Quantifying data needs in surrogate modeling for flow fields in two-dimensional stirred tanks with physics-informed neural networks
📝 Original Info
- Title: Quantifying data needs in surrogate modeling for flow fields in two-dimensional stirred tanks with physics-informed neural networks
- ArXiv ID: 2507.11640
- Date: 2025-07-15
- Authors: Researchers mentioned in the ArXiv original paper
📝 Abstract
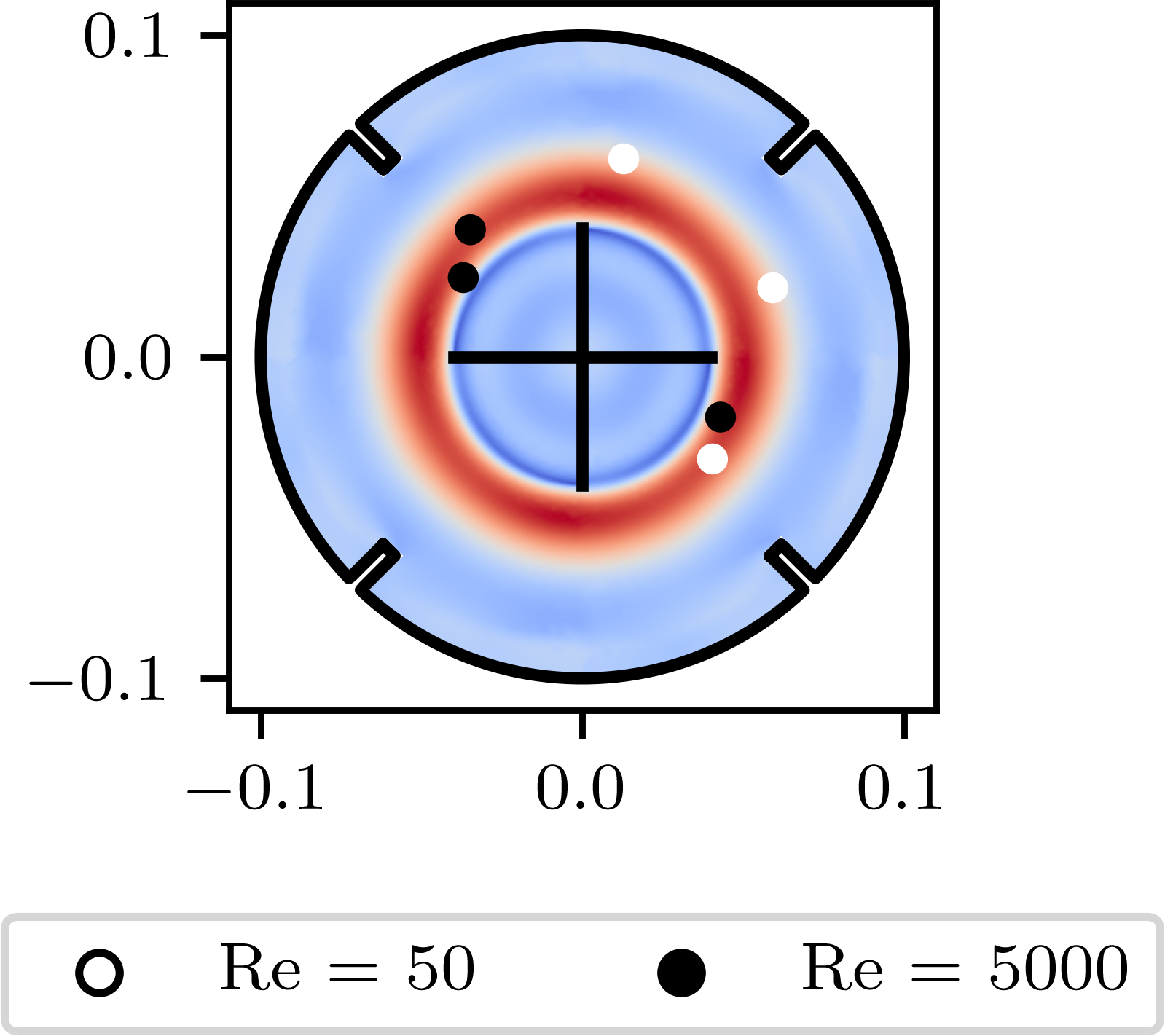
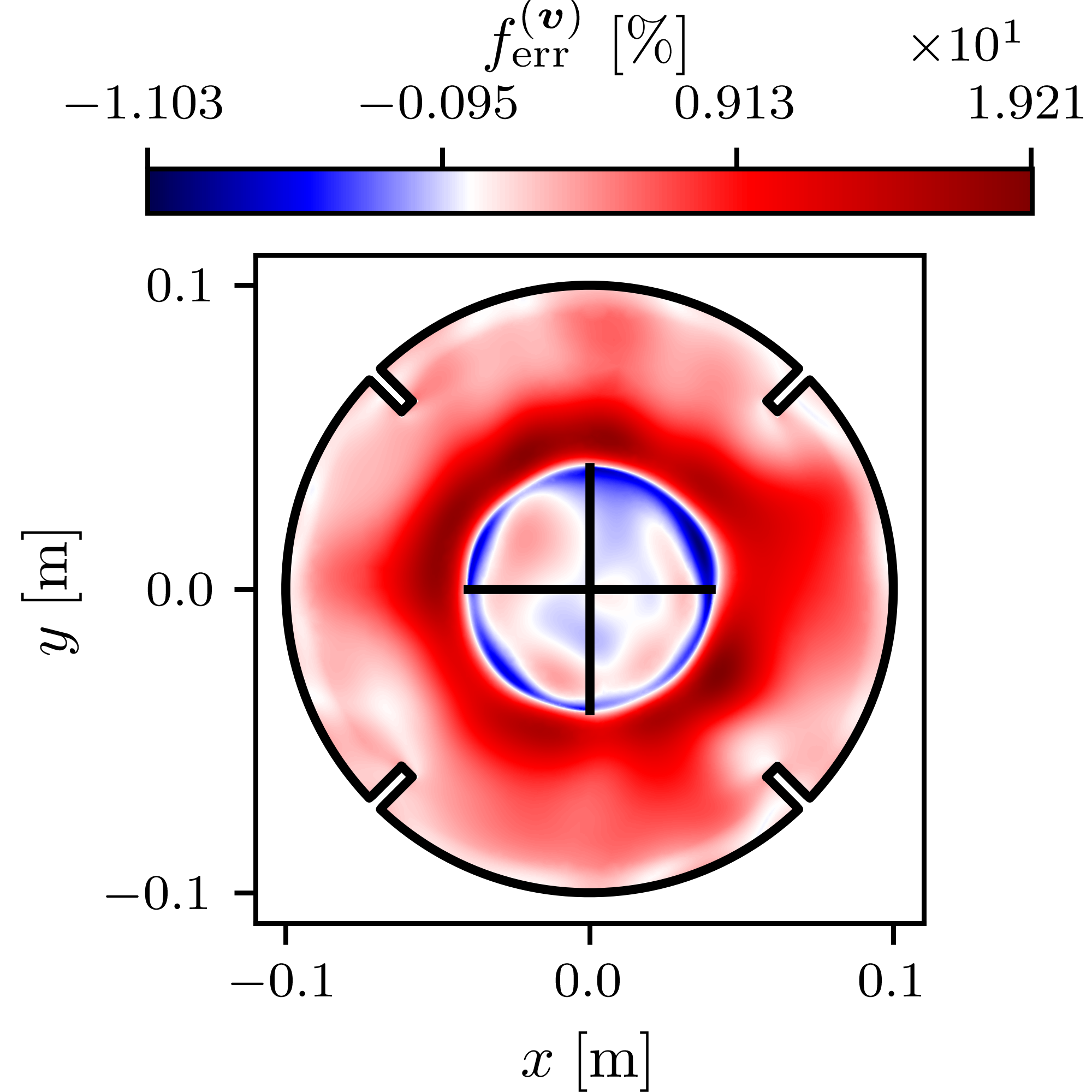
Stirred tanks are vital in chemical and biotechnological processes, particularly as bioreactors. Although computational fluid dynamics (CFD) is widely used to model the flow in stirred tanks, its high computational cost$-$especially in multi-query scenarios for process design and optimization$-$drives the need for efficient data-driven surrogate models. However, acquiring sufficiently large datasets can be costly. Physics-informed neural networks (PINNs) offer a promising solution to reduce data requirements while maintaining accuracy by embedding underlying physics into neural network (NN) training. This study quantifies the data requirements of vanilla PINNs for developing surrogate models of a flow field in a 2D stirred tank. We compare these requirements with classical supervised neural networks and boundary-informed neural networks (BINNs). Our findings demonstrate that surrogate models can achieve prediction errors around 3% across Reynolds numbers from 50 to 5000 using as few as six datapoints. Moreover, employing an approximation of the velocity profile in place of real data labels leads to prediction errors of around 2.5%. These results indicate that even with limited or approximate datasets, PINNs can be effectively trained to deliver high accuracy comparable to high-fidelity data.💡 Deep Analysis
This research explores the key findings and methodology presented in the paper: Quantifying data needs in surrogate modeling for flow fields in two-dimensional stirred tanks with physics-informed neural networks.Stirred tanks are vital in chemical and biotechnological processes, particularly as bioreactors. Although computational fluid dynamics (CFD) is widely used to model the flow in stirred tanks, its high computational cost$-$especially in multi-query scenarios for process design and optimization$-$drives the need for efficient data-driven surrogate models. However, acquiring sufficiently large datasets can be costly. Physics-informed neural networks (PINNs) offer a promising solution to reduce data requirements while maintaining accuracy by embedding underlying physics into neural network (NN) training. This study quantifies the data requirements of vanilla PINNs for developing surrogate models of a flow field in a 2D stirred tank. We compare these requirements with classical supervised neural networks and boundary-informed neural networks (BINNs). Our findings demonstrate that surrogate models can achieve prediction errors around 3% across Reynolds numbers from 50 to 5000 using as few as
📄 Full Content
📸 Image Gallery