LONGQAEVAL: Designing Reliable Evaluations of Long-Form Clinical QA under Resource Constraints
Reading time: 1 minute
...
📝 Original Info
- Title: LONGQAEVAL: Designing Reliable Evaluations of Long-Form Clinical QA under Resource Constraints
- ArXiv ID: 2510.10415
- Date: 2025-10-12
- Authors: ** - 논문에 명시된 저자 정보가 제공되지 않았습니다. (※ 필요 시 원문 혹은 DOI를 확인해 주세요.) **
📝 Abstract
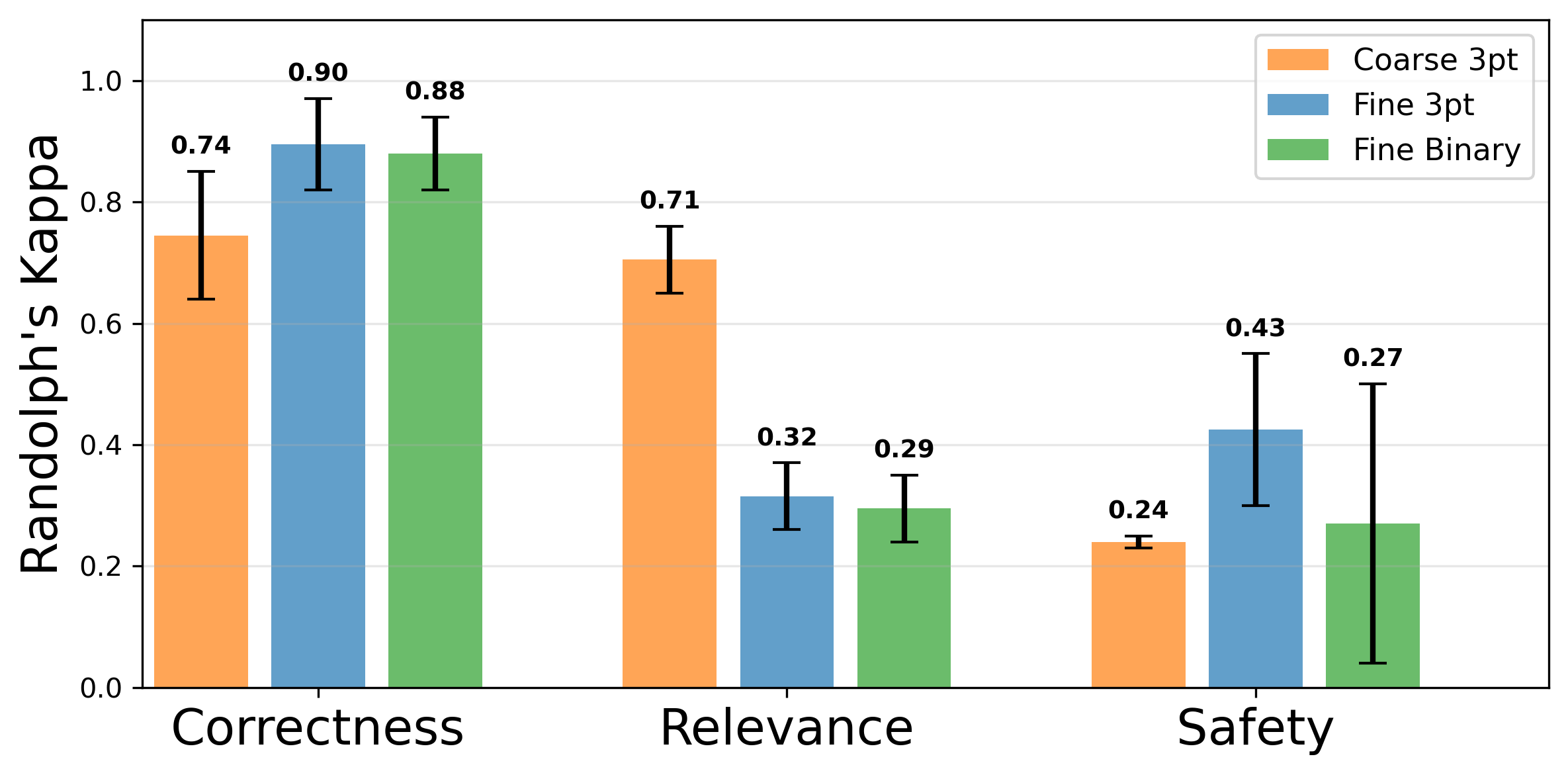
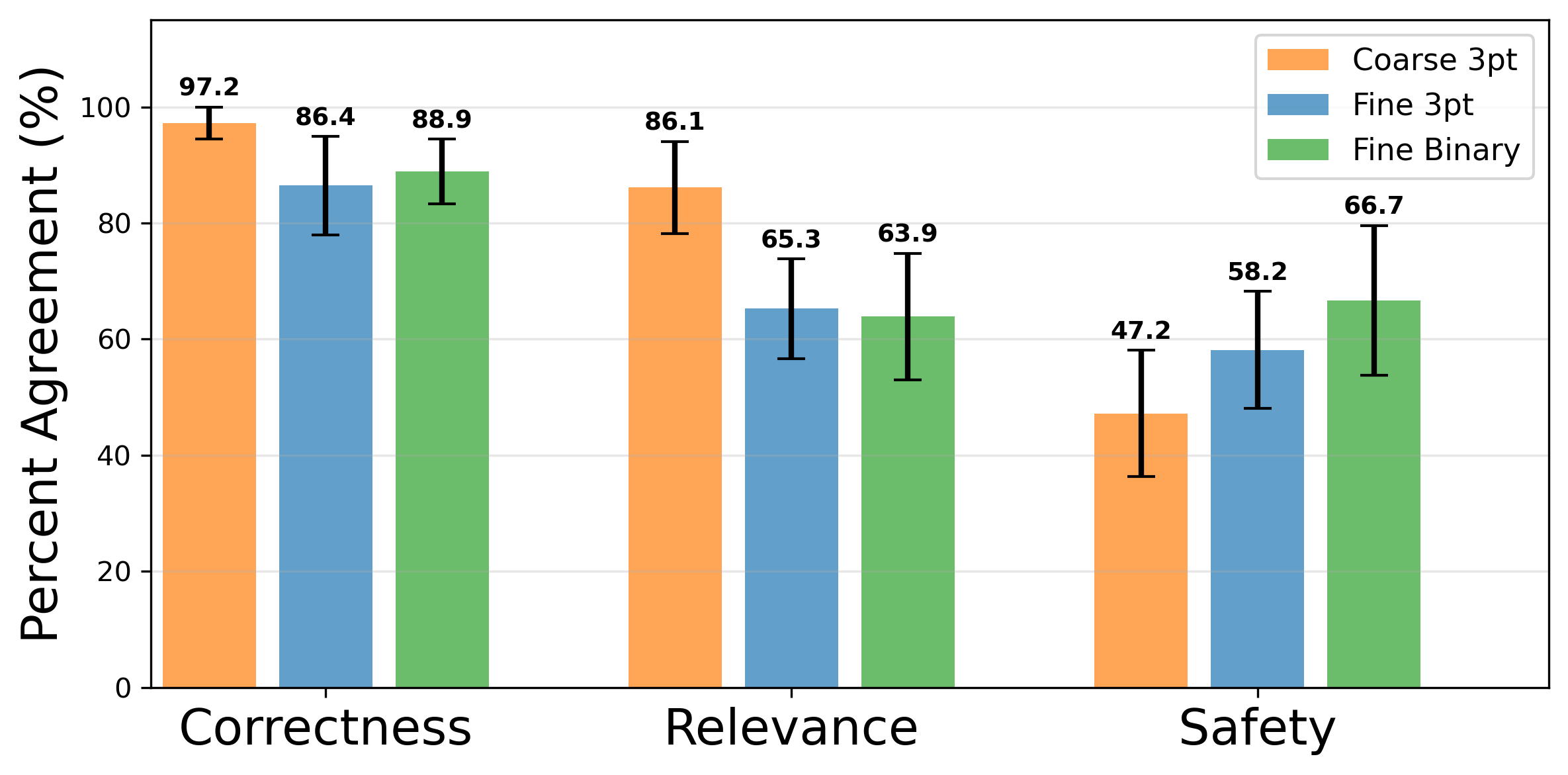
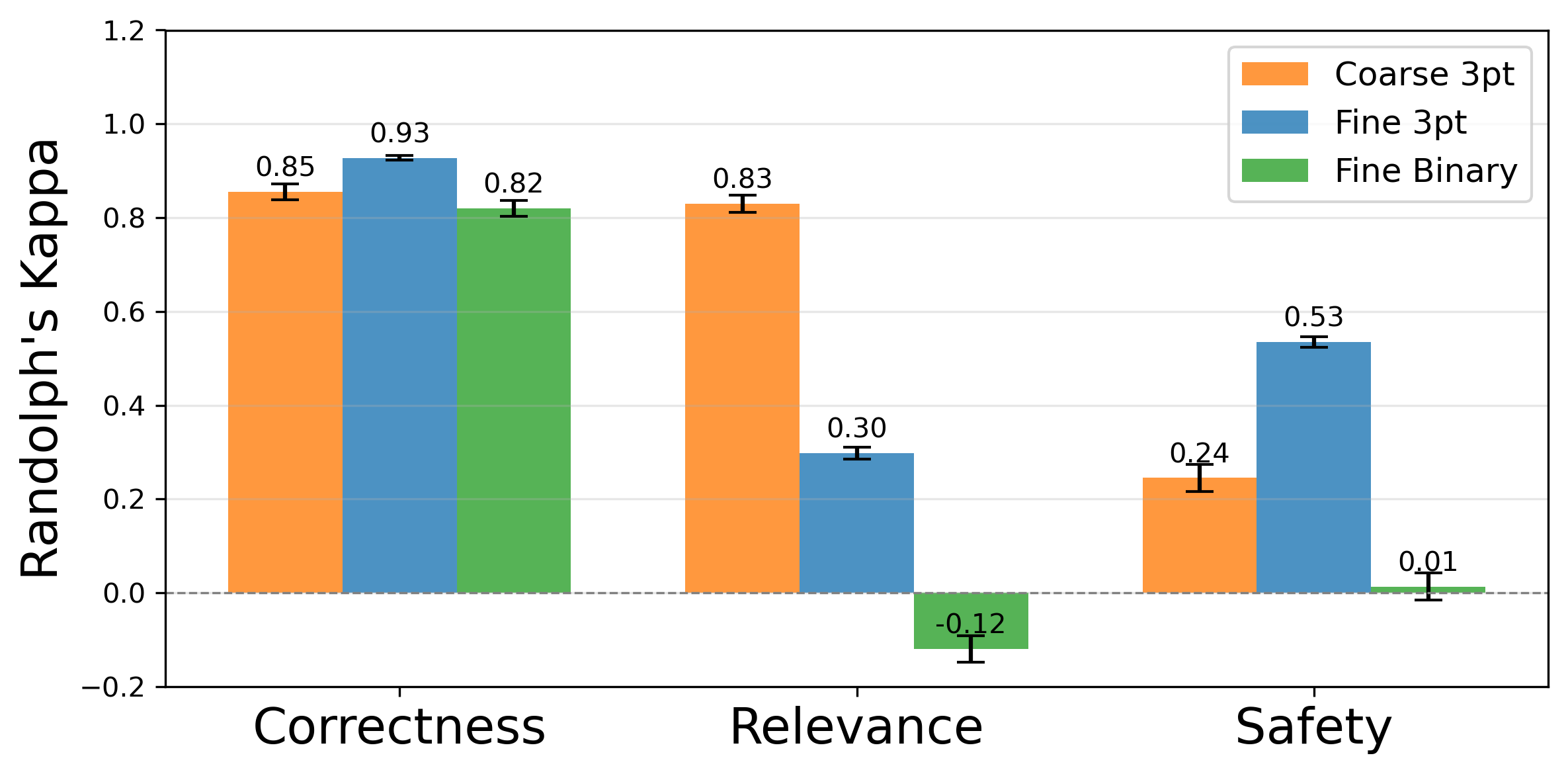
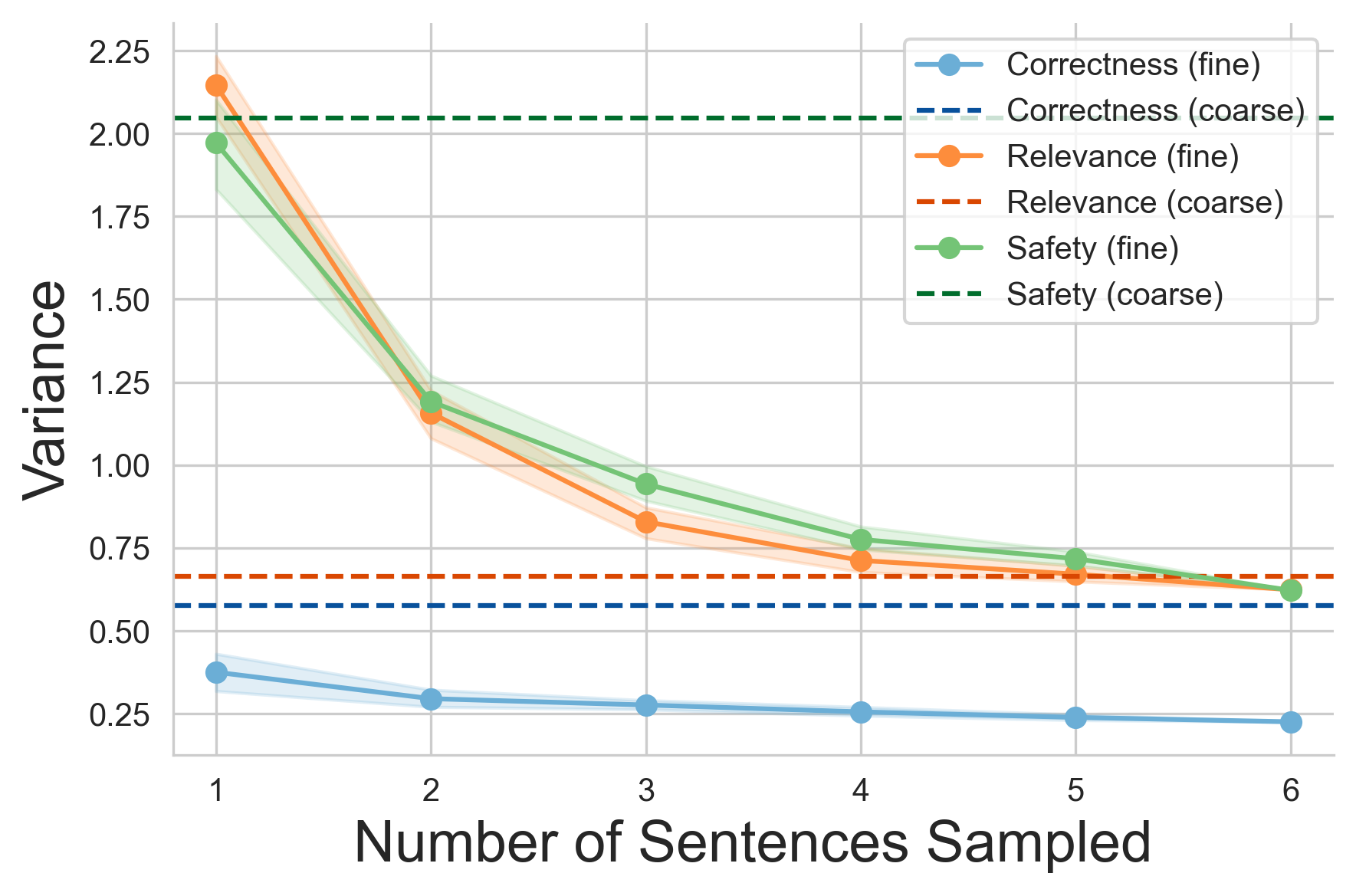
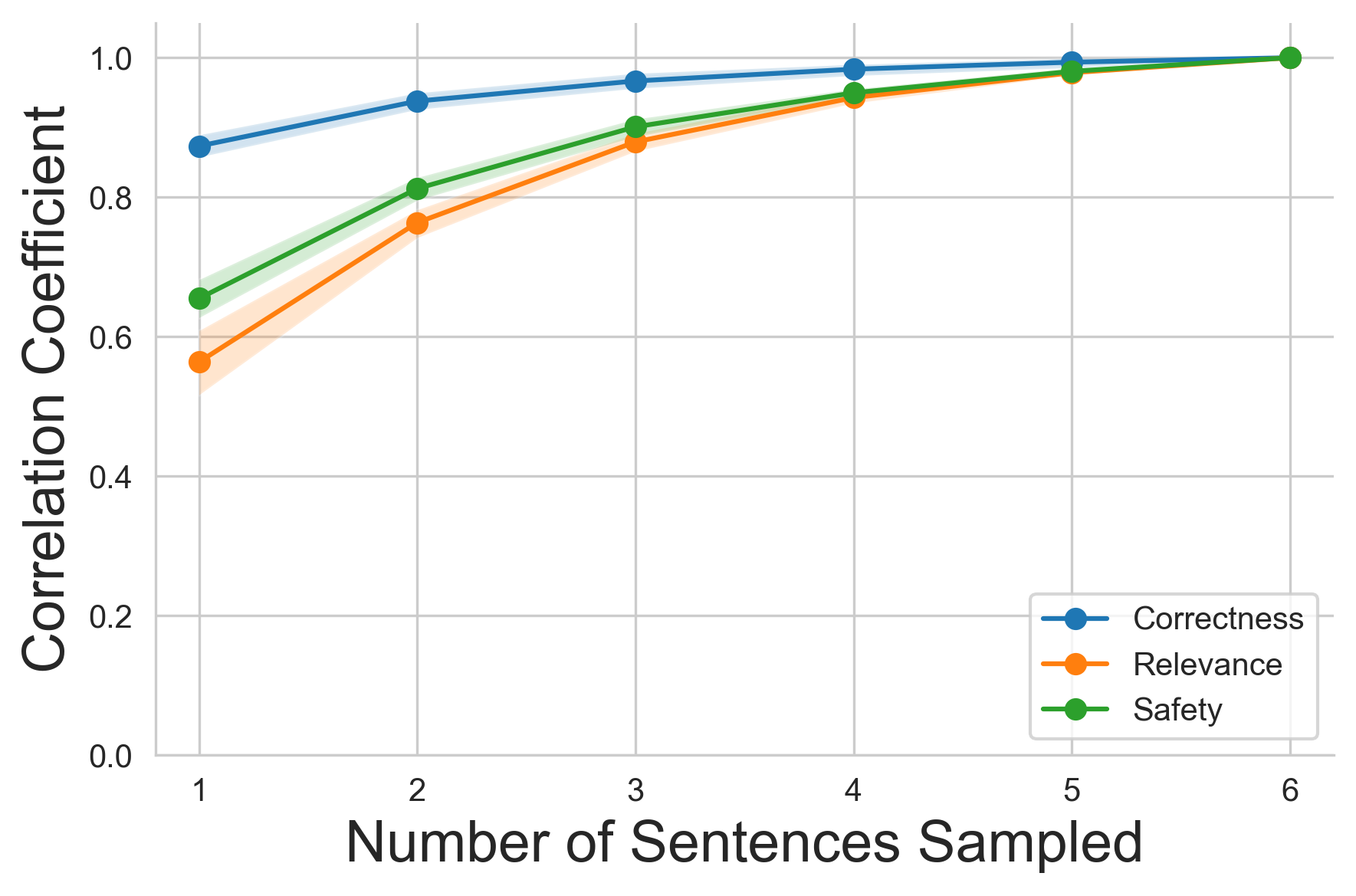
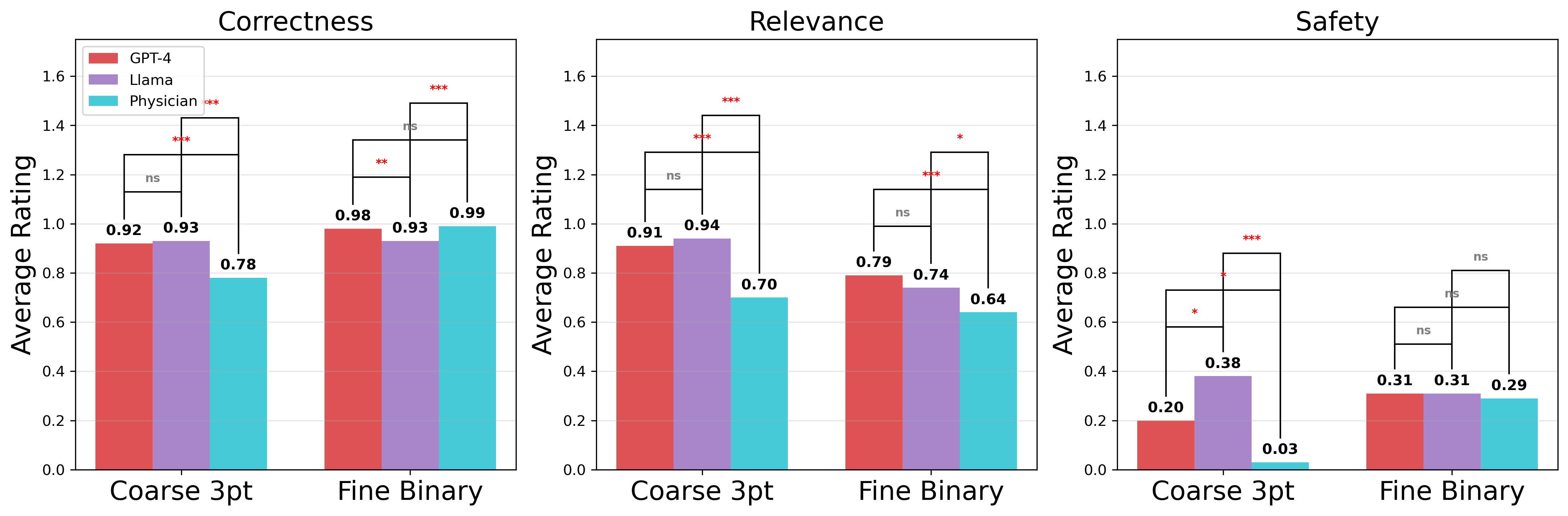
Evaluating long-form clinical question answering (QA) systems is resource-intensive and challenging: accurate judgments require medical expertise and achieving consistent human judgments over long-form text is difficult. We introduce LongQAEval, an evaluation framework and set of evaluation recommendations for limited-resource and high-expertise settings. Based on physician annotations of 300 real patient questions answered by physicians and LLMs, we compare coarse answer-level versus fine-grained sentence-level evaluation over the dimensions of correctness, relevance, and safety. We find that inter-annotator agreement (IAA) varies by dimension: fine-grained annotation improves agreement on correctness, coarse improves agreement on relevance, and judgments on safety remain inconsistent. Additionally, annotating only a small subset of sentences can provide reliability comparable to coarse annotations, reducing cost and effort.💡 Deep Analysis
📄 Full Content
📸 Image Gallery
Reference
This content is AI-processed based on open access ArXiv data.