A Low-Power Sparse Deep Learning Accelerator with Optimized Data Reuse
📝 Original Info
- Title: A Low-Power Sparse Deep Learning Accelerator with Optimized Data Reuse
- ArXiv ID: 2503.19639
- Date: 2025-03-25
- Authors: ** 정보 제공되지 않음 (논문에 저자 정보가 명시되지 않음) **
📝 Abstract
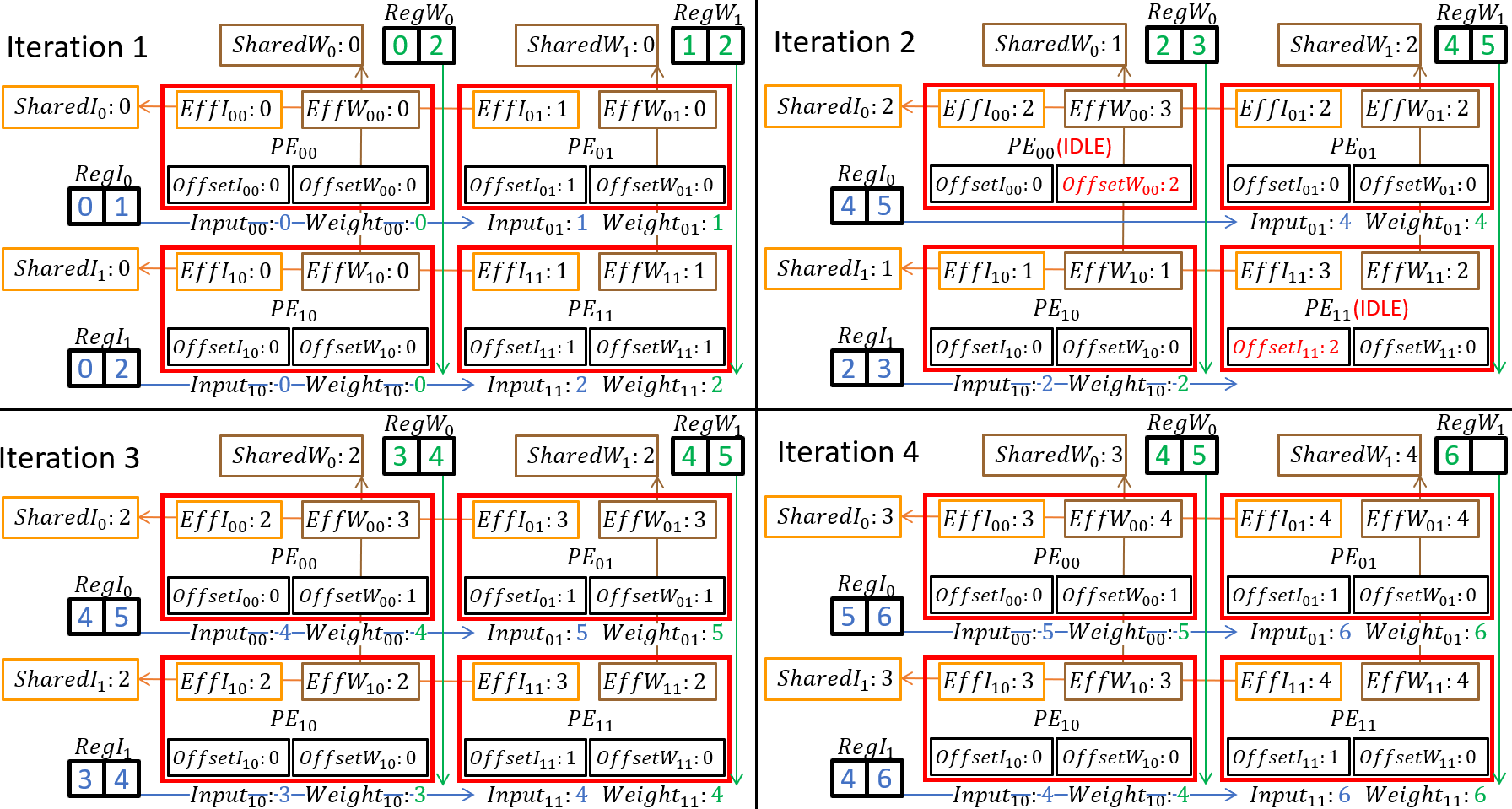
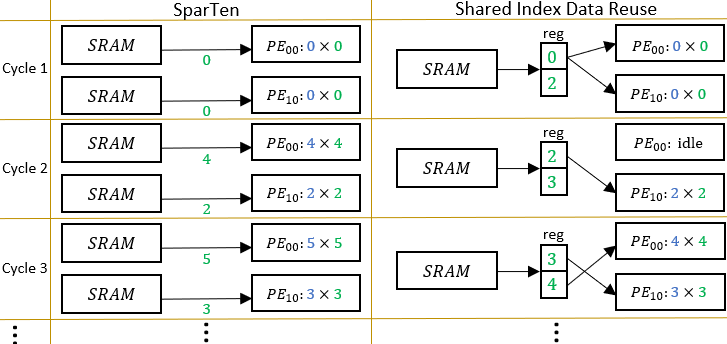
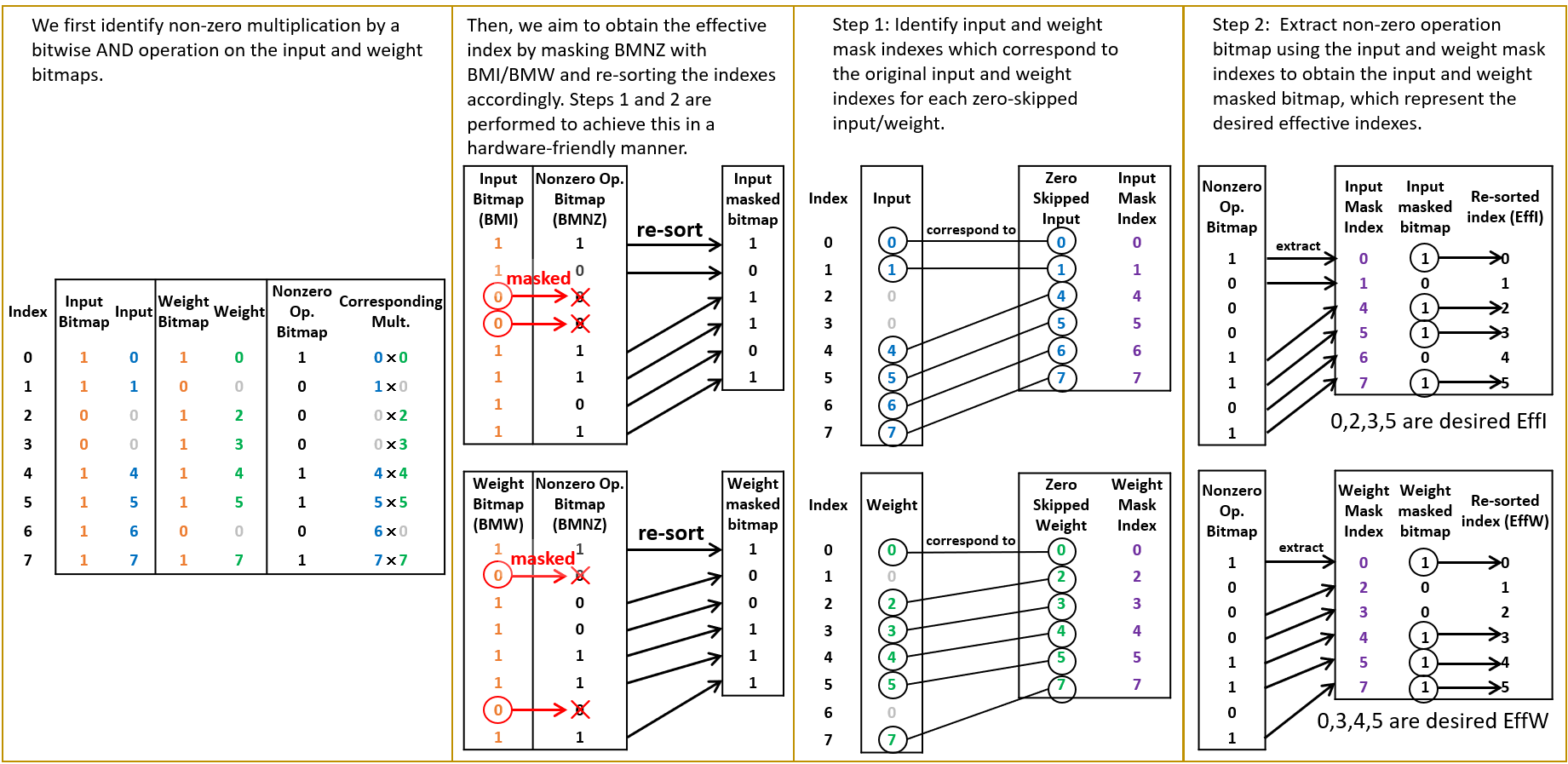
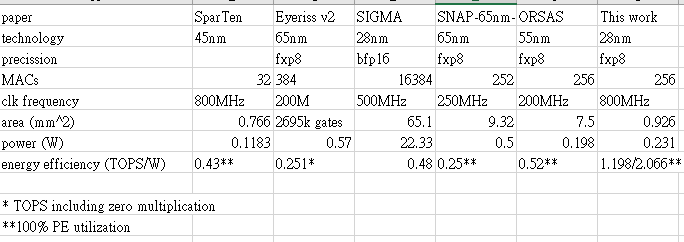
Sparse deep learning has reduced computation significantly, but its irregular non-zero data distribution complicates the data flow and hinders data reuse, increasing on-chip SRAM access and thus power consumption of the chip. This paper addresses the aforementioned issues by maximizing data reuse to reduce SRAM access by two approaches. First, we propose Effective Index Matching (EIM), which efficiently searches and arranges non-zero operations from compressed data. Second, we propose Shared Index Data Reuse (SIDR) which coordinates the operations between Processing Elements (PEs), regularizing their SRAM data access, thereby enabling all data to be reused efficiently. Our approach reduces the access of the SRAM buffer by 86\% when compared to the previous design, SparTen. As a result, our design achieves a 2.5$\times$ improvement in power efficiency compared to state-of-the-art methods while maintaining a simpler dataflow.💡 Deep Analysis
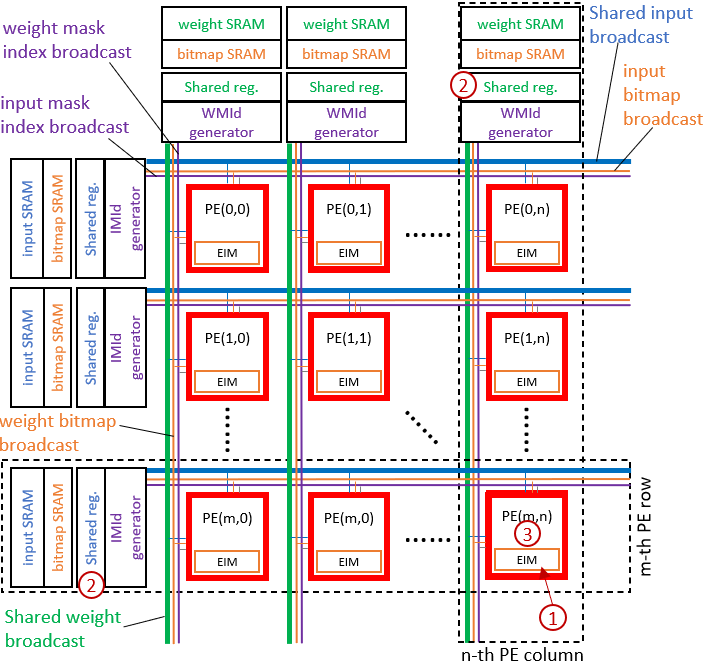
📄 Full Content
📸 Image Gallery

Reference
This content is AI-processed based on open access ArXiv data.