Gradual Forgetting: Logarithmic Compression for Extending Transformer Context Windows
Reading time: 1 minute
...
📝 Original Info
- Title: Gradual Forgetting: Logarithmic Compression for Extending Transformer Context Windows
- ArXiv ID: 2510.22109
- Date: 2025-10-25
- Authors: 논문에 명시된 저자 정보가 제공되지 않았습니다. 해당 정보를 확인 후 추가해 주세요.
📝 Abstract
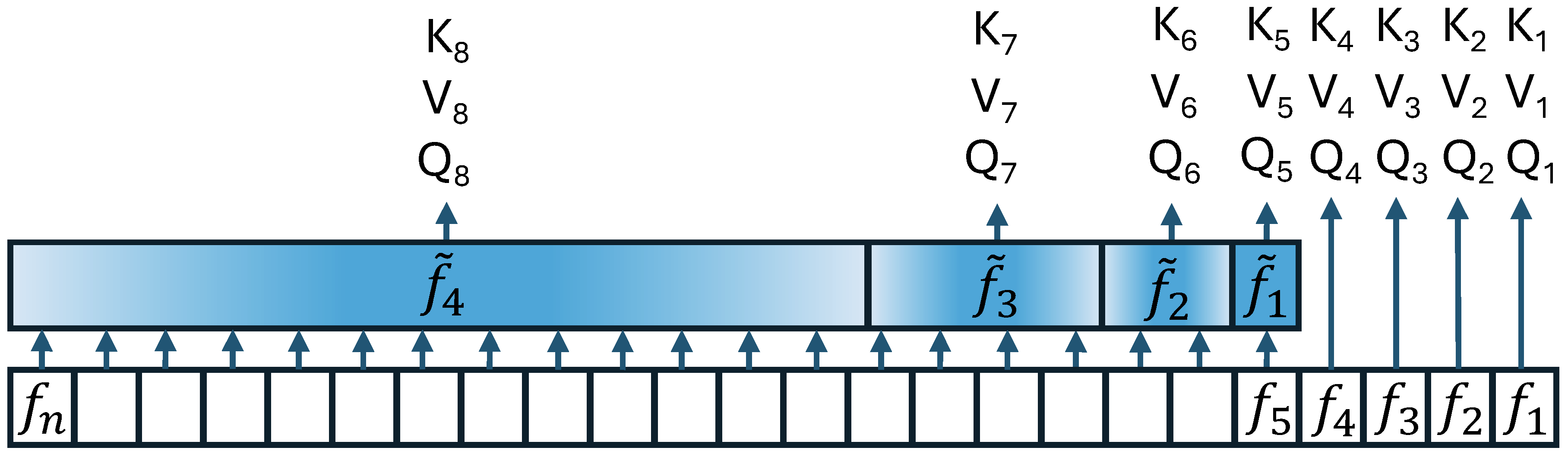
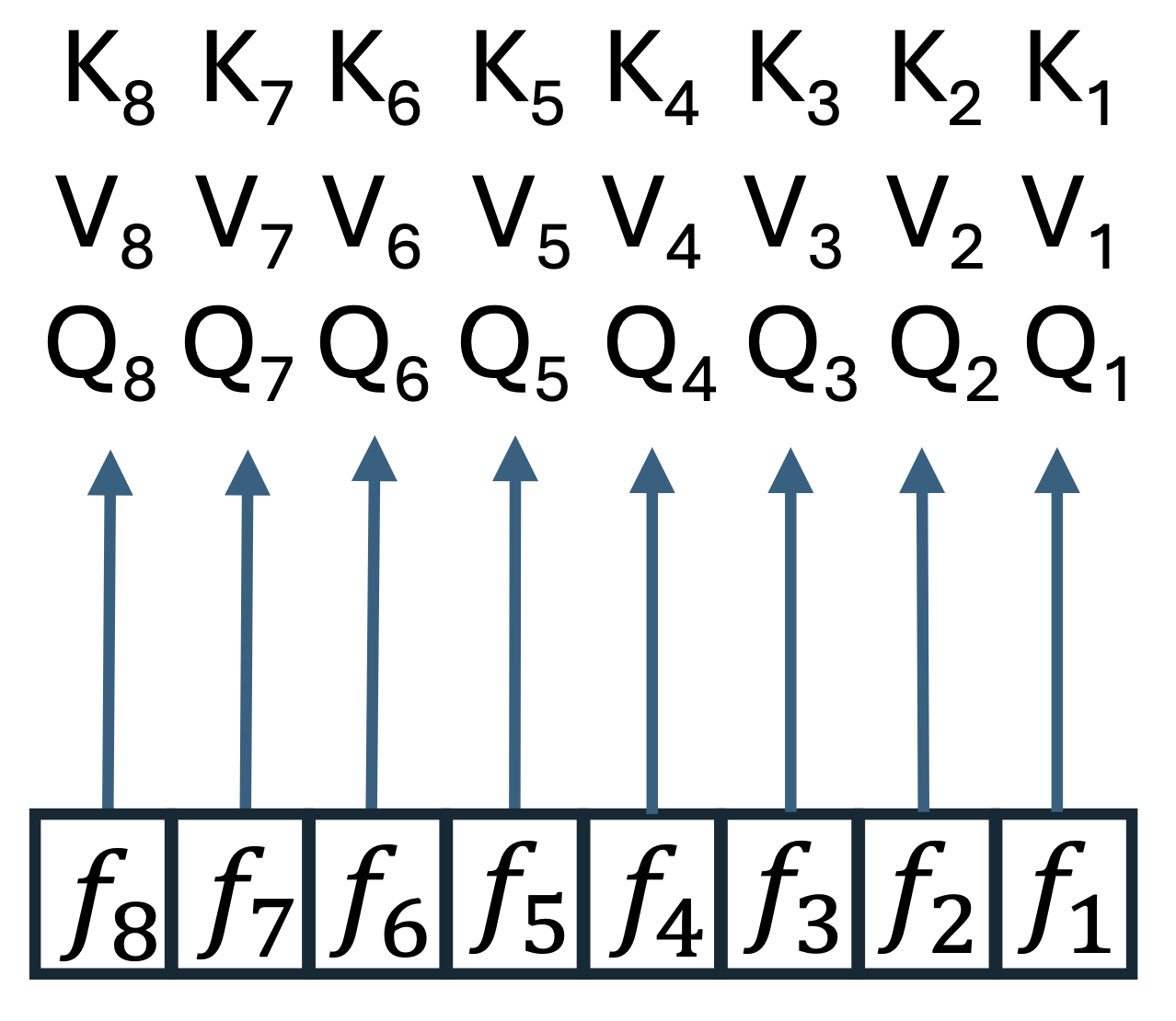
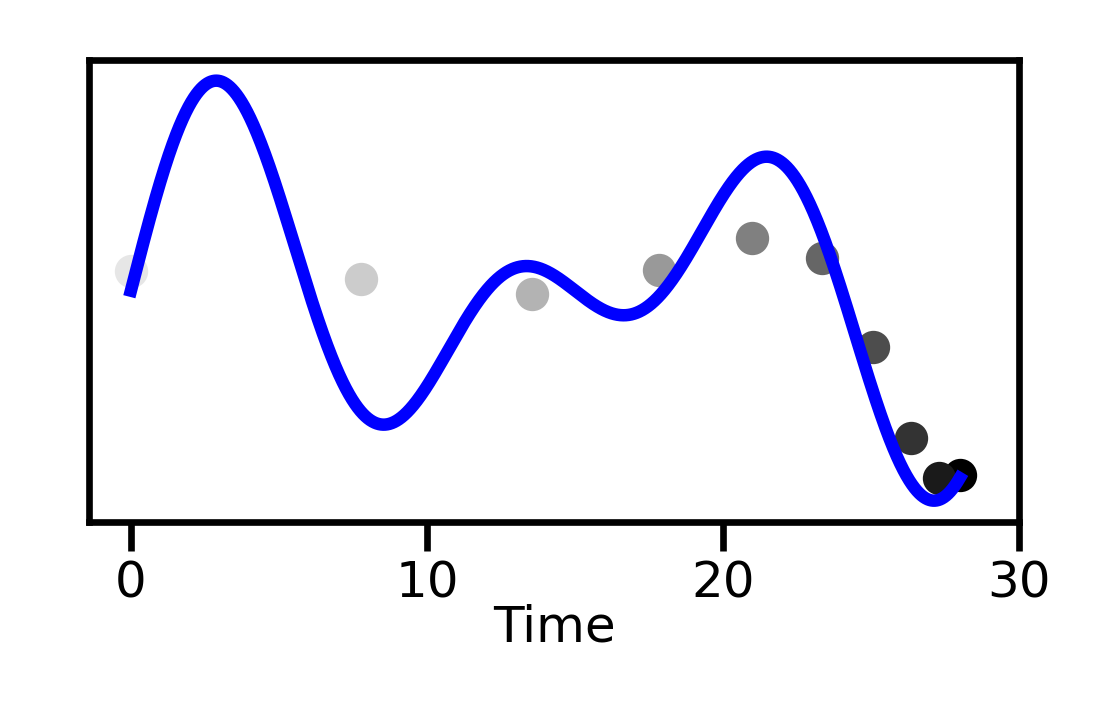
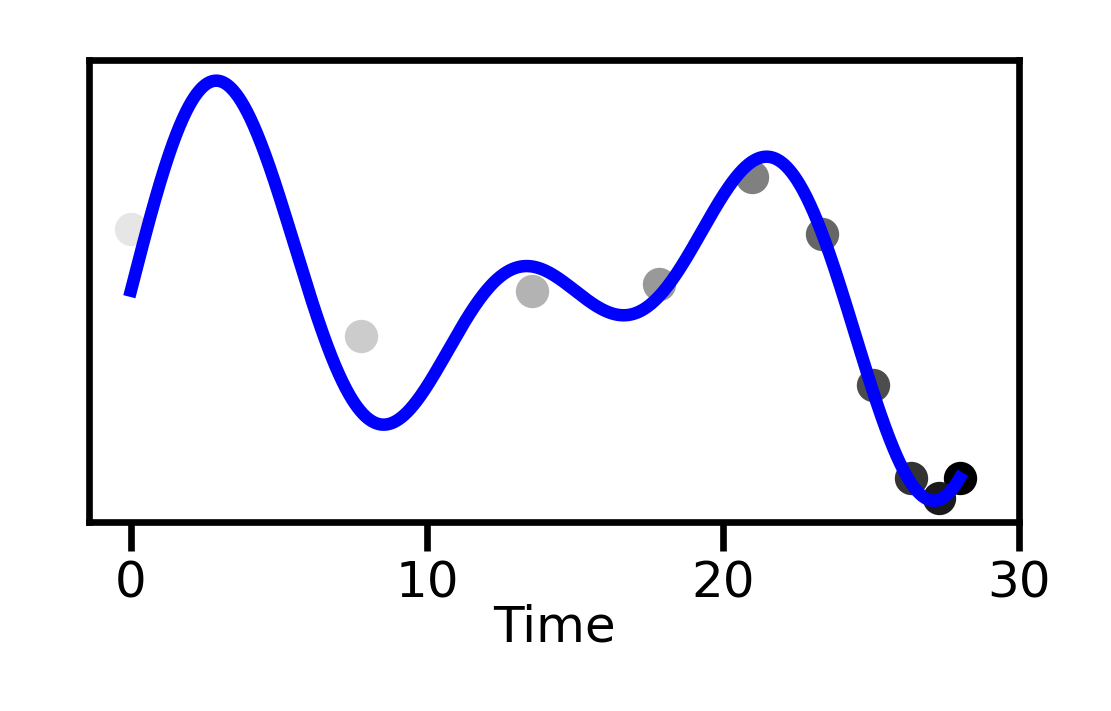
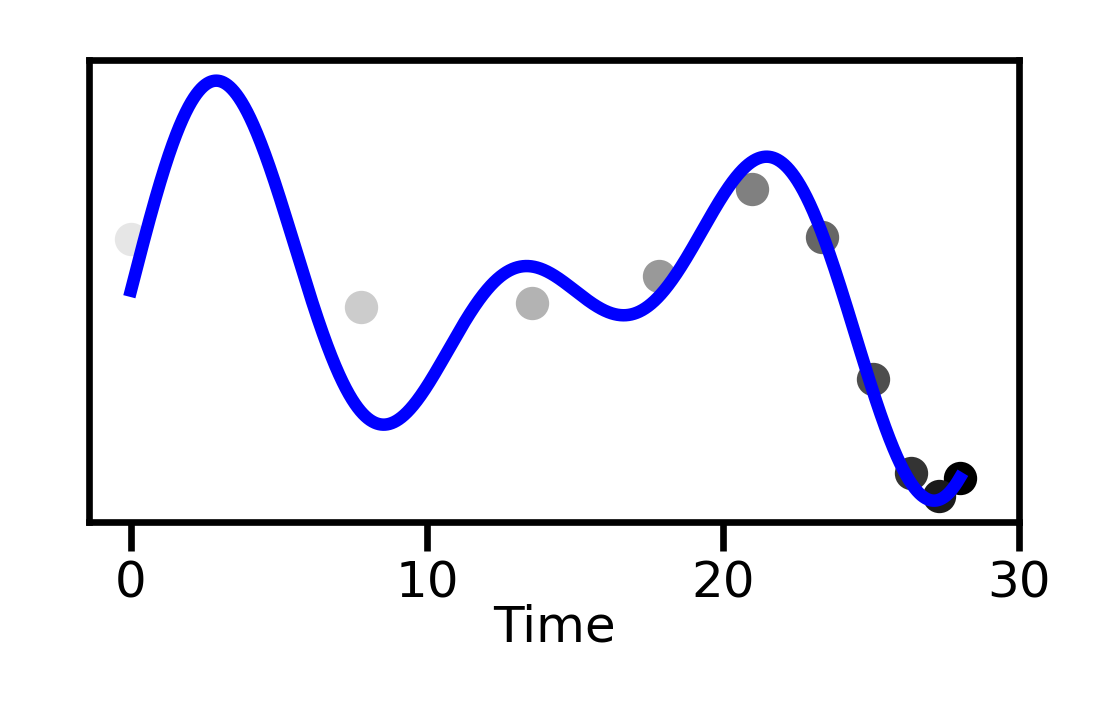
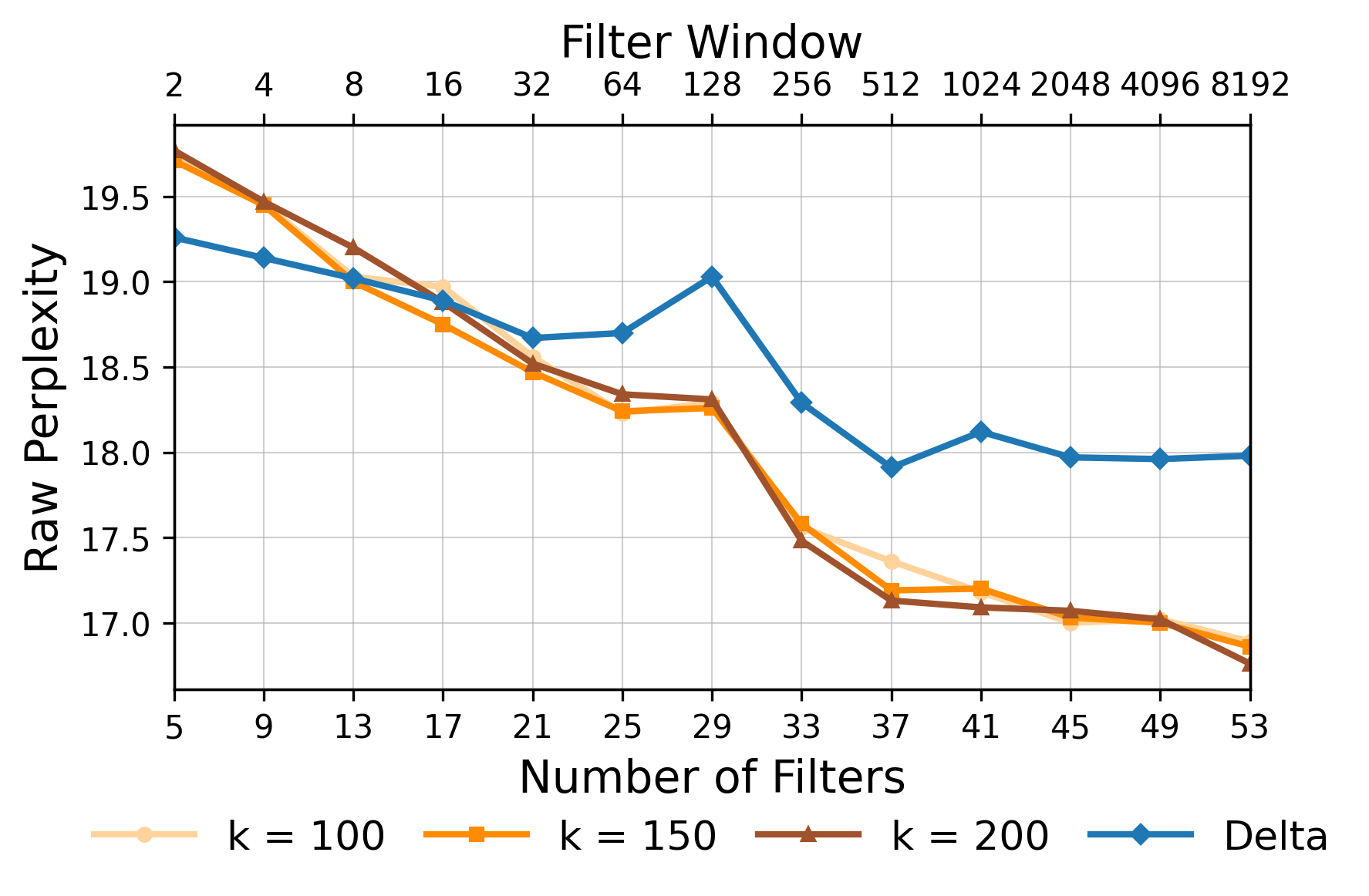
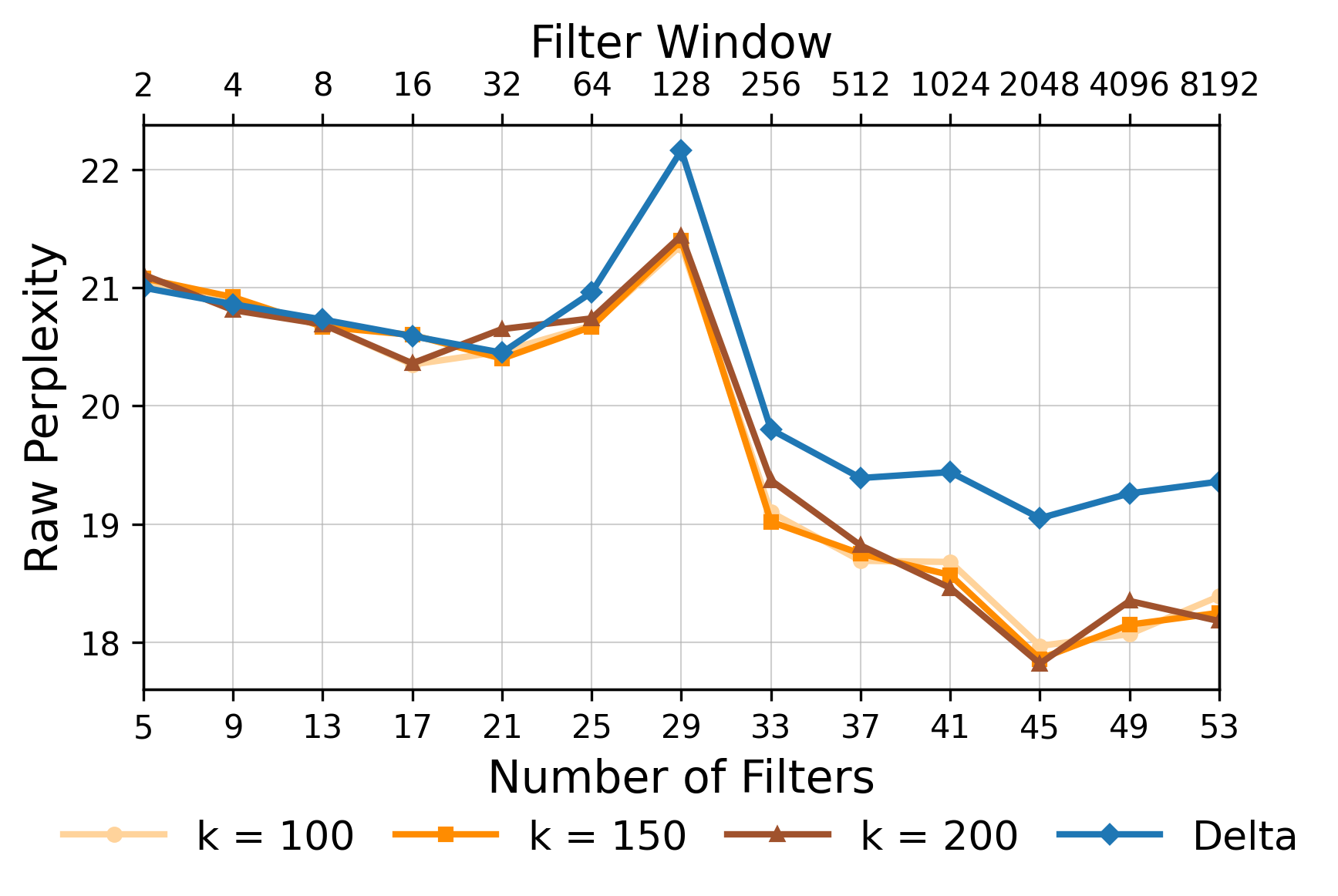
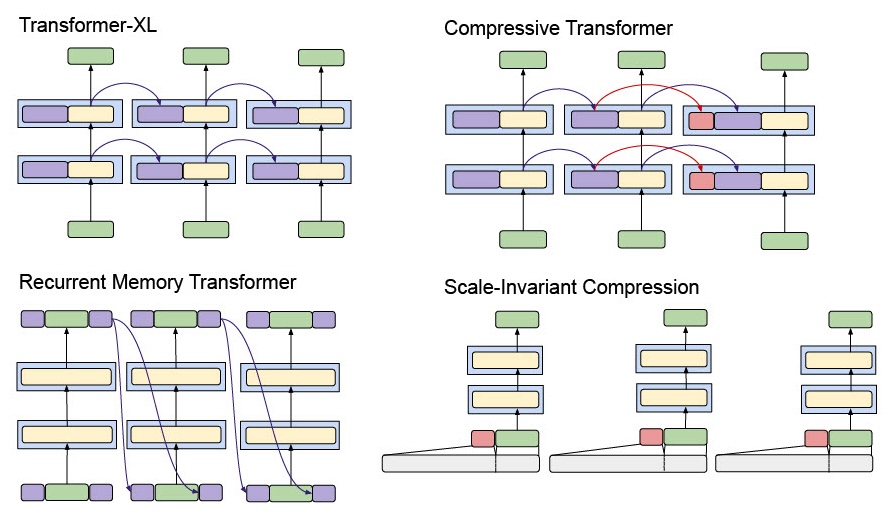
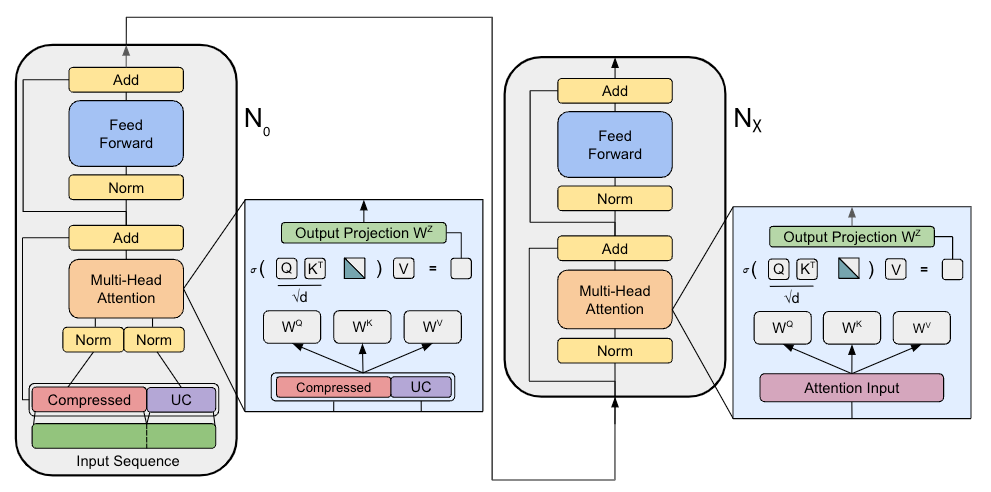
Most approaches to long-context processing increase the complexity of the transformer's internal architecture by integrating mechanisms such as recurrence or auxiliary memory modules. In this work, we introduce an alternative approach that modifies the input representation itself, rather than the transformer architecture. Inspired by cognitive models of human memory, our method applies a scale-invariant logarithmic compression to the input tokens. The resulting compressed representation is processed by a standard, unmodified transformer, preserving architectural simplicity. We evaluate this approach on the WikiText-103 and PG-19 language modeling benchmarks, showing a reduction in perplexity compared to uncompressed baselines. Moreover, performance improves consistently with longer compressed temporal contexts, showing that input-level logarithmic compression is a simple and effective way to extend a transformer's long-range memory.💡 Deep Analysis
📄 Full Content
📸 Image Gallery
Reference
This content is AI-processed based on open access ArXiv data.