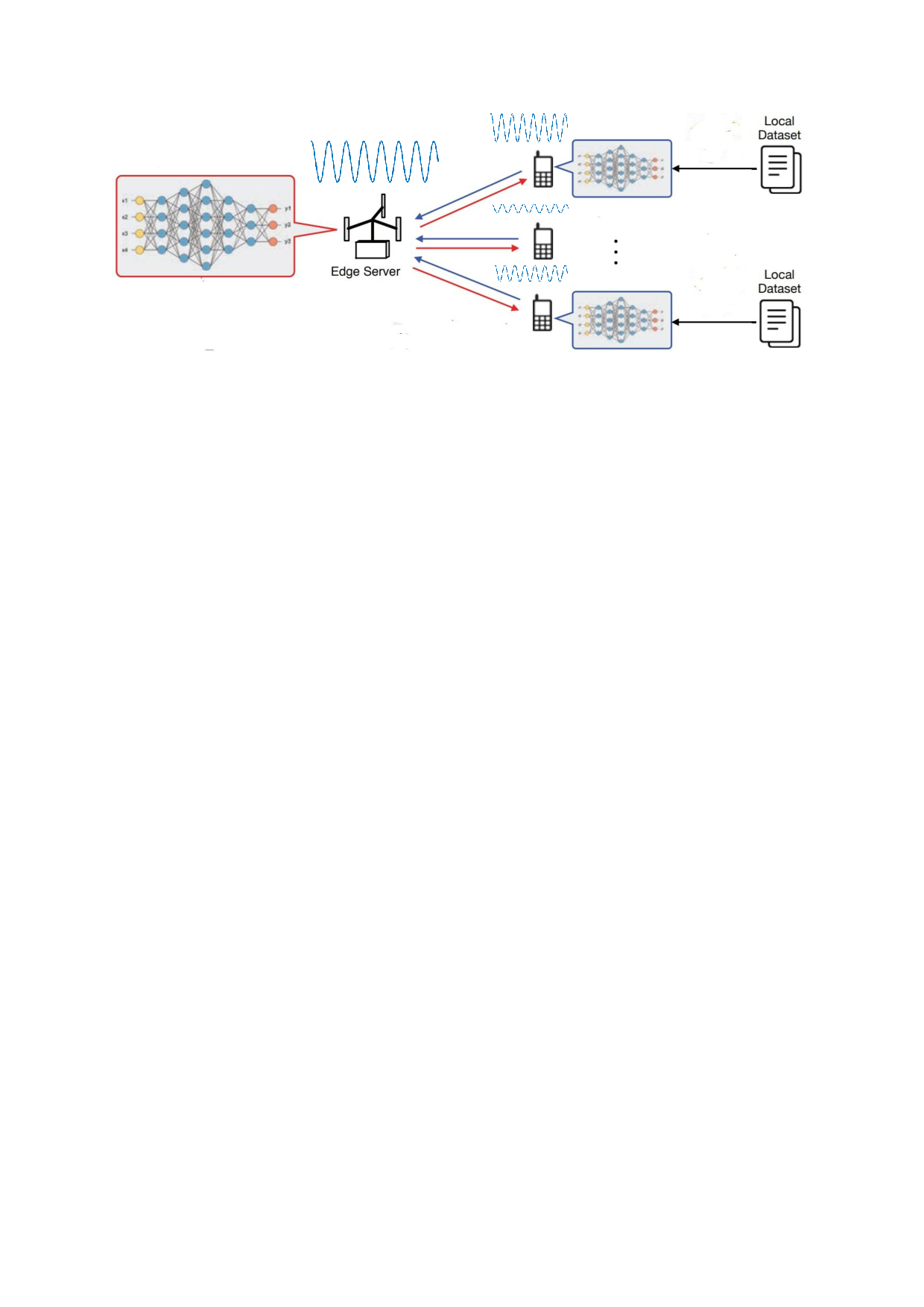
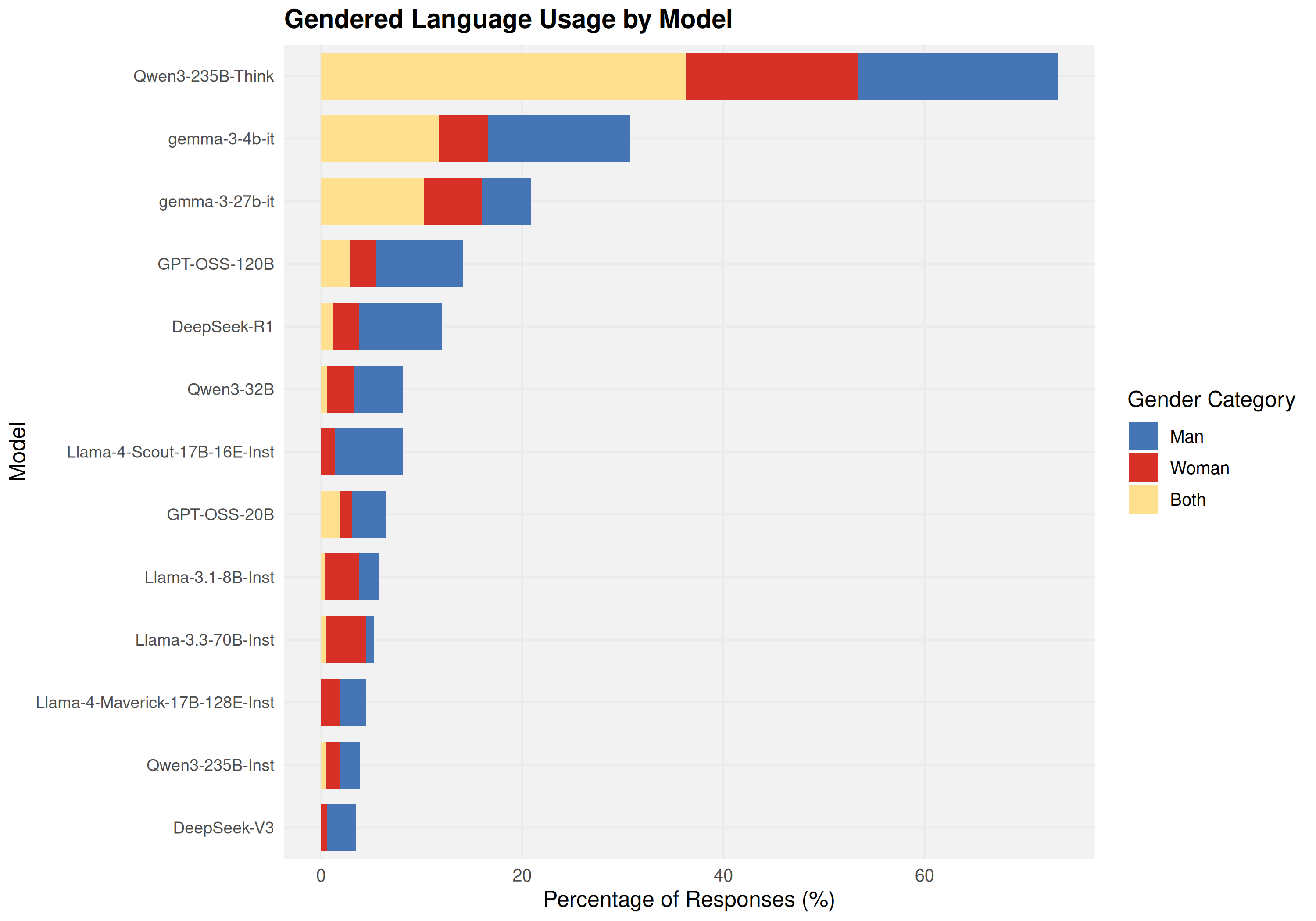
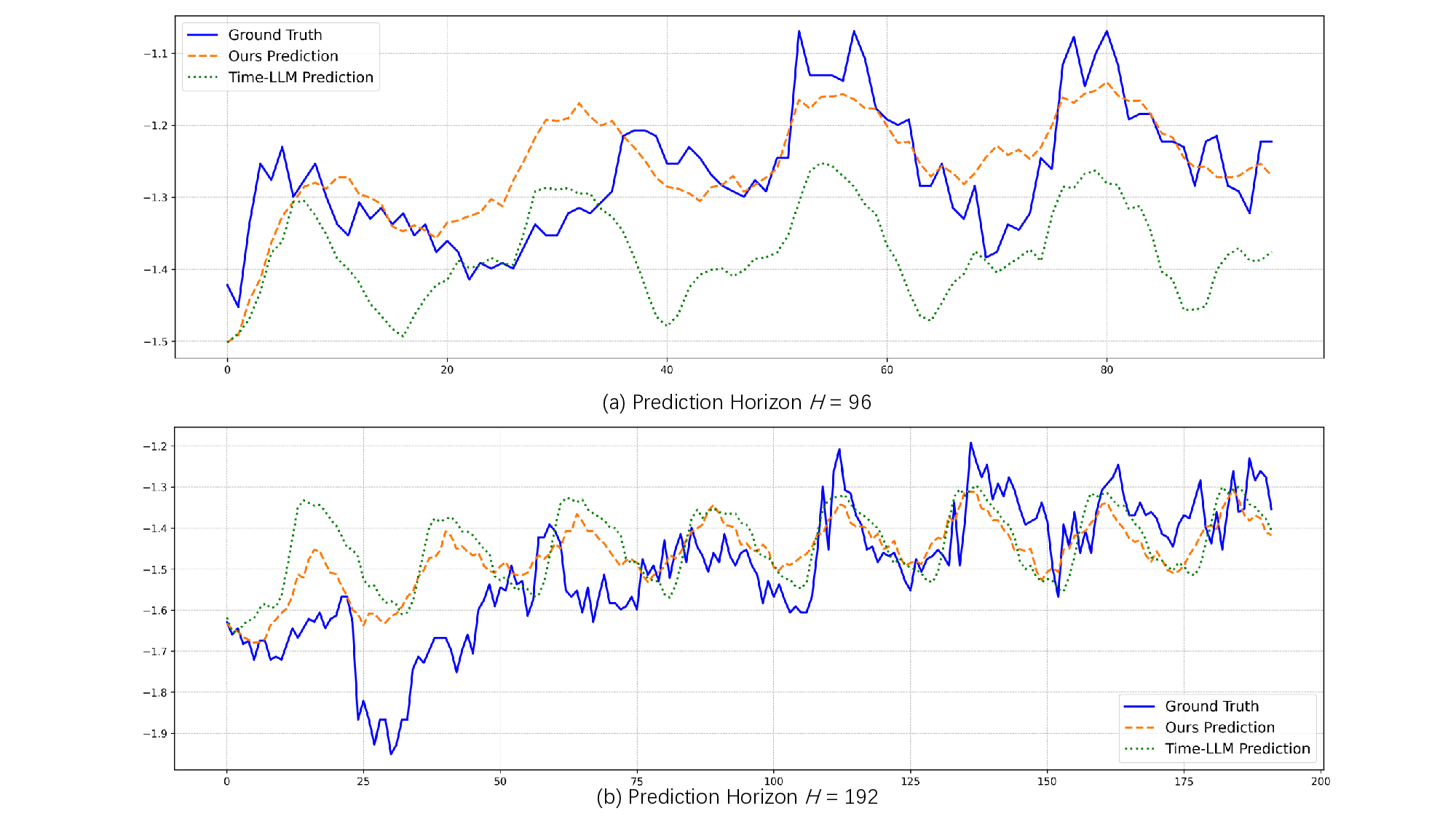
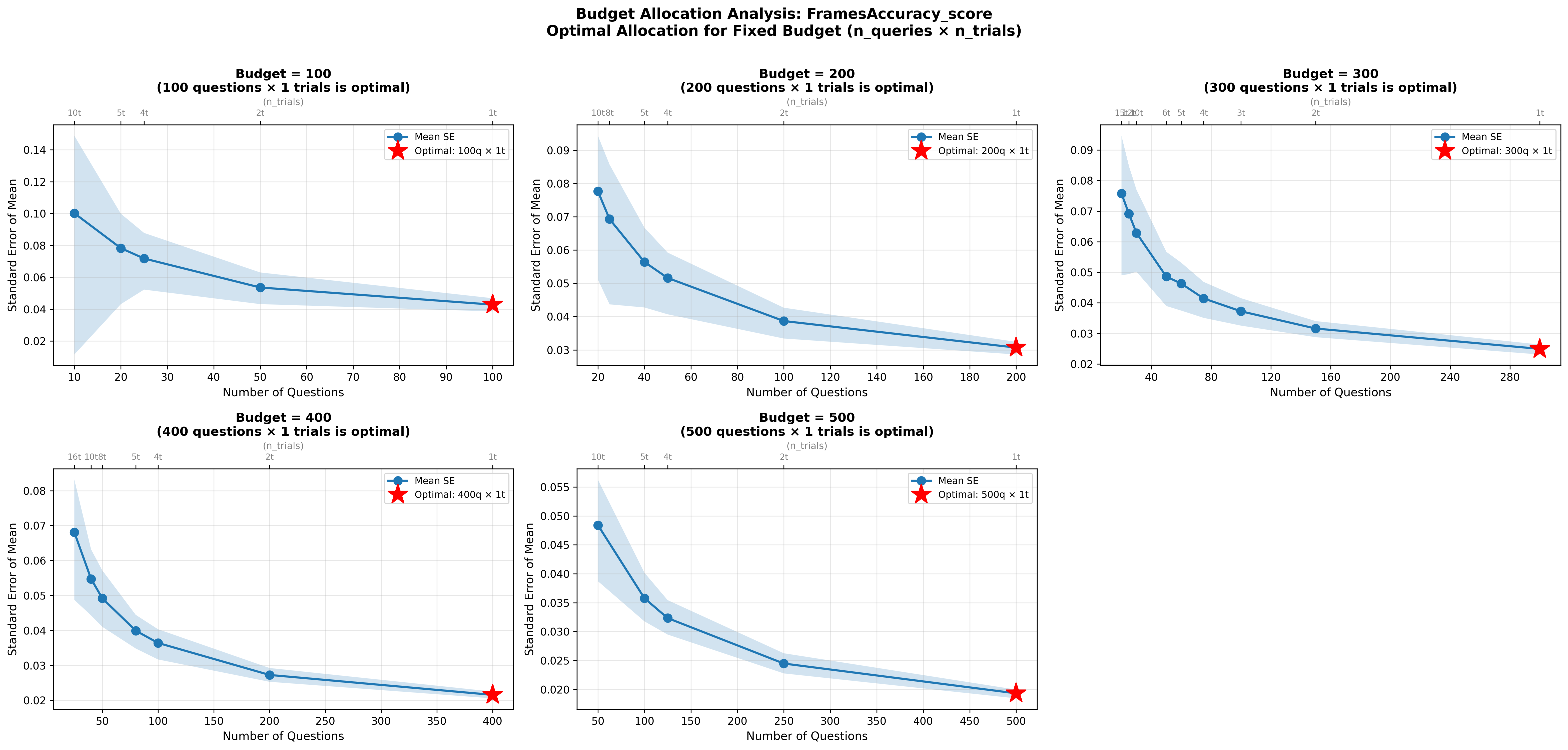
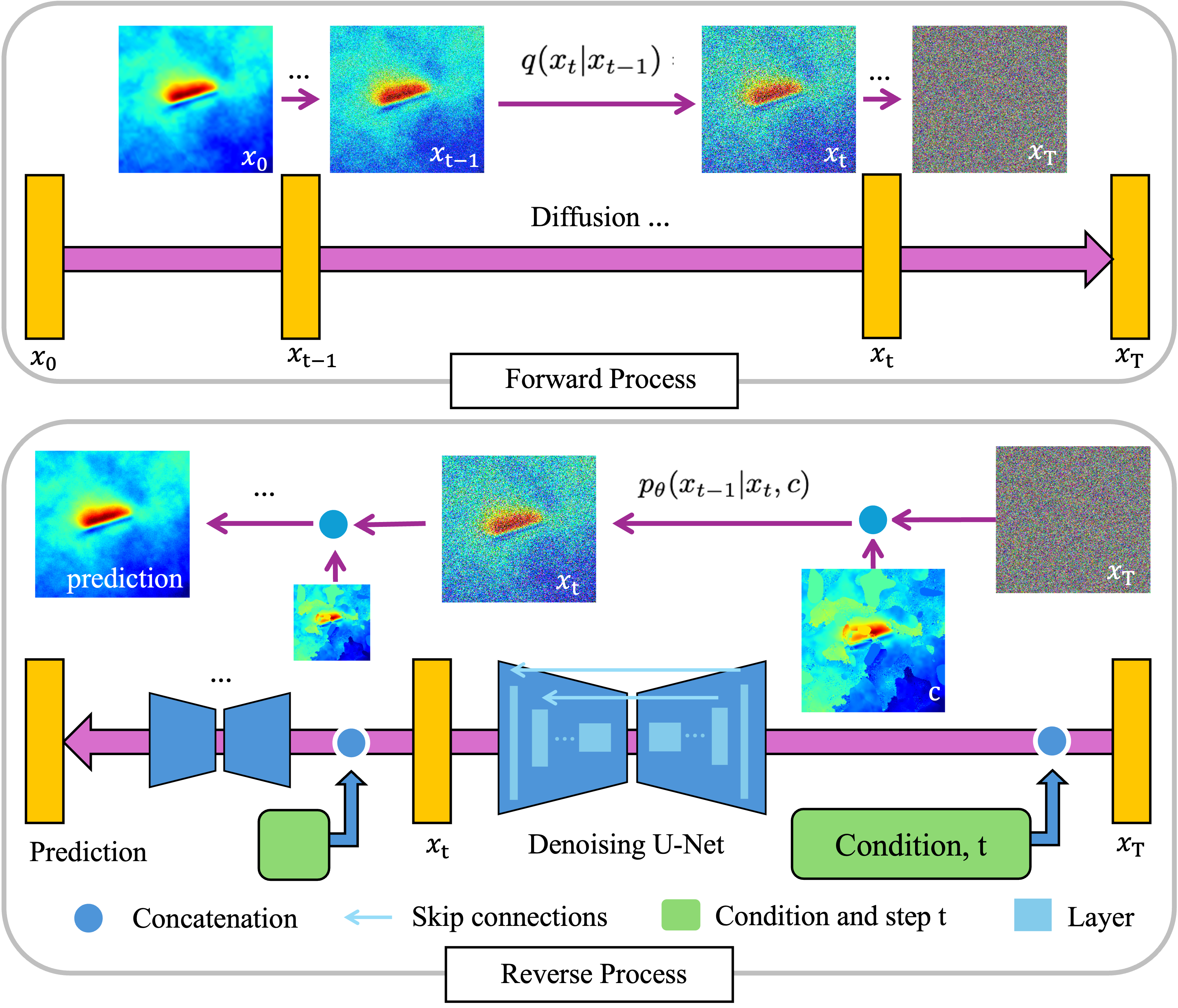
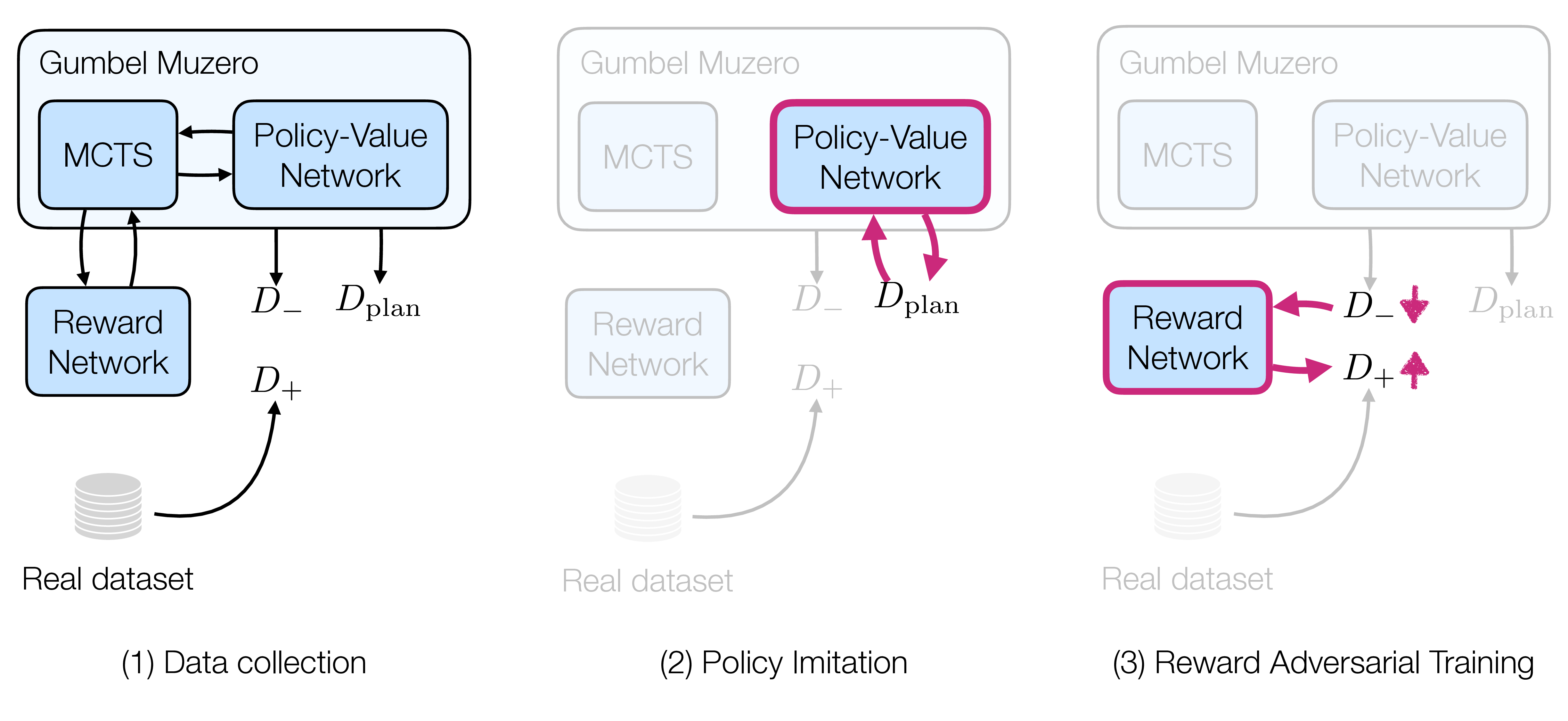
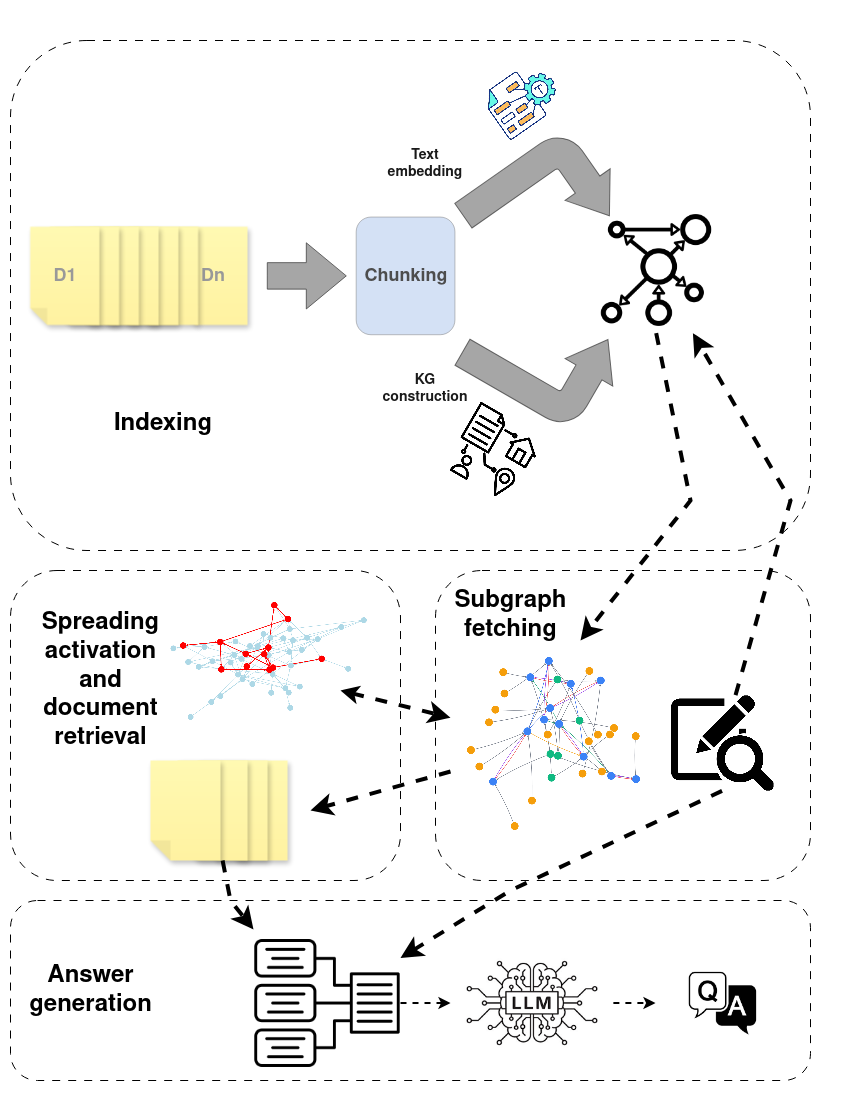
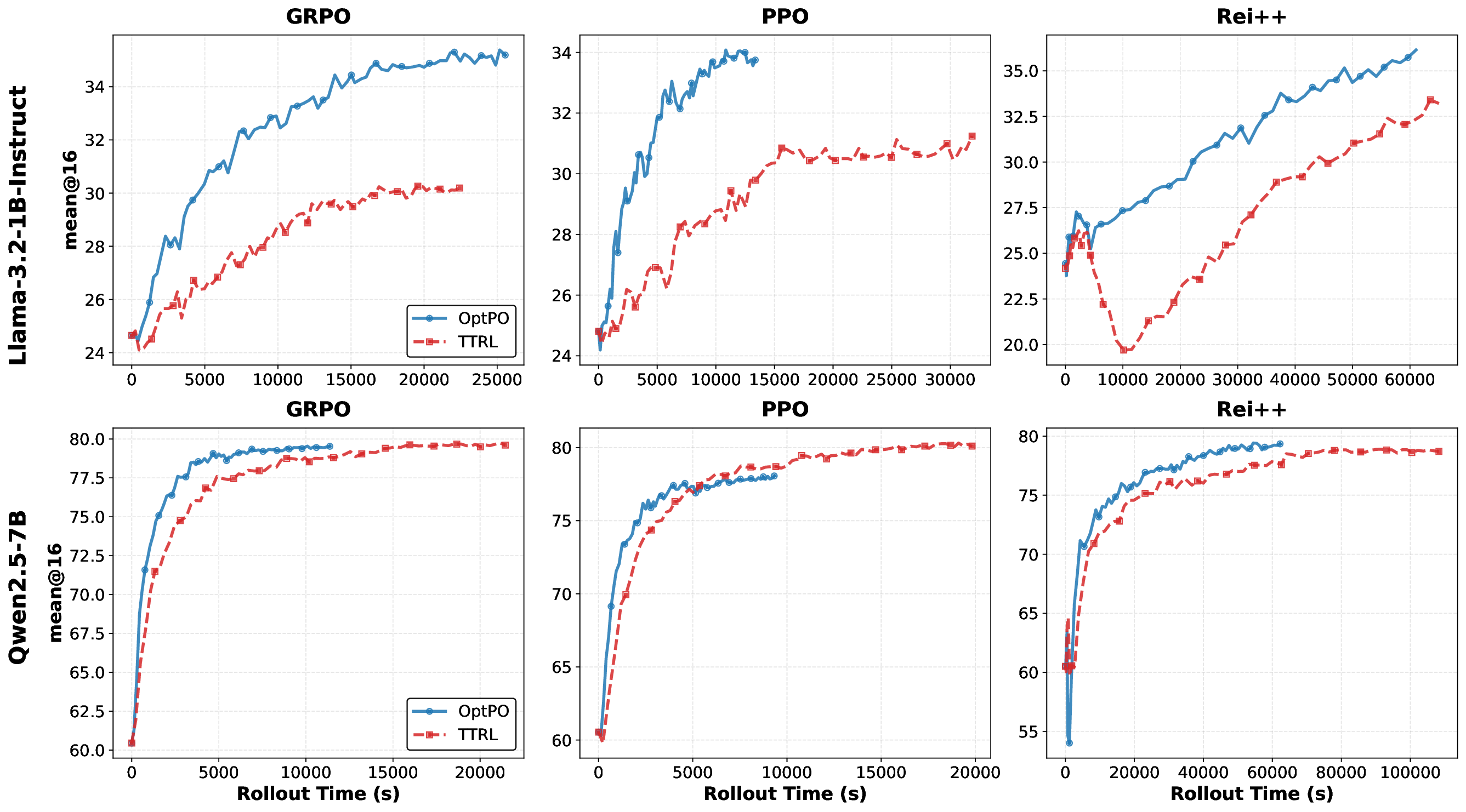
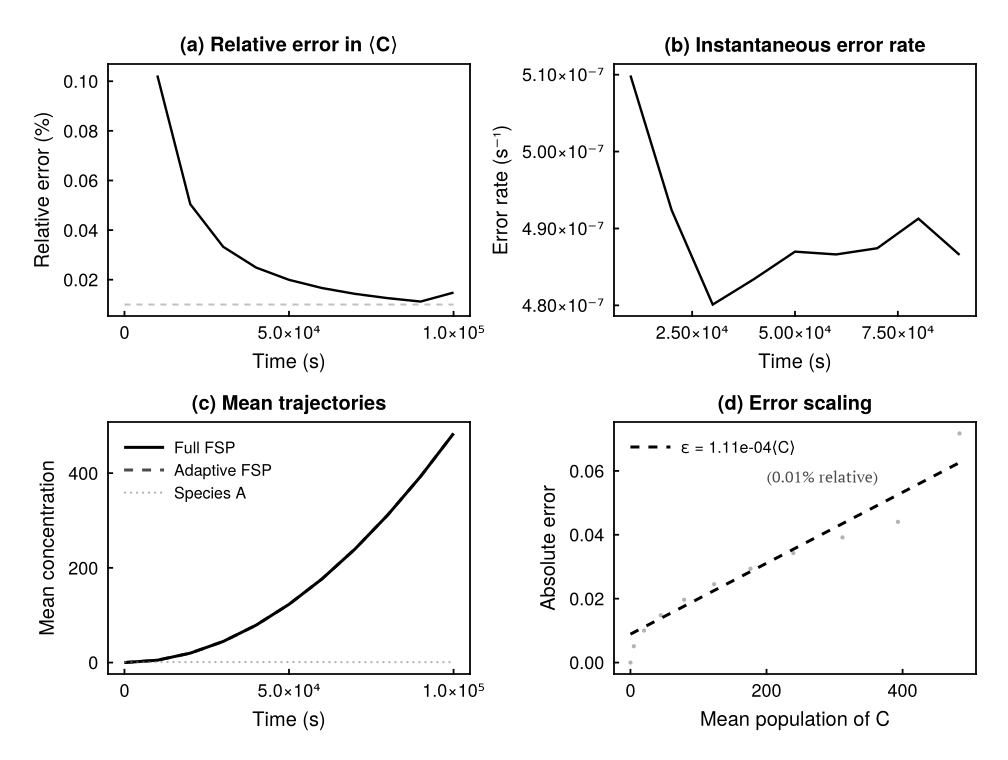
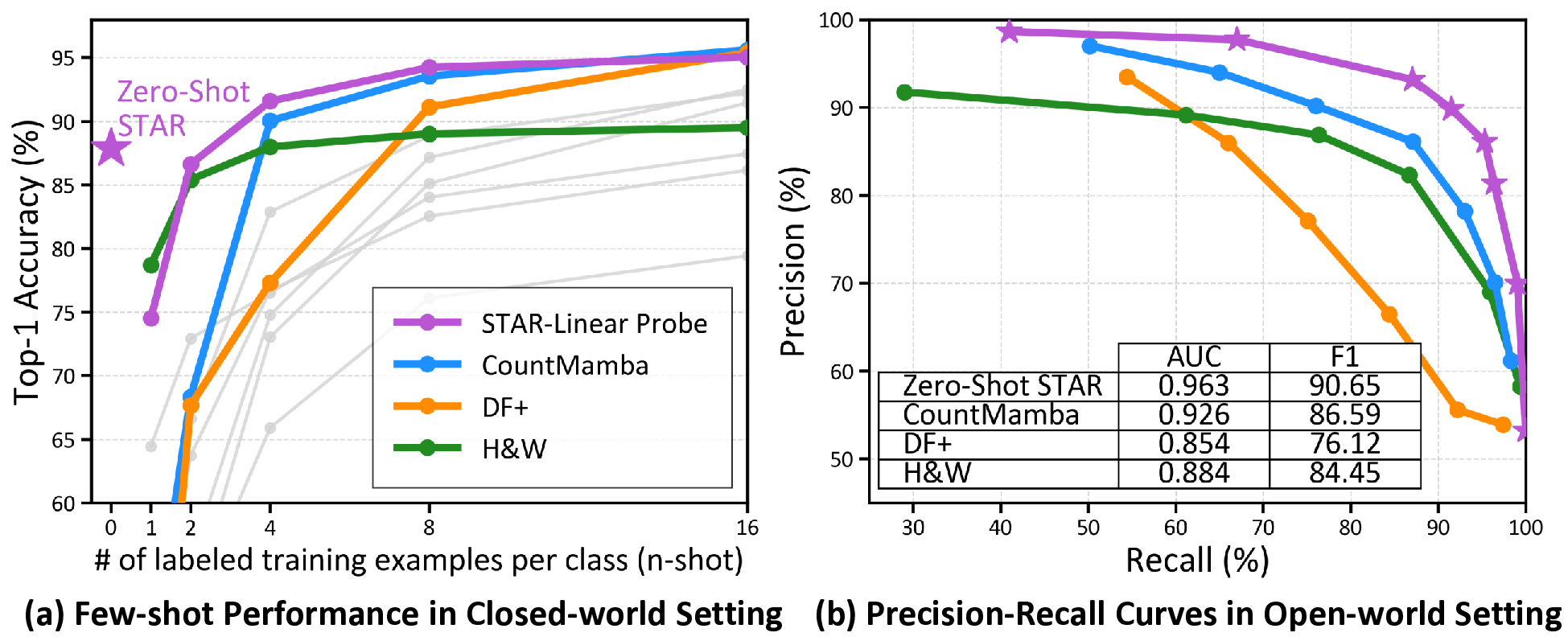
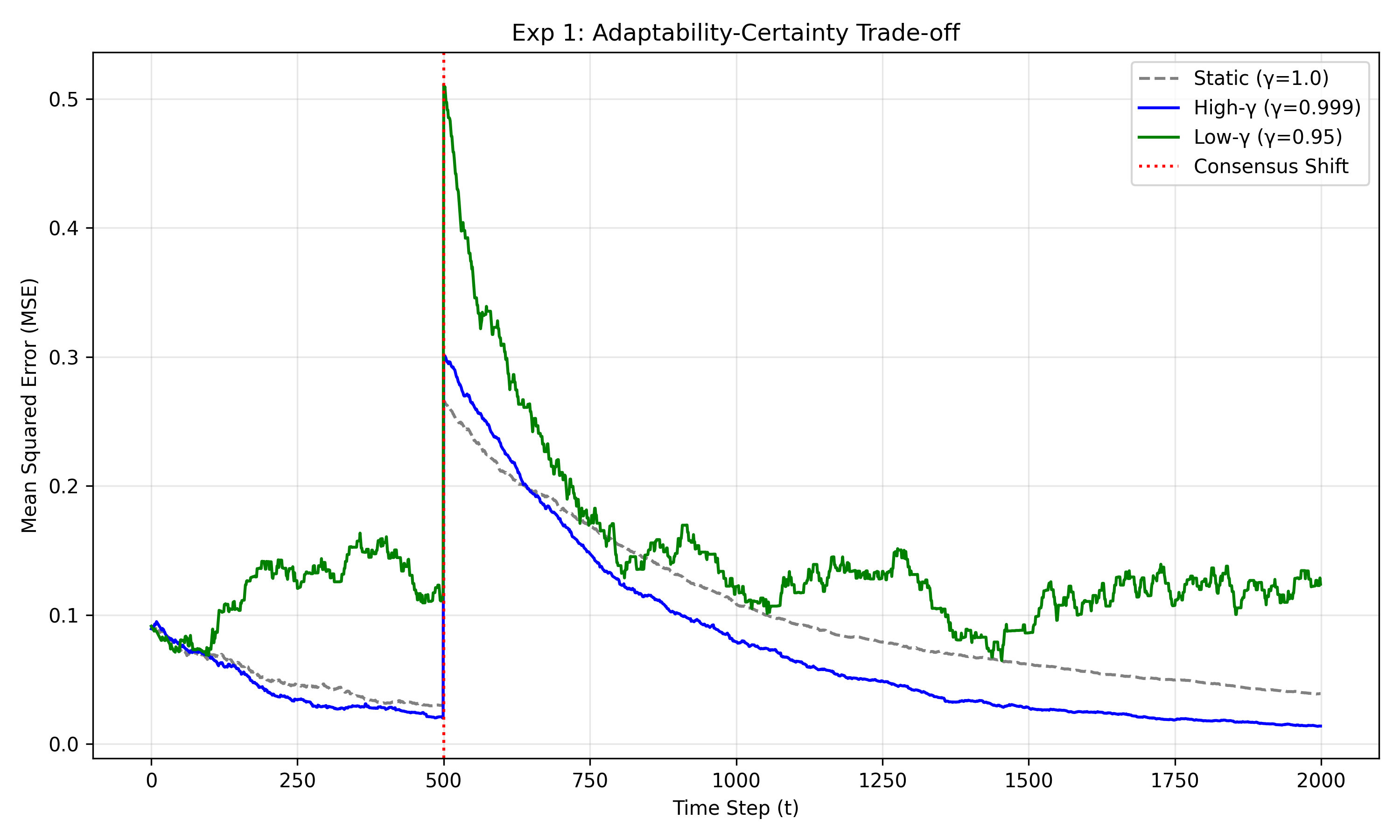
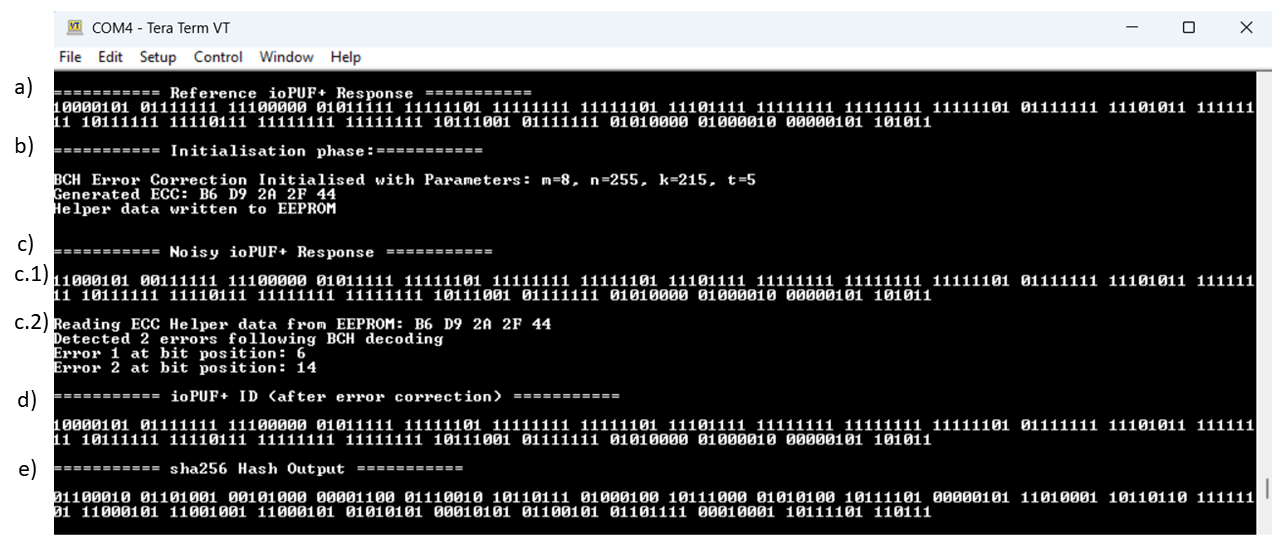
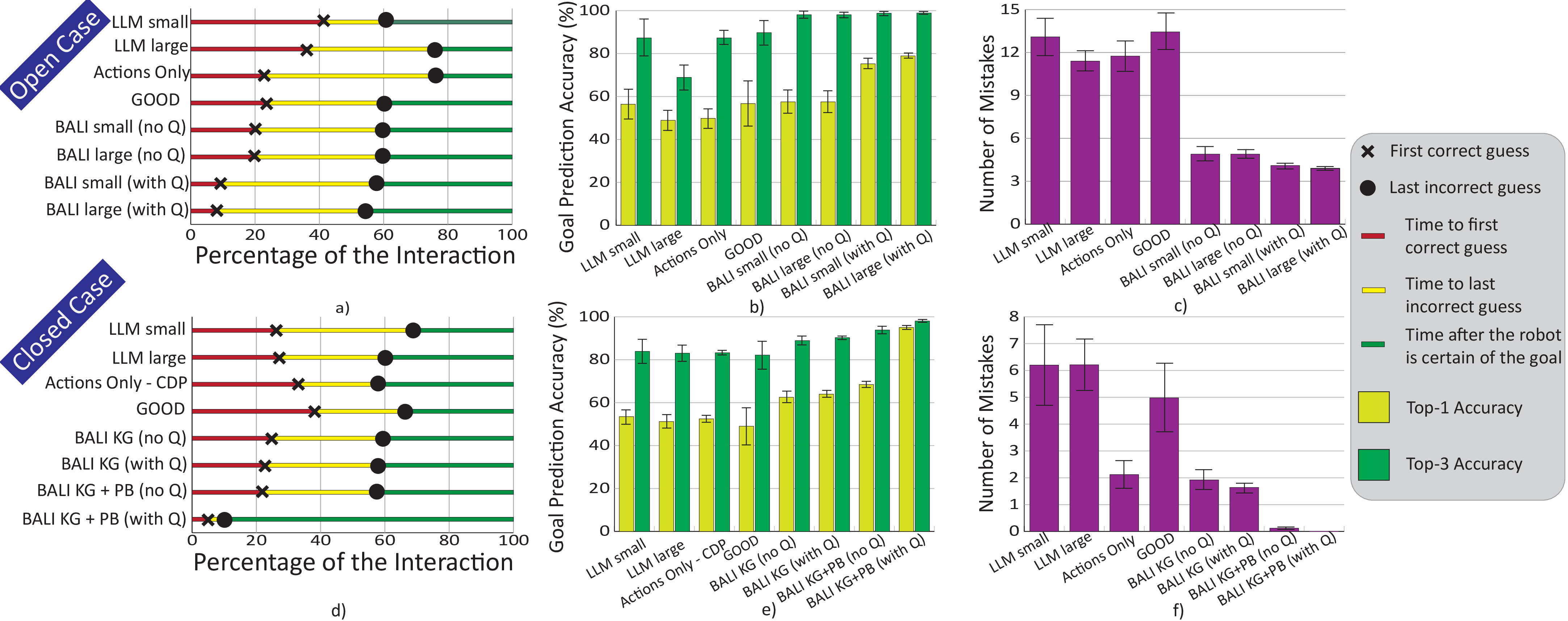
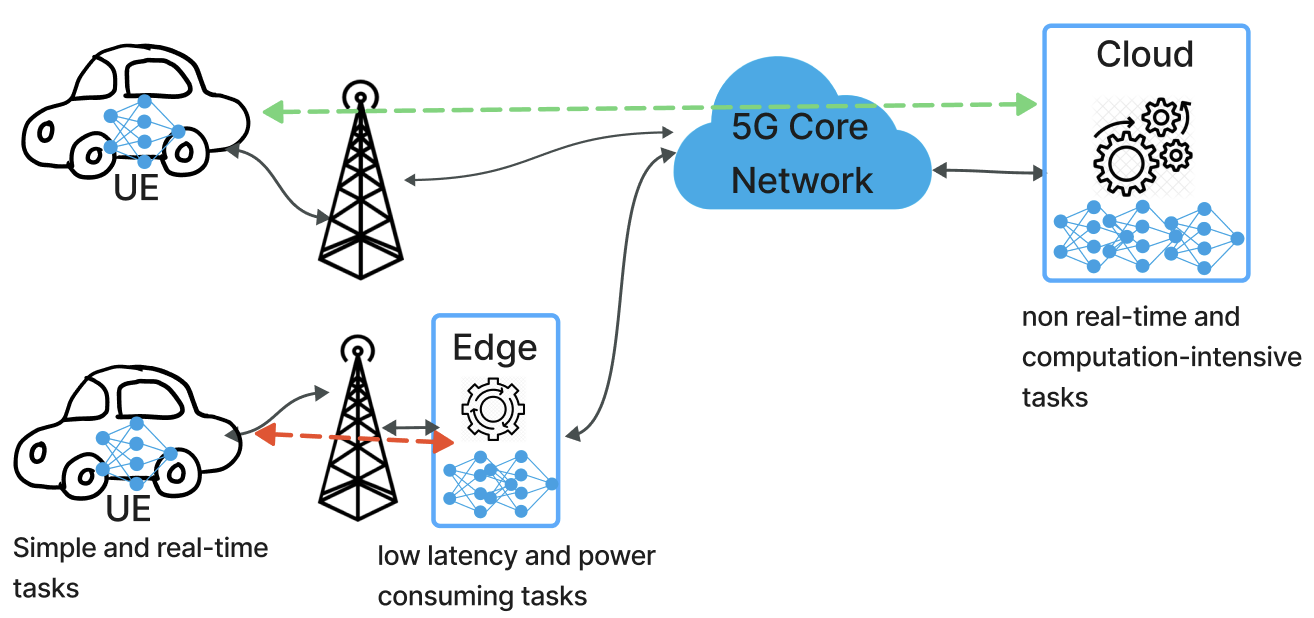
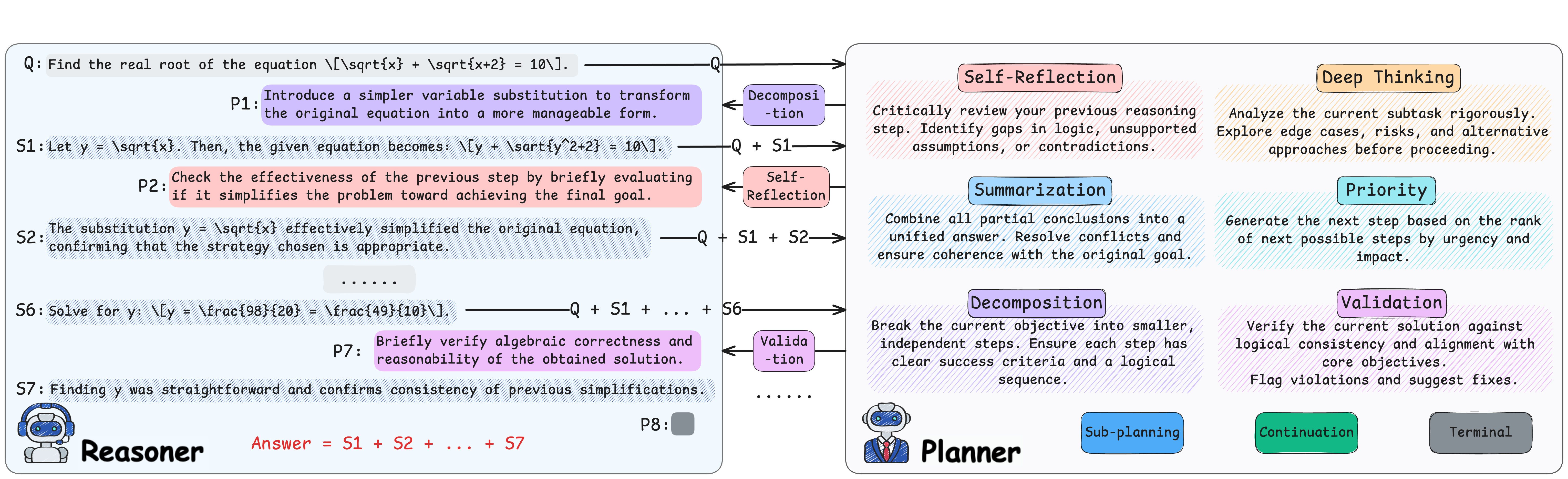
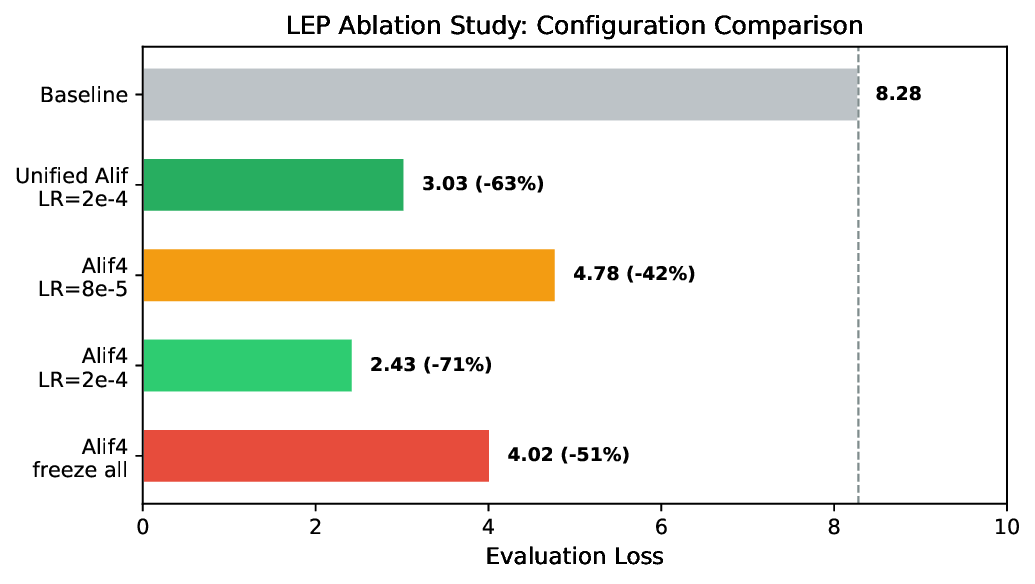
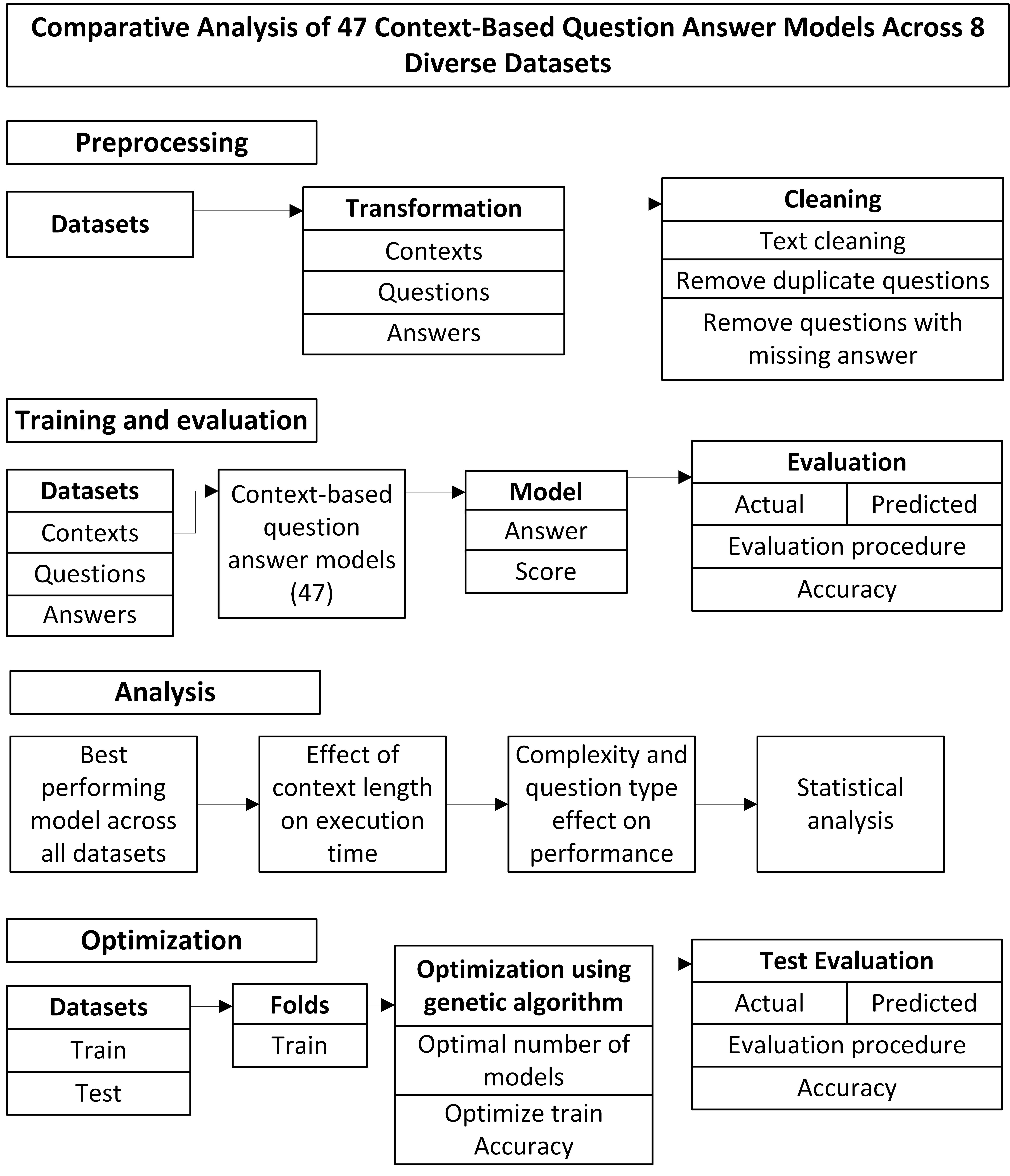
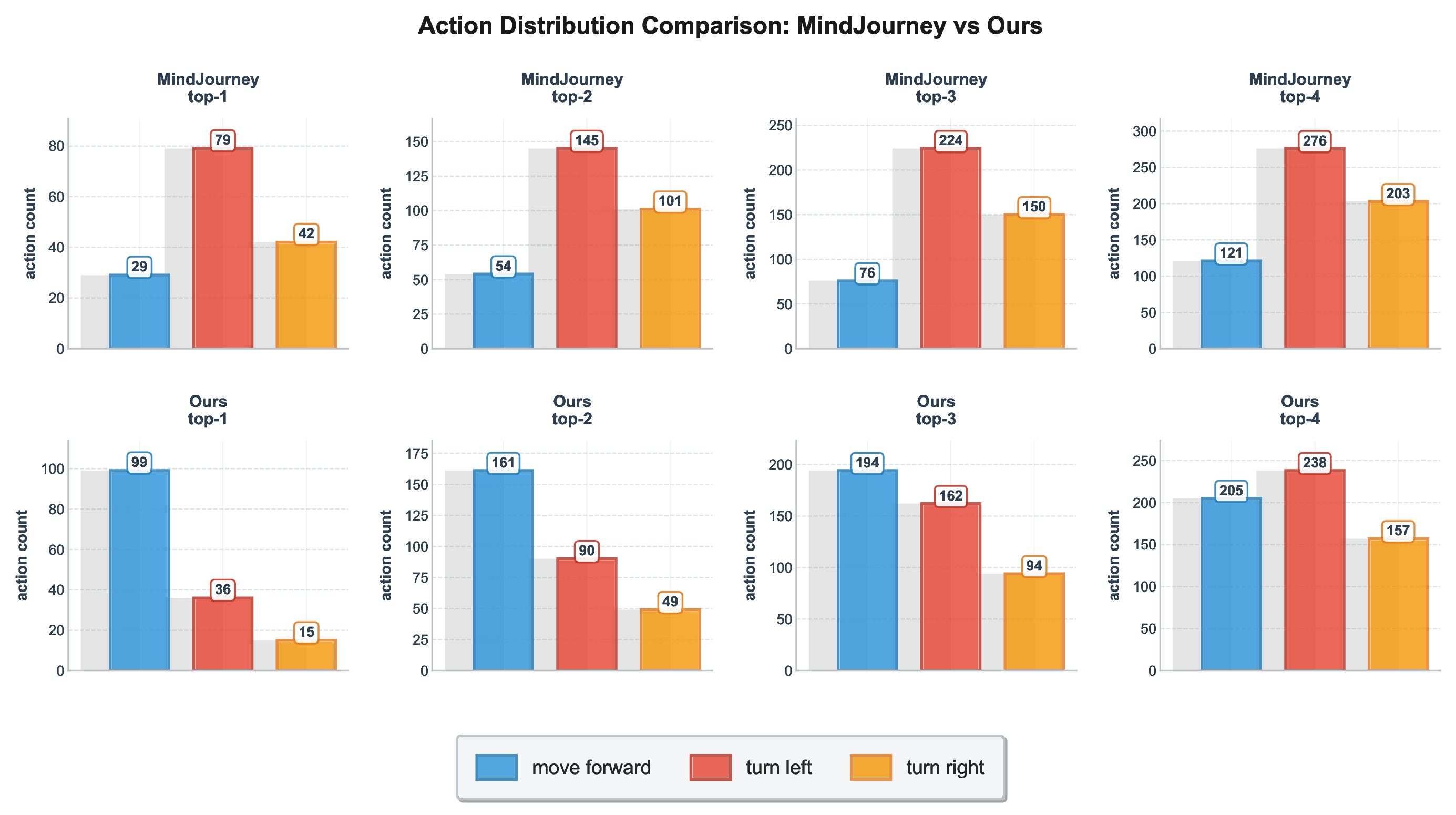
One Layer Is Enough: Adapting Pretrained Visual Encoders for Image Generation
본 논문은 최근 시각 생성 모델이 고차원 이미지 특징을 직접 활용하기보다 압축된 잠재공간에서 작동함으로써 학습 효율성을 높이고 샘플 품질을 유지하려는 흐름을 정확히 짚어낸다. 그러나 사전 학습된 비전 트랜스포머(DINO, SigLIP 등)와 같은 강력한 이해‑지향 특징은 일반적으로 높은 차원을 유지하며, 이는 마스크된 영역에 대한 다양한 가설을 동시에 표현할 수 있다는 장점이 있다. 반면, 확산 모델이나 정규화 흐름과 같은 생성 모델은 노이즈를 정확히 전달하고 점진적으로 샘플을 복원해야 하므로, 차원이 낮고 연속적인 잠재공간을 요구