Better Call CLAUSE: A Discrepancy Benchmark for Auditing LLMs Legal Reasoning Capabilities
Reading time: 2 minute
...
📝 Original Info
- Title: Better Call CLAUSE: A Discrepancy Benchmark for Auditing LLMs Legal Reasoning Capabilities
- ArXiv ID: 2511.00340
- Date: 2025-11-01
- Authors: ** 논문에 명시된 저자 정보가 제공되지 않았습니다. (보통 해당 정보는 논문 첫 페이지 혹은 메타데이터에 포함됩니다.) **
📝 Abstract
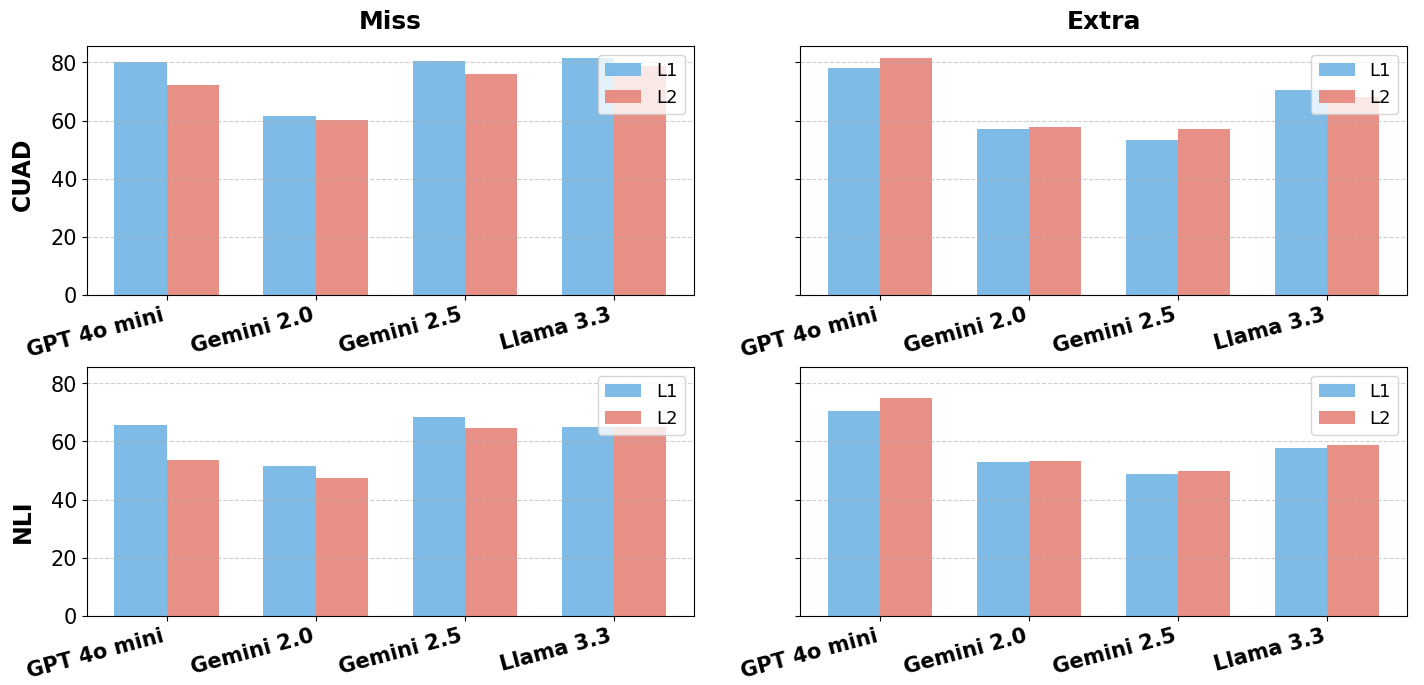
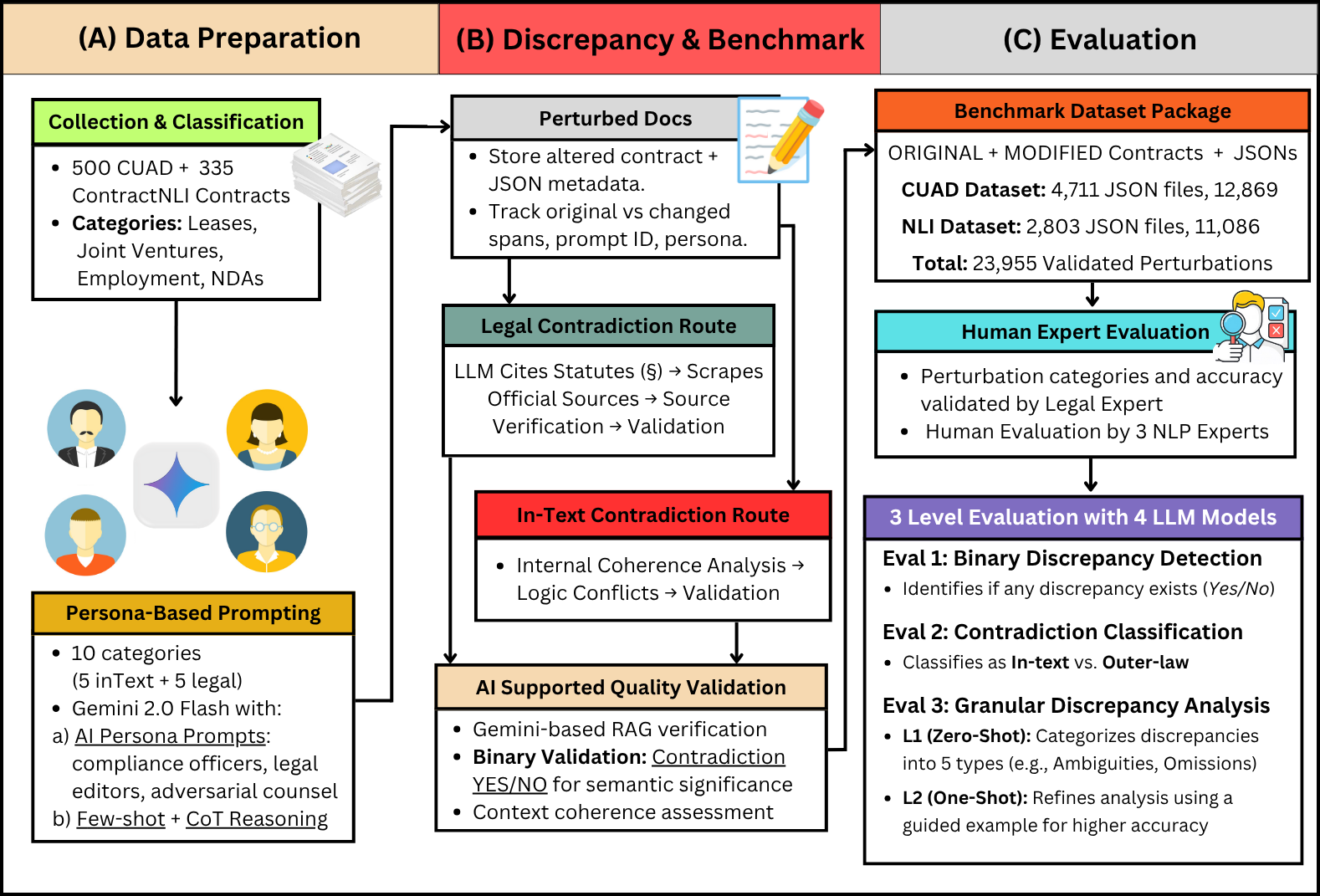
The rapid integration of large language models (LLMs) into high-stakes legal work has exposed a critical gap: no benchmark exists to systematically stress-test their reliability against the nuanced, adversarial, and often subtle flaws present in real-world contracts. To address this, we introduce CLAUSE, a first-of-its-kind benchmark designed to evaluate the fragility of an LLM's legal reasoning. We study the capabilities of LLMs to detect and reason about fine-grained discrepancies by producing over 7500 real-world perturbed contracts from foundational datasets like CUAD and ContractNLI. Our novel, persona-driven pipeline generates 10 distinct anomaly categories, which are then validated against official statutes using a Retrieval-Augmented Generation (RAG) system to ensure legal fidelity. We use CLAUSE to evaluate leading LLMs' ability to detect embedded legal flaws and explain their significance. Our analysis shows a key weakness: these models often miss subtle errors and struggle even more to justify them legally. Our work outlines a path to identify and correct such reasoning failures in legal AI.💡 Deep Analysis
📄 Full Content
📸 Image Gallery


Reference
This content is AI-processed based on open access ArXiv data.