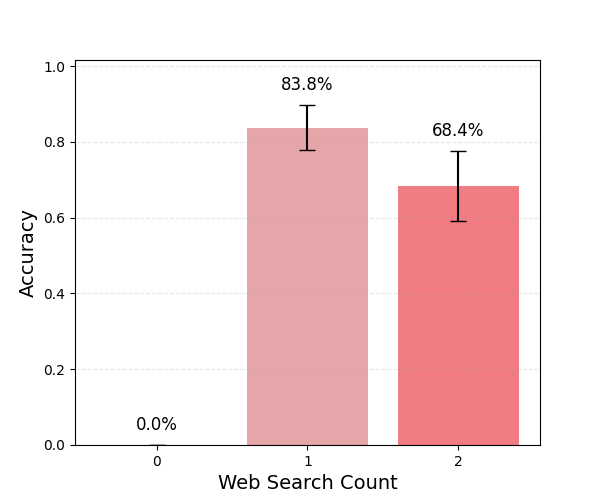
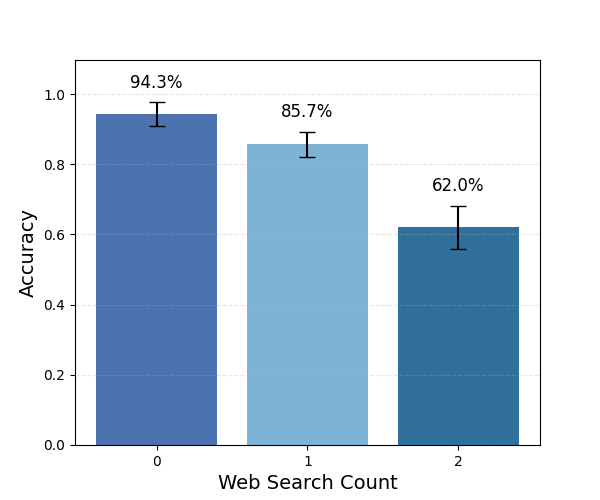
Modern large language models integrate web search to provide realtime answers, yet it remains unclear whether they are efficiently calibrated to use search when it is actually needed. We introduce a benchmark evaluating both the necessity and effectiveness of web access across commercial models with no access to internal states or parameters. The dataset includes a static split of 783 temporally anchored questions answerable from pre-cutoff knowledge, aimed at testing whether models invoke search based on low internal confidence, and a dynamic split of 288 post-cutoff queries designed to test whether models recognise when search is required and retrieve updated information. Web access substantially improves static accuracy for GPT-5-mini and Claude Haiku 4.5, though confidence calibration worsens. On dynamic queries, both models frequently invoke search yet remain below 70 percent accuracy due to weak query formulation. Costs per accuracy-improving call remain low, but returns diminish once initial retrieval fails. Selective invocation helps, but models become overconfident and inconsistent after search. Overall, built-in web search meaningfully improves factual accuracy and can be invoked selectively, yet models remain overconfident, skip retrieval when it is essential, and falter once initial search queries underperform. Taken together, internal web search works better as a good low-latency verification layer than a reliable analytical tool, with clear room for improvement. Our code and dataset will be released publicly. 1
CCS Concepts • Computing methodologies → Information extraction; Language resources.
The rapid growth of Large Language Models (LLMs) has pushed them into a wide range of domains [19,14,16], but their blind spot has remained knowledge about the present [27,32]. Without timely knowledge of events unfolding in real-time, their value in time-sensitive applications has been limited [20,18]. Although pipeline-based external support mechanisms [30,13] and RAG-style scaffolding [24] have resolved real-time context fetching to some extent, the integration of real-time web search tools into the interfaces and APIs of frontier LLMs by OpenAI [23] and Anthropic [3] has fundamentally reshaped the landscape of web-augmented LLMs across multiple applications. By drawing on fresh online sources, newer models can pull in recent context and handle more complex, time-sensitive problems than before. 1 https://anonymous.4open.science/r/look-it-up-0B20/README.md Recent work has explored the capabilities of browsing agents and tool-augmented LLMs, examining which sources they prefer and how reachable those sources are. Yet no exploratory study or benchmark exists to directly test a core research question: "Do LLMs actually know when they should invoke a search tool for current facts rather than defaulting to parametric knowledge, and can they retrieve what they need with minimal expensive web calls?". While similar questions can be studied more directly in opensource models where internal states and parameter-level traces are available, closed-source systems require external measurement and behavioural analysis to infer invocation strategy. We therefore focus on widely deployed commercial models from OpenAI and Anthropic, both because they are commonly used in real-world applications and because their web search capabilities warrant empirical evaluation before being deployed reliably. Our approach offers an exploratory, externally-grounded assessment using targeted data rather than internal instrumentation.
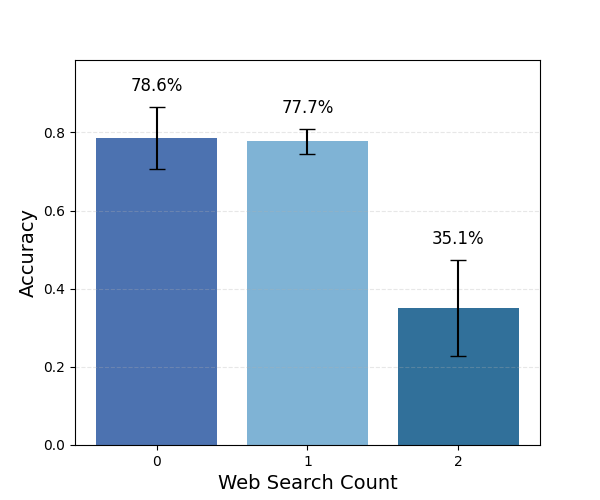
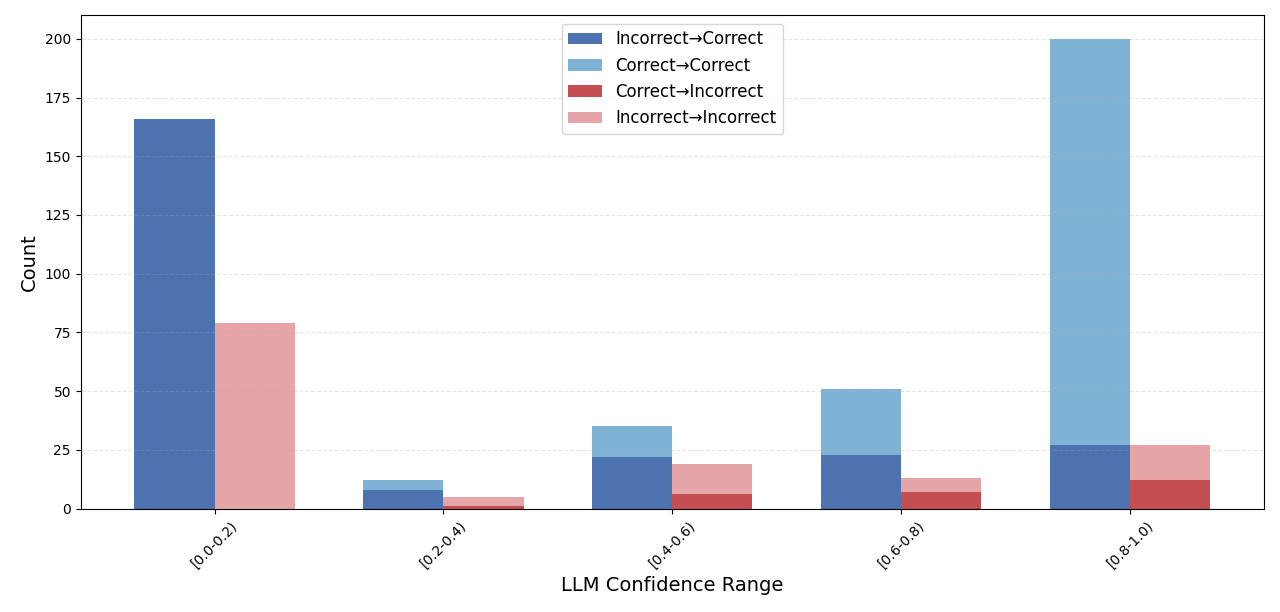
Frontier models from OpenAI and Anthropic now ship with builtin search capabilities called web search tools, and both note that models “use internal reasoning capabilities to determine whether the web search tool would help provide a more accurate response” [23,3]. In practice, we expect this internal reasoning to depend on two signals: low internal confidence in a factual claim [31] and the recognition that a query refers to information beyond the model’s training cut-off [7]. There is no standardised evaluation focused on closed-source settings that measures how reliably or precisely LLMs use internal web search tools to boost accuracy or other performance metrics. This leaves a central capability essentially untested.
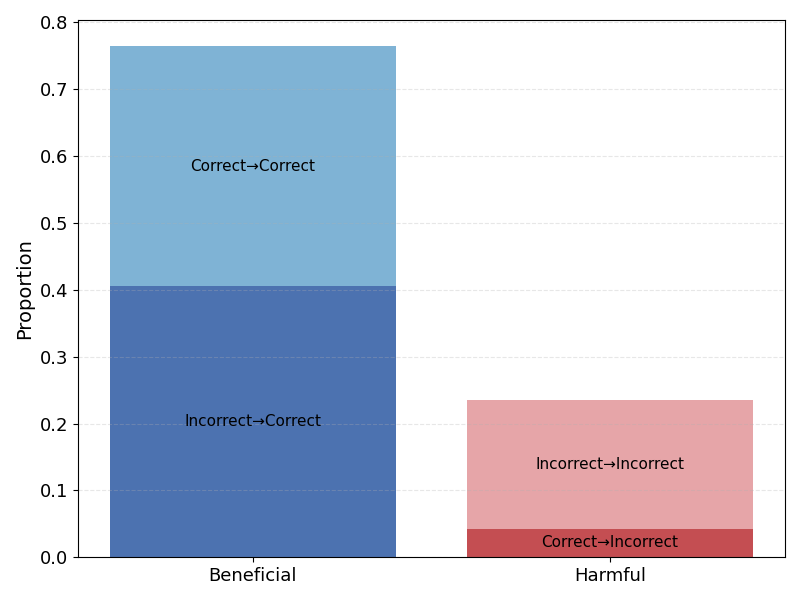
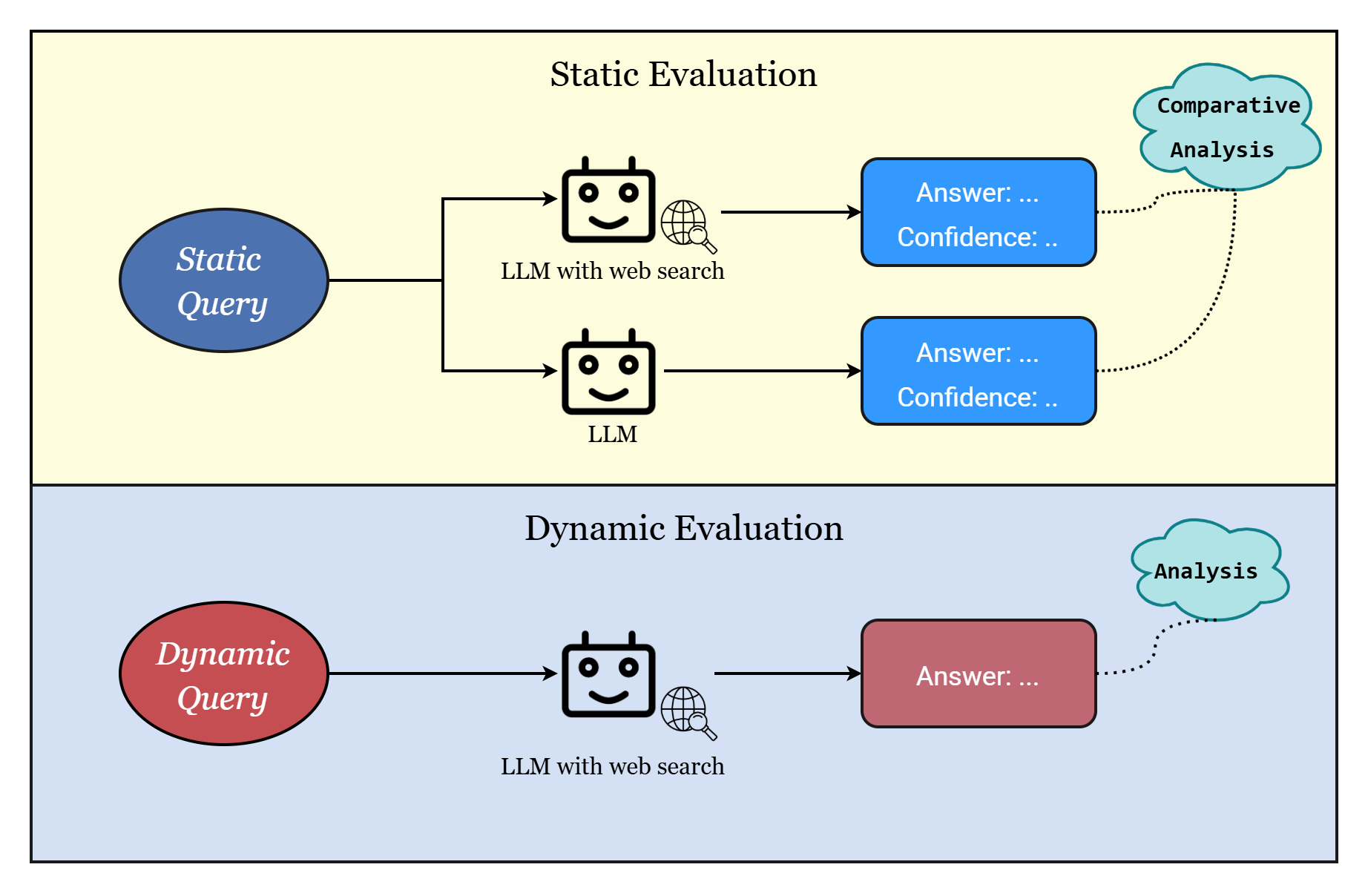
To address this gap, we introduce a benchmark to provide an exploratory analysis of evaluating the quality and the necessity of web search for LLMs when answering simple factual questions. The benchmark is divided into a static and a dynamic part. The static part enables a clean comparison of models with and without web search, and tests how their factual confidence influences the decision to use web search. It contains questions about fixed facts from before each model’s knowledge cut-off, allowing a controlled assessment of accuracy gains, cost-accuracy trade-off and confidence calibration [25]. The dynamic part provides a stand-alone evaluation of web search capability and precision, using time-sensitive questions framed with terms such as “currently” and “present” to test how these cues shape a model’s decision to call the tool [8].
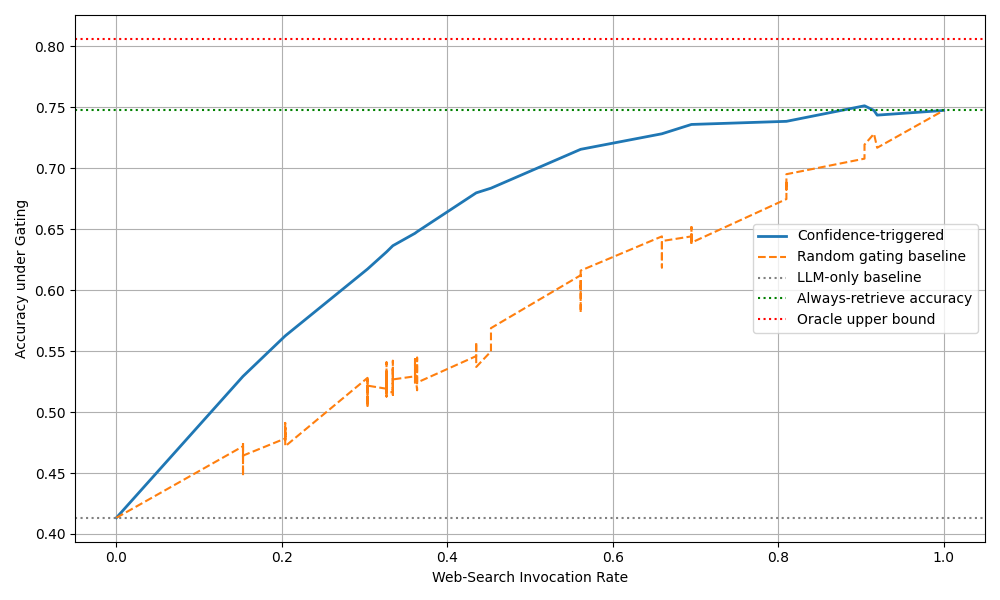
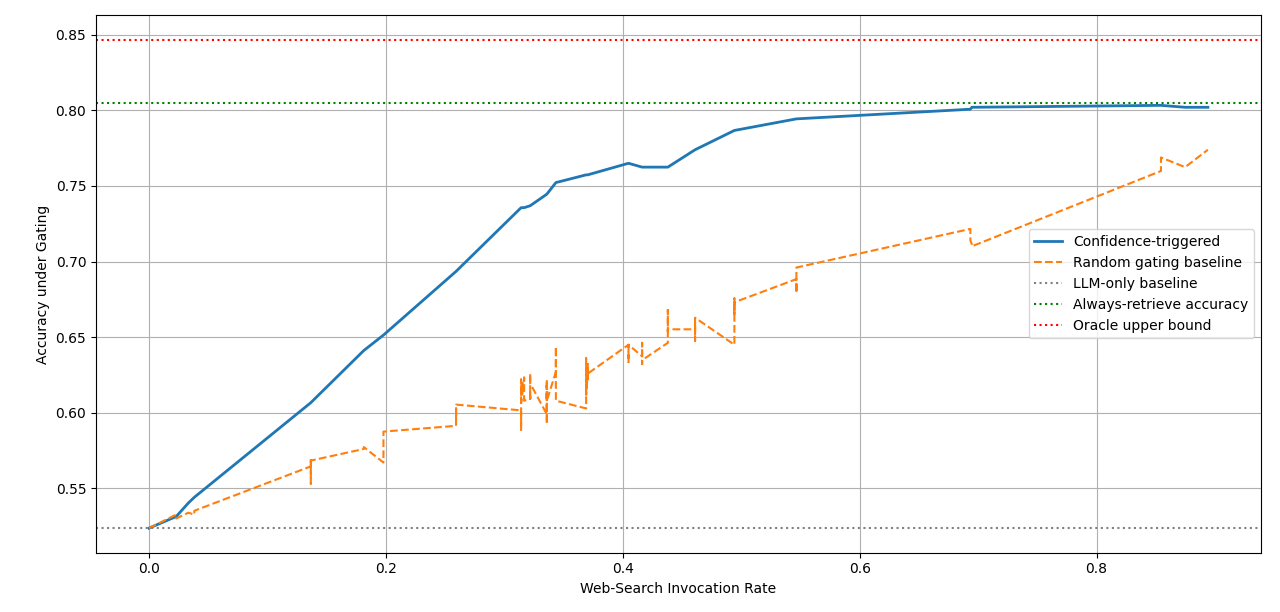
Here we evaluate whether models execute searches efficiently and how much accuracy they gain for the cost incurred.
Overall, the paper offers a focused and systematic way to extrinsically measure how effectively modern LLMs use in-built web search capabilities without accessing internal parameters or configuration. The main contributions of our work can be summarised as follows:
• We introduce a benchmark that can explore how well calibrated frontier LLMs are in their use of web search, without relying on internal configuration details • We analyse LLMs’ web search capabilities through a comparative evaluation of the benefits and cost with and without web search, as well as a stand-alone assessment of calibration in search-enabled settings • We offer deployment-oriented guidance on best uses for inbuilt web search and selective invocation strategies, mapping model behaviour and cost-accuracy dynamics to concrete application scenarios
While past work has assessed agent competence (browsing, navigation, tool use) or safety, our contribution lies in evaluating the decision-making mechanism behind search invocation and its efficiency in closed-source yet widely used models from an external perspective.
Recent methods have embedded web access into LLMs to mitigate reliance on stale parametric knowledge, enabling retrievalaugmented, browser-like capabilities with AI integration, such as RaDA [17] and DeepResearcher [36]. Similarly, several benchmarks have bee
This content is AI-processed based on open access ArXiv data.