Evaluating Prompting Strategies and Large Language Models in Systematic Literature Review Screening: Relevance and Task-Stage Classification
📝 Original Info
- Title: Evaluating Prompting Strategies and Large Language Models in Systematic Literature Review Screening: Relevance and Task-Stage Classification
- ArXiv ID: 2510.16091
- Date: 2025-10-17
- Authors: ** 정보 없음 (원문에 저자 정보가 제공되지 않음) **
📝 Abstract
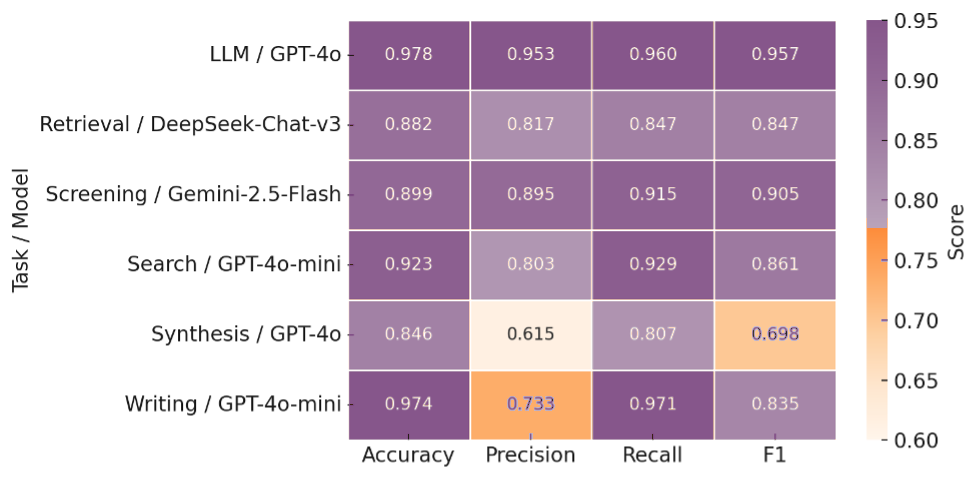
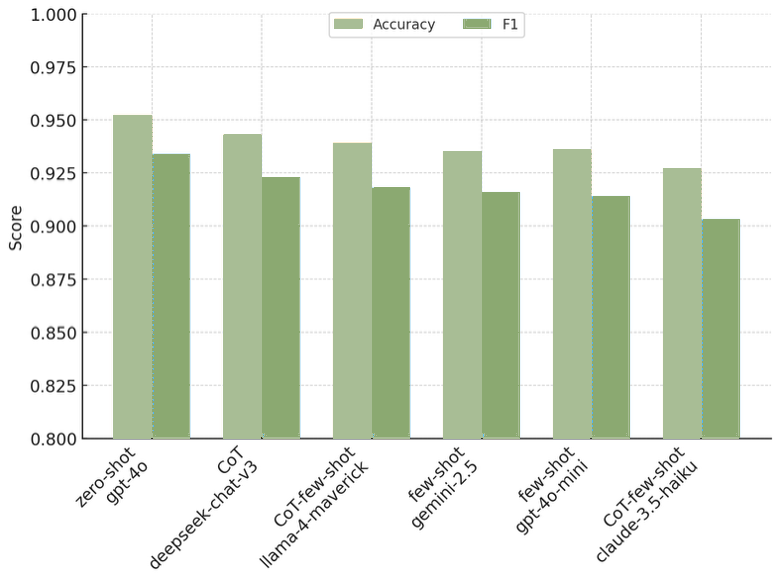
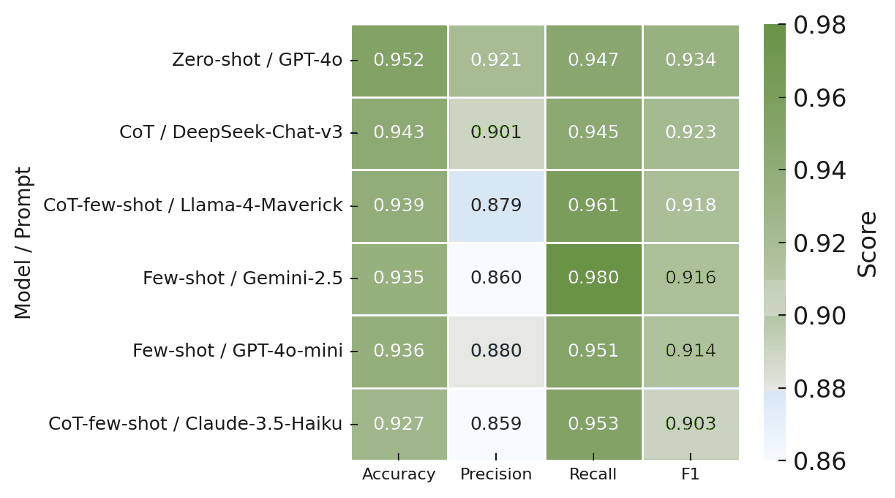
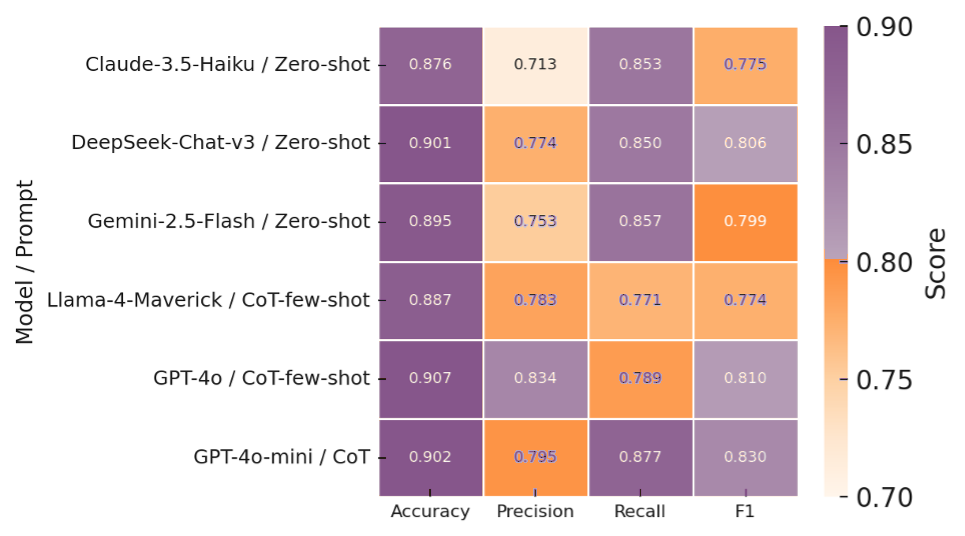
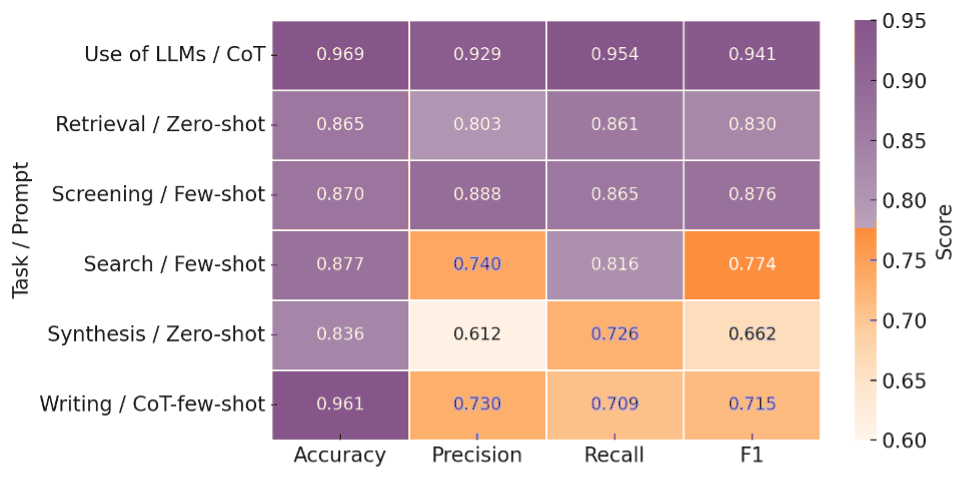
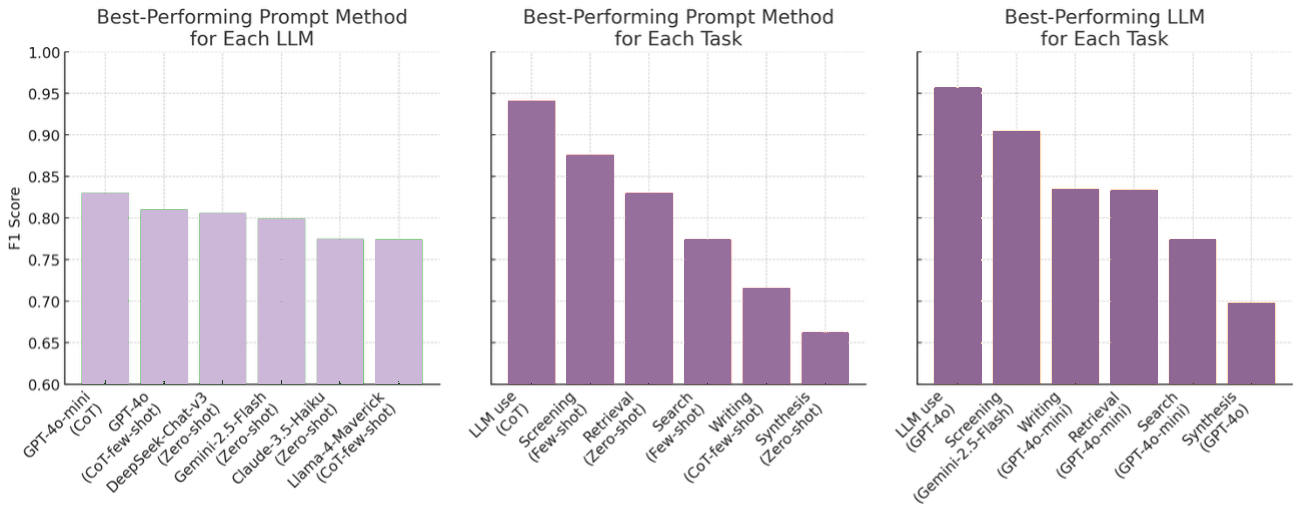
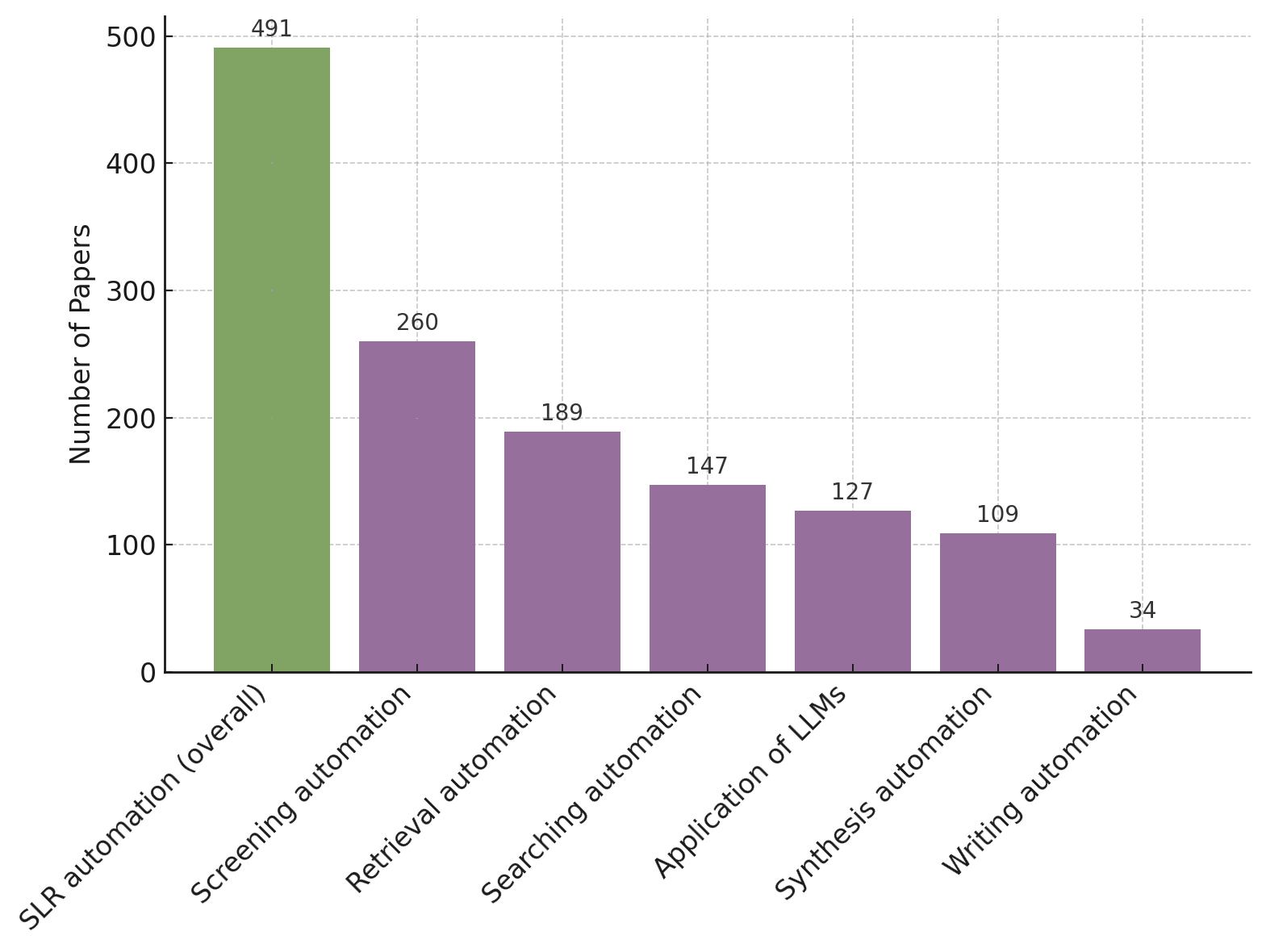
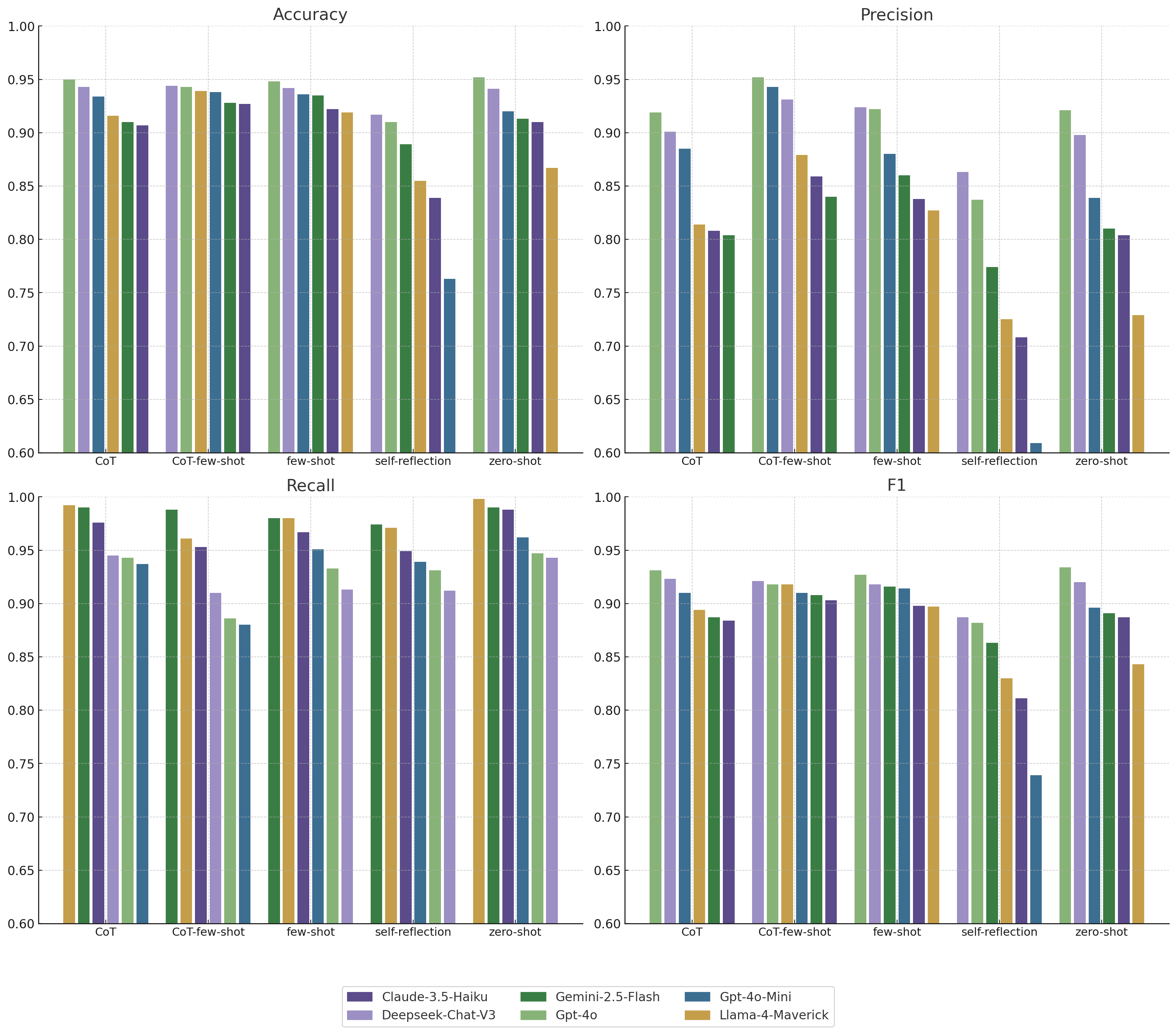
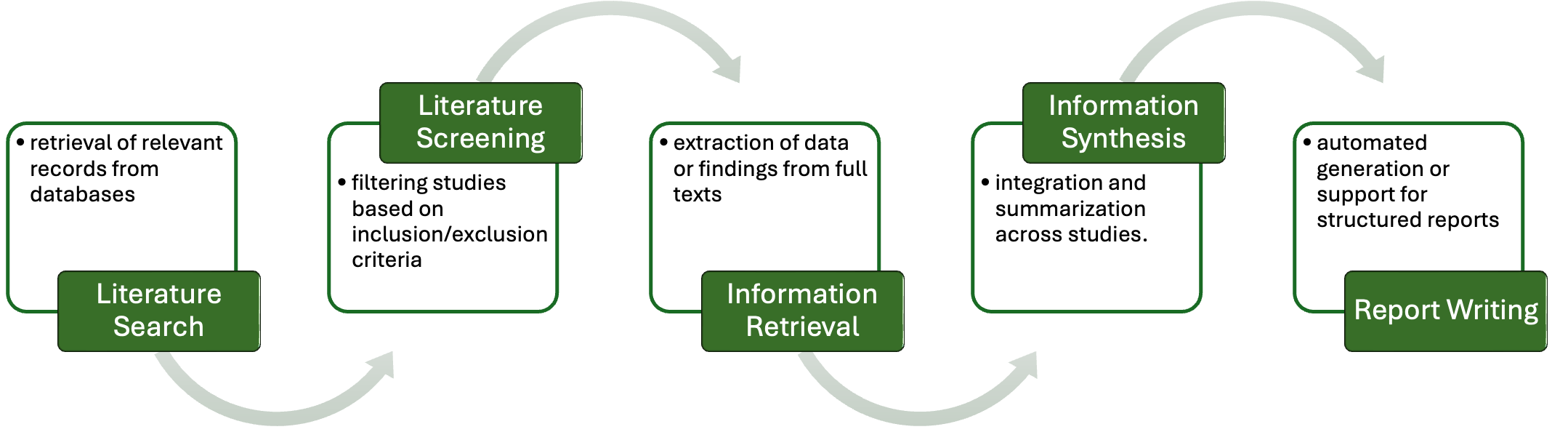
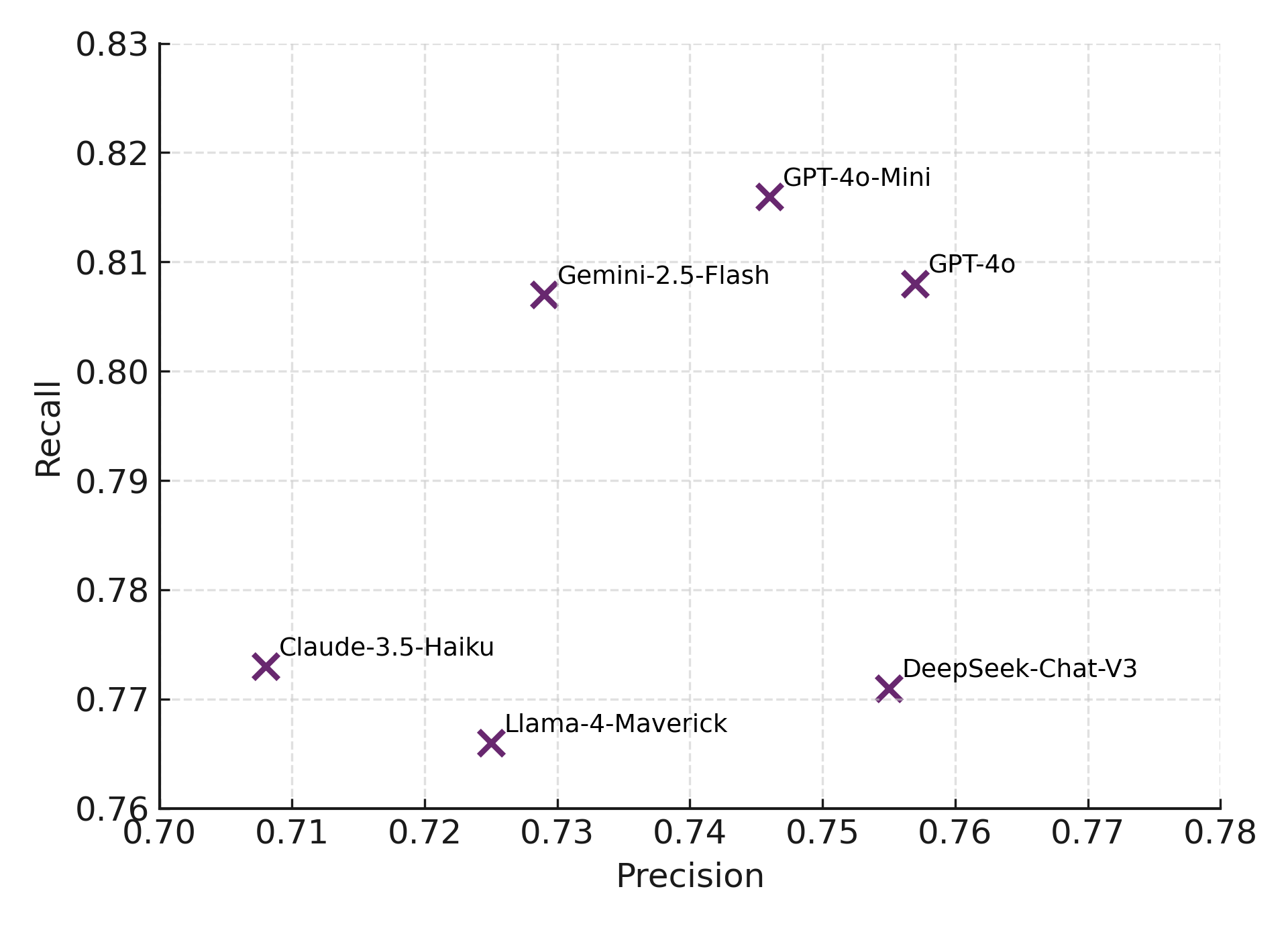
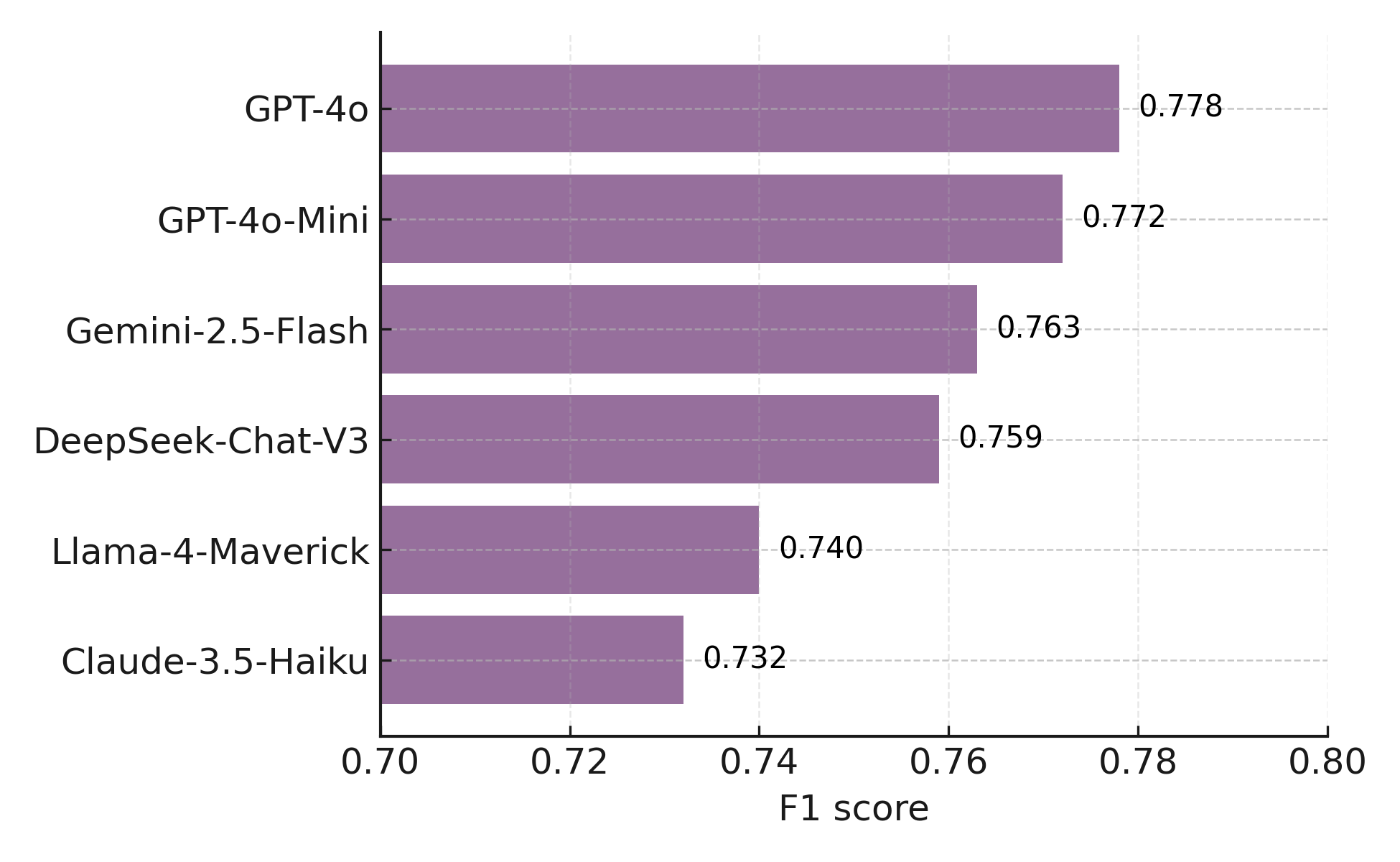
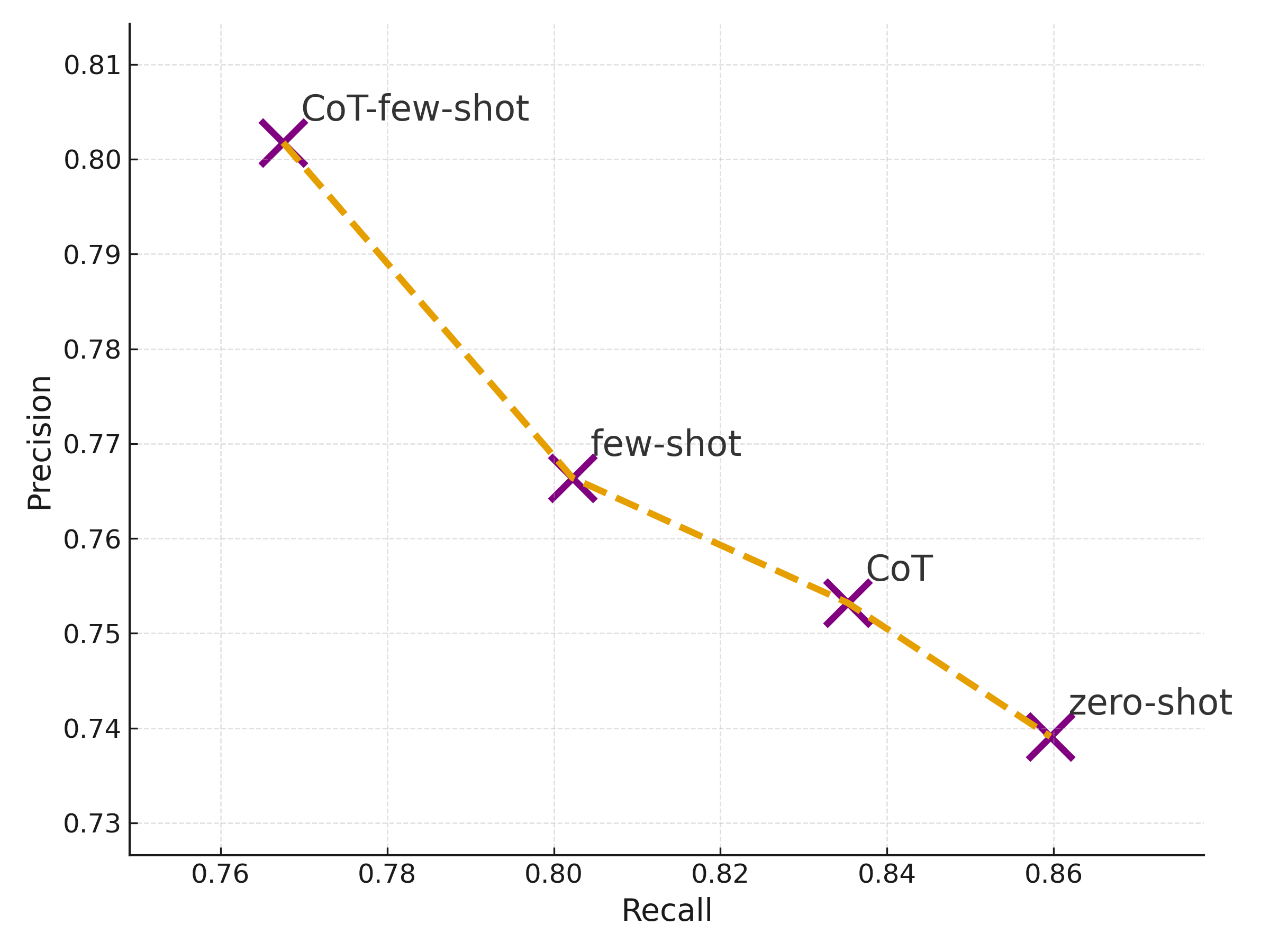
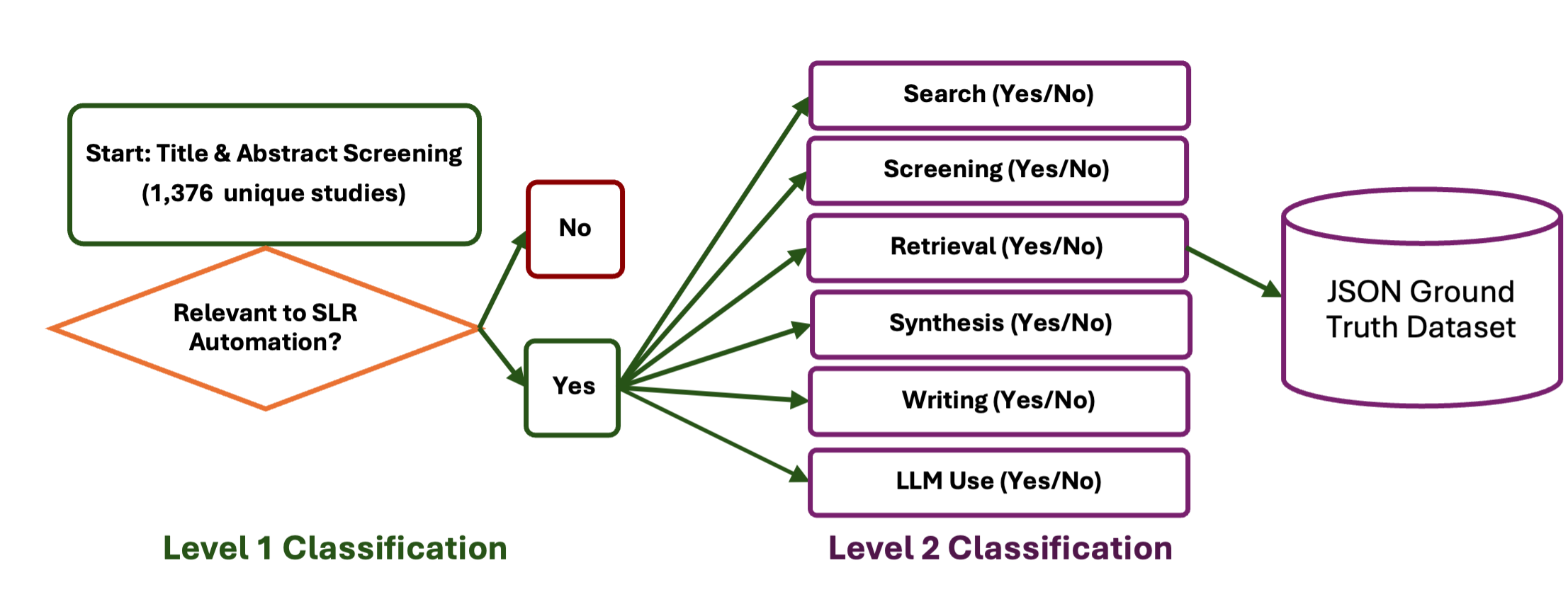
This study quantifies how prompting strategies interact with large language models (LLMs) to automate the screening stage of systematic literature reviews (SLRs). We evaluate six LLMs (GPT-4o, GPT-4o-mini, DeepSeek-Chat-V3, Gemini-2.5-Flash, Claude-3.5-Haiku, Llama-4-Maverick) under five prompt types (zero-shot, few-shot, chain-of-thought (CoT), CoT-few-shot, self-reflection) across relevance classification and six Level-2 tasks, using accuracy, precision, recall, and F1. Results show pronounced model-prompt interaction effects: CoT-few-shot yields the most reliable precision-recall balance; zero-shot maximizes recall for high-sensitivity passes; and self-reflection underperforms due to over-inclusivity and instability across models. GPT-4o and DeepSeek provide robust overall performance, while GPT-4o-mini performs competitively at a substantially lower dollar cost. A cost-performance analysis for relevance classification (per 1,000 abstracts) reveals large absolute differences among model-prompt pairings; GPT-4o-mini remains low-cost across prompts, and structured prompts (CoT/CoT-few-shot) on GPT-4o-mini offer attractive F1 at a small incremental cost. We recommend a staged workflow that (1) deploys low-cost models with structured prompts for first-pass screening and (2) escalates only borderline cases to higher-capacity models. These findings highlight LLMs' uneven but promising potential to automate literature screening. By systematically analyzing prompt-model interactions, we provide a comparative benchmark and practical guidance for task-adaptive LLM deployment.💡 Deep Analysis
📄 Full Content
📸 Image Gallery
Reference
This content is AI-processed based on open access ArXiv data.