A Hybrid Heuristic Framework for Resource-Efficient Querying of Scientific Experiments Data
📝 Original Info
- Title: A Hybrid Heuristic Framework for Resource-Efficient Querying of Scientific Experiments Data
- ArXiv ID: 2506.10422
- Date: 2025-06-12
- Authors: Researchers mentioned in the ArXiv original paper
📝 Abstract
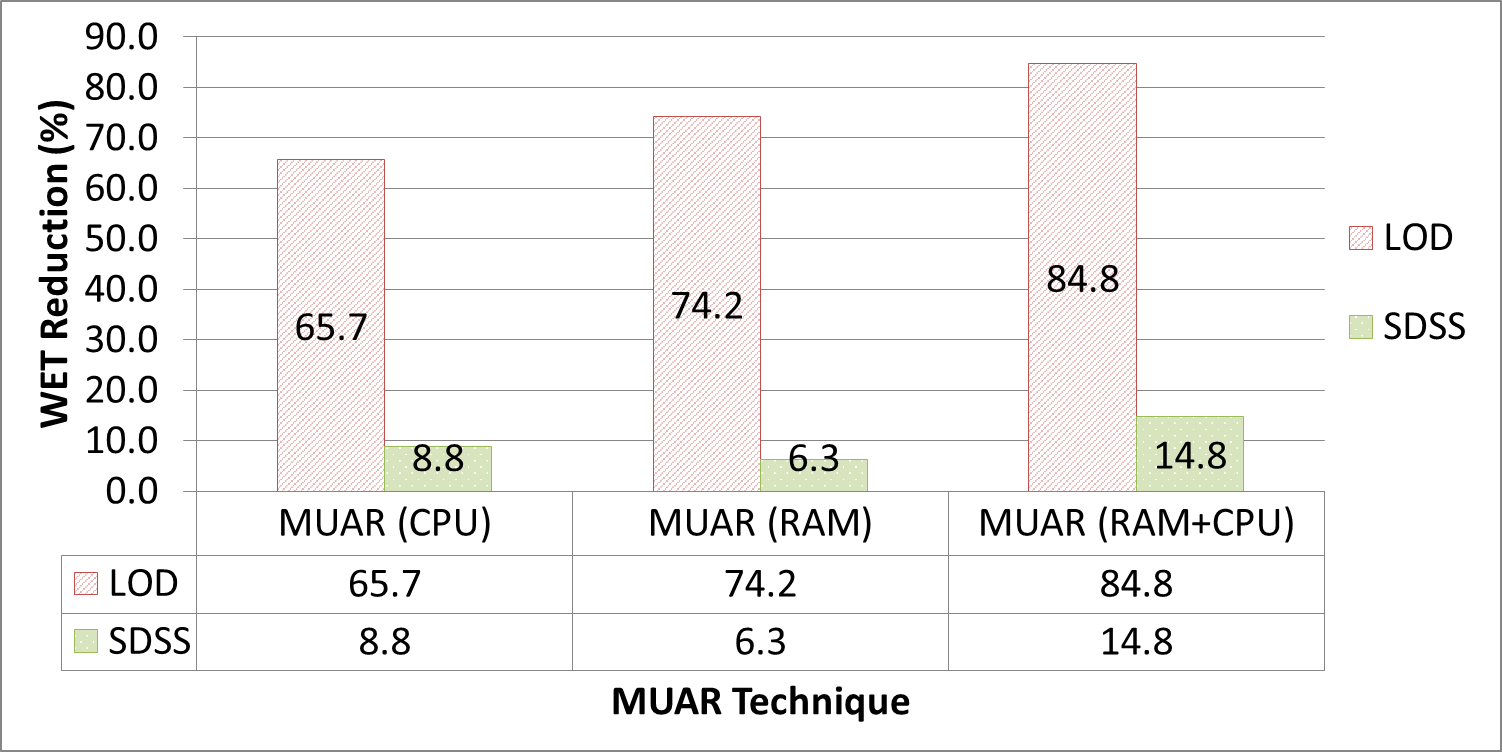
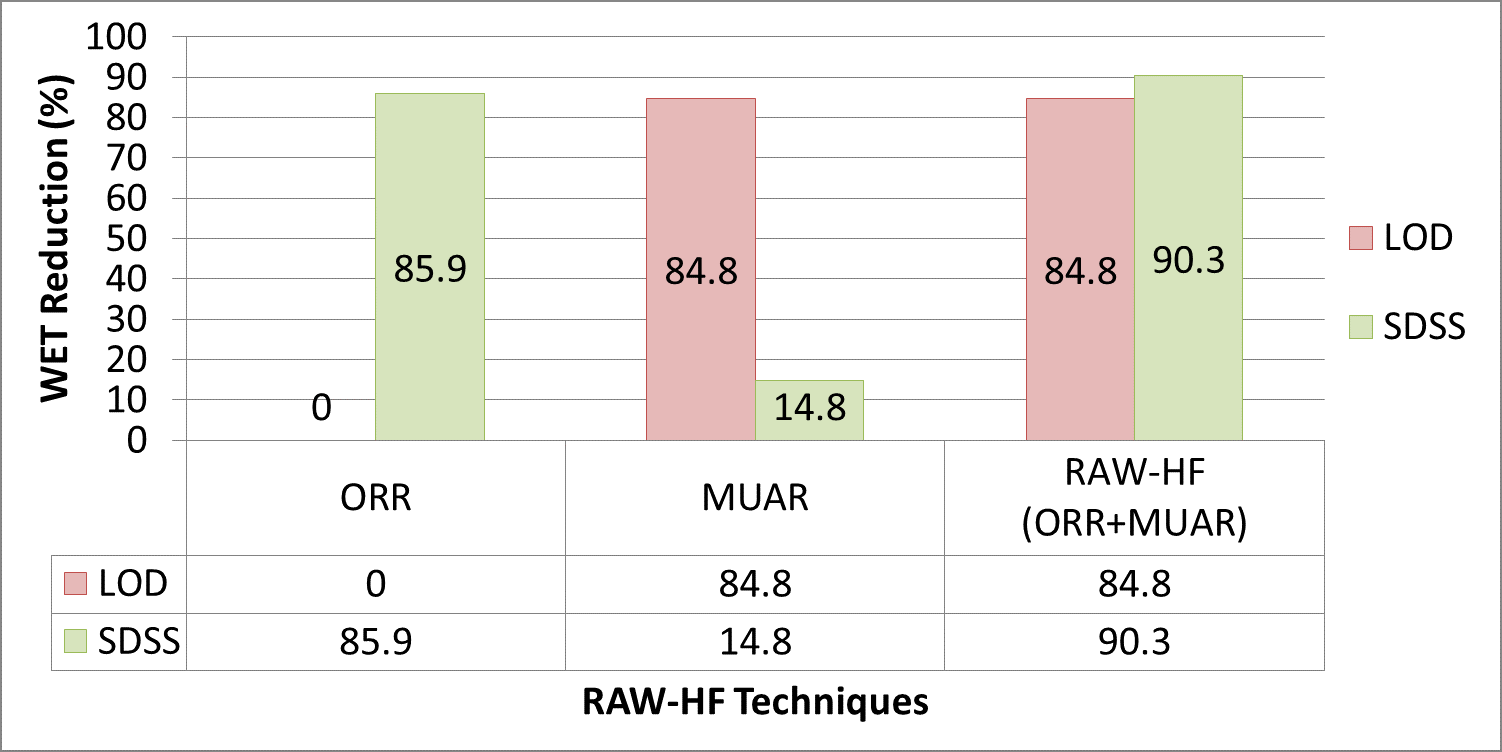
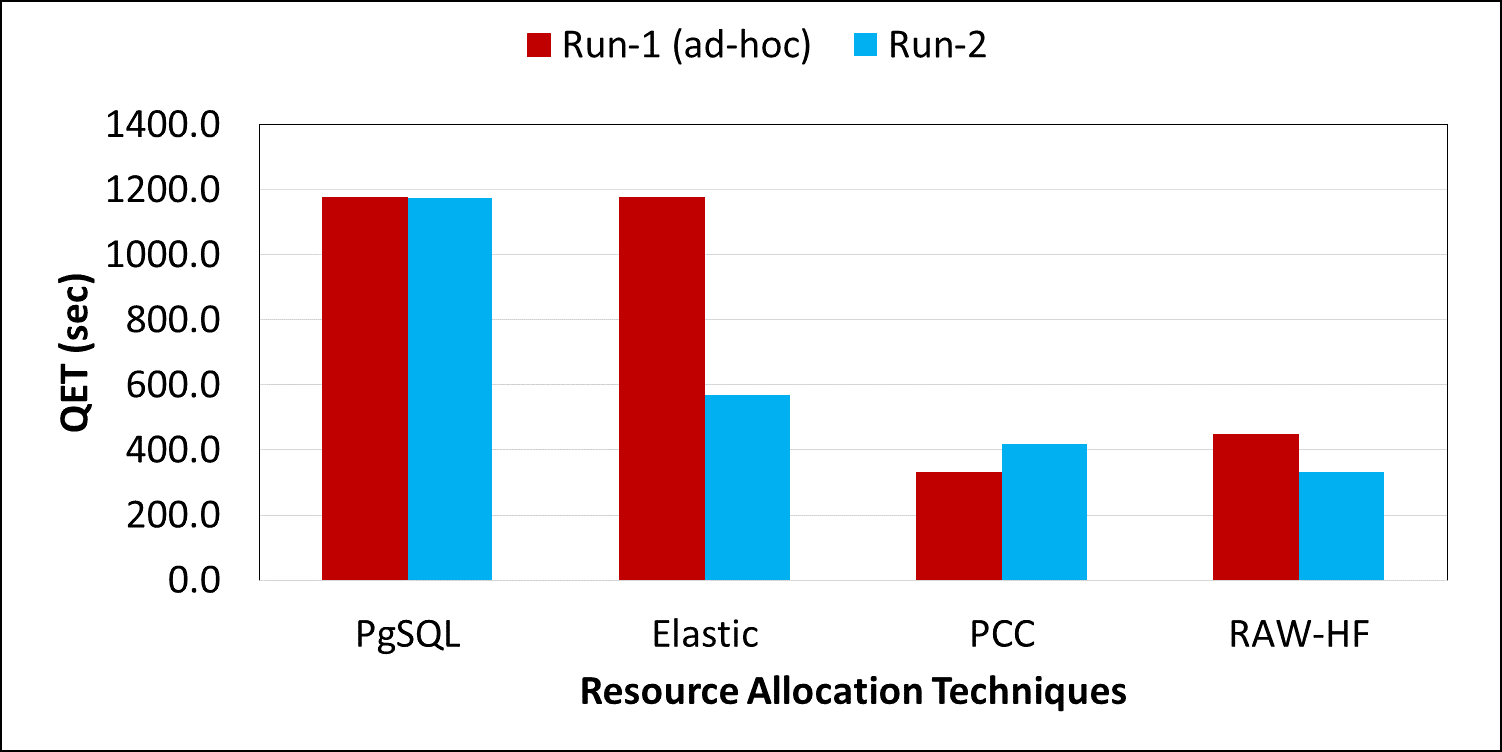
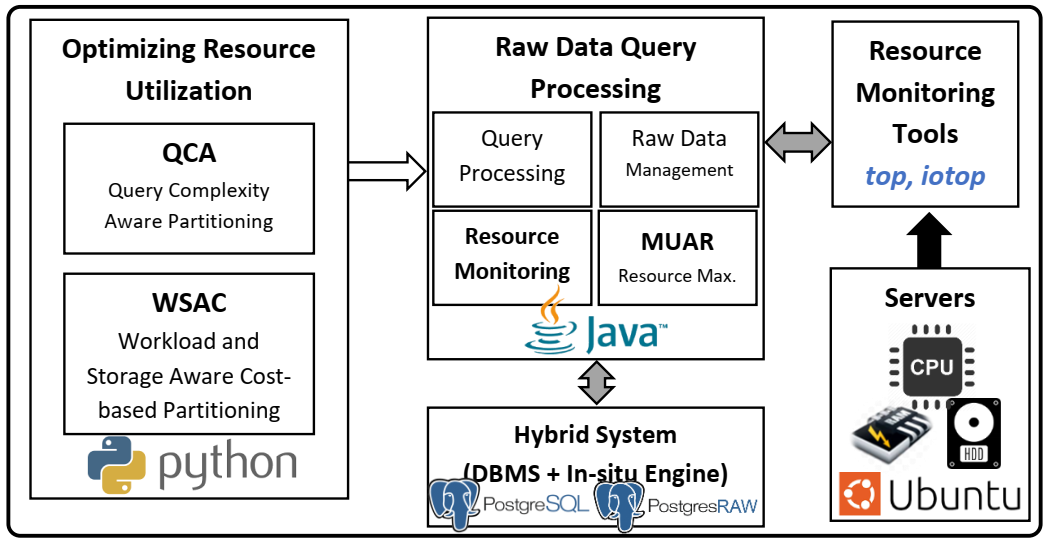
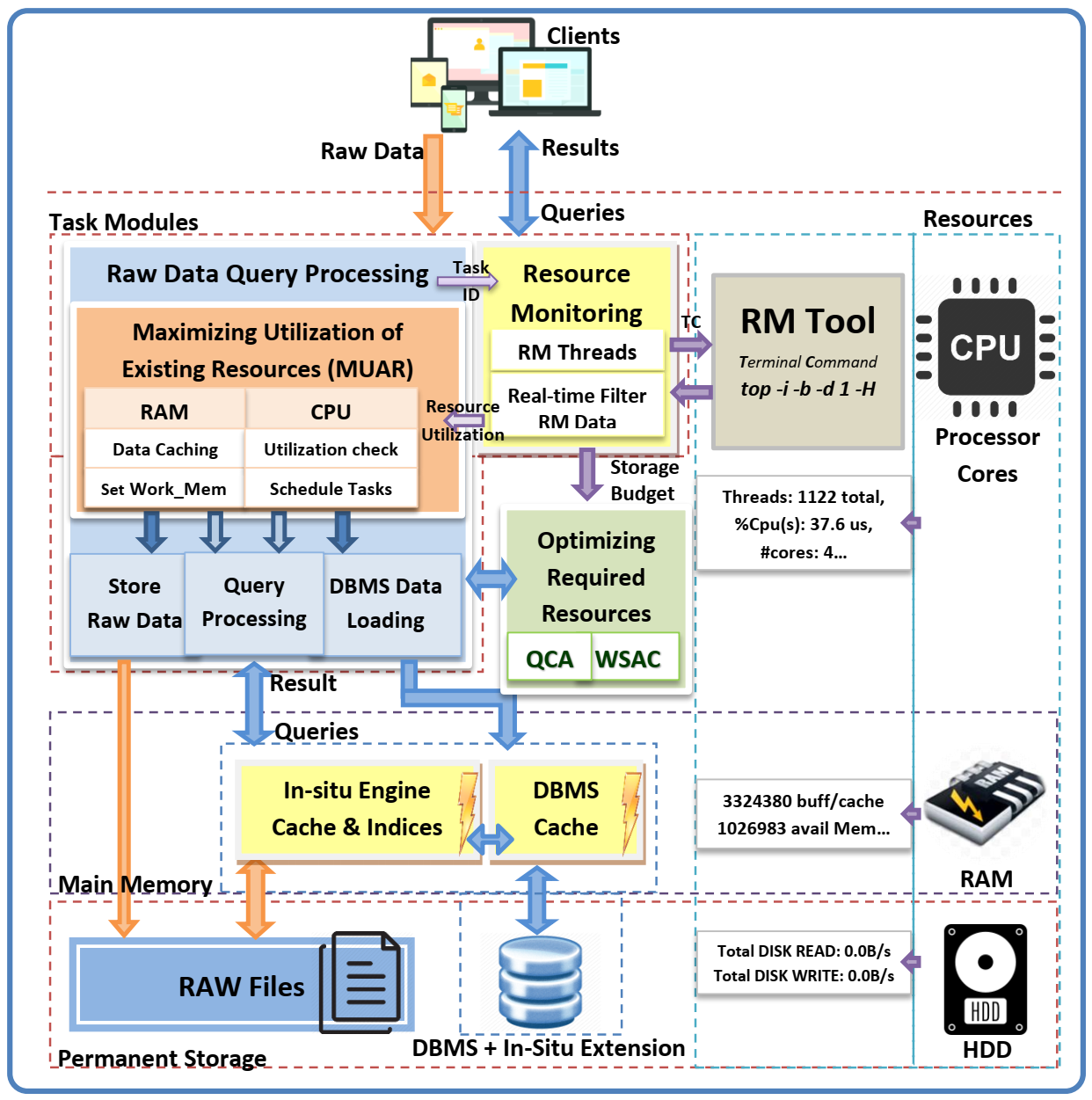
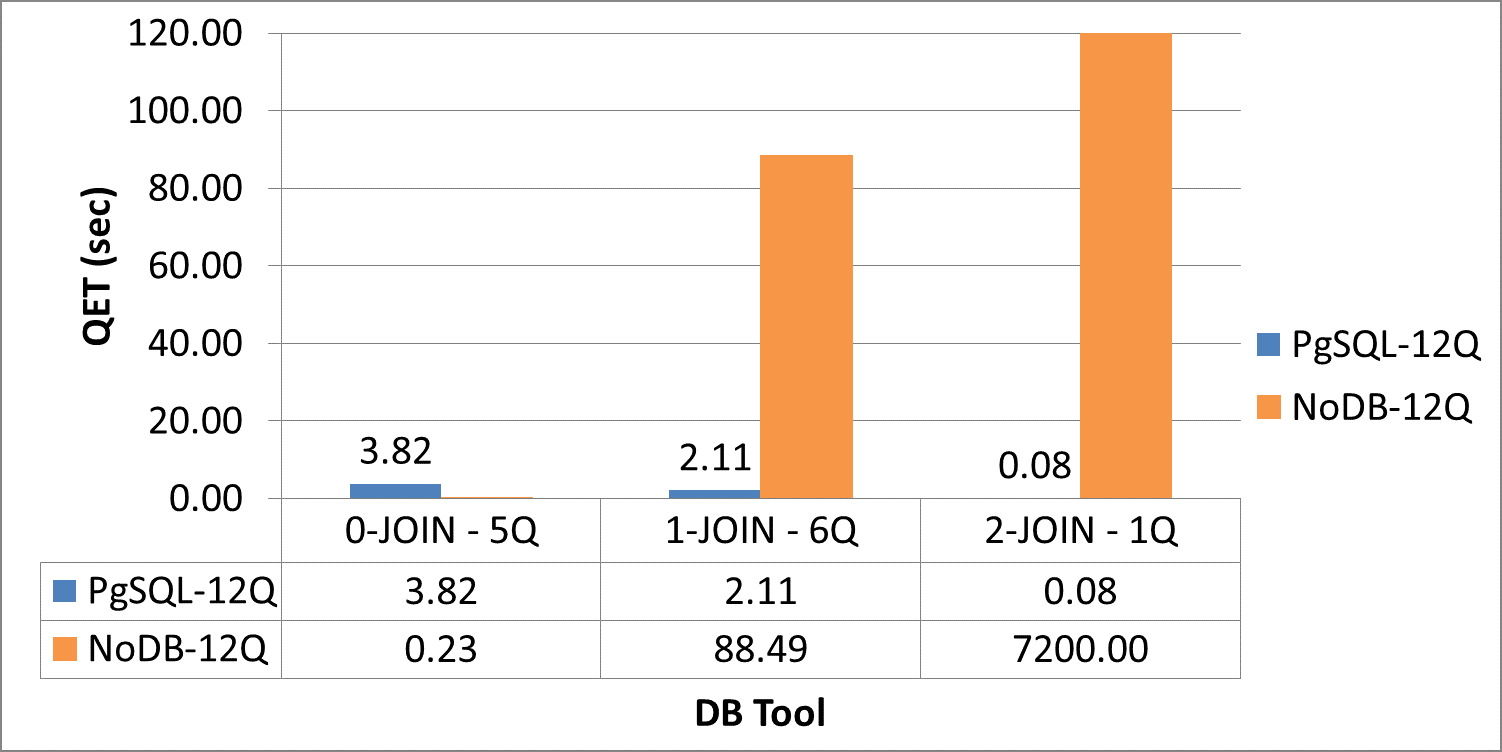
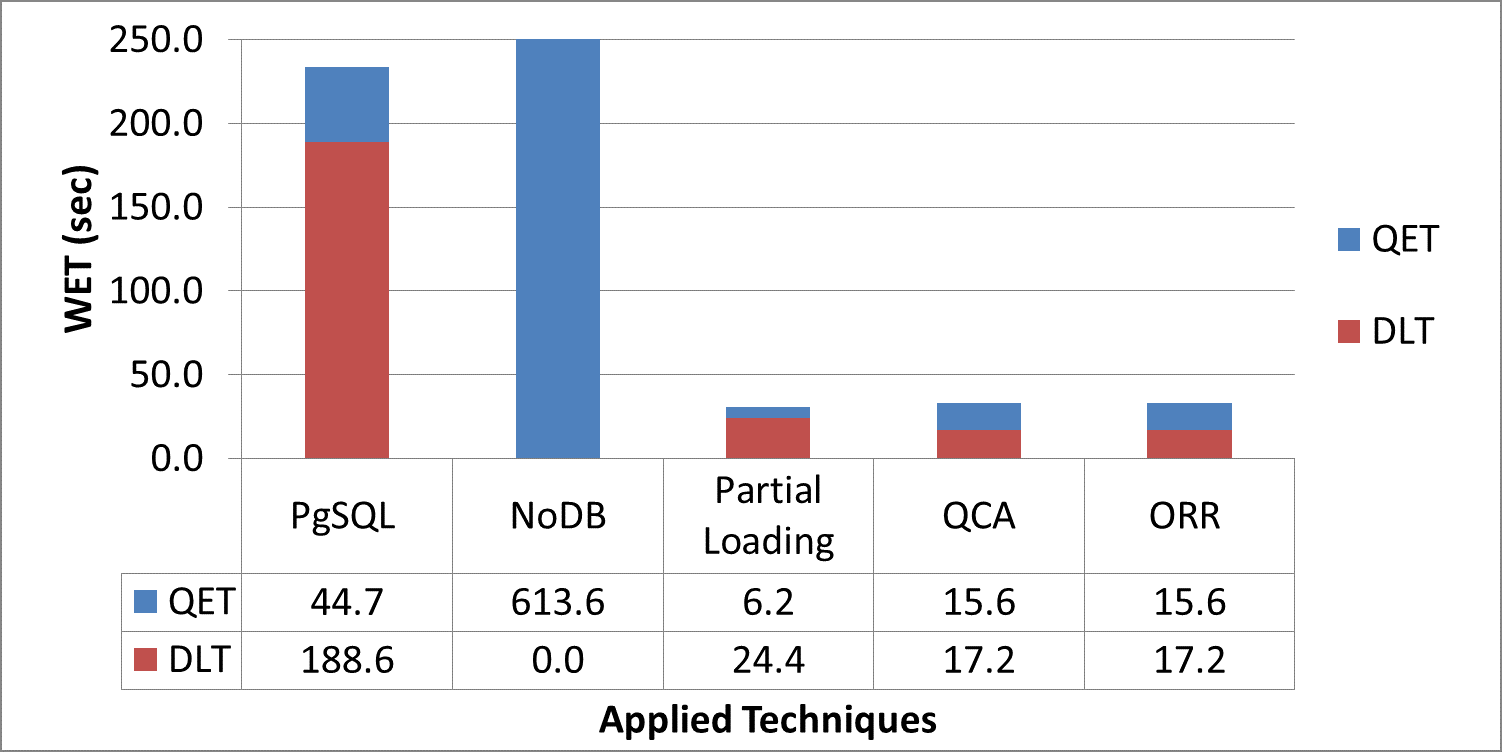
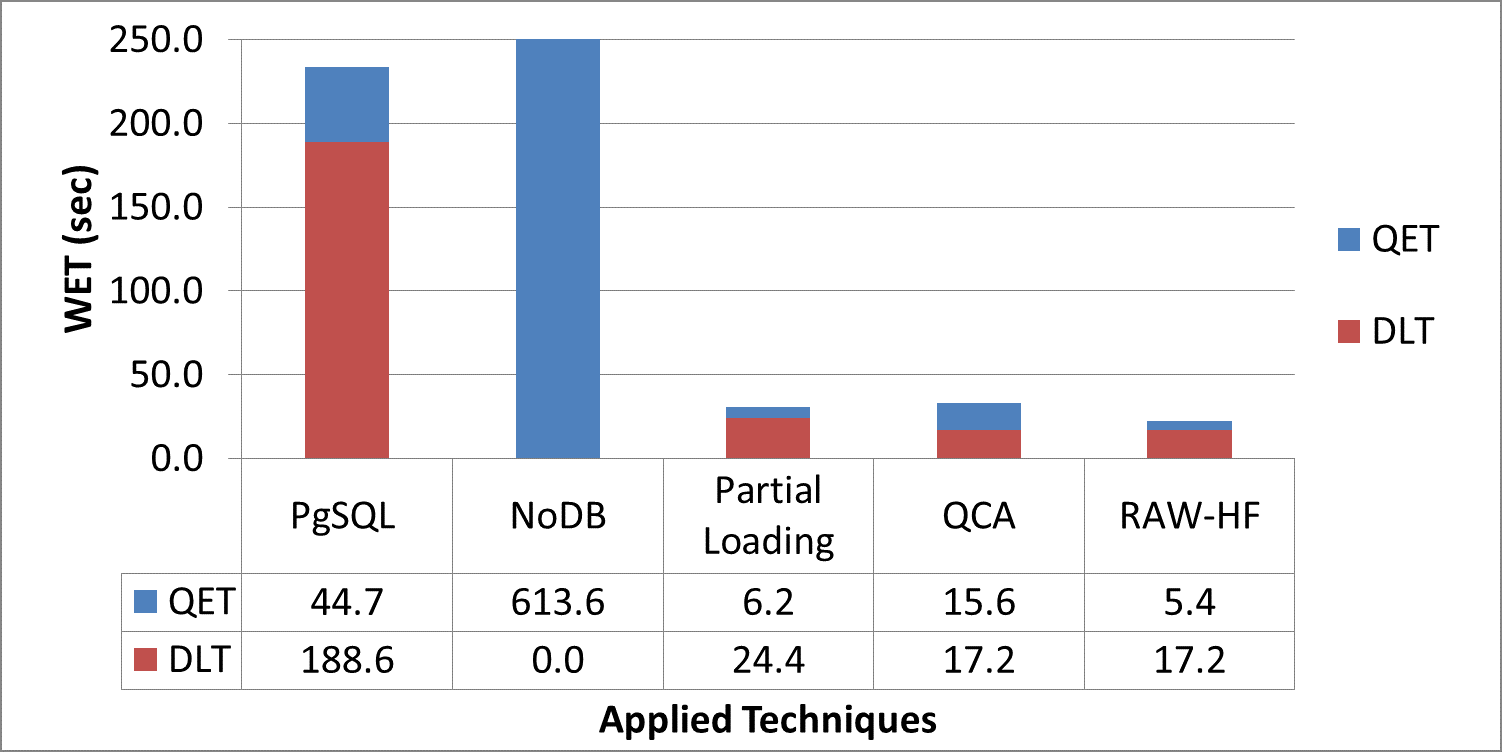
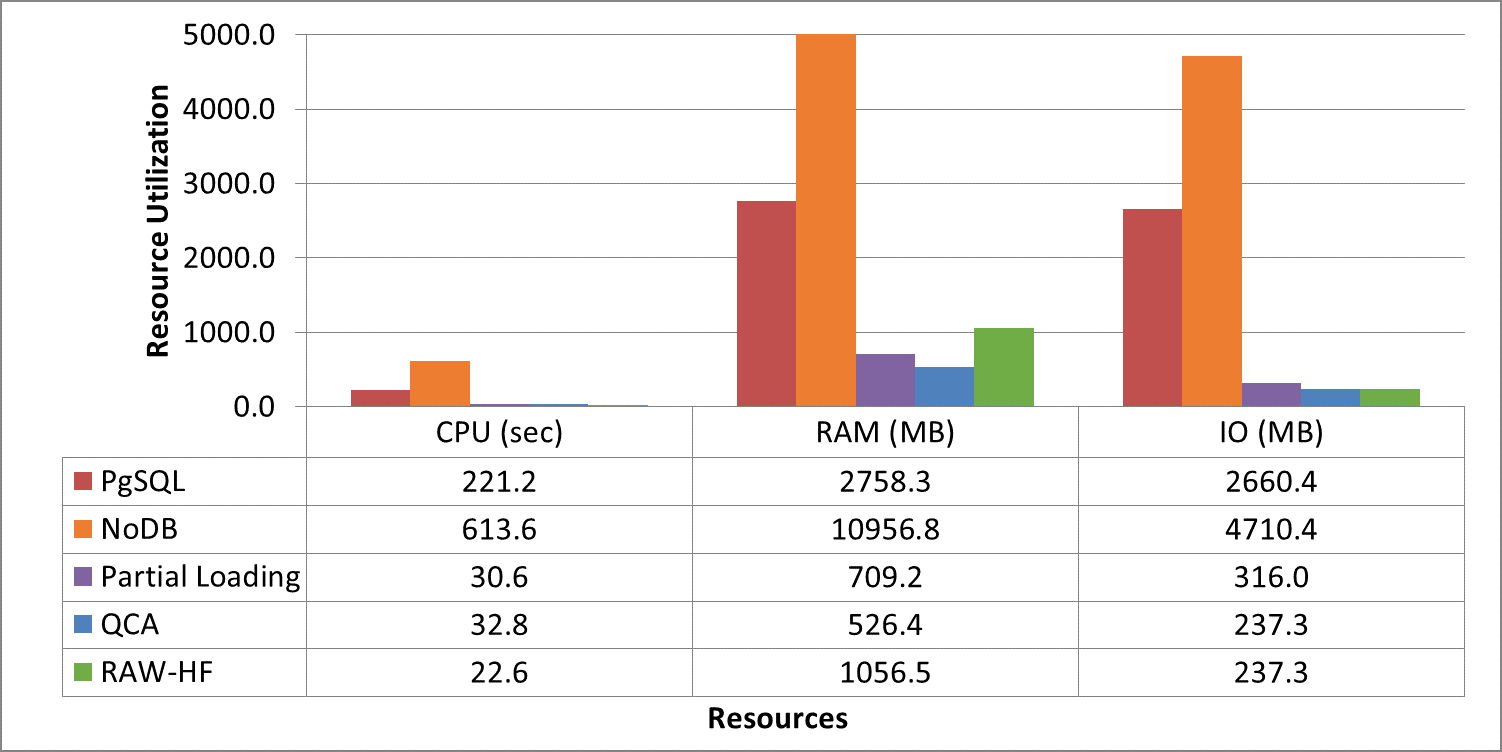
Scientific experiments and modern applications are generating large amounts of data every day. Most organizations utilize In-house servers or Cloud resources to manage application data and workload. The traditional database management system (DBMS) and HTAP systems spend significant time & resources to load the entire dataset into DBMS before starting query execution. On the other hand, in-situ engines may reparse required data multiple times, increasing resource utilization and data processing costs. Additionally, over or under-allocation of resources also increases application running costs. This paper proposes a lightweight Resource Availability &Workload aware Hybrid Framework (RAW-HF) to optimize querying raw data by utilizing existing finite resources efficiently. RAW-HF includes modules that help optimize the resources required to execute a given workload and maximize the utilization of existing resources. The impact of applying RAW-HF to real-world scientific dataset workloads like Sloan Digital Sky Survey (SDSS) and Linked Observation Data (LOD) presented over 90% and 85% reduction in workload execution time (WET) compared to widely used traditional DBMS PostgreSQL. The overall CPU, IO resource utilization, and WET have been reduced by 26%, 25%, and 26%, respectively, while improving memory utilization by 33%, compared to the state-of-the-art workload-aware partial loading technique (WA) proposed for hybrid systems. A comparison of MUAR technique used by RAW-HF with machine learning based resource allocation techniques like PCC is also presented.💡 Deep Analysis
This research explores the key findings and methodology presented in the paper: A Hybrid Heuristic Framework for Resource-Efficient Querying of Scientific Experiments Data.Scientific experiments and modern applications are generating large amounts of data every day. Most organizations utilize In-house servers or Cloud resources to manage application data and workload. The traditional database management system (DBMS) and HTAP systems spend significant time & resources to load the entire dataset into DBMS before starting query execution. On the other hand, in-situ engines may reparse required data multiple times, increasing resource utilization and data processing costs. Additionally, over or under-allocation of resources also increases application running costs. This paper proposes a lightweight Resource Availability &Workload aware Hybrid Framework (RAW-HF) to optimize querying raw data by utilizing existing finite resources efficiently. RAW-HF includes modules that help optimize the resources required to execute a given workload and maximize the utilization of existing resources. The impact of applying RAW-HF to real-world scientific dataset workloads
📄 Full Content
📸 Image Gallery