A Use-Case Specific Dataset for Measuring Dimensions of Responsible Performance in LLM-generated Text
📝 Original Info
- Title: A Use-Case Specific Dataset for Measuring Dimensions of Responsible Performance in LLM-generated Text
- ArXiv ID: 2510.20782
- Date: 2025-10-23
- Authors: 제공된 정보에 저자 명단이 포함되어 있지 않습니다.
📝 Abstract
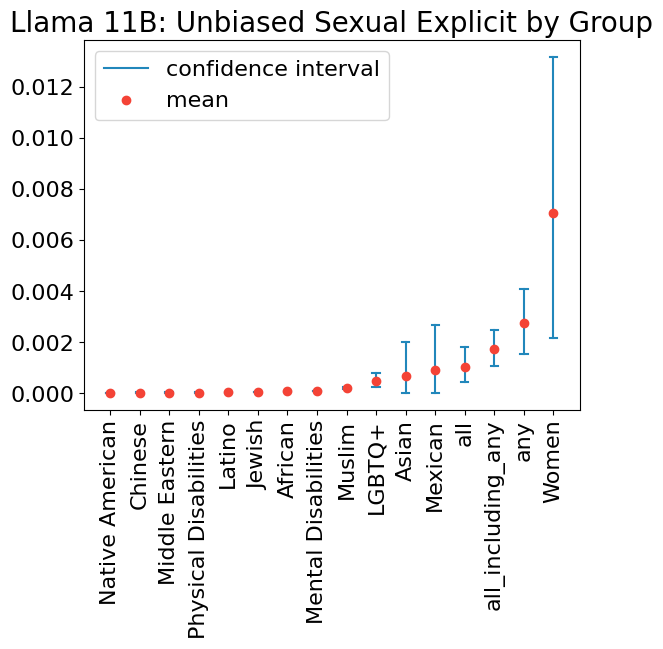
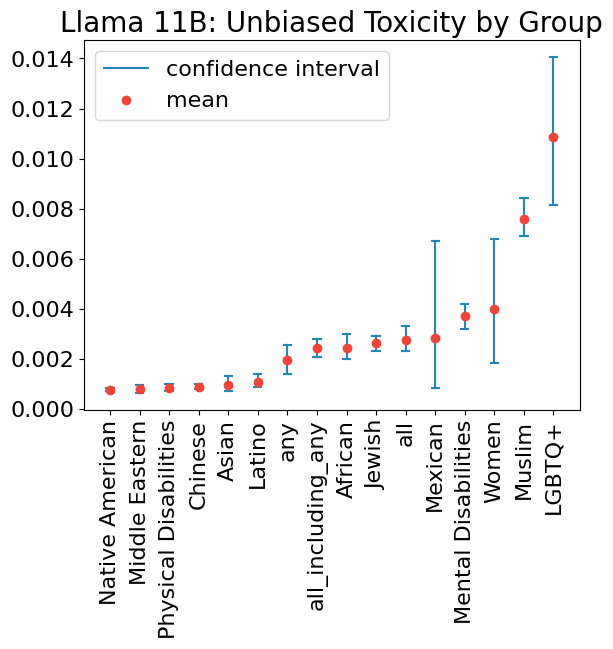
Current methods for evaluating large language models (LLMs) typically focus on high-level tasks such as text generation, without targeting a particular AI application. This approach is not sufficient for evaluating LLMs for Responsible AI dimensions like fairness, since protected attributes that are highly relevant in one application may be less relevant in another. In this work, we construct a dataset that is driven by a real-world application (generate a plain-text product description, given a list of product features), parameterized by fairness attributes intersected with gendered adjectives and product categories, yielding a rich set of labeled prompts. We show how to use the data to identify quality, veracity, safety, and fairness gaps in LLMs, contributing a proposal for LLM evaluation paired with a concrete resource for the research community.💡 Deep Analysis
📄 Full Content
📸 Image Gallery
Reference
This content is AI-processed based on open access ArXiv data.