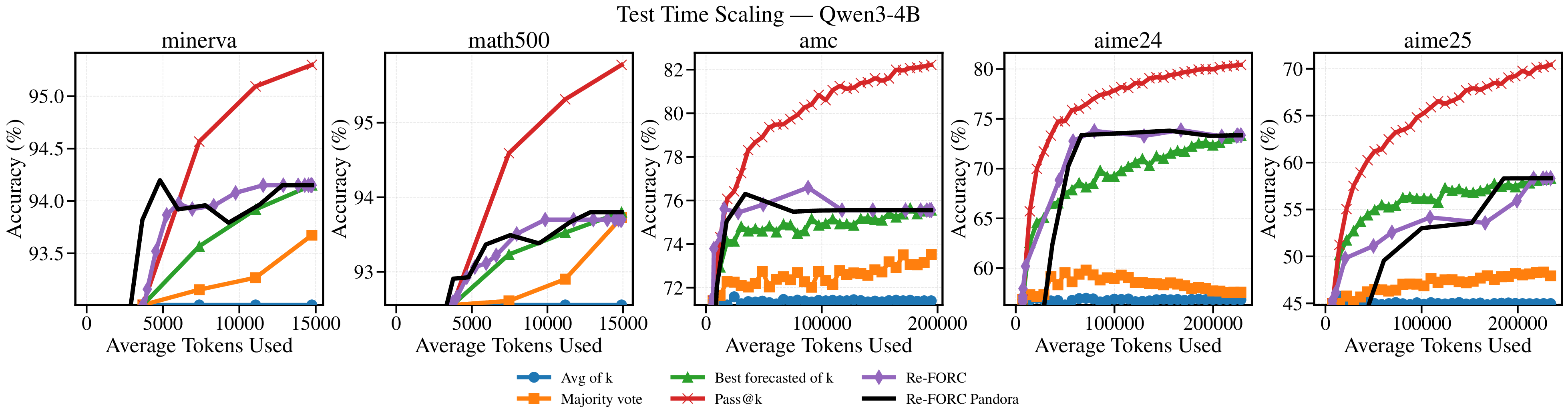
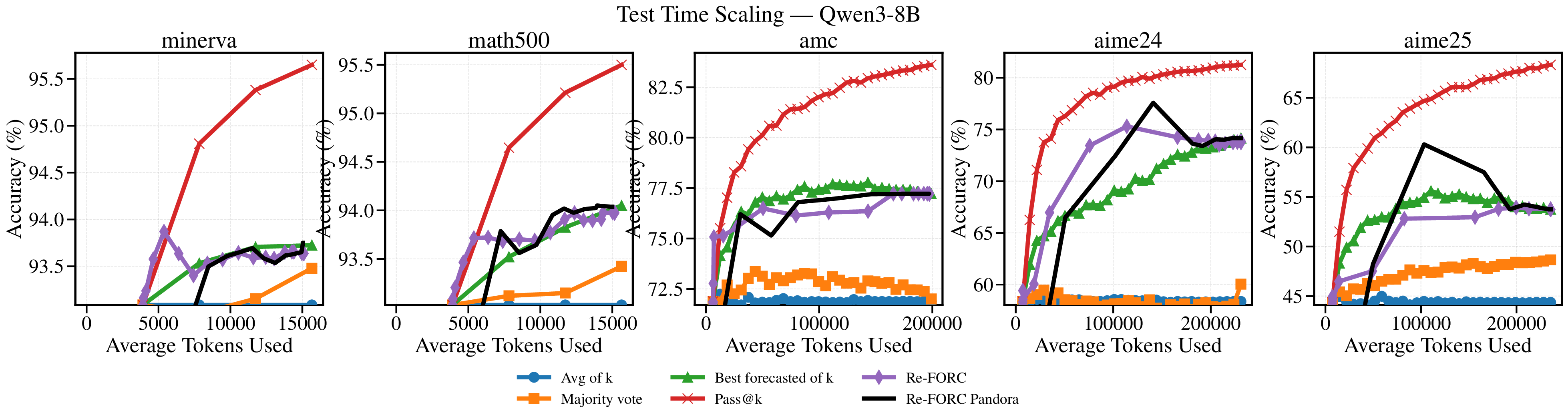
Reference
This content is AI-processed based on open access ArXiv data.