The security of code generated by large language models (LLMs) is a significant concern, as studies indicate that such code often contains vulnerabilities and lacks essential defensive programming constructs. This work focuses on examining and evaluating the security of LLM-generated code, particularly in the context of C/C++. We categorized known vulnerabilities using the Common Weakness Enumeration (CWE) and, to study their criticality, mapped them to CVEs. We used ten different LLMs for code generation and analyzed the outputs through static analysis. The amount of CWEs present in AI-generated code is concerning. Our findings highlight the need for developers to be cautious when using LLM-generated code. This study provides valuable insights to advance automated code generation and encourage further research in this domain.
In recent years, significant advancements have been observed in the field of Large Language Models (LLMs) and their applications within programming, fundamentally transforming the methodologies used by developers in writing and debugging code [23]. These advanced AI models have experienced rapid evolution, progressing from simple text generation to performing complex tasks such as code synthesis, language translation, and debugging [26]. With each successive iteration, these models not only reduce the time required for development but also enhance the productivity of developers [52]. However, a crucial question persists: Is the code generated by LLMs, secure for applications potentially utilized by millions of users? Can this code be fully trusted?
Considering that LLMs are trained on diverse sources of code, it is uncertain whether all the learned code is secure. This raises the possibility that vulnerabilities present in the training data may reflect in the code produced by LLMs [51]. In this study, we conducted an analysis of the code generated by ten different models to assess its security, particularly in the context of C/C++. Before further discussion, it is necessary to understand the fundamental concepts of security vulnerabilities in software development.
Definition 1.1 (Vulnerability). A vulnerability refers to a code flaw that could expose sensitive information or allow an attacker to exploit the code. Definition 1.2 (Common Weakness Enumeration (CWE)). Common Weakness Enumeration (CWE), is a community-developed list of common software and hardware weaknesses that can lead to vulnerabilities. MITRE Corporation maintains it and serves as a standardized taxonomy for identifying and classifying these weaknesses [50].
Common Vulnerabilities and Exposures (CVE), is a publicly accessible catalog of known security vulnerabilities in software and hardware, used to identify and track these vulnerabilities [36].
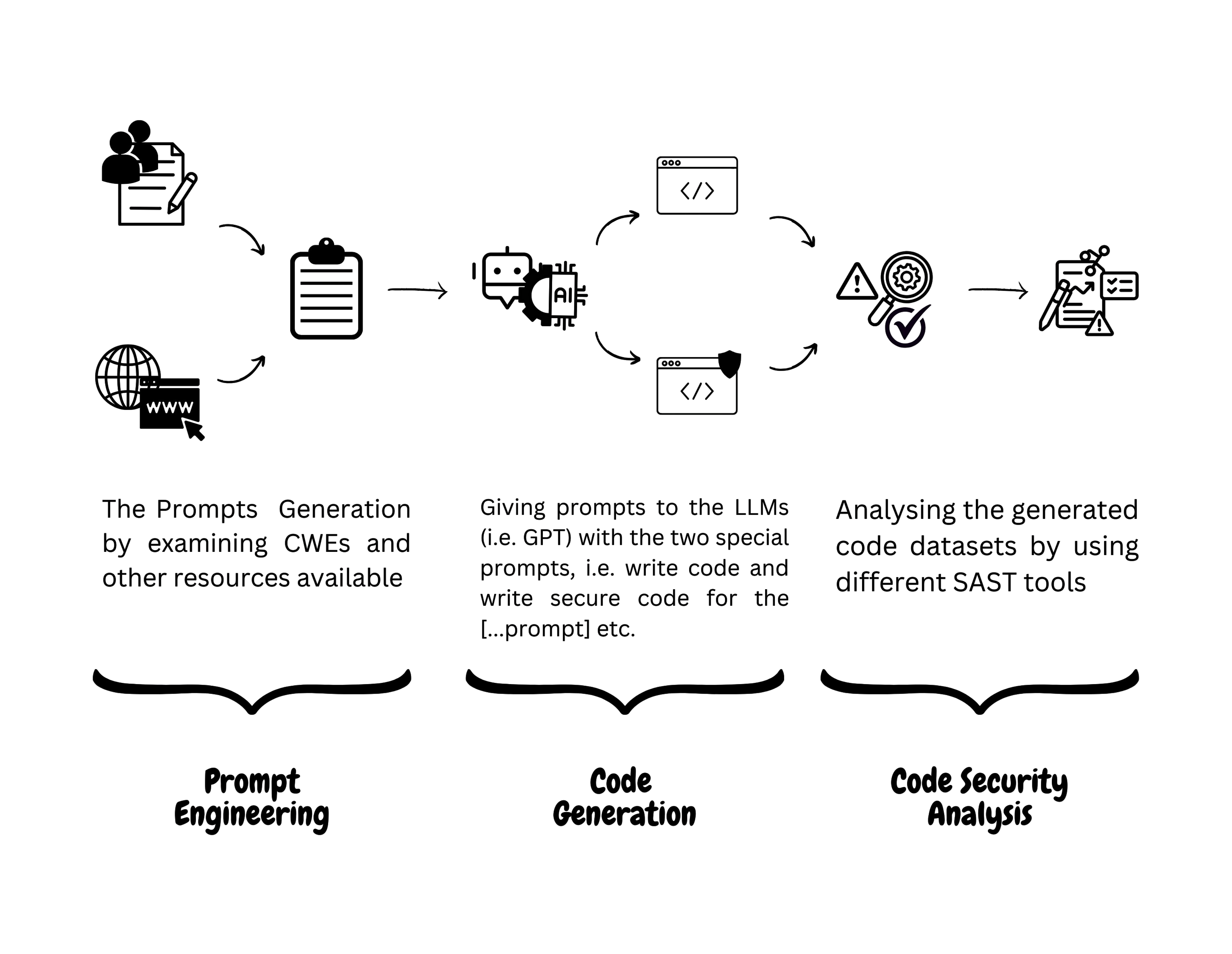
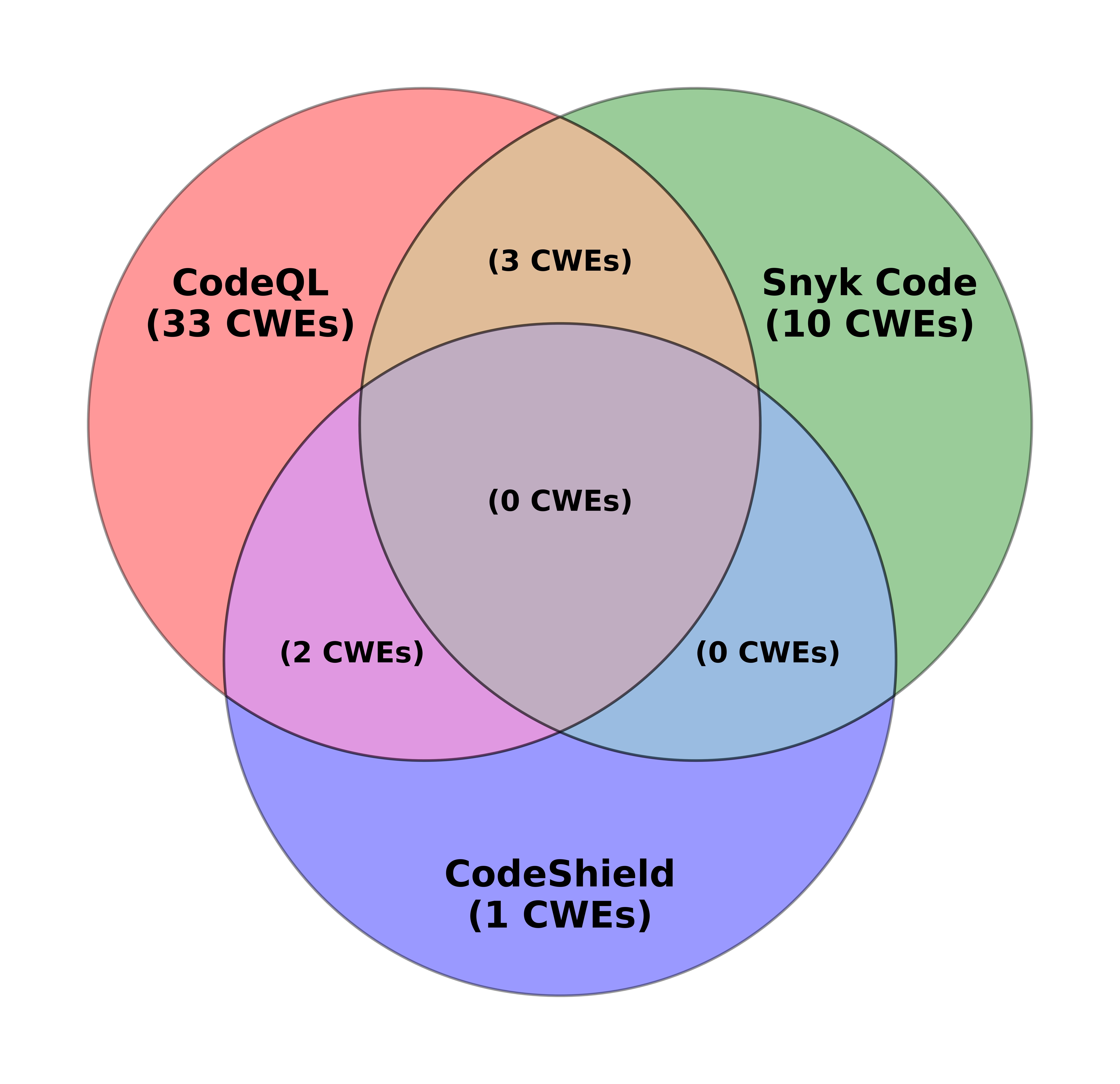
We categorized known vulnerabilities using the Common Weakness Enumeration (CWE). Furthermore, we used the CVE (Common Vulnerability and Exposure) mapping, which provides a catalog of specific real-world incidents associated with these vulnerabilities. For our CWE data, we relied on the MITRE database [34,35], and for CVE mappings, we utilized the National Vulnerability Database (NVD) [37]. To detect these vulnerabilities, we used a technique known as static code analysis. Initially, we generated code from the models and then applied SAST tools such as CodeQL [16] and Snyk Code [49] to perform a static analysis of the generated code. In addition, we utilized CodeShield, an open-source tool developed by Meta as part of the Purple Llama initiative. This tool is specifically designed to detect and filter insecure code outputs from LLMs. This allowed us to identify vulnerabilities and insecure coding practices uniquely associated with code generated by AI models.
This study focuses on examining and evaluating the security of LLM-generated code. By testing code from ten different models in C/C++, utilizing tools designed to identify vulnerabilities, we aim to understand the safety of AI-generated code. Our findings will assist developers in recognizing risks when using LLMs for code generation.
The study makes significant contributions to the field of LLM Generated Code and it’s analysis specifically:
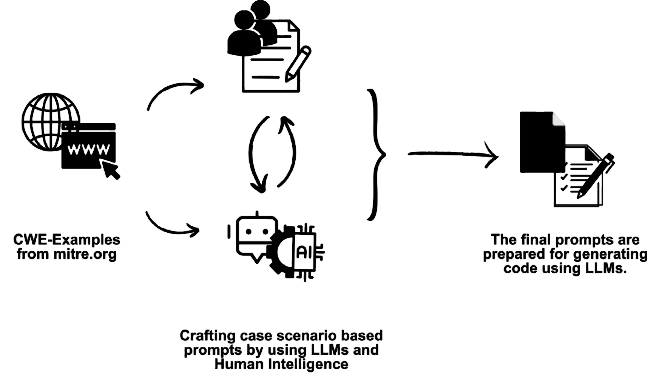
(1) Prompt Dataset Creation: We introduce a novel dataset comprising crafted prompts specifically designed for the generation of code from large language models (LLMs) in C/C++. This dataset can be found on Github [45] and Hugging Face [46].
(2) Code Dataset Development: Our study presents a comprehensive dataset that includes 20 diverse codebases, each generated against 10 different LLMs (with contributions from two codebases per LLM). These datasets are categorized according to whether they were generated by a simple assistant or a secure assistant. This dataset can be found on Github [28] and HuggingFace [29]. (3) Systematic Approach: Our methodology establishes a standardized framework for code generation against a baseline. This involves constructing prompts from established baselines, such as MITRE, and subsequently employing them for code generation, which can be found in Section 3, Research Methodology.
These contributions provide a foundational framework for analyzing the effectiveness, security, and diversity of LLM-generated code, providing valuable insights to advance automated code generation and encouraging further research in this domain.
The security of code generated by large language models (LLMs) is a significant concern, as studies indicate that such code often contains vulnerabilities and lacks essential defensive programming constructs [51]. Recent research has been conducted to assess the security of LLM-generated code and has concluded the security concerns related to LLM-generated code. Research has been done solely around GitHub’s Copilot, where code generated by Copilot
This content is AI-processed based on open access ArXiv data.