Scalable Processing-Near-Memory for 1M-Token LLM Inference: CXL-Enabled KV-Cache Management Beyond GPU Limits
Reading time: 2 minute
...
📝 Original Info
- Title: Scalable Processing-Near-Memory for 1M-Token LLM Inference: CXL-Enabled KV-Cache Management Beyond GPU Limits
- ArXiv ID: 2511.00321
- Date: 2025-10-31
- Authors: ** 정보 없음 (제공된 텍스트에 저자 정보가 포함되지 않음) **
📝 Abstract
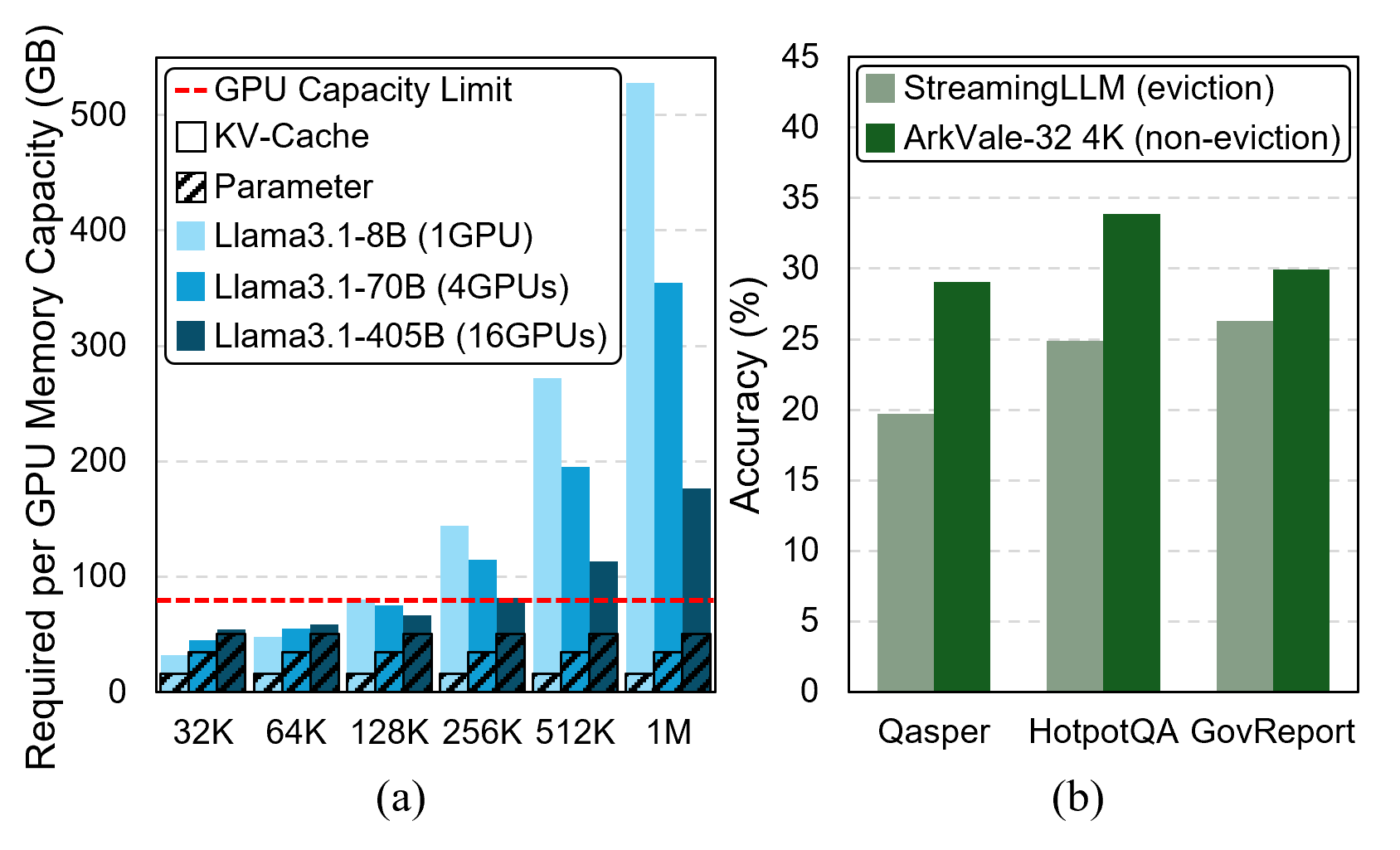
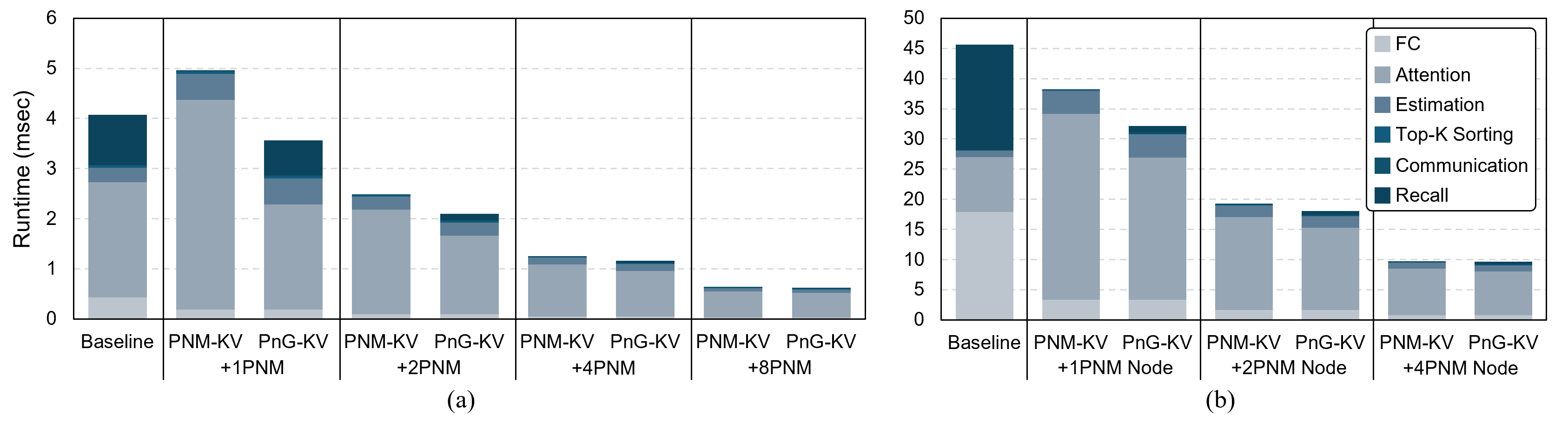
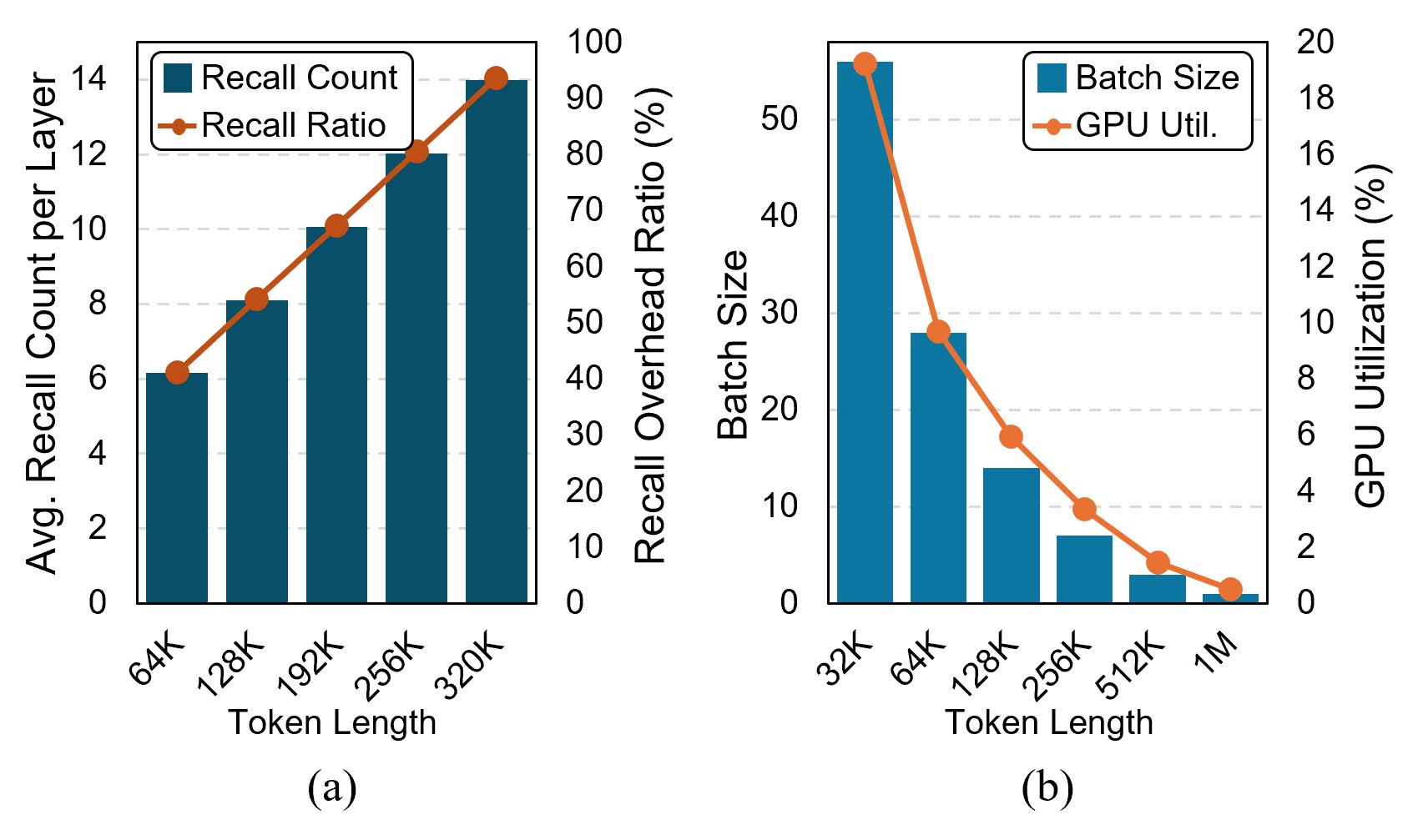
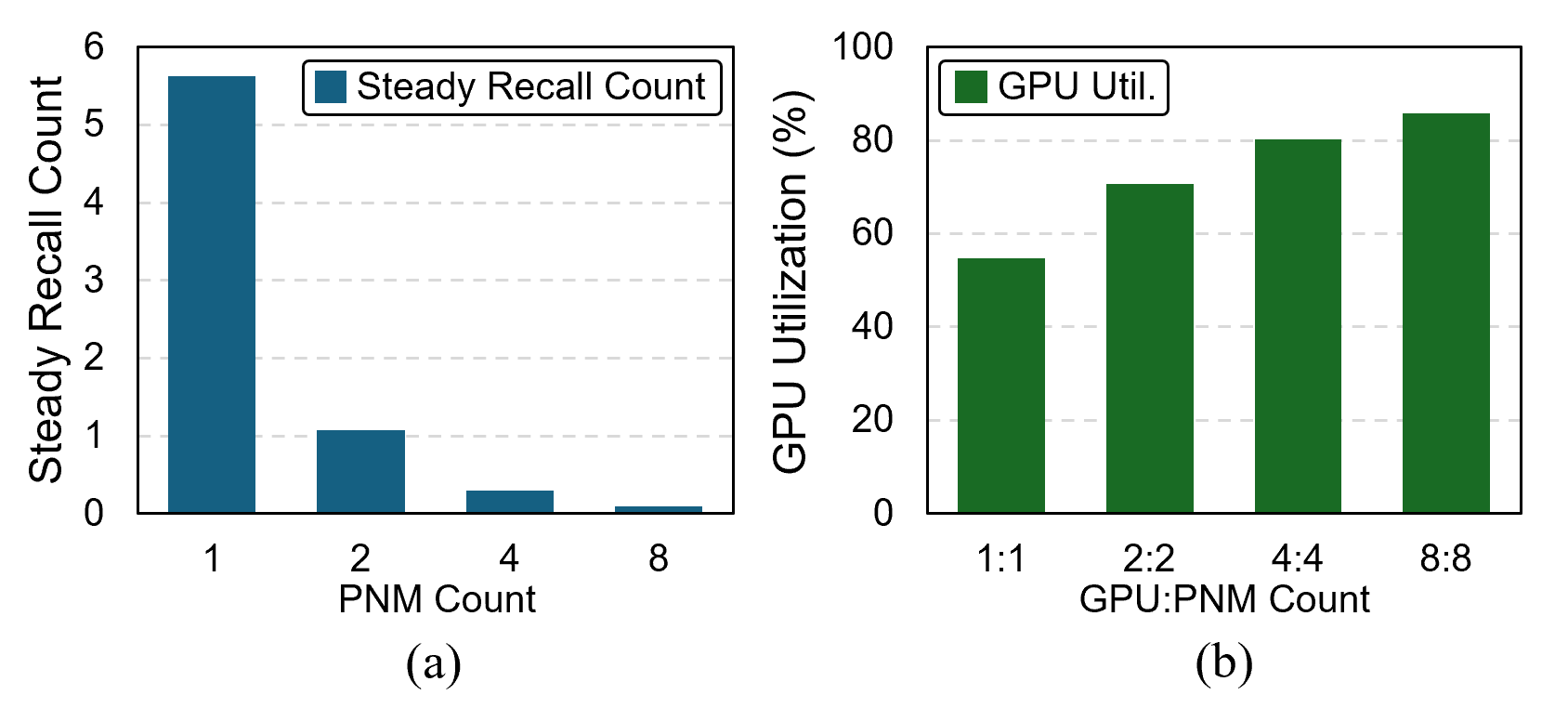
The expansion of context windows in large language models (LLMs) to multi-million tokens introduces severe memory and compute bottlenecks, particularly in managing the growing Key-Value (KV) cache. While Compute Express Link (CXL) enables non-eviction frameworks that offload the full KV-cache to scalable external memory, these frameworks still suffer from costly data transfers when recalling non-resident KV tokens to limited GPU memory as context lengths increase. This work proposes scalable Processing-Near-Memory (PNM) for 1M-Token LLM Inference, a CXL-enabled KV-cache management system that coordinates memory and computation beyond GPU limits. Our design offloads token page selection to a PNM accelerator within CXL memory, eliminating costly recalls and enabling larger GPU batch sizes. We further introduce a hybrid parallelization strategy and a steady-token selection mechanism to enhance compute efficiency and scalability. Implemented atop a state-of-the-art CXL-PNM system, our solution delivers consistent performance gains for LLMs with up to 405B parameters and 1M-token contexts. Our PNM-only offloading scheme (PNM-KV) and GPU-PNM hybrid with steady-token execution (PnG-KV) achieve up to 21.9x throughput improvement, up to 60x lower energy per token, and up to 7.3x better total cost efficiency than the baseline, demonstrating that CXL-enabled multi-PNM architectures can serve as a scalable backbone for future long-context LLM inference.💡 Deep Analysis
📄 Full Content
📸 Image Gallery
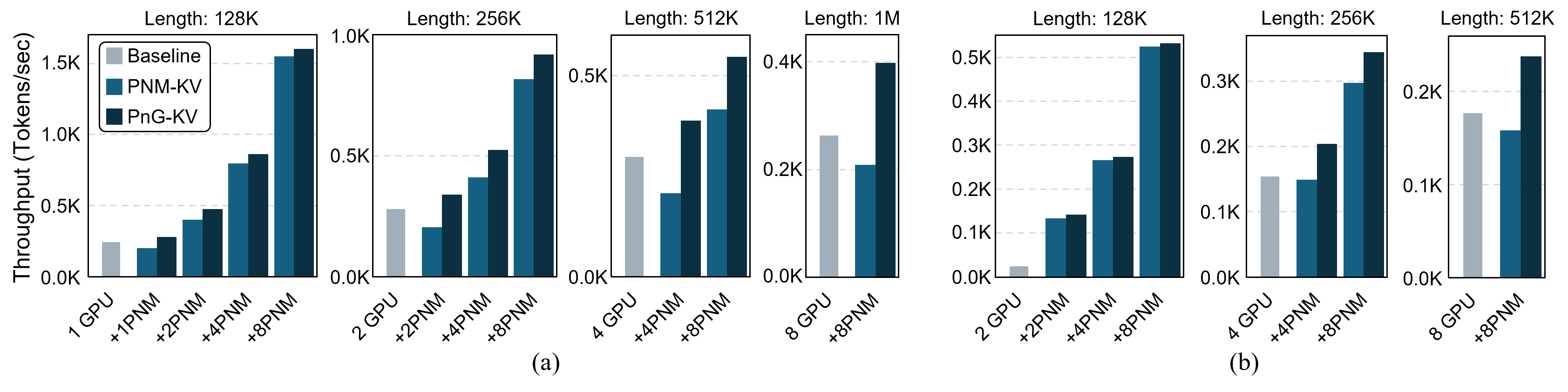
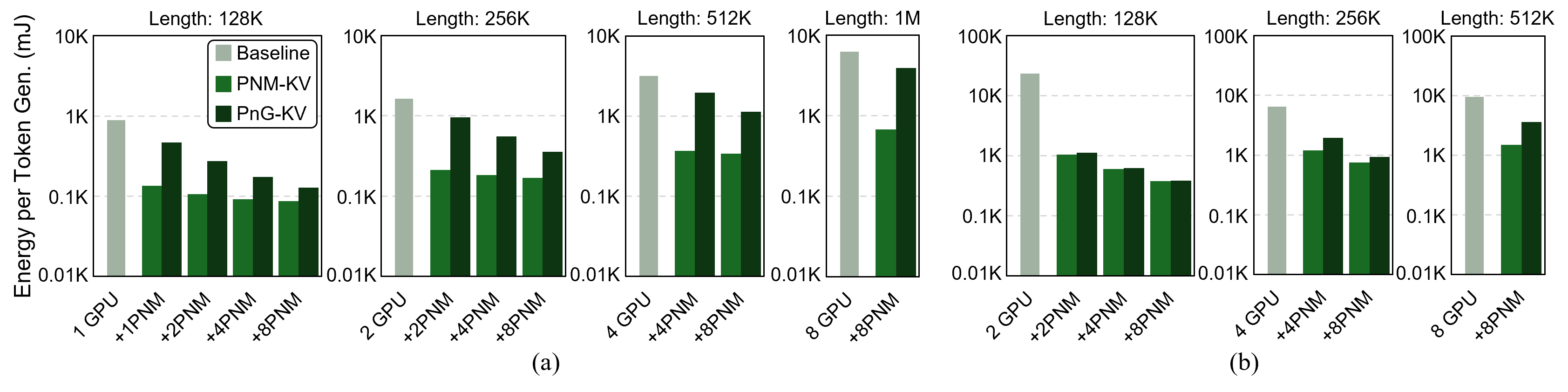
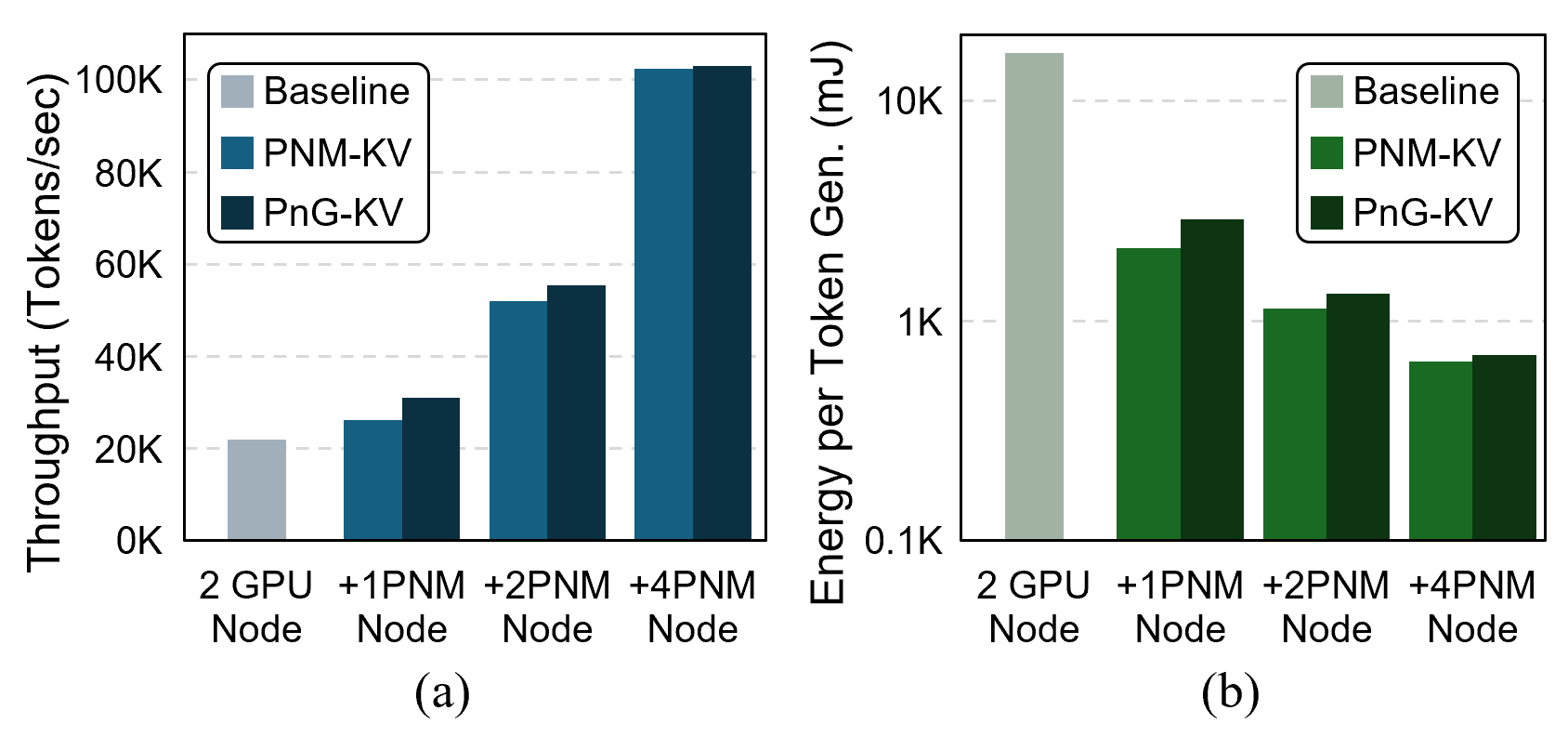
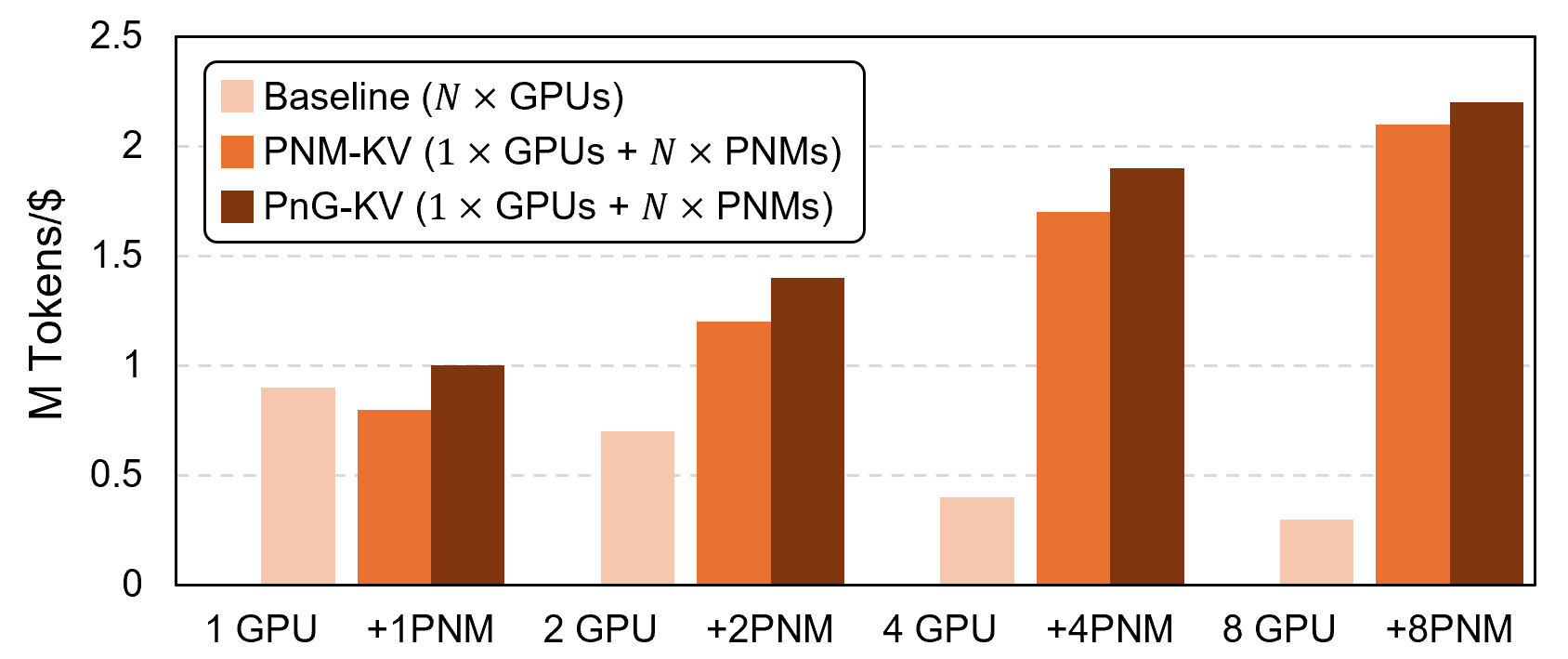
Reference
This content is AI-processed based on open access ArXiv data.