Title: MambaTAD: When State-Space Models Meet Long-Range Temporal Action Detection
ArXiv ID: 2511.17929
Date: 2021-08-01
Authors: : Hui Lu, Yi Yu, Shijian Lu, Deepu Rajan, Boon Poh Ng, Alex C. Kot, Xudong Jiang
📝 Abstract
Temporal Action Detection (TAD) aims to identify and localize actions by determining their starting and ending frames within untrimmed videos. Recent Structured State-Space Models such as Mamba have demonstrated potential in TAD due to their long-range modeling capability and linear computational complexity. On the other hand, structured state-space models often face two key challenges in TAD, namely, decay of temporal context due to recursive processing and self-element conflict during global visual context modeling, which become more severe while handling long-span action instances. Additionally, traditional methods for TAD struggle with detecting long-span action instances due to a lack of global awareness and inefficient detection heads. This paper presents MambaTAD, a new state-space TAD model that introduces long-range modeling and global feature detection capabilities for accurate temporal action detection. MambaTAD comprises two novel designs that complement each other with superior TAD performance. First, it introduces a Diagonal-Masked Bidirectional State-Space (DMBSS) module which effectively facilitates global feature fusion and temporal action detection. Second, it introduces a global feature fusion head that refines the detection progressively with multi-granularity features and global awareness. In addition, MambaTAD tackles TAD in an end-to-end one-stage manner using a new state-space temporal adapter(SSTA) which reduces network parameters and computation cost with linear complexity. Extensive experiments show that MambaTAD achieves superior TAD performance consistently across multiple public benchmarks.
💡 Deep Analysis
📄 Full Content
JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021
1
MambaTAD: When State-Space Models Meet
Long-Range Temporal Action Detection
Hui Lu, Yi Yu, Shijian Lu, Deepu Rajan, Member, IEEE, Boon Poh Ng, Alex C. Kot, Life Fellow, IEEE,
Xudong Jiang, Fellow, IEEE
Abstract—Temporal Action Detection (TAD) aims to identify
and localize actions by determining their starting and ending
frames within untrimmed videos. Recent Structured State-Space
Models such as Mamba have demonstrated potential in TAD due
to their long-range modeling capability and linear computational
complexity. On the other hand, structured state-space models
often face two key challenges in TAD, namely, decay of temporal
context due to recursive processing and self-element conflict
during global visual context modeling, which become more
severe while handling long-span action instances. Additionally,
traditional methods for TAD struggle with detecting long-span
action instances due to a lack of global awareness and inefficient
detection heads. This paper presents MambaTAD, a new state-
space TAD model that introduces long-range modeling and global
feature detection capabilities for accurate temporal action detec-
tion. MambaTAD comprises two novel designs that complement
each other with superior TAD performance. First, it introduces
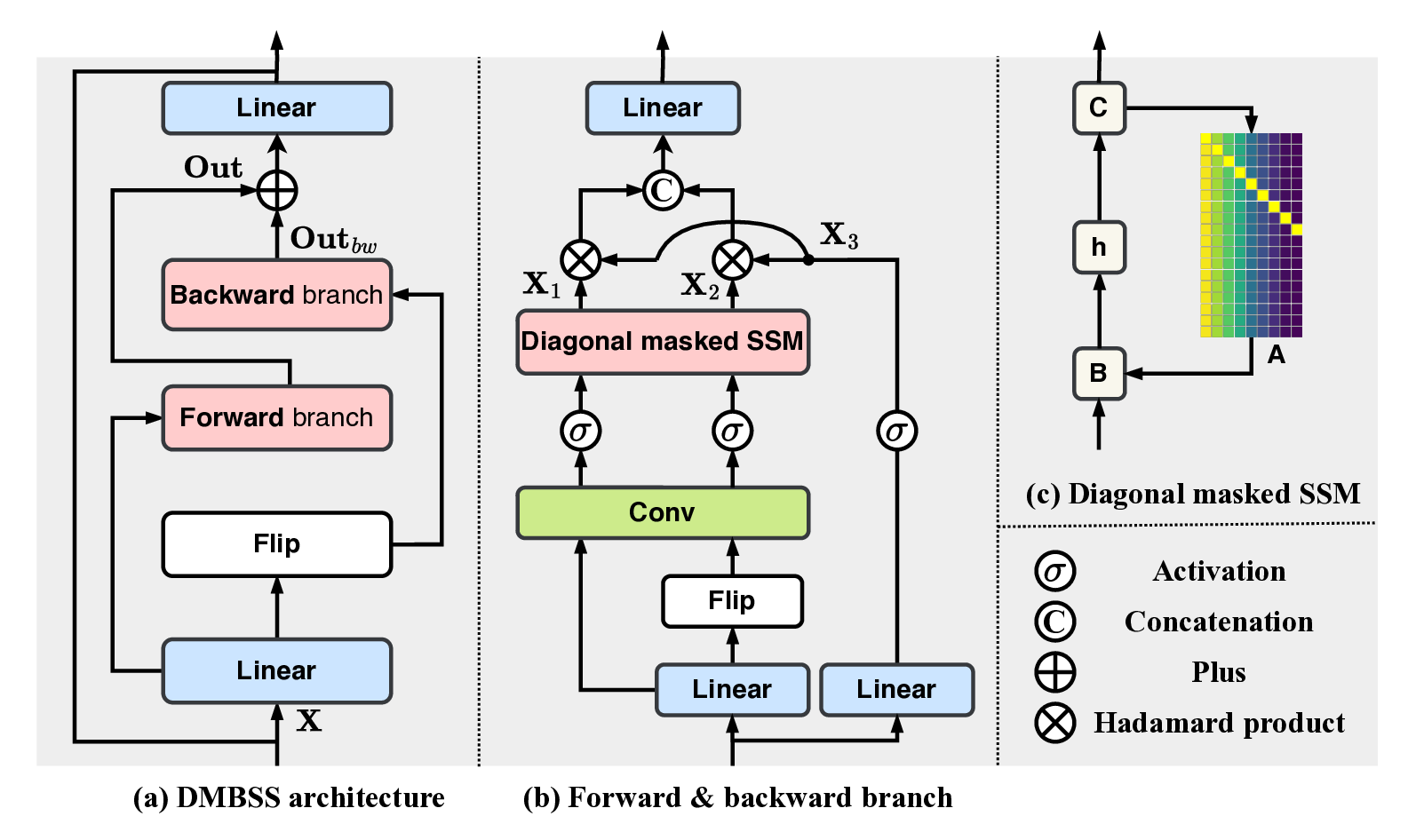
a Diagonal-Masked Bidirectional State-Space (DMBSS) module
which effectively facilitates global feature fusion and temporal ac-
tion detection. Second, it introduces a global feature fusion head
that refines the detection progressively with multi-granularity
features and global awareness. In addition, MambaTAD tackles
TAD in an end-to-end one-stage manner using a new state-space
temporal adapter(SSTA) which reduces network parameters and
computation cost with linear complexity. Extensive experiments
show that MambaTAD achieves superior TAD performance
consistently across multiple public benchmarks.
Index Terms—temporal action detection, state-space models,
end-to-end temporal action detection.
I. INTRODUCTION
T
Emporal action detection (TAD) aims to detect specific
action categories and extract corresponding temporal
spans in untrimmed videos. It is a long-standing and chal-
lenging problem in video understanding with extensive real-
world applications such as sports analysis, surveillance and
security. The development of deep neural networks such as
CNNs [1], [2] and Transformers [3], [4] has led to continuous
advancements in TAD performance over the past few years.
However, CNNs have limited capabilities in capturing long-
range dependencies, while Transformers face challenges with
computational complexity and feature discrimination [1].
Recently, Structured State-Space Sequence models (S4) [5]
such as Mamba [6] have demonstrated great efficiency
Hui Lu and Yi Yu are with the Rapid-Rich Object Search Lab, Interdisci-
plinary Graduate Programme, Nanyang Technological University, Singapore,
(e-mail: {hui007, yuyi0010}@e.ntu.edu.sg).
Shijian Lu and Deepu Rajan are with the College of Computing and Data
Science, Nanyang Technological University, Singapore, (e-mail: {shijian.Lu,
asdrajan}@ntu.edu.sg).
Boon Poh Ng, Alex C. Kot, and Xudong Jiang are with the School of
Electrical and Electronic Engineering, Nanyang Technological University,
Singapore, (e-mail: {ebpng, eackot, exdjiang}@ntu.edu.sg).
50
55
60
65
70
75
80
ActionFormer
Tridet
DyFADet
MambaTAD
Avg. mAPN (%)
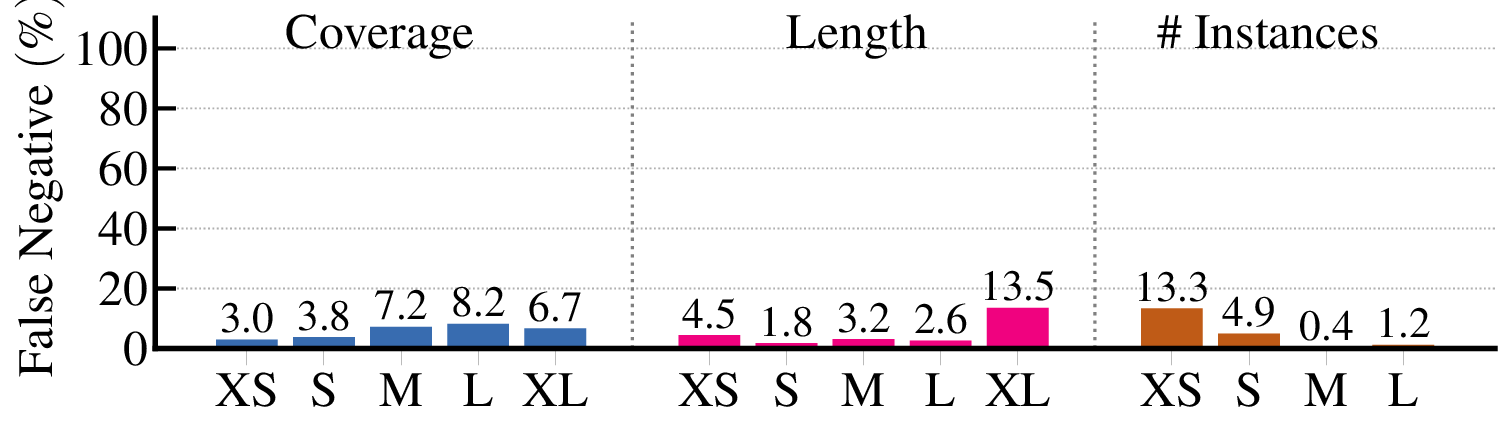
Coverage
Length
Average
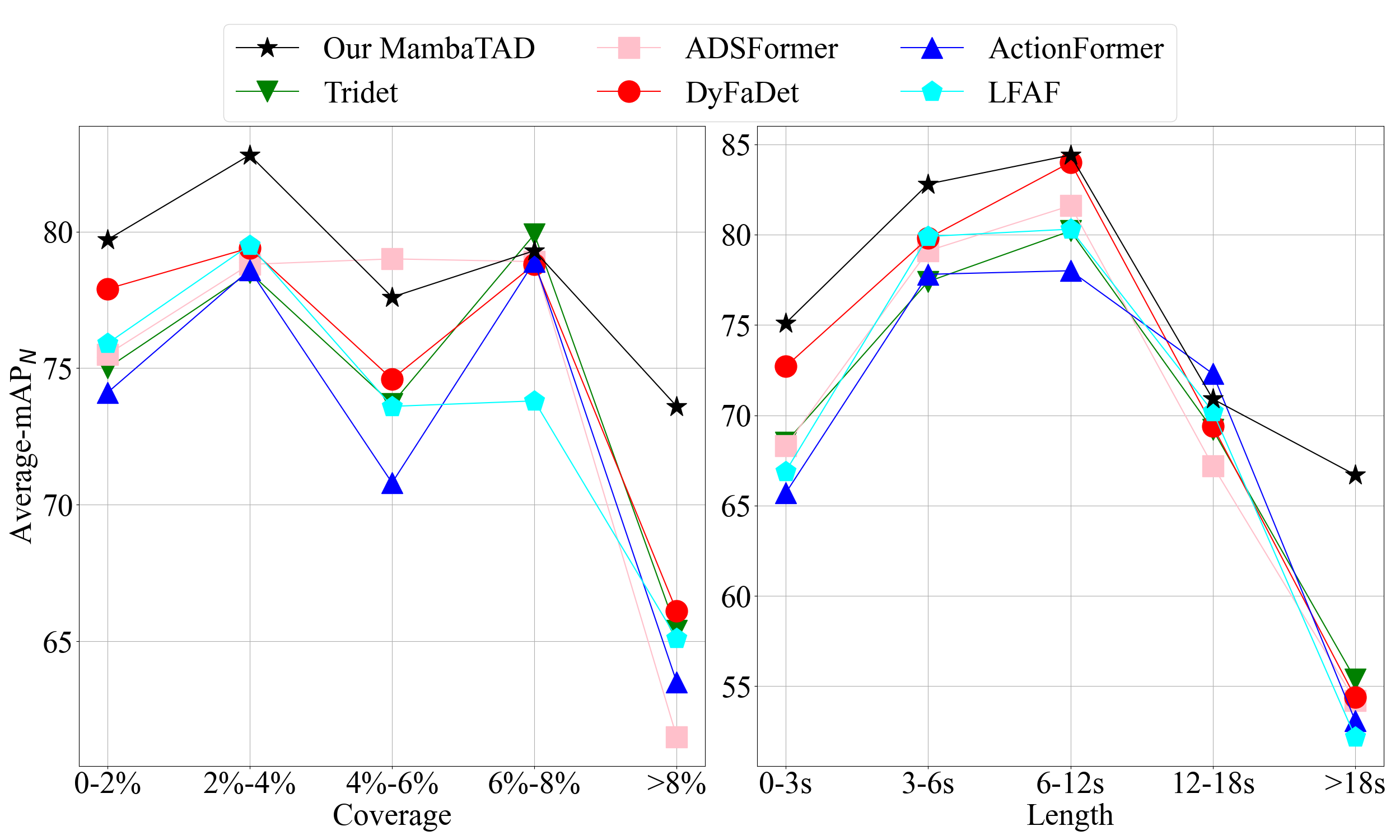
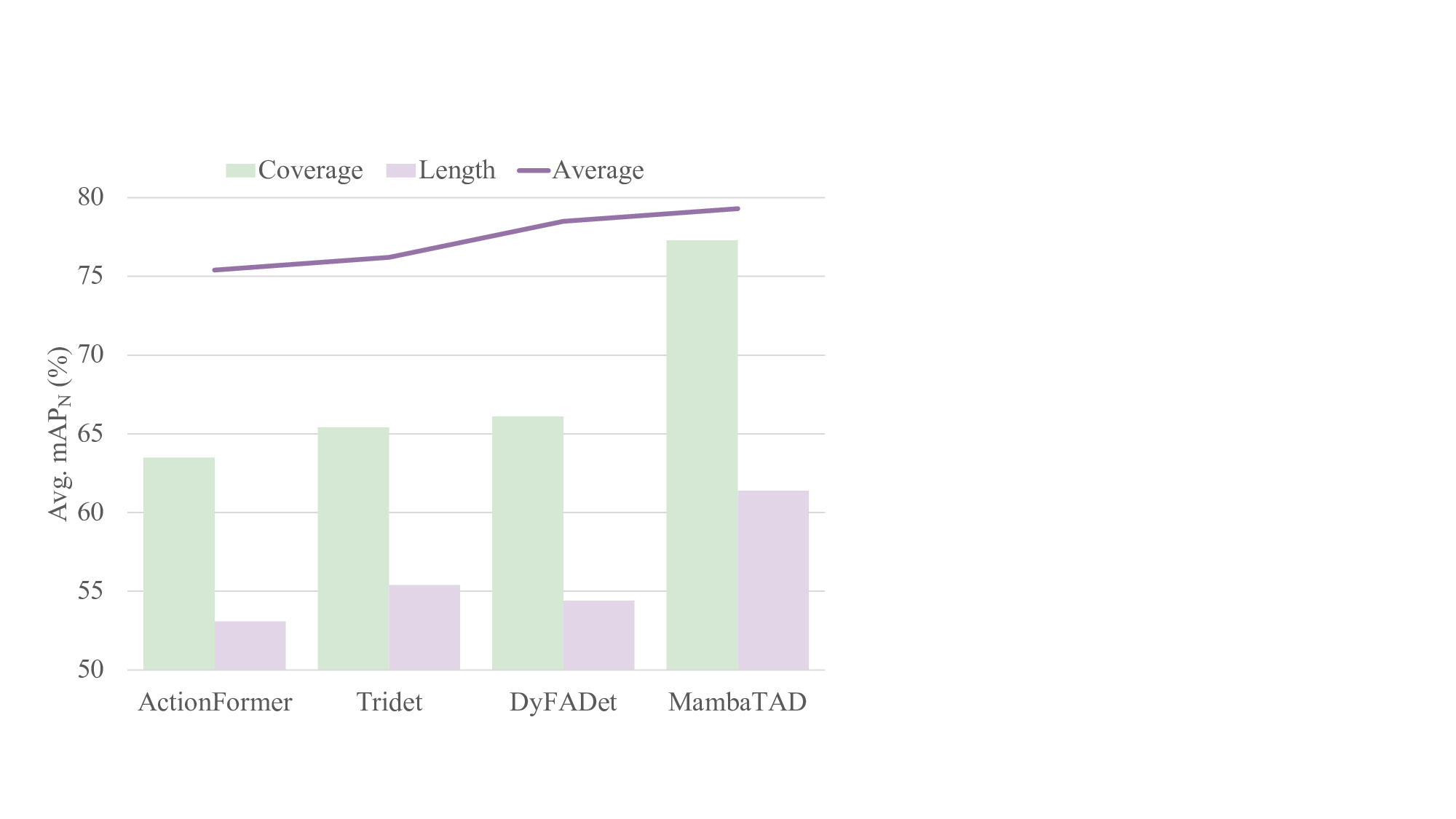
Fig. 1.
Comparison of TAD methods: Prior studies suffer from decay of
temporal information and self-element conflict, which often struggle while
facing long-span action instances. The proposed MambaTAD can handle long-
span action instances effectively with its long-range modeling and global
feature fusion capabilities. The Coverage and Length are two metrics for
identifying long action instances according to their proportion with respect to
the whole videos ([0.08,1]) and the absolute action length ([18,∞] seconds),
respectively. The Average means the normalized average mAP over all action
instances of various lengths in the dataset.
and effectiveness in deep network construction [7], [8].
These models, enhanced by specially designed structured re-
parameterization [9] and selective scan mechanisms, facilitate
the natural activation of extended temporal moments, thereby
improving classification and boundary regression performance.
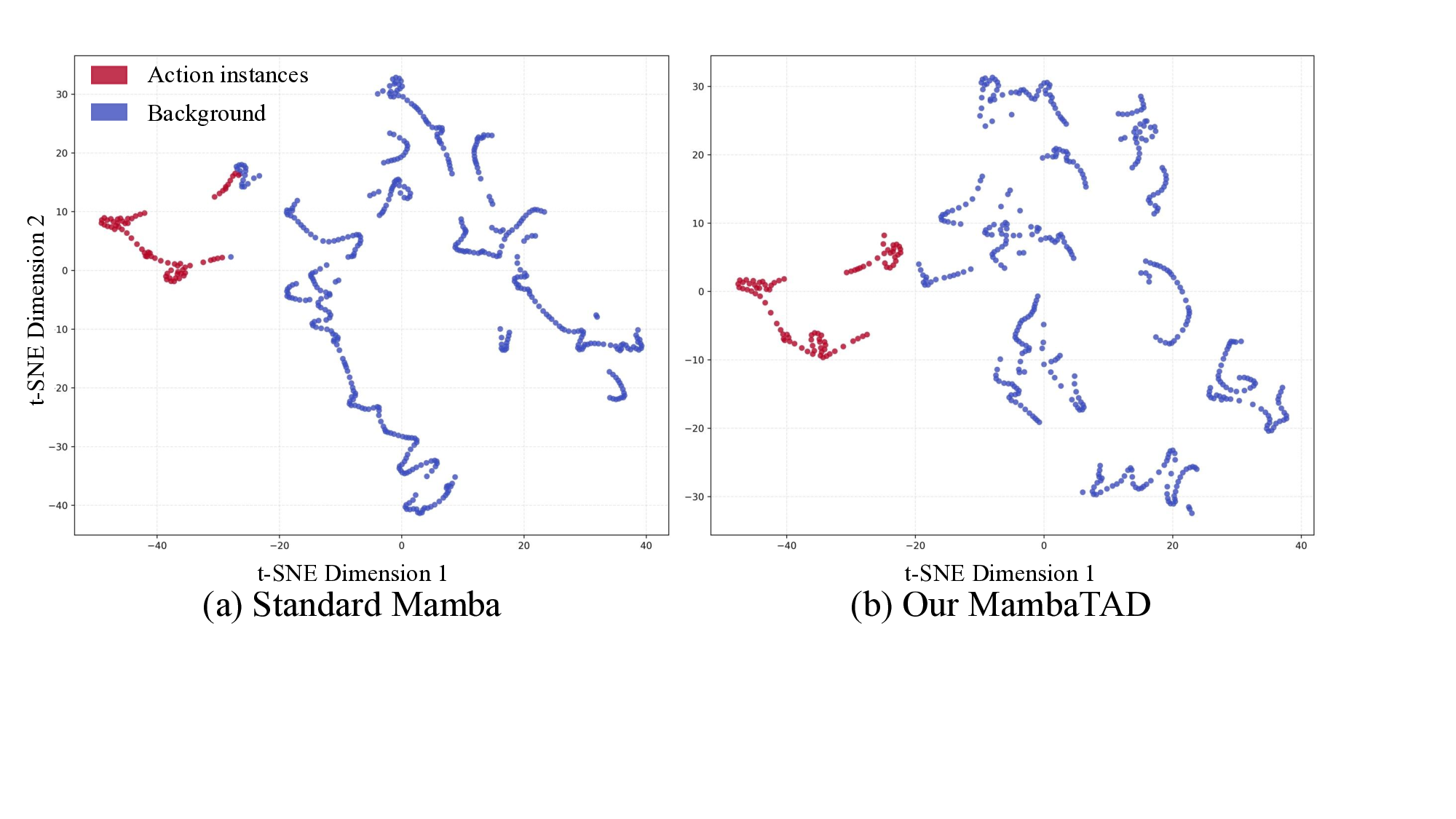
However, the standard Mamba, which is designed for long
sequence data in natural language using one forward branch,
is not a natural fit for the TAD task. Specifically, Mamba
processes flattened one-dimensional sequences in a recursive
manner. It often loses temporal information of earlier moments
and suffers from the problem of decay of temporal information
due to the involved lower triangular matrices [10]. In addition,
since the trainable weights are the incorporation of a lower tri-
angular matrix and an upper triangular matrix in bidirectional
Mamba [11], [12], they often face the problem of self-ele