F-BFQ: Flexible Block Floating-Point Quantization Accelerator for LLMs
Reading time: 2 minute
...
📝 Original Info
- Title: F-BFQ: Flexible Block Floating-Point Quantization Accelerator for LLMs
- ArXiv ID: 2510.13401
- Date: 2025-10-15
- Authors: ** 논문에 저자 정보가 제공되지 않았습니다. **
📝 Abstract
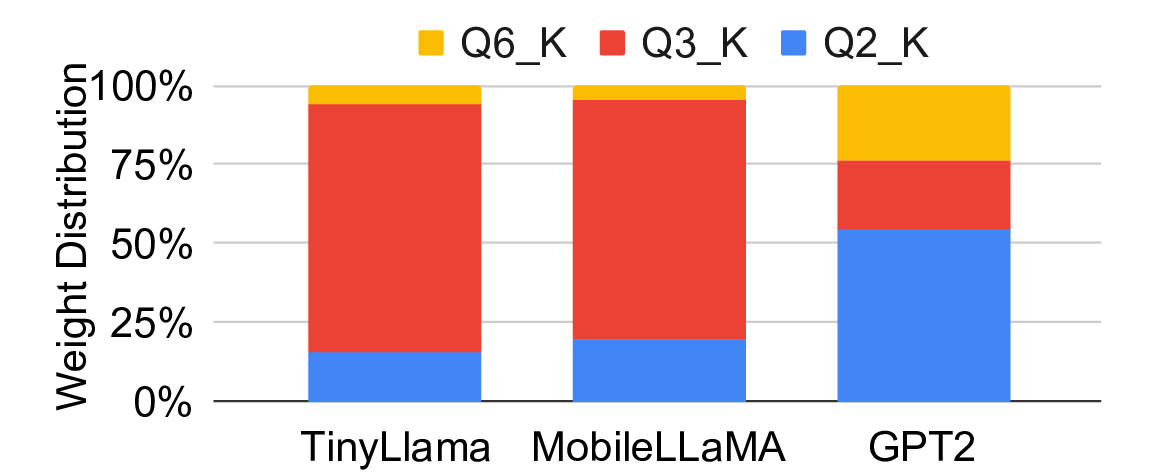
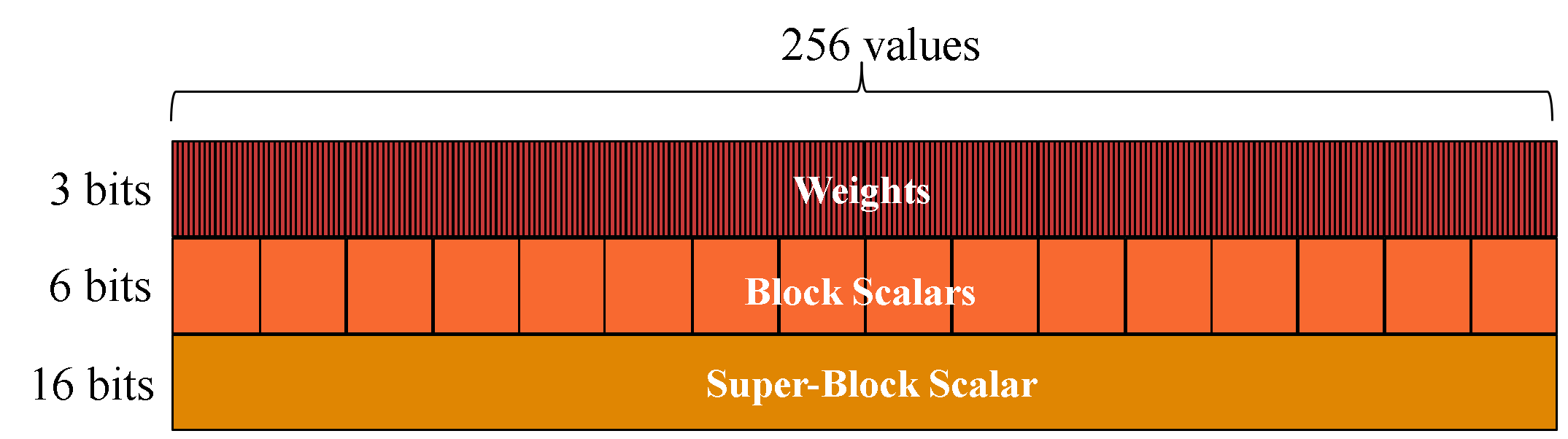
Large Language Models (LLMs) have become increasingly prominent for daily tasks, from improving sound-totext translation to generating additional frames for the latest video games. With the help of LLM inference frameworks, such as llama.cpp, which support optimizations such as KV-caching and quantization, it is now easier than ever to deploy LLMs on edge devices. Quantization is fundamental to enable LLMs on resource-constrained edge devices, and llama.cpp utilizes block floating point (BFP) quantization to drastically reduce the bit width of weights and input tensors, the memory footprint, and the computational power required to run LLMs. LLMs are typically quantized with mixed BFP quantization across the model layers to reduce the loss of model accuracy due to quantization. Therefore, to efficiently accelerate across the layers of BFP-quantized LLMs, specialized accelerators need to support different BFP variants without reconfiguration. To address this issue, we propose a Flexible Block FloatingPoint Quantization (F-BFQ) accelerator, which can dynamically switch between two BFP quantization variants and perform matrix multiplication (MatMul) operations. Our initial F-BFQ accelerator design, deployed on the AMD Kria board, reduces inference time by 1.4x on average over the Arm NEON-based CPU execution across three BFP quantized LLMs while achieving 5.2 tokens per second (~3.9 words per second).💡 Deep Analysis
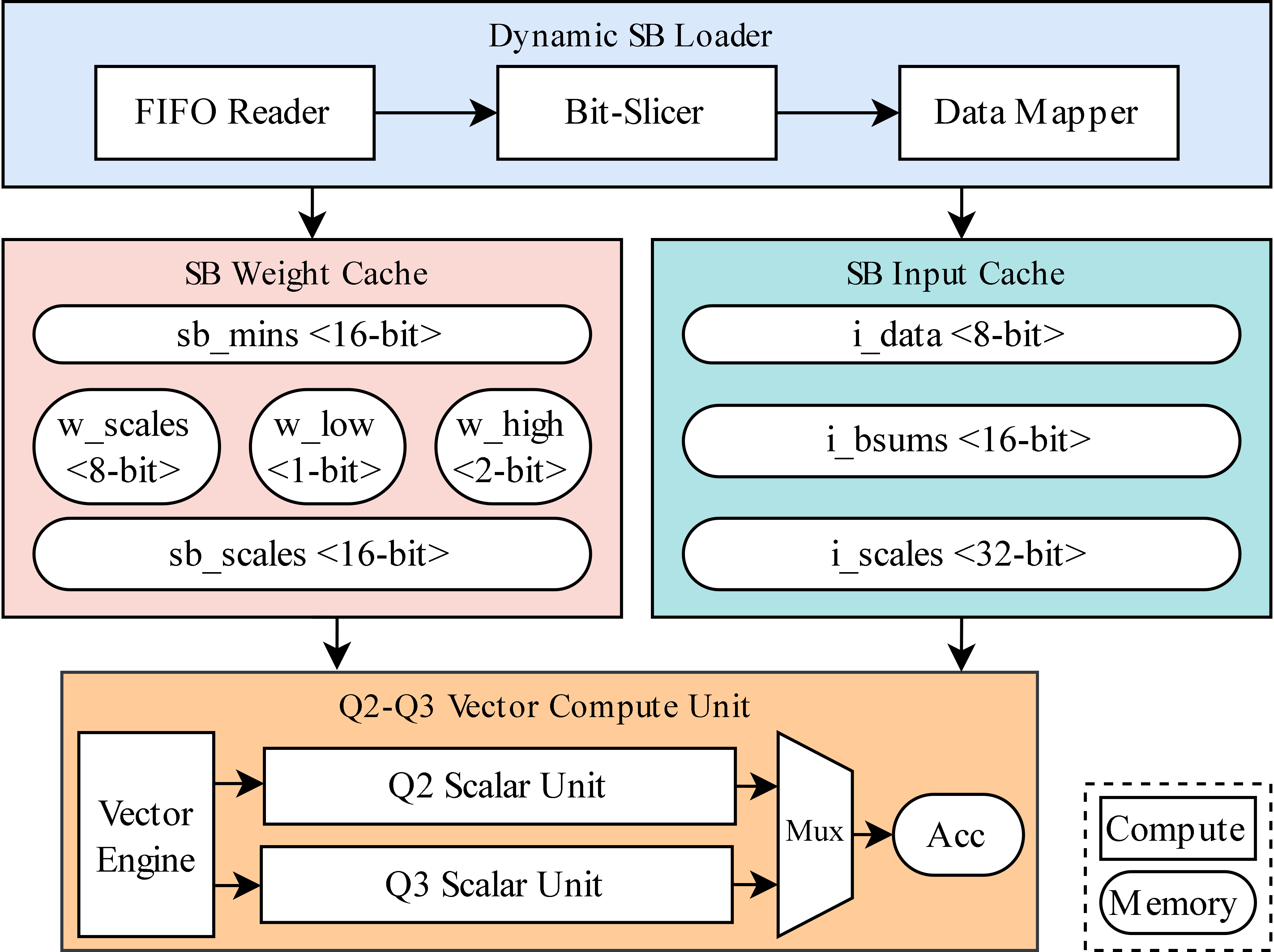
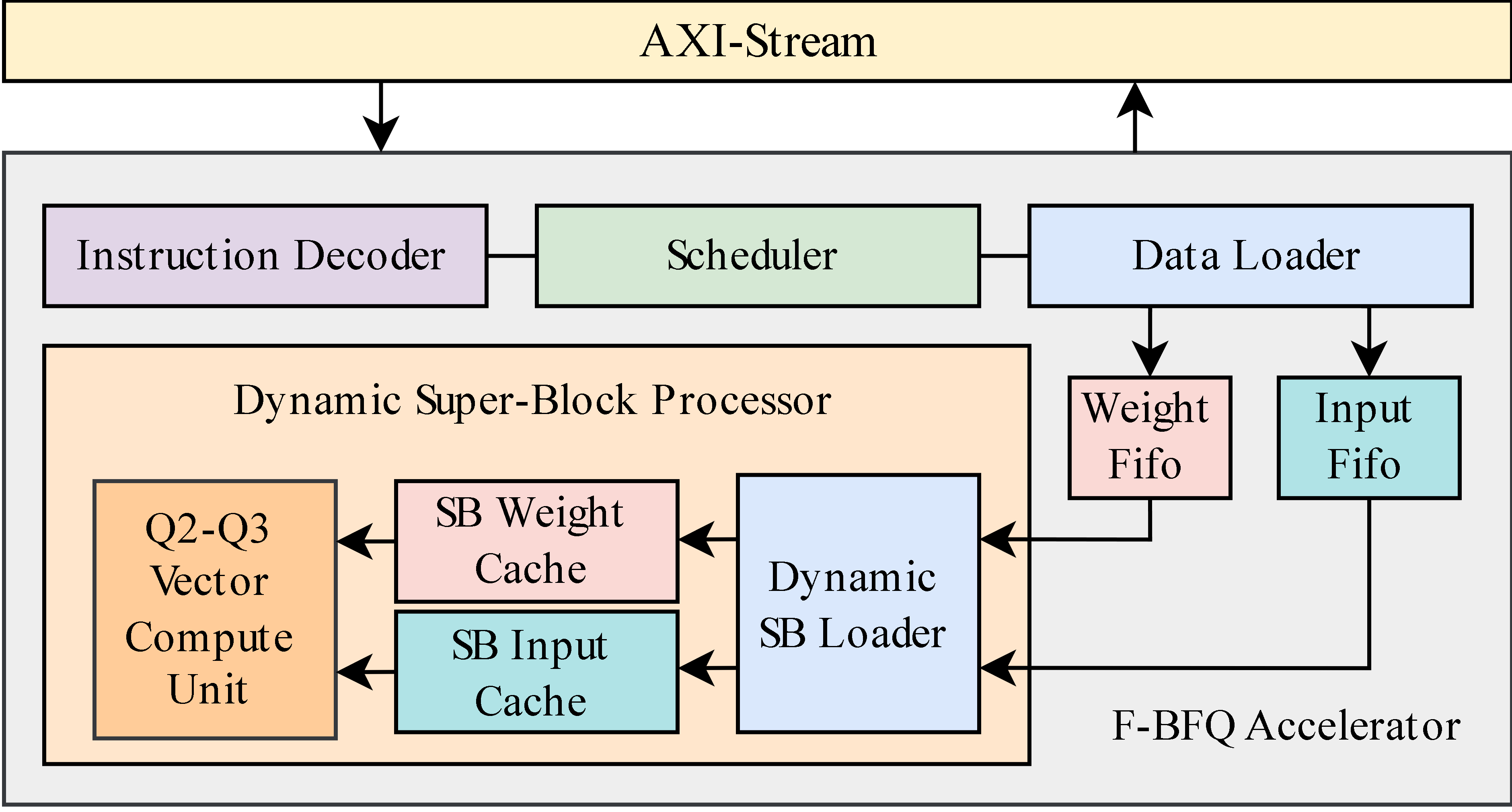
📄 Full Content
📸 Image Gallery
Reference
This content is AI-processed based on open access ArXiv data.