A Retrospect to Multi-prompt Learning across Vision and Language
📝 Original Info
- Title: A Retrospect to Multi-prompt Learning across Vision and Language
- ArXiv ID: 2511.00191
- Date: 2025-10-31
- Authors: ** 논문에 명시된 저자 정보가 제공되지 않았습니다. **
📝 Abstract
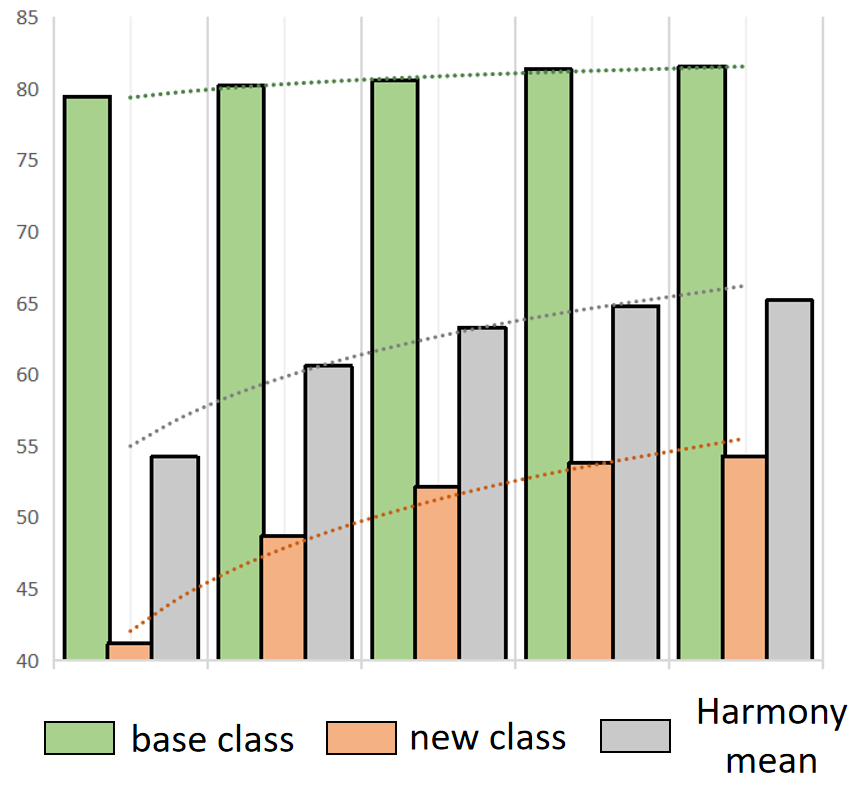
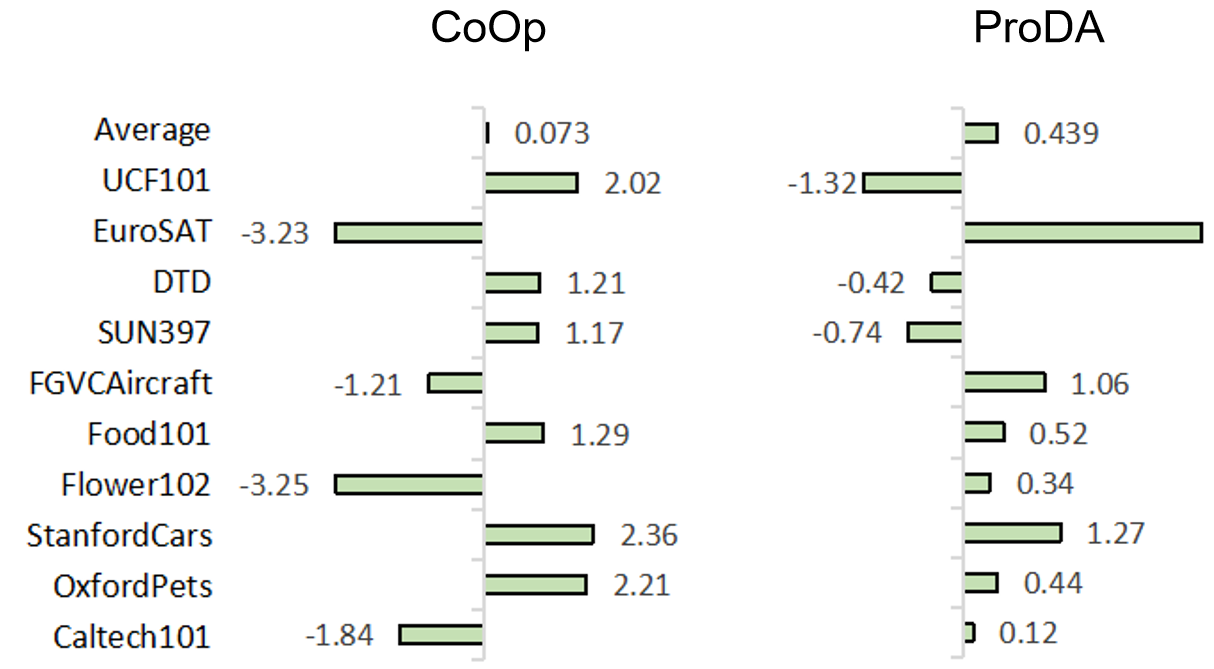
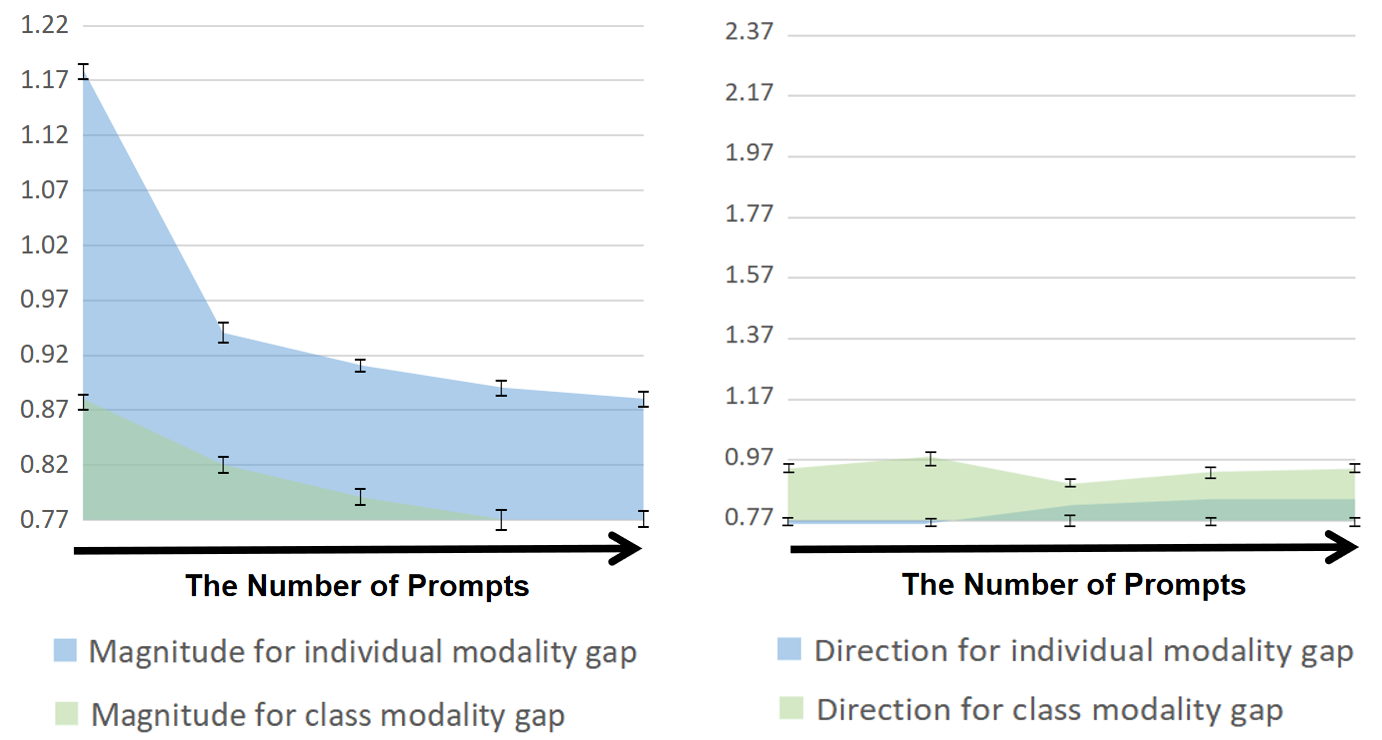
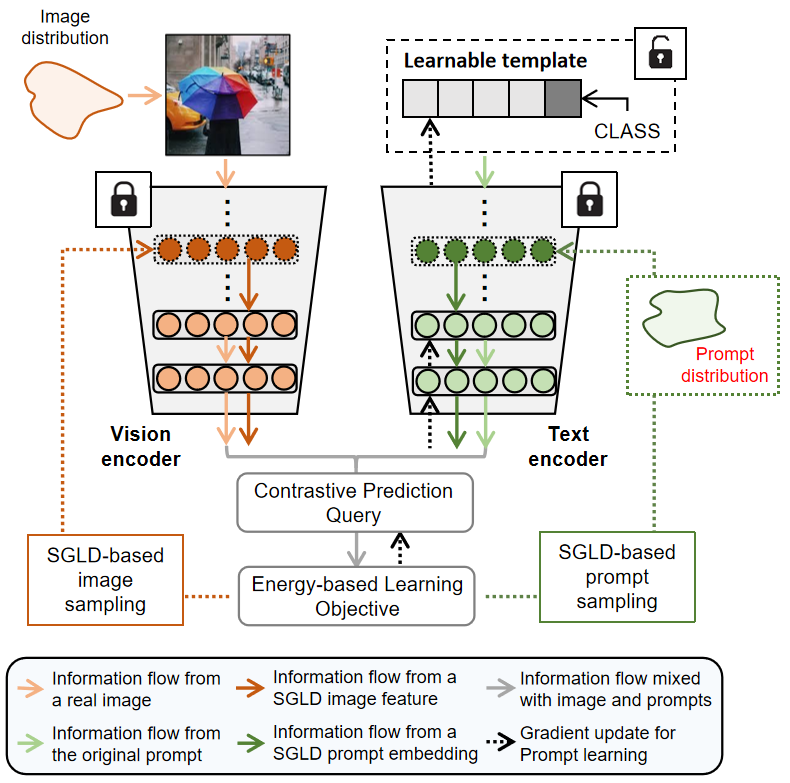
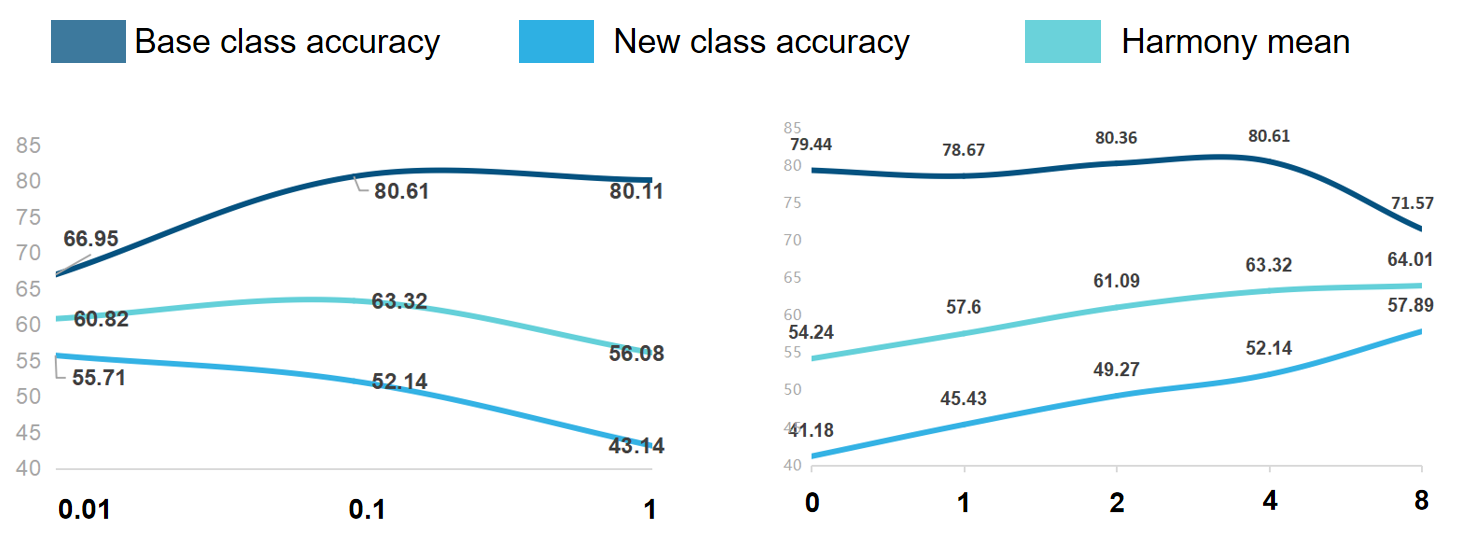
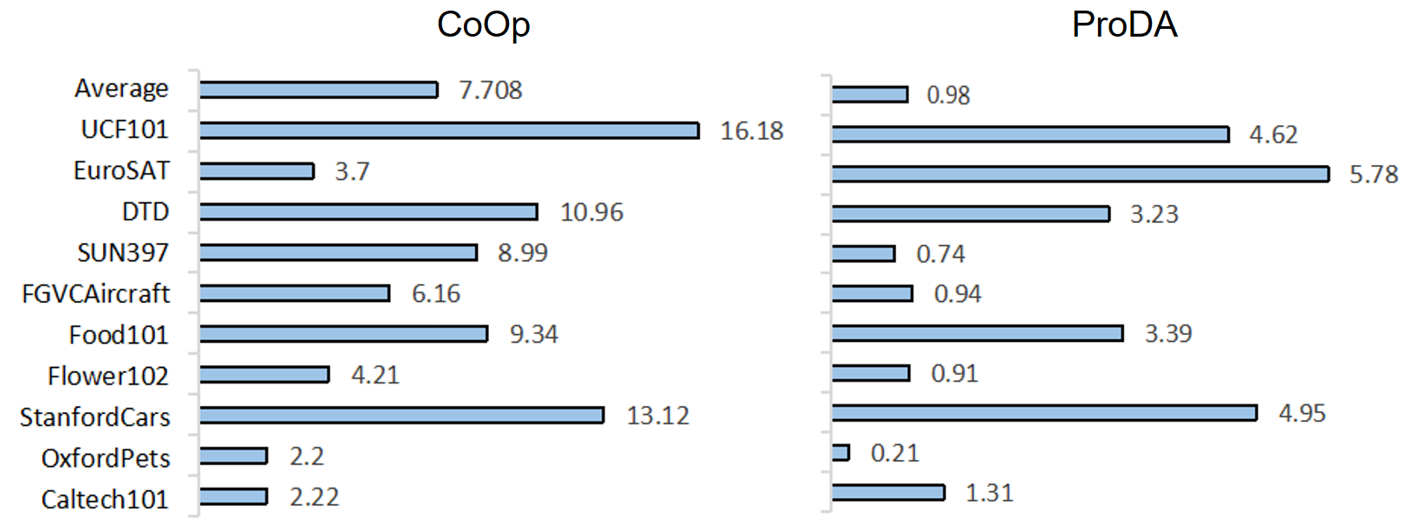
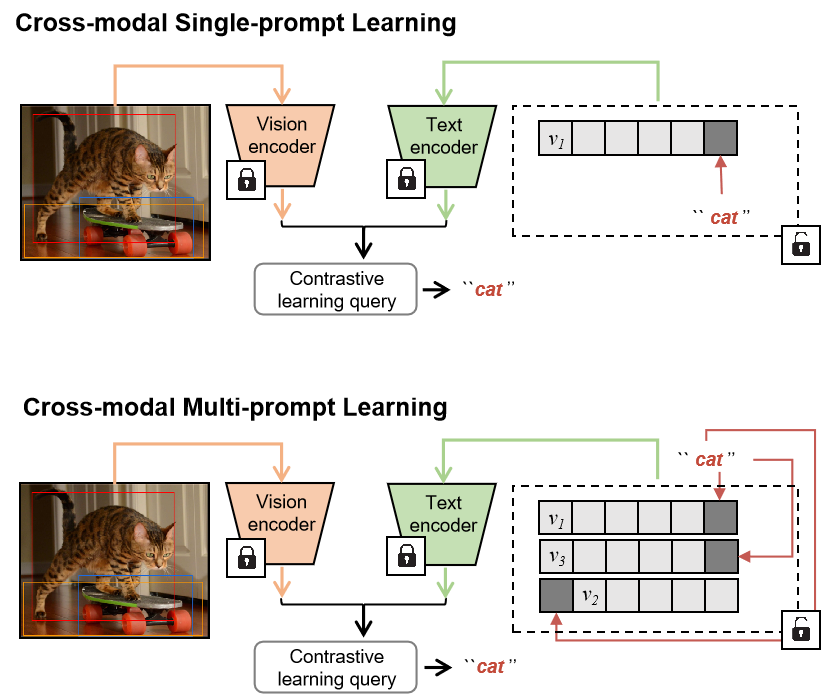
The vision community is undergoing the unprecedented progress with the emergence of Vision-Language Pretraining Models (VLMs). Prompt learning plays as the holy grail of accessing VLMs since it enables their fast adaptation to downstream tasks with limited resources. Whereas existing researches milling around single-prompt paradigms, rarely investigate the technical potential behind their multi-prompt learning counterparts. This paper aims to provide a principled retrospect for vision-language multi-prompt learning. We extend the recent constant modality gap phenomenon to learnable prompts and then, justify the superiority of vision-language transfer with multi-prompt augmentation, empirically and theoretically. In terms of this observation, we propose an Energy-based Multi-prompt Learning (EMPL) to generate multiple prompt embeddings by drawing instances from an energy-based distribution, which is implicitly defined by VLMs. So our EMPL is not only parameter-efficient but also rigorously lead to the balance between in-domain and out-of-domain open-vocabulary generalization. Comprehensive experiments have been conducted to justify our claims and the excellence of EMPL.💡 Deep Analysis
📄 Full Content
📸 Image Gallery
Reference
This content is AI-processed based on open access ArXiv data.