Domain models are central to software engineering, as they enable a shared understanding, guide implementation, and support automated analyses and modeldriven development. Yet, despite these benefits, practitioners often skip modeling because it is time-consuming and demands scarce expertise. We address this barrier by investigating whether open-weight large language models, adapted via instruction tuning, can generate high-quality BPMN process models directly from natural language descriptions in a cost-effective and privacy-preserving way. We introduce InstruBPM, a reproducible approach that prepares paired text-diagram data and instruction tunes an open source large language model with parameter-efficient fine-tuning and quantization for on-prem deployment. We evaluate the tuned model through complementary perspectives: (i) text/code similarity using BLEU, ROUGE-L, and METEOR, (ii) structural fidelity using Relative Graph Edit Distance, (iii) guidelines conformance using external tool checks, and (iv) a small expert review. Using a curated subset of a multidomain BPMN dataset, we compare the tuned model with untuned open-weight baselines and strong proprietary models under consistent prompting regimes. Our compact tuned model outperforms all baselines across sequence and structural metrics while requiring substantially fewer resources; guideline analysis and expert feedback further indicate that the generated diagrams largely follow BPMN best practices and are useful starting points that reduce modeling effort. Overall, instruction tuning improves structural accuracy and robustness compared to untuned baselines and reduces reliance on heavy prompt scaffolding. We publicly share the trained models and scripts to support reproducibility and further research.
💡 Deep Analysis
📄 Full Content
Instruction-Tuning Open-Weight Language Models for
BPMN Model Generation
Gökberk Çelikmasata,∗, Atay Özgövdea, Fatma Başak Aydemirb
aBoğaziçi University, İstanbul, Türkiye
bUtrecht University, Utrecht, The Netherlands
Abstract
Domain models are central to software engineering, as they enable a shared un-
derstanding, guide implementation, and support automated analyses and model-
driven development. Yet, despite these benefits, practitioners often skip model-
ing because it is time-consuming and demands scarce expertise. We address this
barrier by investigating whether open-weight large language models, adapted via
instruction tuning, can generate high-quality BPMN process models directly
from natural language descriptions in a cost-effective and privacy-preserving
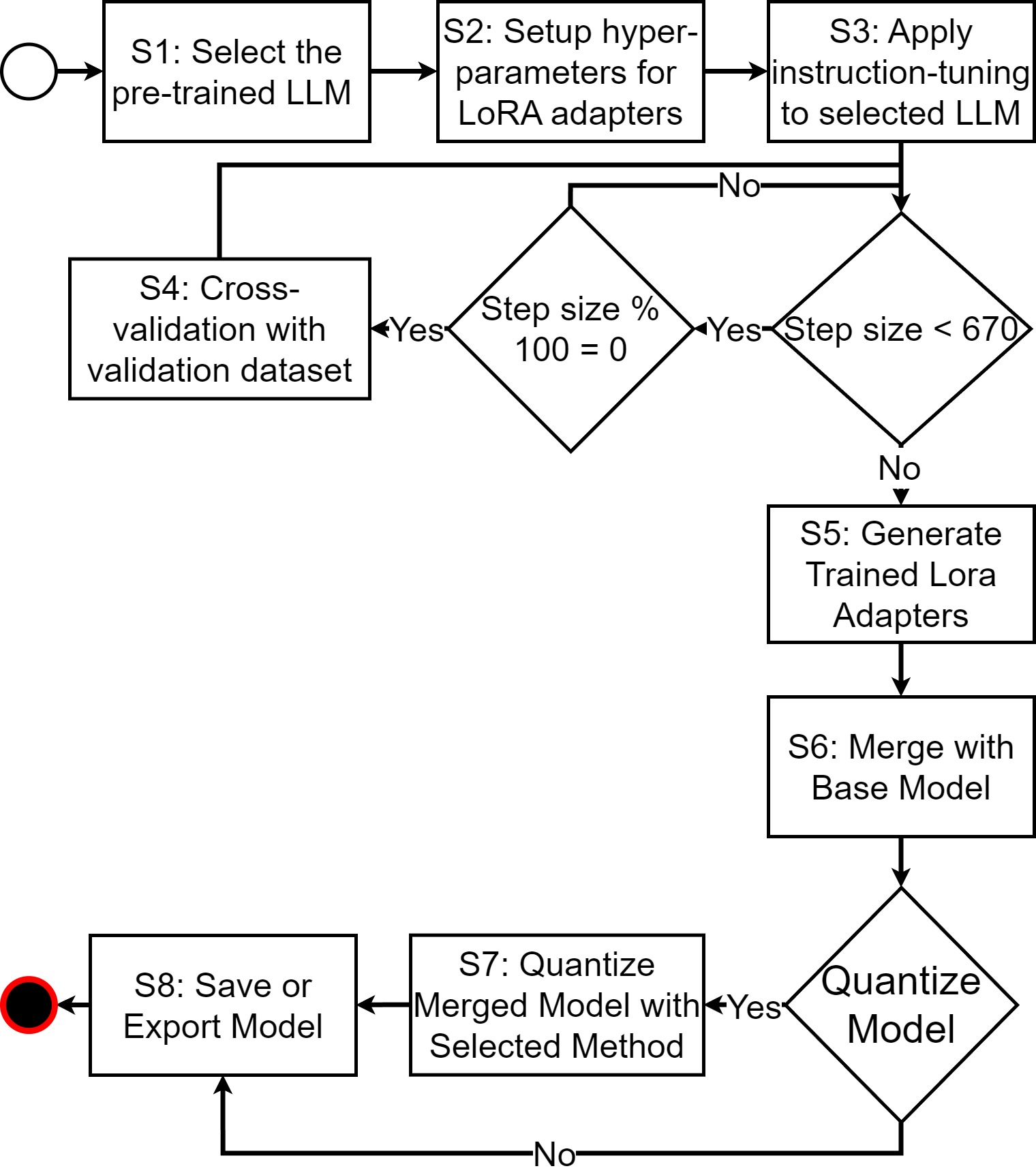
way. We introduce InstruBPM, a reproducible approach that prepares paired
text–diagram data and instruction tunes an open source large language model
with parameter-efficient fine-tuning and quantization for on-prem deployment.
We evaluate the tuned model through complementary perspectives: (i) text/-
code similarity using BLEU, ROUGE-L, and METEOR, (ii) structural fidelity
using Relative Graph Edit Distance, (iii) guidelines conformance using external
tool checks, and (iv) a small expert review. Using a curated subset of a multi-
domain BPMN dataset, we compare the tuned model with untuned open-weight
baselines and strong proprietary models under consistent prompting regimes.
Our compact tuned model outperforms all baselines across sequence and struc-
tural metrics while requiring substantially fewer resources; guideline analysis
and expert feedback further indicate that the generated diagrams largely follow
BPMN best practices and are useful starting points that reduce modeling effort.
Overall, instruction tuning improves structural accuracy and robustness com-
pared to untuned baselines and reduces reliance on heavy prompt scaffolding.
We publicly share the trained models and scripts to support reproducibility and
further research.
Keywords:
business process modeling, model generation, generative AI, large
language models, instruction tuning, parameter-efficient fine-tuning
∗Corresponding author
Email addresses: gokberk.celikmasat@std.bogazici.edu.tr (Gökberk Çelikmasat),
ozgovde@bogazici.edu.tr (Atay Özgövde), f.b.aydemir@uu.nl (Fatma Başak Aydemir)
arXiv:2512.12063v1 [cs.SE] 12 Dec 2025
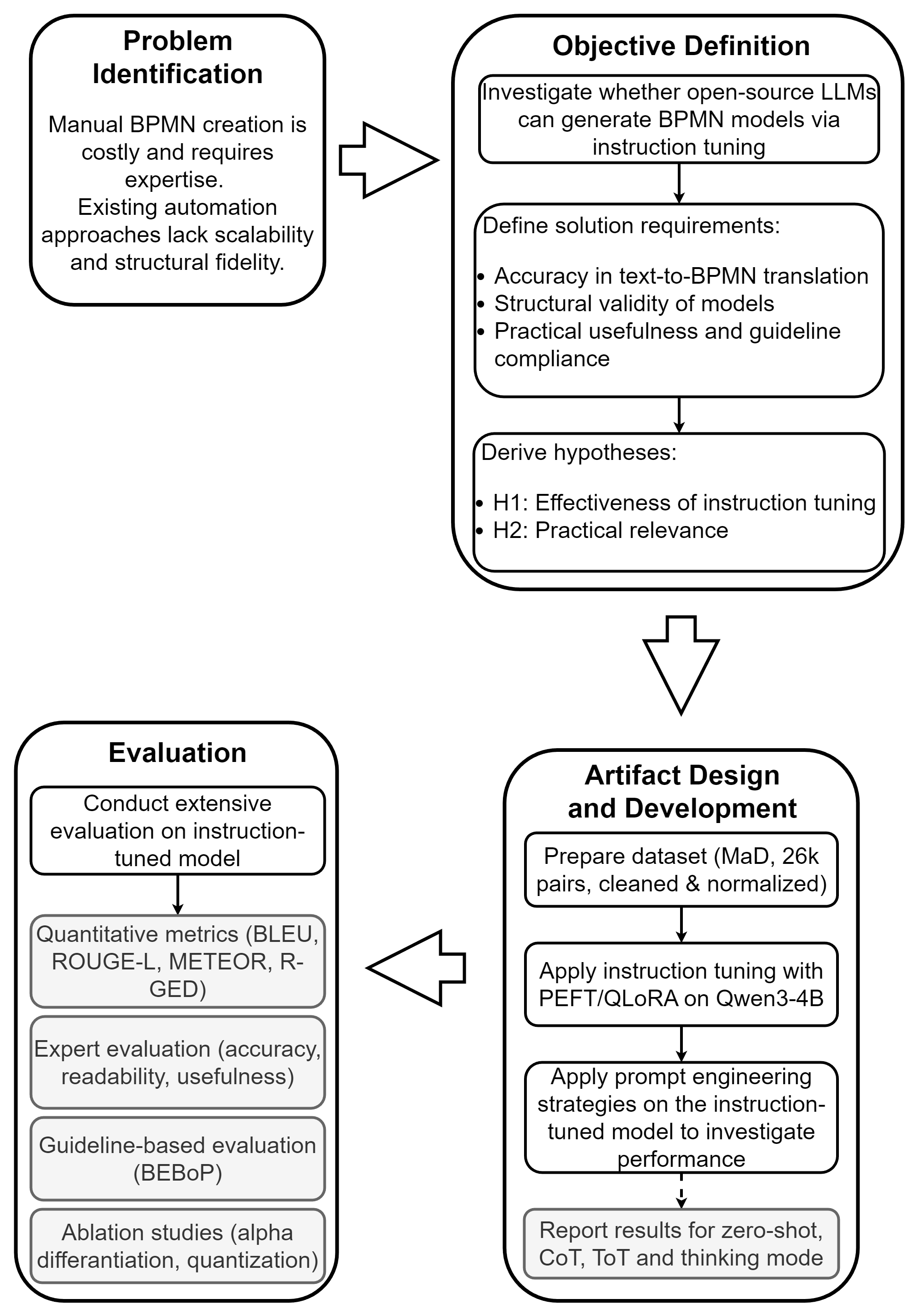
1. Introduction
Domain models capture both the static and dynamic aspects of a system
[1]. They are conceptual representations that capture entities, relationships,
and constraints within a given domain [2]. They serve as an abstraction of the
real world, providing a shared vocabulary among stakeholders and supporting
communication, analysis, and model-driven development practices [3, 4].
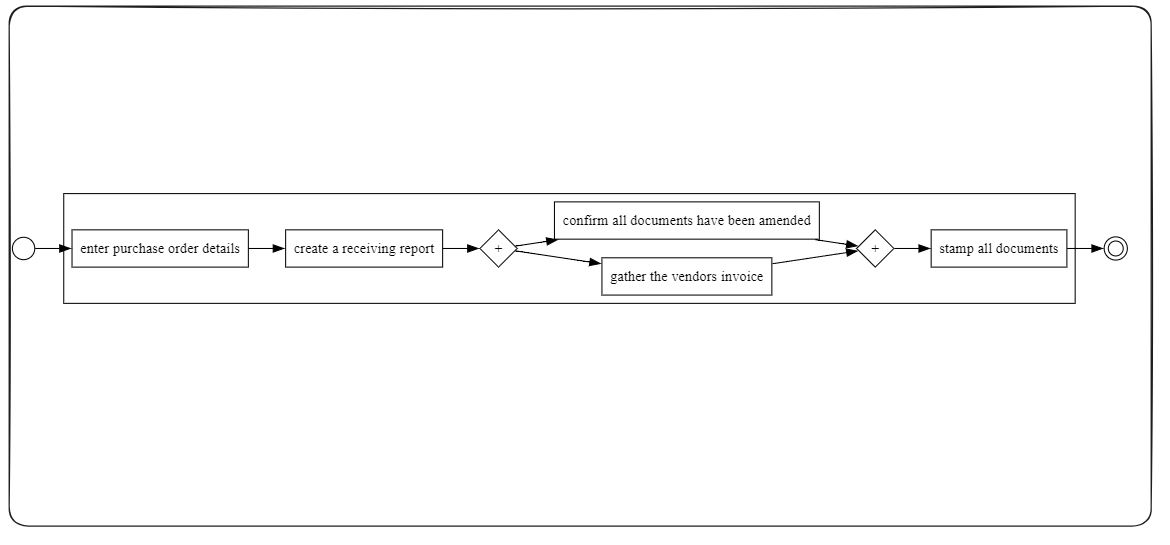
Among the various types of domain models, business process models (BPMs)
are particularly significant because they describe the sequence of tasks, events,
and decisions that define how work is conducted within organizations. BPMs
help organizations understand, optimize, and communicate their workflows,
playing a central role in business process management and digital transforma-
tion initiatives [5].
The Business Process Model and Notation (BPMN) has become the de facto
standard for BPMs due to its expressive power and wide adoption across both
industry and academia [6]. BPMN 2.0 [7] provides a standardized graphical
language for describing processes in a way that is both machine-readable and
understandable to business stakeholders.
Despite these benefits, BPMs are often underutilized in practice because
creating them manually is labor-intensive and requires significant expertise [8].
Existing automation approaches, including rule-based methods, machine learn-
ing (ML) pipelines, and natural language processing (NLP) techniques, offer
partial support but often lack scalability, structural fidelity, or the ability to
generalize across diverse process descriptions [9, 10, 11].
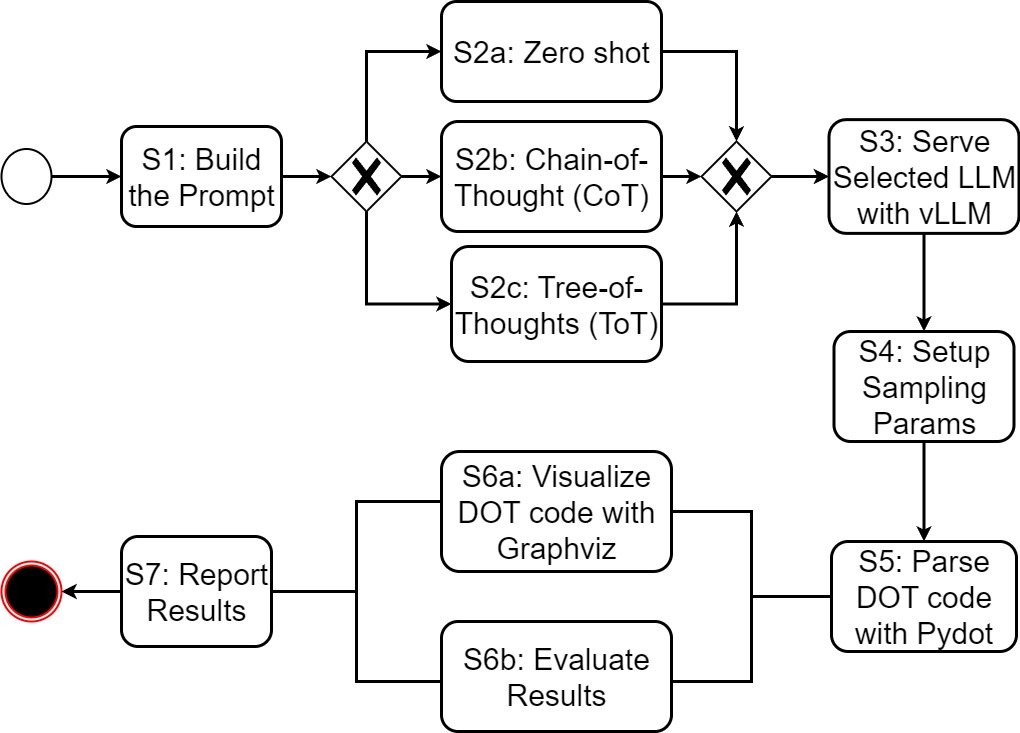
Existing approaches based on generative artificial intelligence apply prompt
engineering techniques such as zero-shot, tree-of-thought (ToT) [12], and chain-
of-thought (CoT) prompting [13] or use thinking capabilities [14] to increase
their generalizability capacities to provide structured outputs with minimal
supervision of large language models (LLMs).
While prompt engineering is
adaptable, it relies on handcrafted instructions and leaves model parameters
unchanged, limiting its capacity to generalize complex patterns without supervi-
sion [15]. Beyond these manual strategies, meta-prompting techniques introduce
task-agnostic scaffolding prompts that orchestrate multiple instances of a model
to decompose tasks, refine intermediate solutions, and improve reasoning with-
out task-specific fine-tuning [16]. Complementary work on automatic prompt
engineering treats prompt design itself as an optimization problem and sur-
veys foundation-model-based, evolutionary, gradient-based, and reinforcement-
learn