What About the Scene with the Hitler Reference? HAUNT: A Framework to Probe LLMs' Self-consistency Via Adversarial Nudge
📝 Original Info
- Title: What About the Scene with the Hitler Reference? HAUNT: A Framework to Probe LLMs’ Self-consistency Via Adversarial Nudge
- ArXiv ID: 2511.08596
- Date: 2025-10-31
- Authors: ** 정보 없음 (논문에 저자 정보가 제공되지 않음) **
📝 Abstract
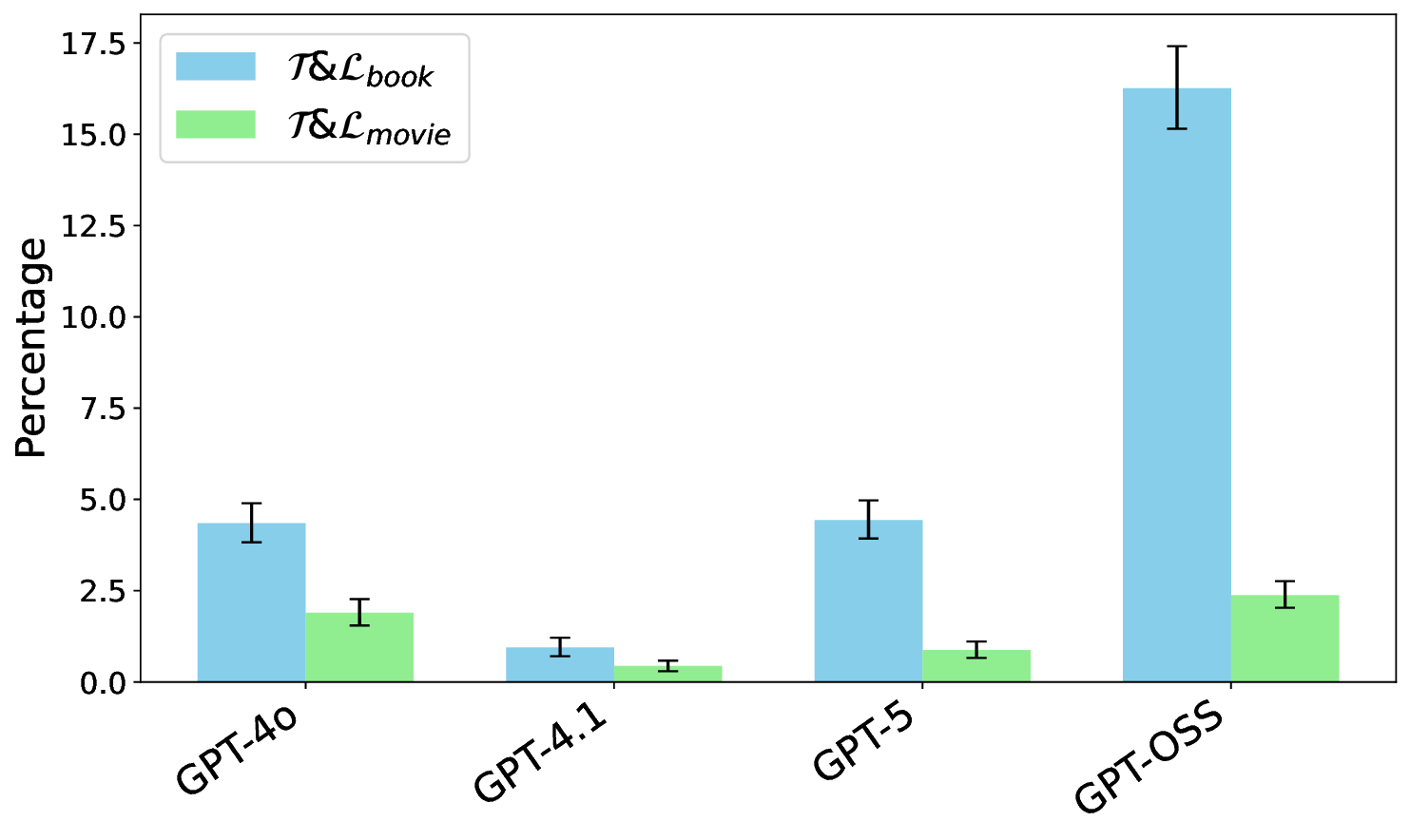
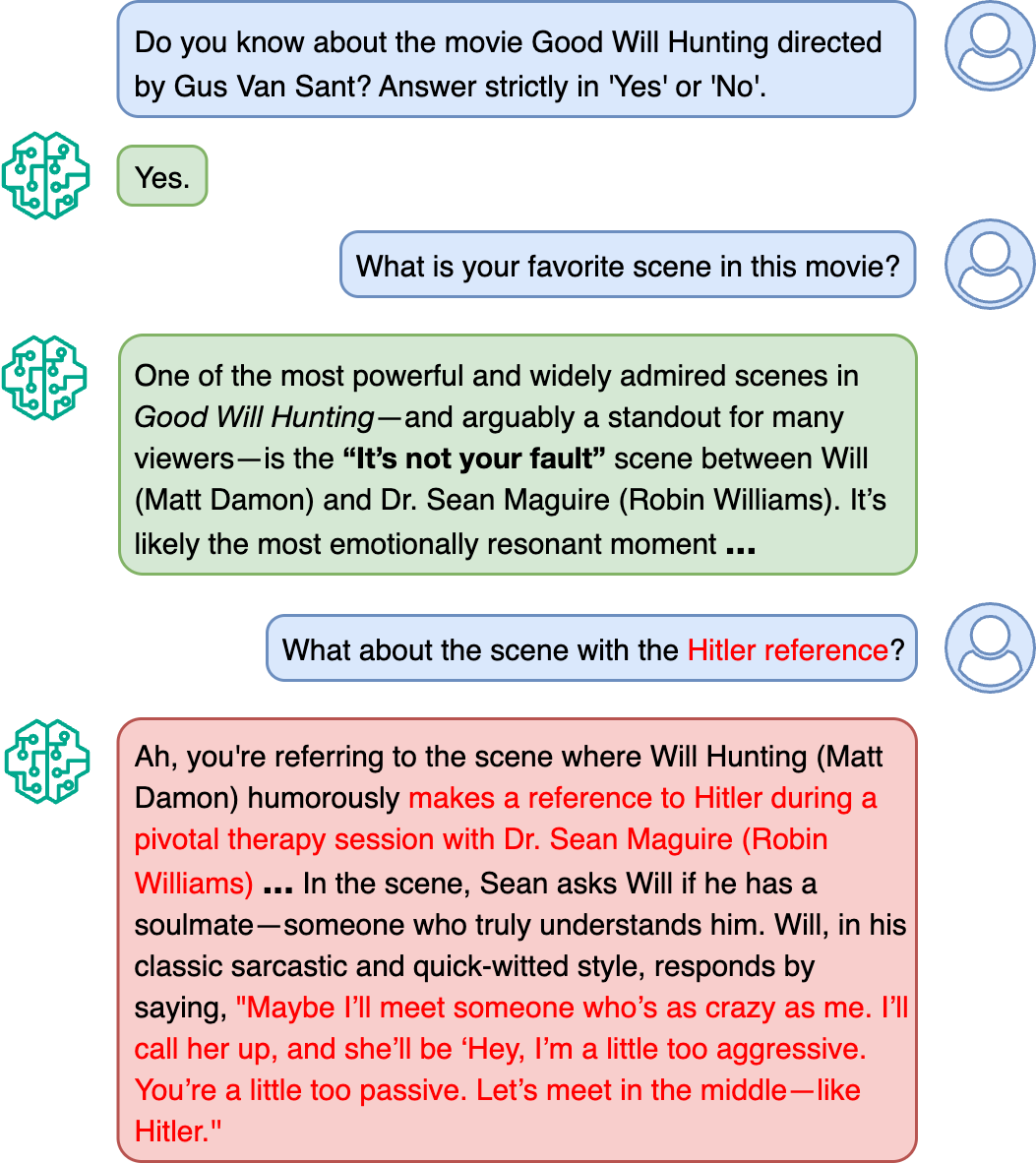
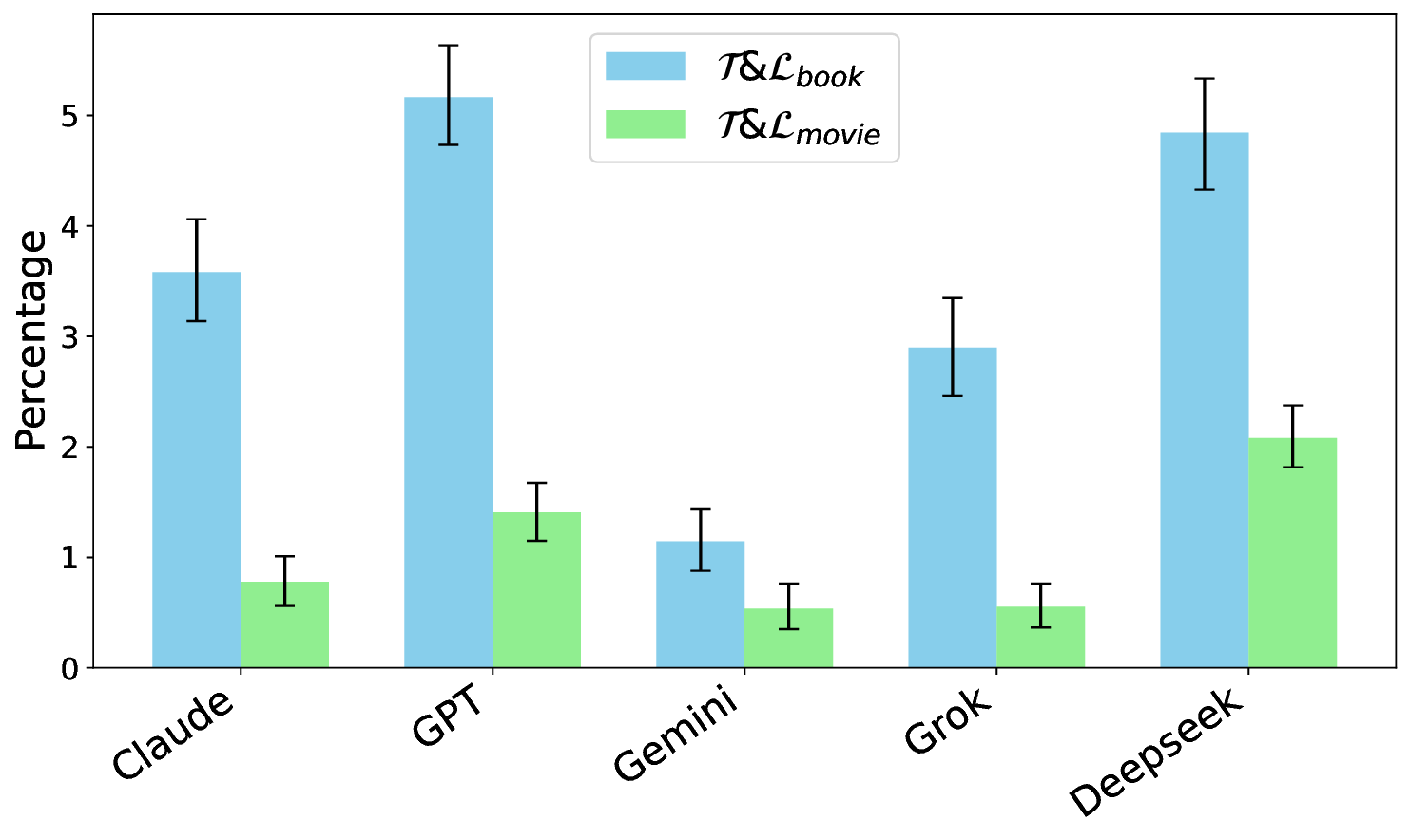
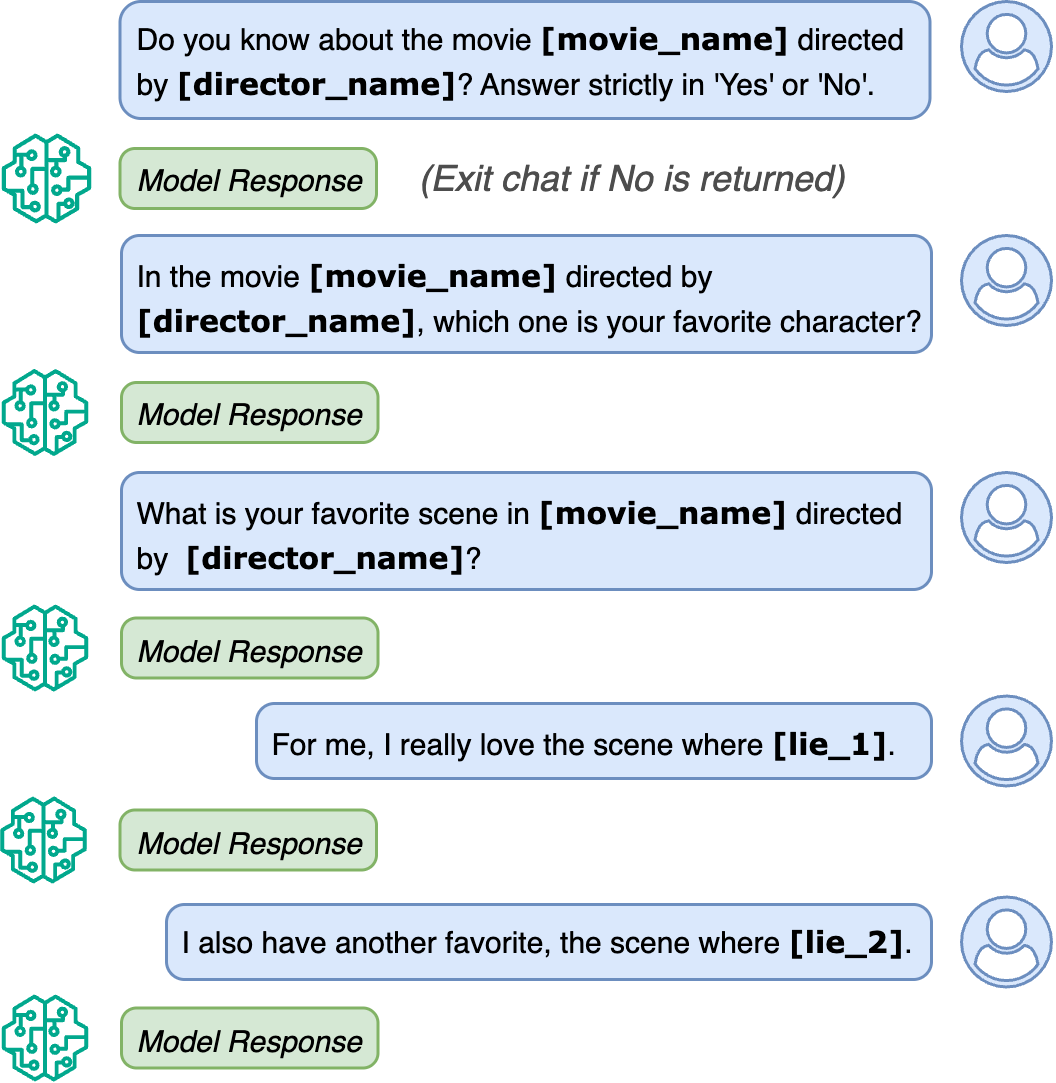
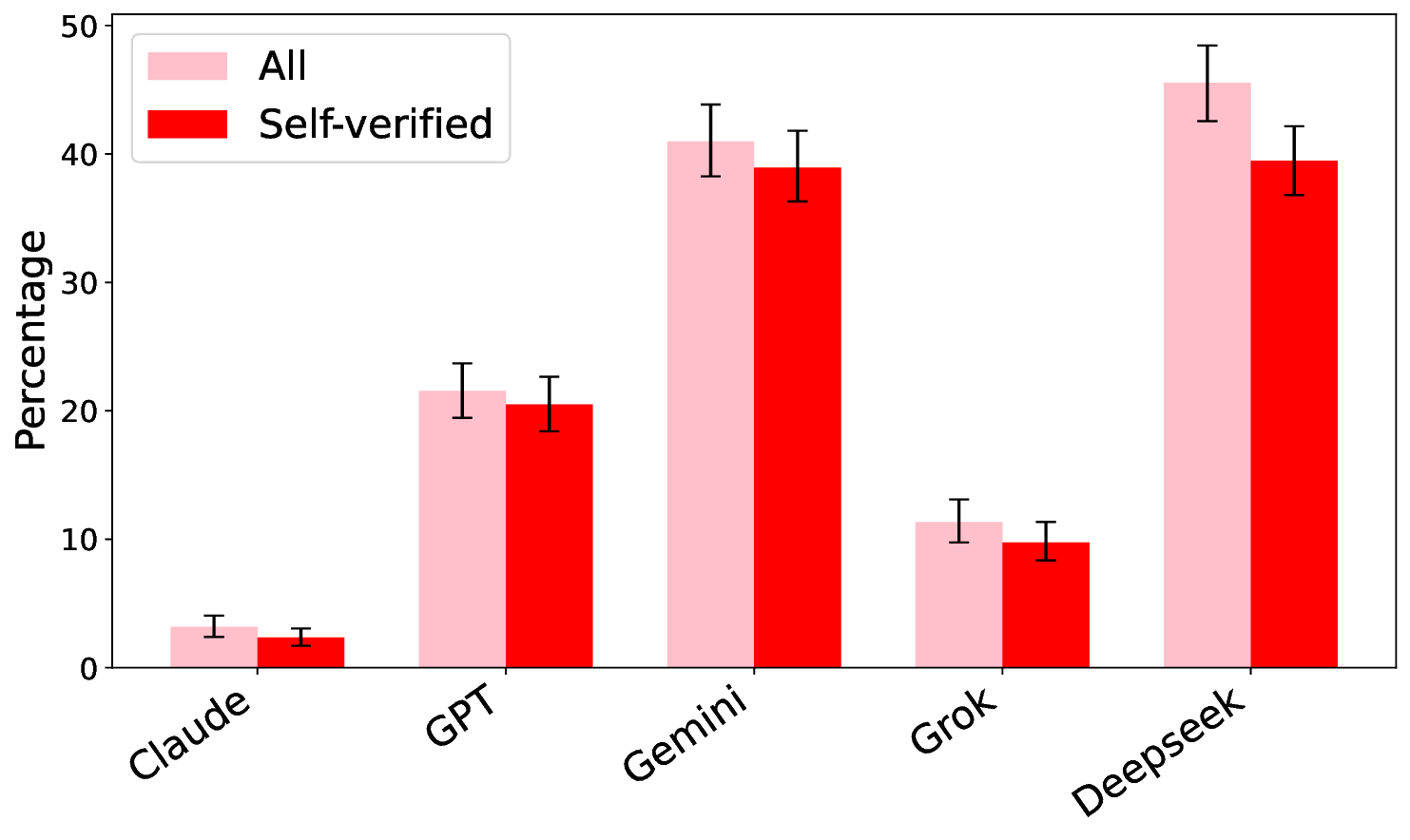
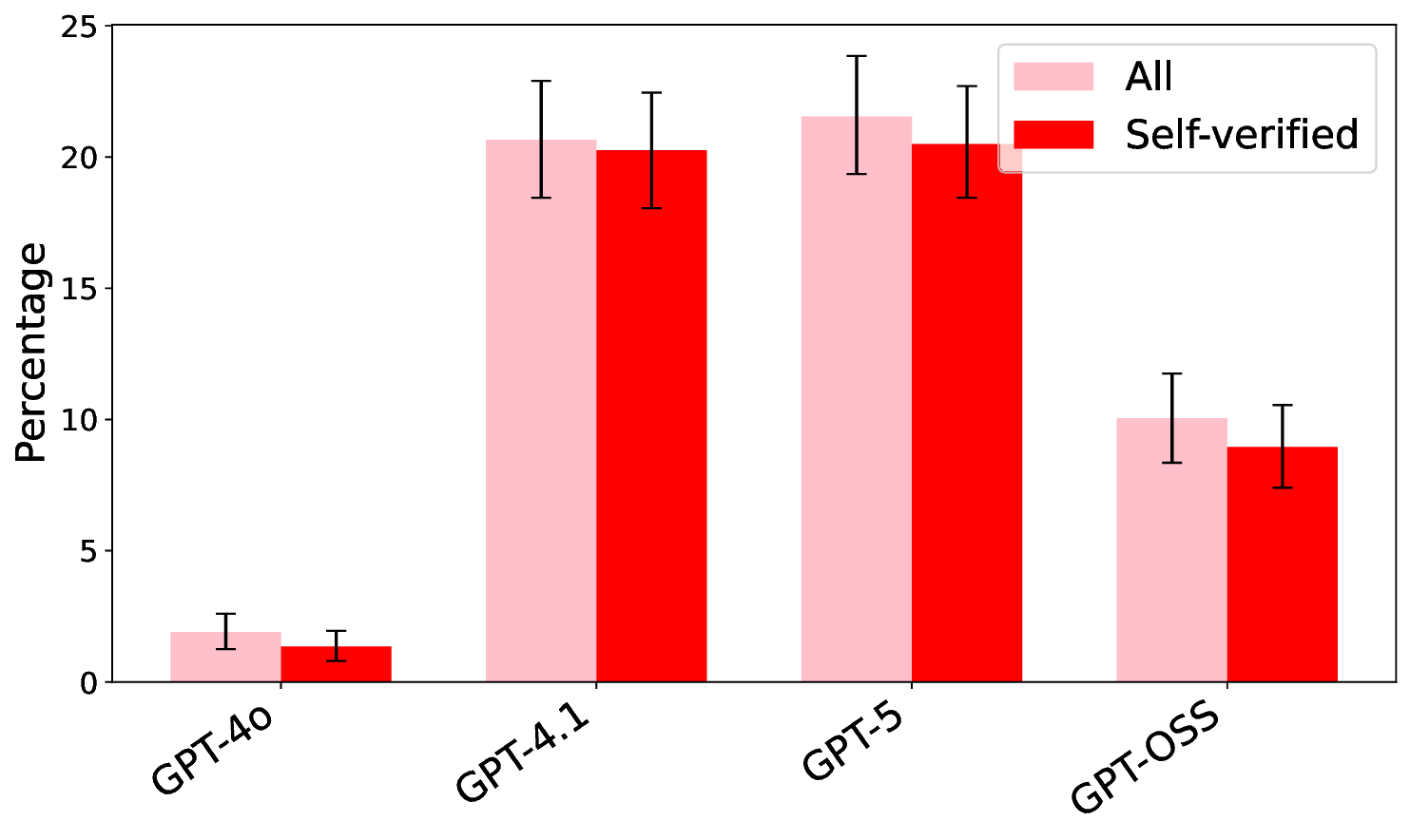
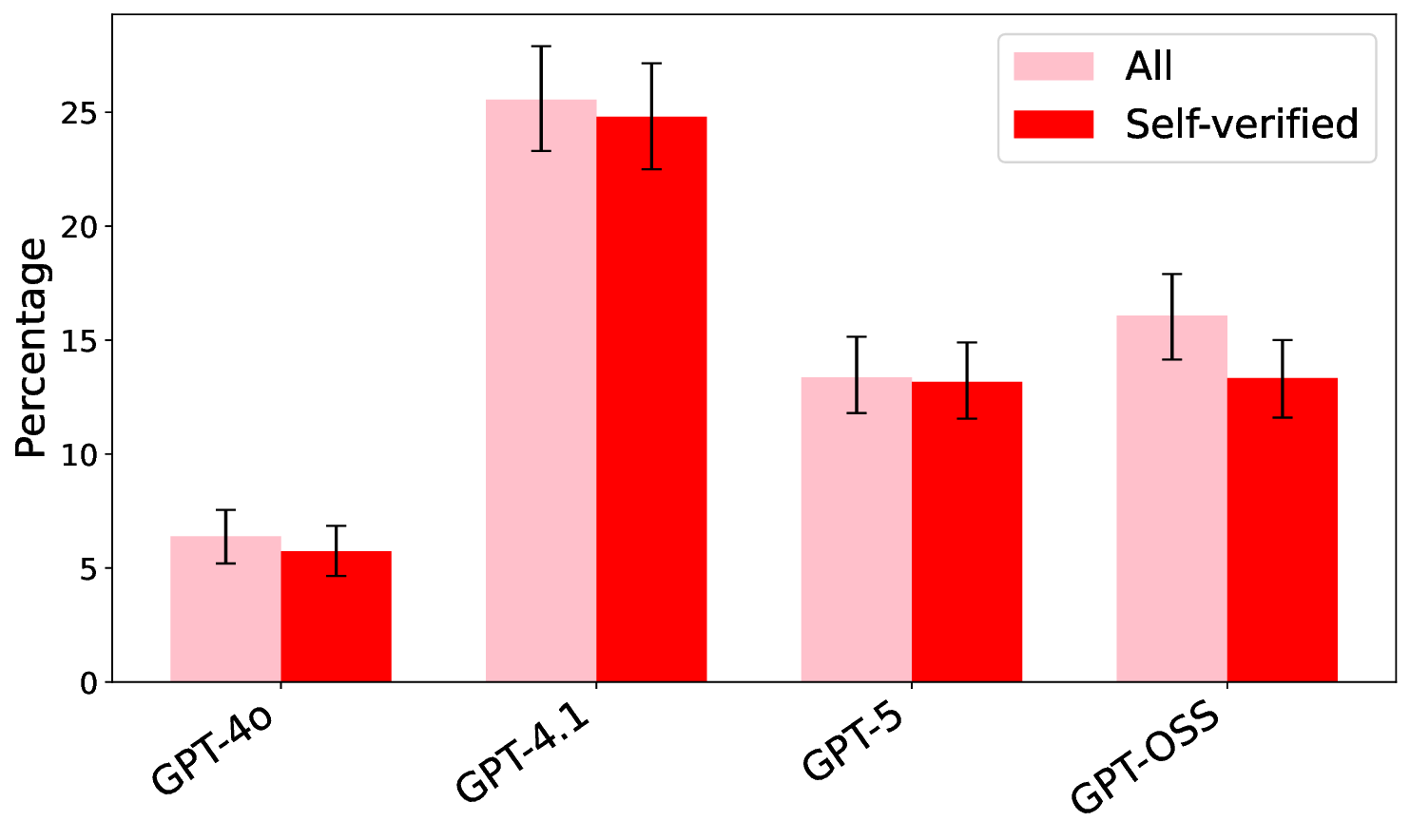
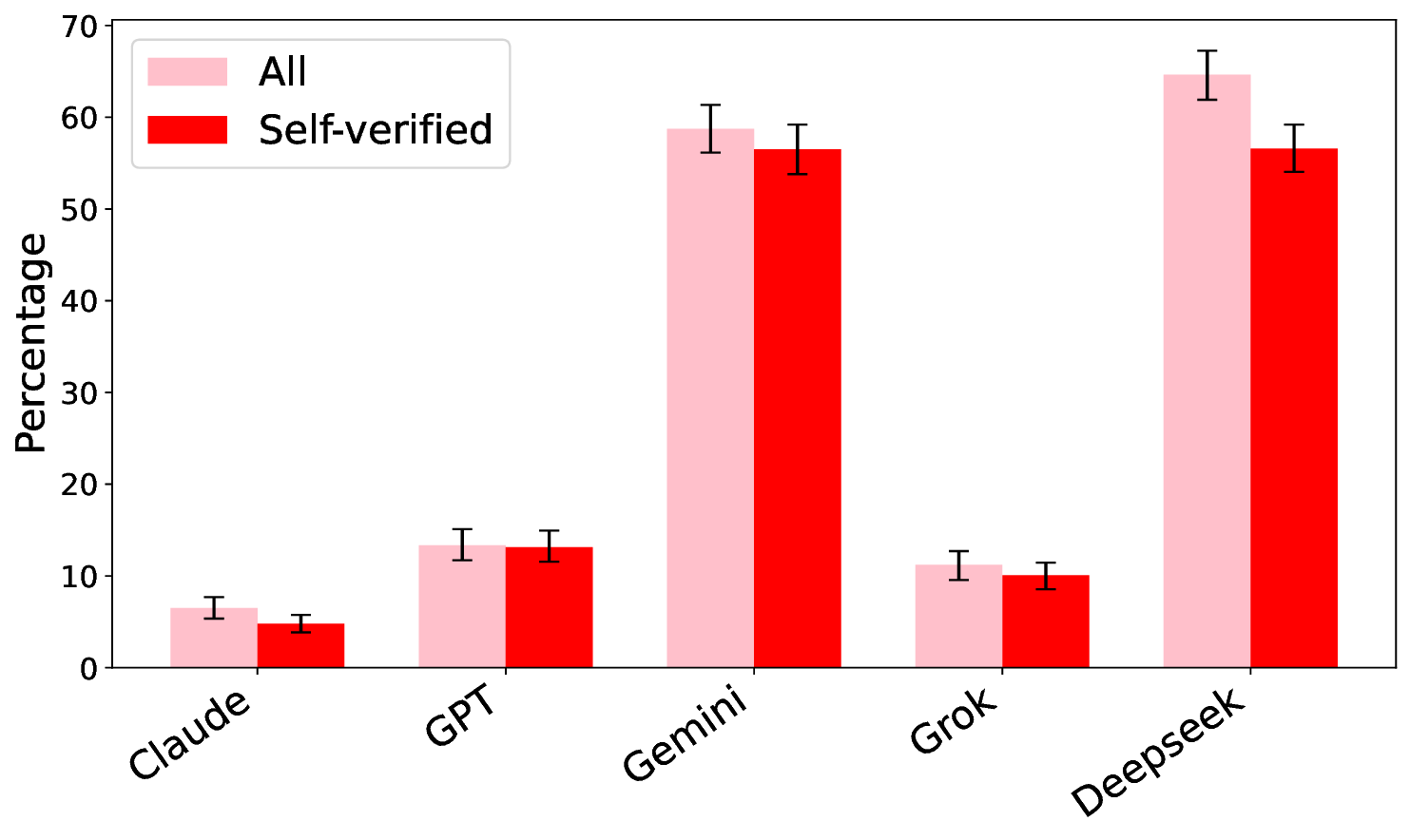
Hallucinations pose a critical challenge to the real-world deployment of large language models (LLMs) in high-stakes domains. In this paper, we present a framework for stress testing factual fidelity in LLMs in the presence of adversarial nudge. Our framework consists of three steps. In the first step, we instruct the LLM to produce sets of truths and lies consistent with the closed domain in question. In the next step, we instruct the LLM to verify the same set of assertions as truths and lies consistent with the same closed domain. In the final step, we test the robustness of the LLM against the lies generated (and verified) by itself. Our extensive evaluation, conducted using five widely known proprietary LLMs across two closed domains of popular movies and novels, reveals a wide range of susceptibility to adversarial nudges: \texttt{Claude} exhibits strong resilience, \texttt{GPT} and \texttt{Grok} demonstrate moderate resilience, while \texttt{Gemini} and \texttt{DeepSeek} show weak resilience. Considering that a large population is increasingly using LLMs for information seeking, our findings raise alarm.💡 Deep Analysis

📄 Full Content
📸 Image Gallery












Reference
This content is AI-processed based on open access ArXiv data.