FramePrompt: In-context Controllable Animation with Zero Structural Changes
Reading time: 1 minute
...
📝 Original Info
- Title: FramePrompt: In-context Controllable Animation with Zero Structural Changes
- ArXiv ID: 2506.17301
- Date: 2025-06-17
- Authors: ** 논문에 명시된 저자 정보가 제공되지 않았습니다. (정보 없음) **
📝 Abstract
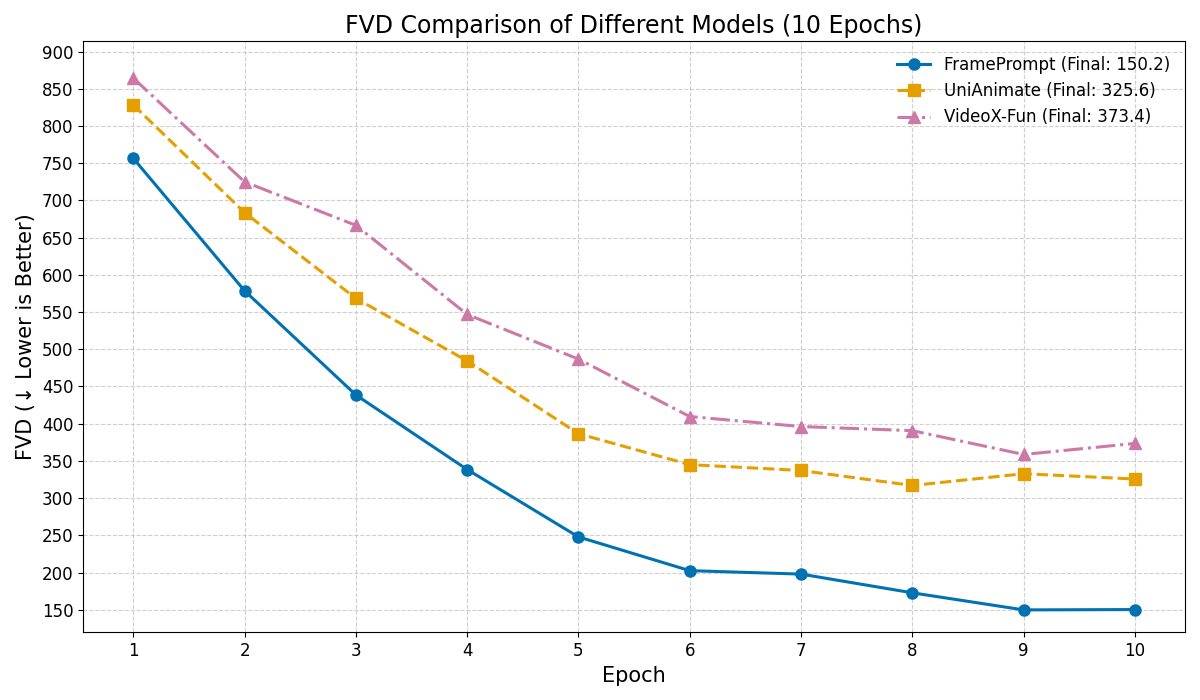
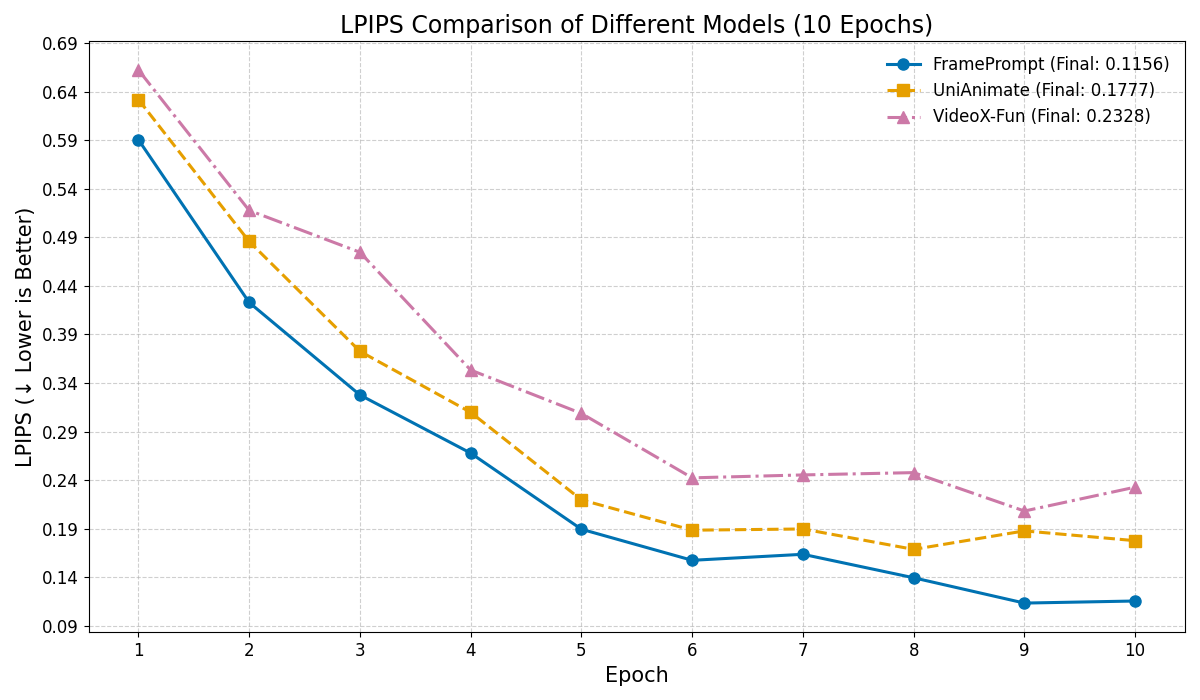
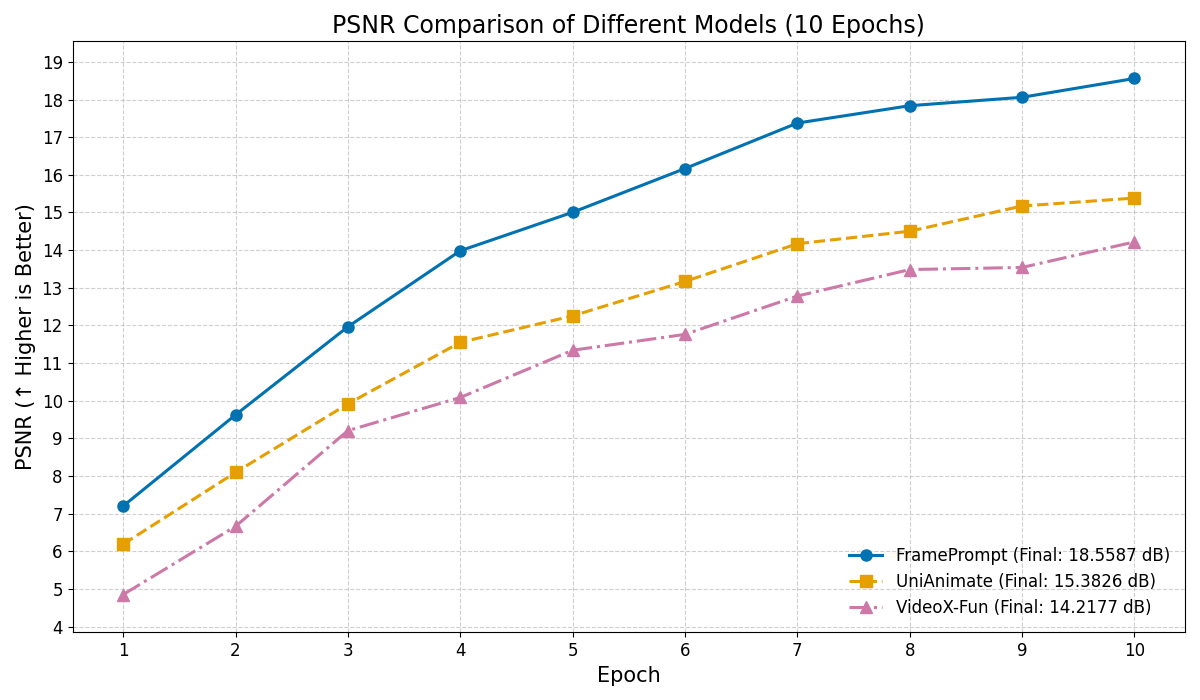
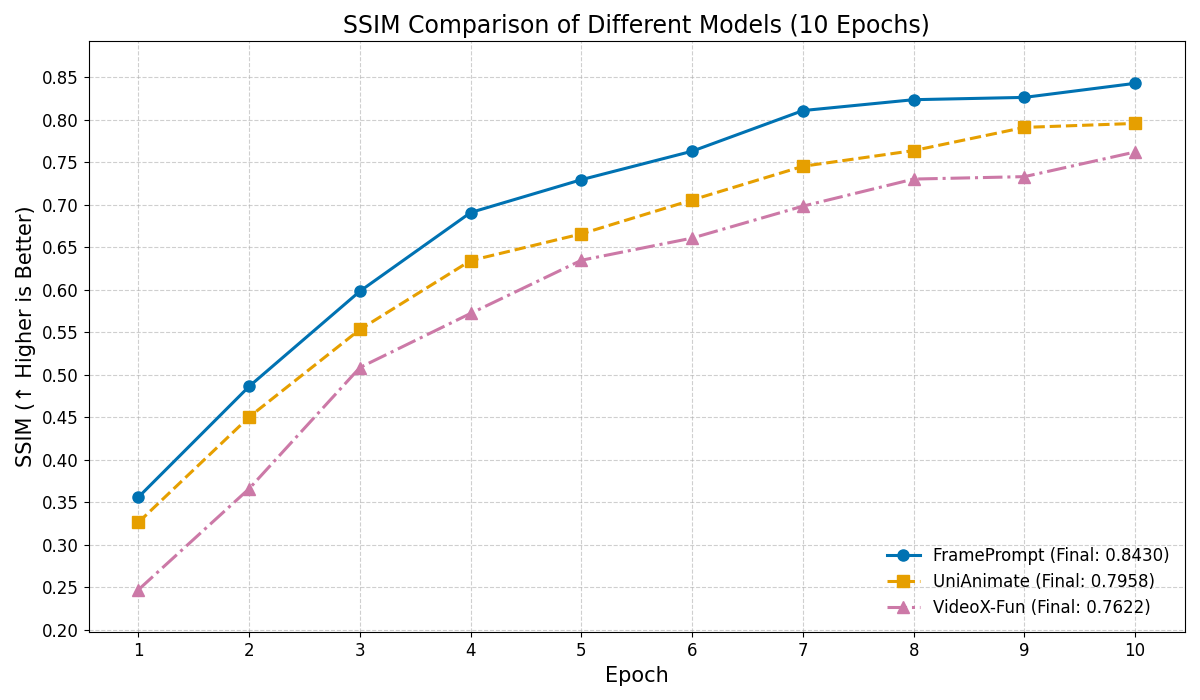
Generating controllable character animation from a reference image and motion guidance remains a challenging task due to the inherent difficulty of injecting appearance and motion cues into video diffusion models. Prior works often rely on complex architectures, explicit guider modules, or multi-stage processing pipelines, which increase structural overhead and hinder deployment. Inspired by the strong visual context modeling capacity of pre-trained video diffusion transformers, we propose FramePrompt, a minimalist yet powerful framework that treats reference images, skeleton-guided motion, and target video clips as a unified visual sequence. By reformulating animation as a conditional future prediction task, we bypass the need for guider networks and structural modifications. Experiments demonstrate that our method significantly outperforms representative baselines across various evaluation metrics while also simplifying training. Our findings highlight the effectiveness of sequence-level visual conditioning and demonstrate the potential of pre-trained models for controllable animation without architectural changes.💡 Deep Analysis
📄 Full Content
📸 Image Gallery


Reference
This content is AI-processed based on open access ArXiv data.