HRM-Agent: Training a recurrent reasoning model in dynamic environments using reinforcement learning
📝 Original Info
- Title: HRM-Agent: Training a recurrent reasoning model in dynamic environments using reinforcement learning
- ArXiv ID: 2510.22832
- Date: 2025-10-26
- Authors: ** 정보 없음 (논문에 명시된 저자 정보가 제공되지 않았습니다) **
📝 Abstract
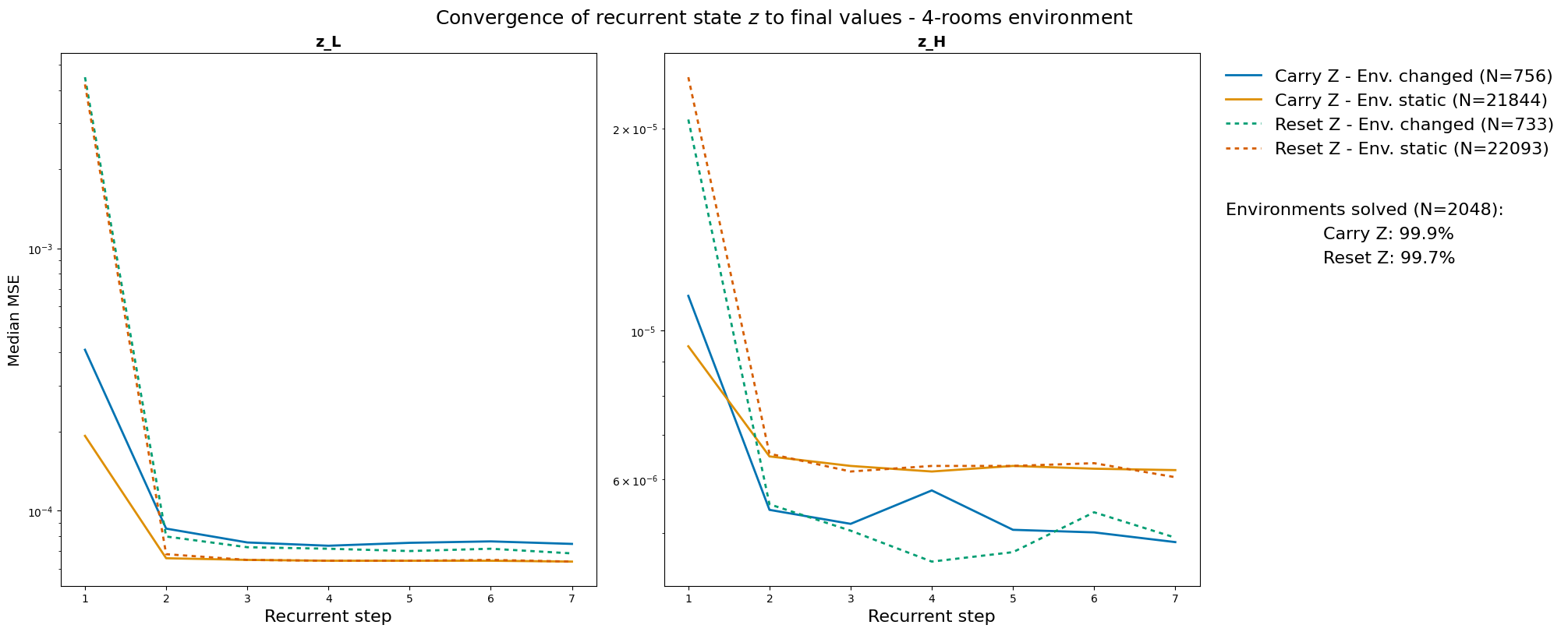
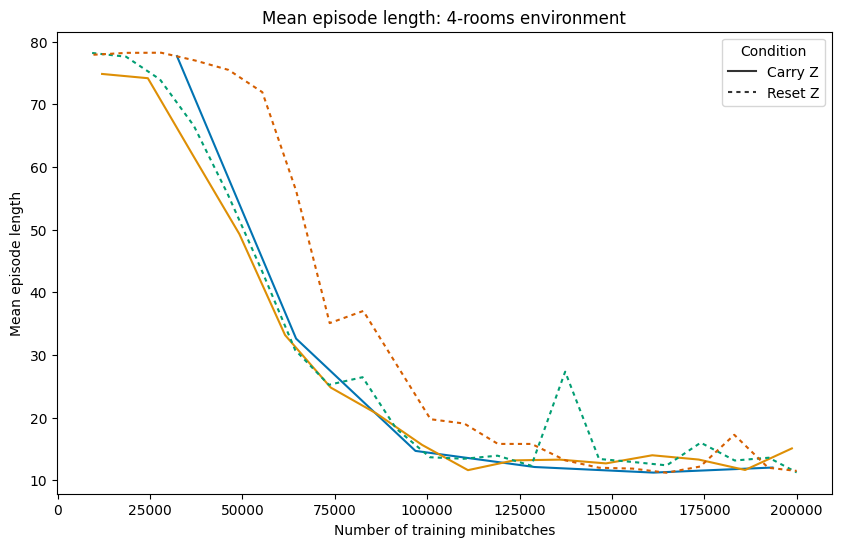
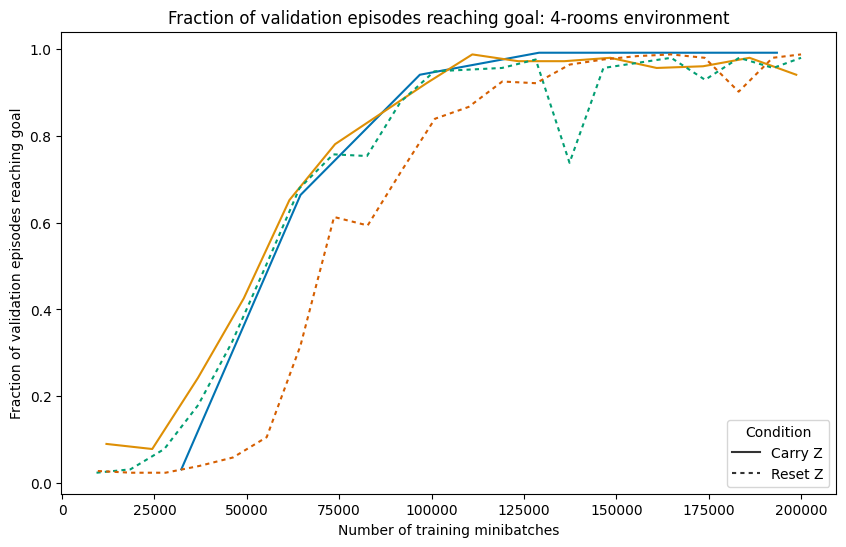
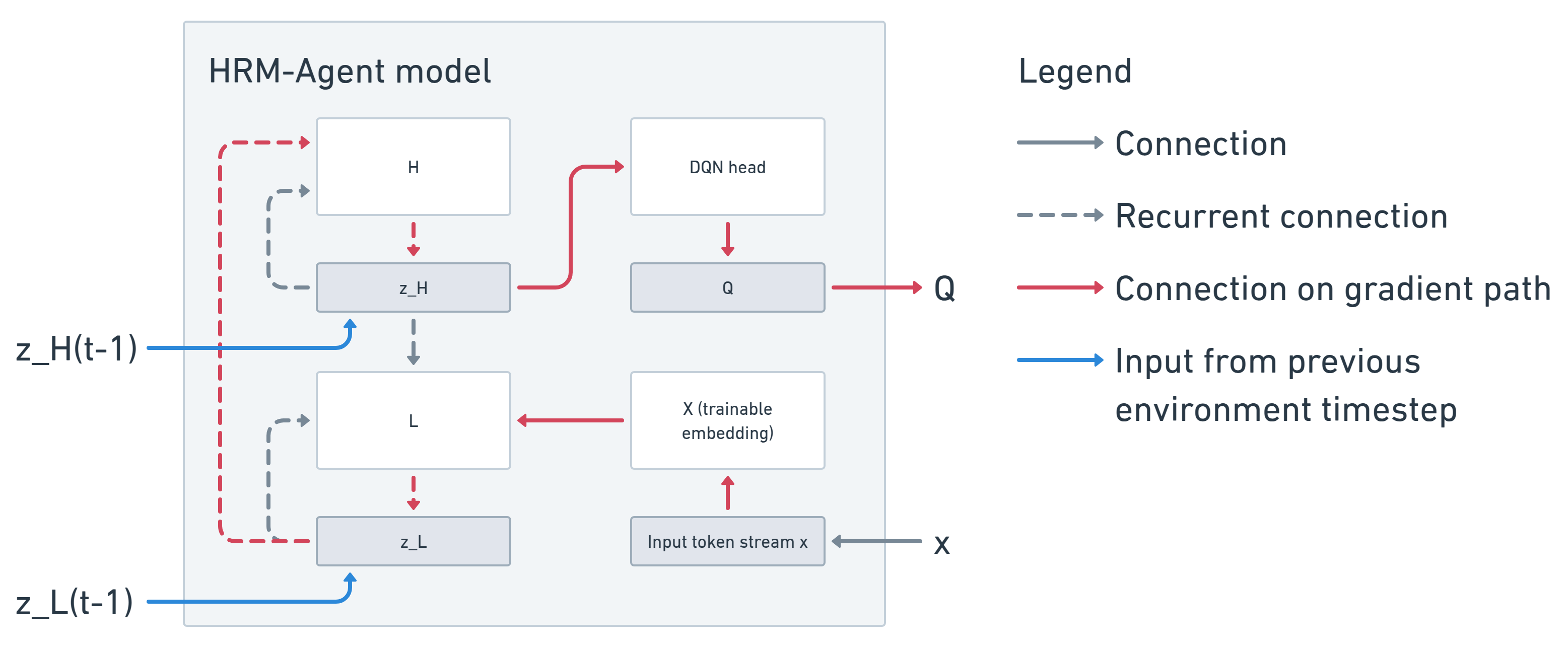
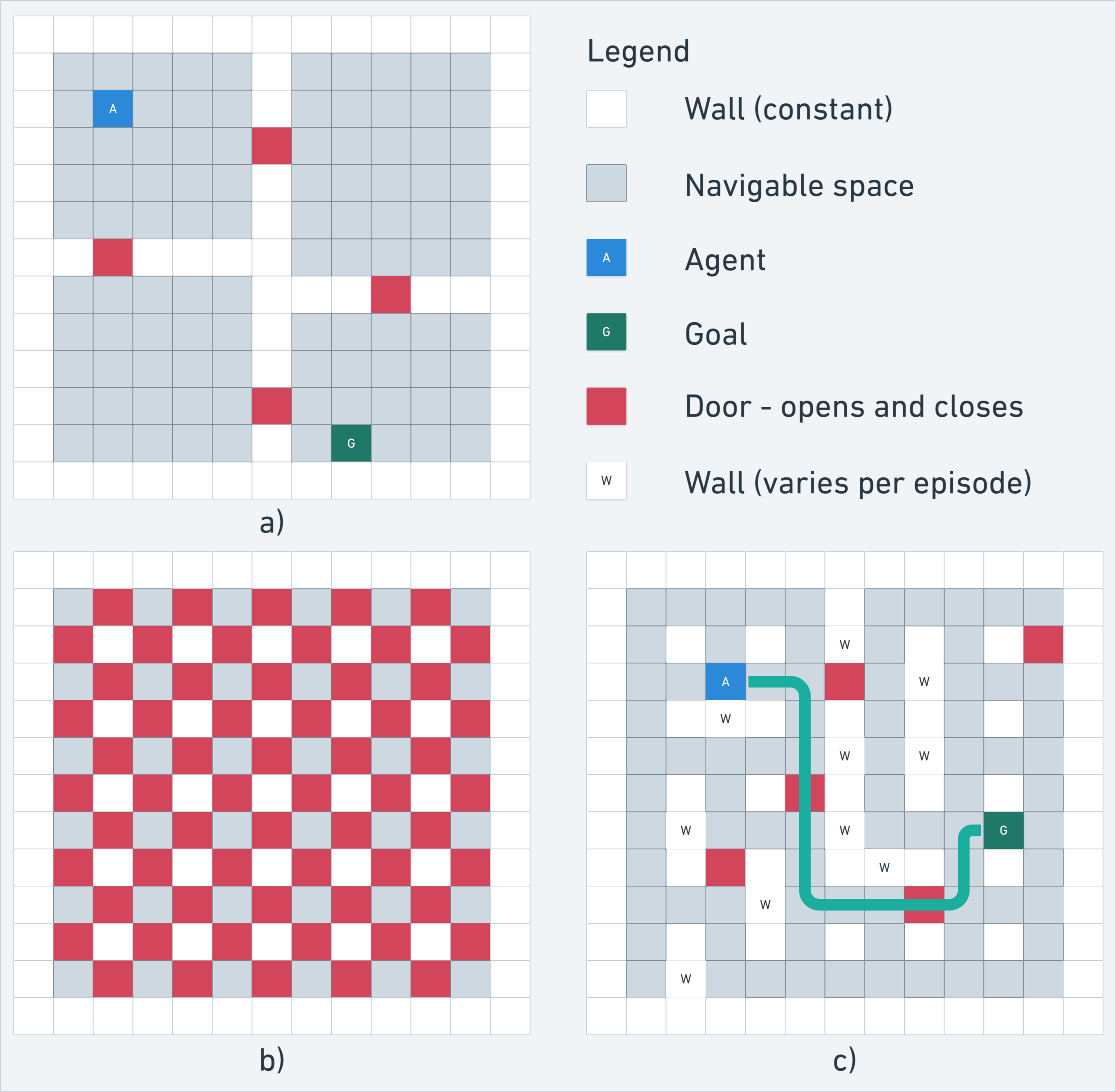
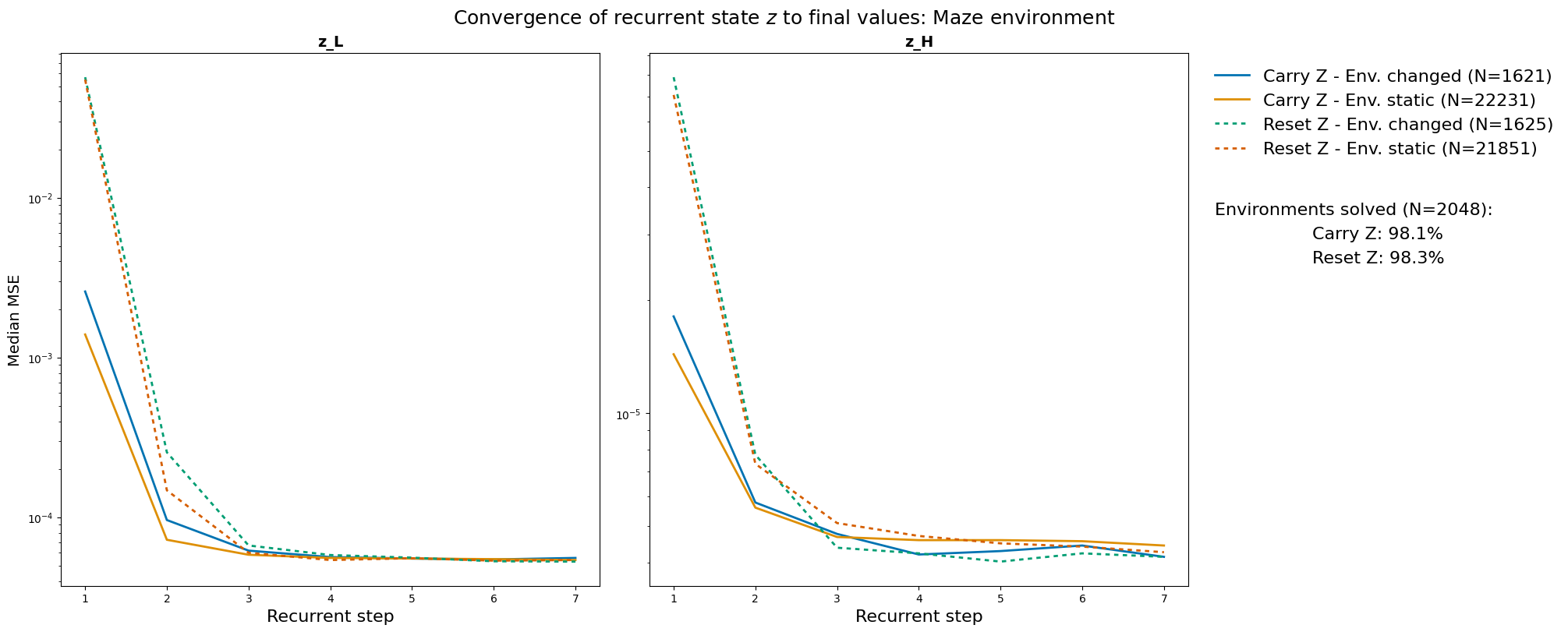
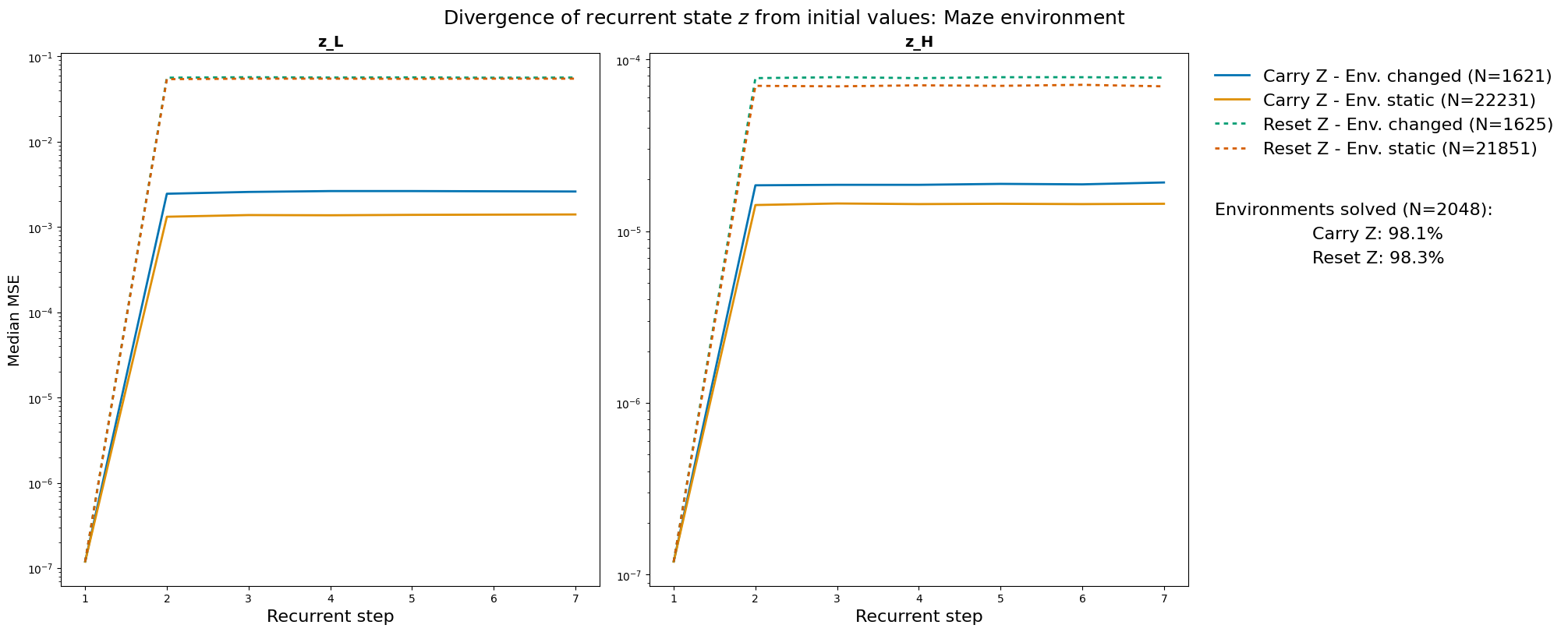
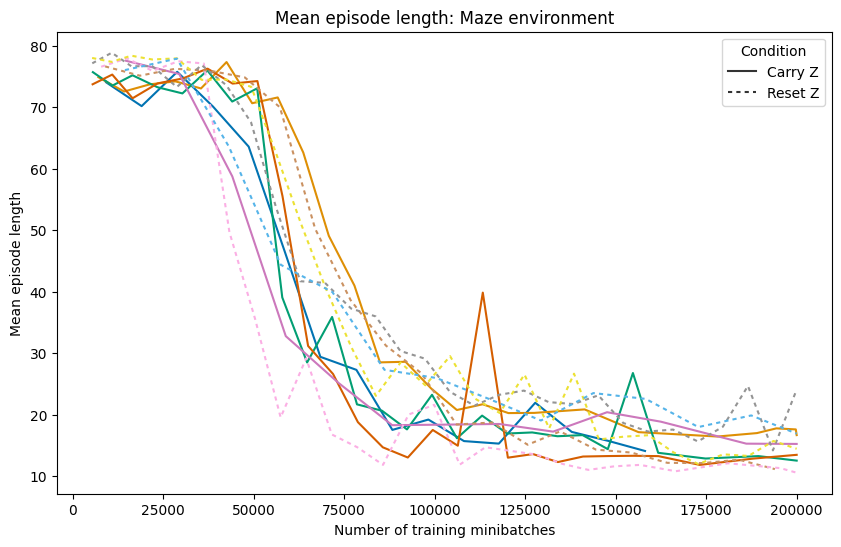
The Hierarchical Reasoning Model (HRM) has impressive reasoning abilities given its small size, but has only been applied to supervised, static, fully-observable problems. One of HRM's strengths is its ability to adapt its computational effort to the difficulty of the problem. However, in its current form it cannot integrate and reuse computation from previous time-steps if the problem is dynamic, uncertain or partially observable, or be applied where the correct action is undefined, characteristics of many real-world problems. This paper presents HRM-Agent, a variant of HRM trained using only reinforcement learning. We show that HRM can learn to navigate to goals in dynamic and uncertain maze environments. Recent work suggests that HRM's reasoning abilities stem from its recurrent inference process. We explore the dynamics of the recurrent inference process and find evidence that it is successfully reusing computation from earlier environment time-steps.💡 Deep Analysis
📄 Full Content
📸 Image Gallery
Reference
This content is AI-processed based on open access ArXiv data.