Text-VQA Aug: Pipelined Harnessing of Large Multimodal Models for Automated Synthesis
📝 Original Info
- Title: Text-VQA Aug: Pipelined Harnessing of Large Multimodal Models for Automated Synthesis
- ArXiv ID: 2511.02046
- Date: 2025-11-03
- Authors: ** 제공된 논문 정보에 저자 명단이 포함되어 있지 않습니다. (정보 없음) **
📝 Abstract
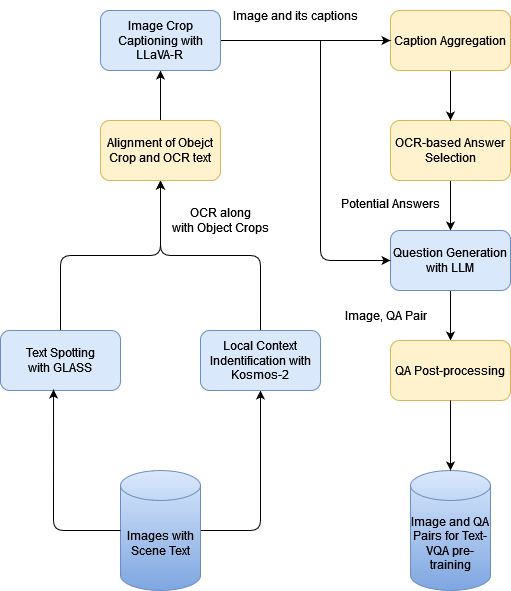
Creation of large-scale databases for Visual Question Answering tasks pertaining to the text data in a scene (text-VQA) involves skilful human annotation, which is tedious and challenging. With the advent of foundation models that handle vision and language modalities, and with the maturity of OCR systems, it is the need of the hour to establish an end-to-end pipeline that can synthesize Question-Answer (QA) pairs based on scene-text from a given image. We propose a pipeline for automated synthesis for text-VQA dataset that can produce faithful QA pairs, and which scales up with the availability of scene text data. Our proposed method harnesses the capabilities of multiple models and algorithms involving OCR detection and recognition (text spotting), region of interest (ROI) detection, caption generation, and question generation. These components are streamlined into a cohesive pipeline to automate the synthesis and validation of QA pairs. To the best of our knowledge, this is the first pipeline proposed to automatically synthesize and validate a large-scale text-VQA dataset comprising around 72K QA pairs based on around 44K images.💡 Deep Analysis
📄 Full Content
📸 Image Gallery











Reference
This content is AI-processed based on open access ArXiv data.