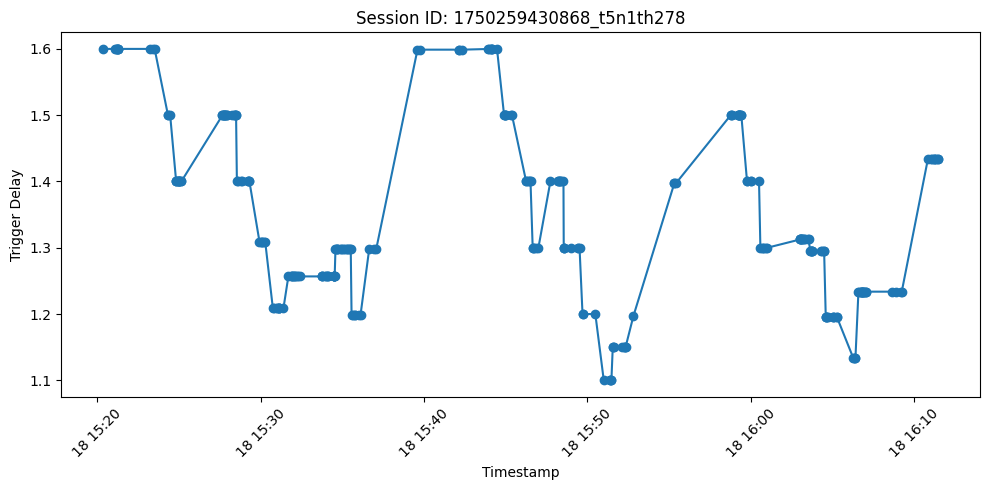
Large Language Models (LLMs) have transformed code auto-completion by generating context-aware suggestions. Yet, deciding when to present these suggestions remains underexplored, often leading to interruptions or wasted inference calls. We propose an adaptive timing mechanism that dynamically adjusts the delay before offering a suggestion based on real-time developer feedback. Our suggested method combines a logistic transform of recent acceptance rates with a bounded delay range, anchored by a high-level binary prediction of the developer's cognitive state. In a two-month deployment with professional developers, our system improved suggestion acceptance from 4.9% with no delay to 15.4% with static delays, and to 18.6% with adaptive timing-while reducing blind rejections (rejections without being read) from 8.3% to 0.36%. Together, these improvements increase acceptance and substantially reduce wasted inference calls by 75%, making LLM-based code assistants more efficient and cost-effective in practice.
Modern software development increasingly relies on AIpowered code assistants-most prominently LLM-based tools such as GitHub Copilot-which leverage massive pre-trained models to suggest context-aware completions and entire code snippets [1], [2]. These systems aim to boost productivity by reducing boilerplate and aiding API recall. Subsequent work on specialized code models (e.g., CodeBERT and CodeT5) has further improved completion accuracy and relevance [3]- [5].
Despite advances in what content to generate, the timing of suggestion delivery remains an underexplored yet critical factor. Immediate, keystroke-triggered suggestions can interrupt a developer’s flow or be ignored outright, while overly delayed prompts risk becoming irrelevant once the context has changed. Mistimed suggestions not only degrade user experience but also waste expensive LLM inference calls.
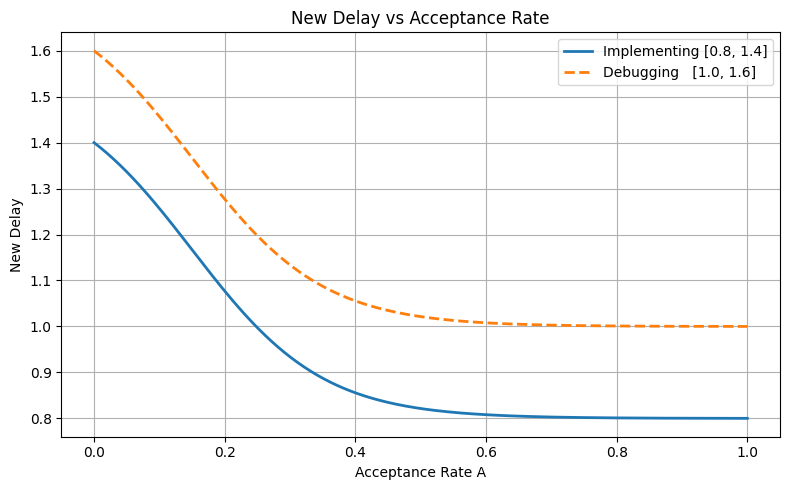
In this paper, we focus squarely on optimizing suggestion timing. We introduce a lightweight, feedback-driven algorithm that modulates delay based on real-time acceptance rates, bounded by a minimal binary prediction of the developer’s cognitive state (implementing vs. debugging). Our contributions are:
• A formal, bounded delay adaptation mechanism using a logistic mapping of acceptance history. • Integration with a cognitive state classifier to anchor timing ranges. • A real-world deployment showing meaningful 3x increases in suggestion acceptance and substantial reductions in wasteful completions. The paper is organized as follows. Section 2 surveys related work on code suggestion models and adaptive human-computer interaction. Section 3 details our adaptive delay method, including the acceptance-rate transform and state anchoring. Section 4 describes the system architecture and experimental design, and Section 5 presents the deployment results with a discussion of efficiency and user experience. Finally, Section 6 concludes and outlines directions for future research.
Recent advances in large language models (LLMs) have significantly improved the accuracy and fluency of code completion systems. Early breakthroughs such as GPT-3 [1] demonstrated the capacity of general-purpose transformers to perform few-shot learning across diverse code-related tasks. This was followed by specialized models like Codex [2], CodeBERT [3], and CodeT5 [4], which introduced inductive biases for programming syntax and identifier structure, yielding improved performance on both generation and understanding benchmarks.
More recently, open-source efforts such as StarCoder [6], Code LLaMA [7], and CodeChain [8] have scaled token context windows, improved multilingual coverage, explored chain-of-thought prompting for complex tasks and domain-adaptive techniques [9]. Recent robustness work also studies adversarial prompt design for LLM completer [10]. While foundational for commercial assistants, these models focus on suggestion content rather than timing or interaction dynamics. Meanwhile, holistic benchmarks such as Complex-CodeEval [11] highlight the need for richer, context-aware assessment of code-oriented LLMs.
Despite these advances, most systems remain limited to static invocation triggers (e.g., after every keystroke or upon user request), overlooking the cognitive and behavioral variability of the developer. Our work focuses on this under explored temporal axis of adaptivity.
The question of when to offer a code suggestion has only recently received attention in the literature. Empirical studies have shown that poorly timed suggestions can introduce cognitive overhead, disrupt developer flow, or even reduce trust in the assistant [12]- [14]. For example, [13] reported that aggressive suggestion timing often leads developers to immediately dismiss completions without reading them-an effect our system explicitly targets via blind rejection reduction. Recent simulation studies such as RepoSim corroborate this observation by replaying realistic typing traces [15].
Cognitive science research has long emphasized the cost of interruptions in high-load tasks, yet most current assistants apply fixed or heuristically determined delays. Recent proposals such as [16] and [17] explore proactive suggestion timing, proposing conceptual frameworks for timing-aware interactions, but do not implement bounded, feedback-driven controllers in real-world systems.
The closest implementation-level work is [18], which proposes a transformer-based classifier to predict opportune moments for suggestion invocation. While promising, their system does not integrate developer feedback into a control loop or deploy in production. We address this gap by deploying a bounded adaptation policy that adjusts timing based on developer state and real-time feedback.
Traditional systems adjusted interface behaviors using explicit or implicit user state, ranging from idle detection to eye-tracking. In the LLM era, adaptivity has largely focused on content generation-e.g., via reinforcement l
This content is AI-processed based on open access ArXiv data.