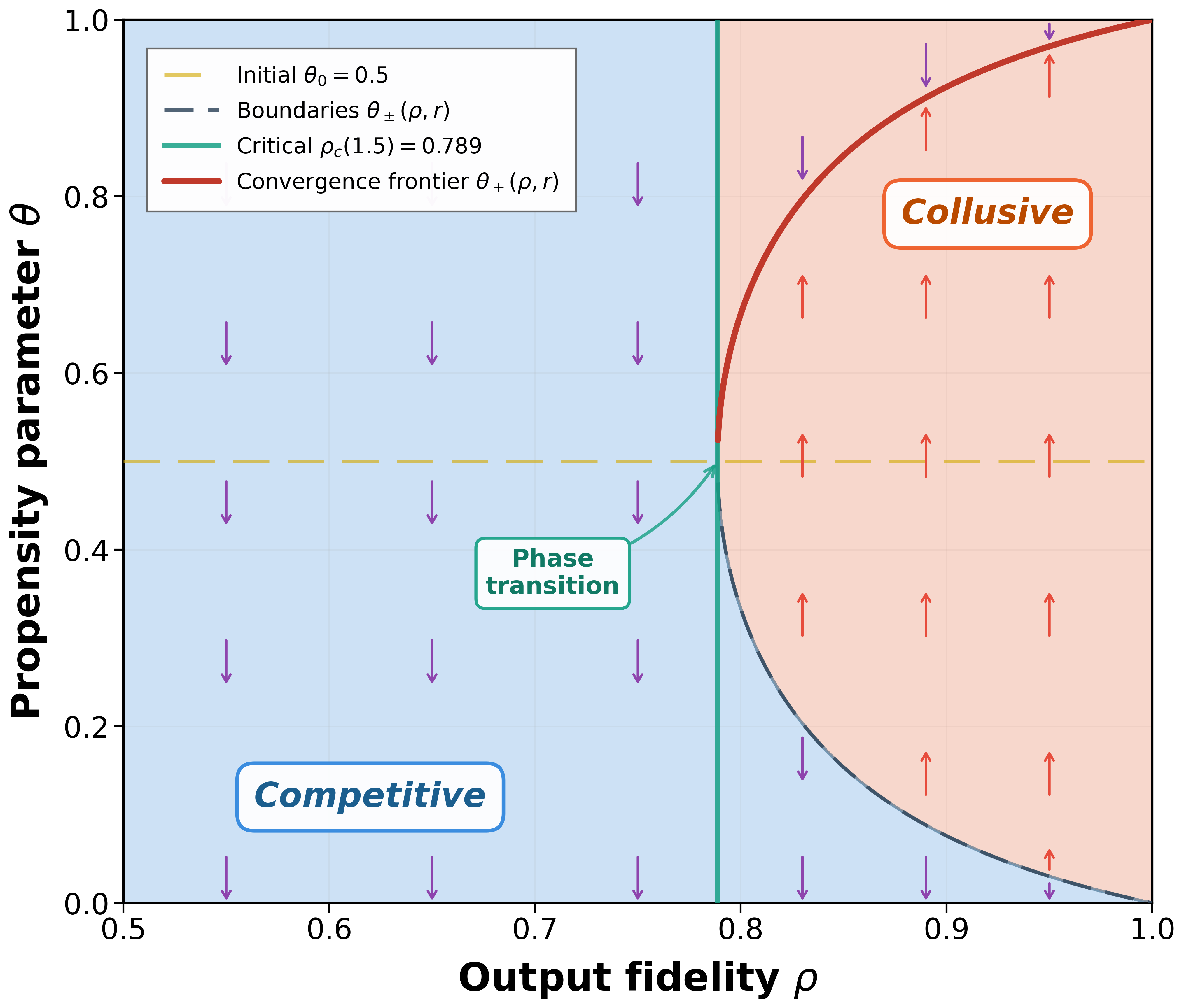
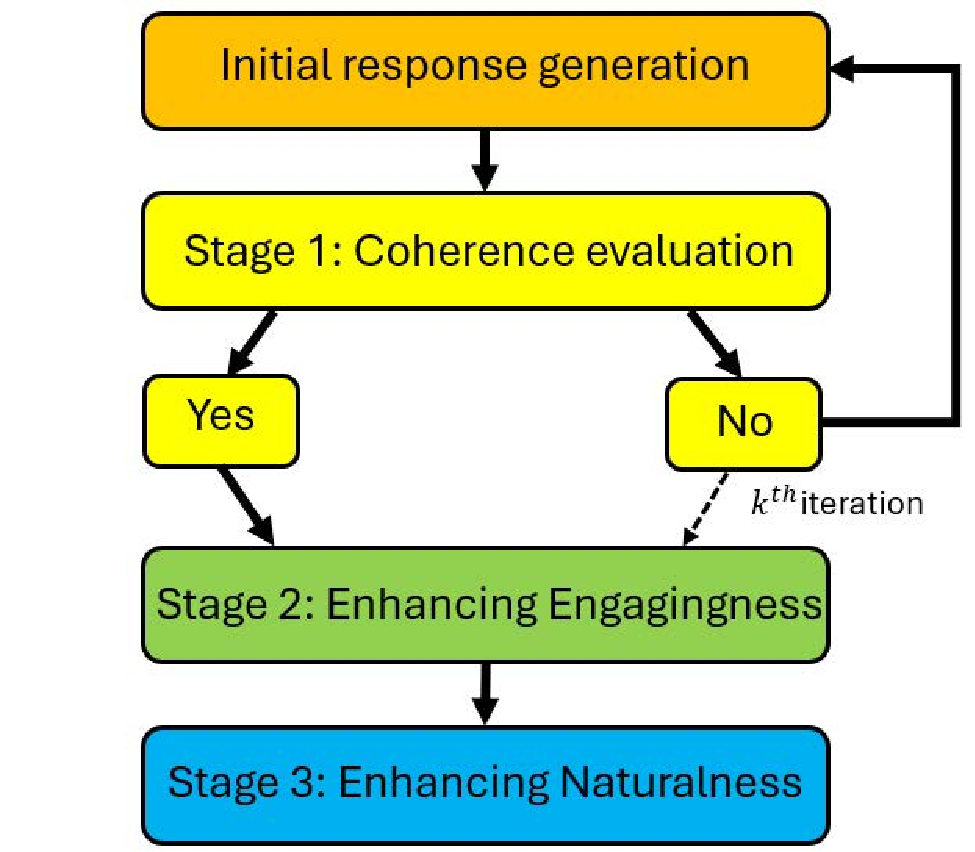
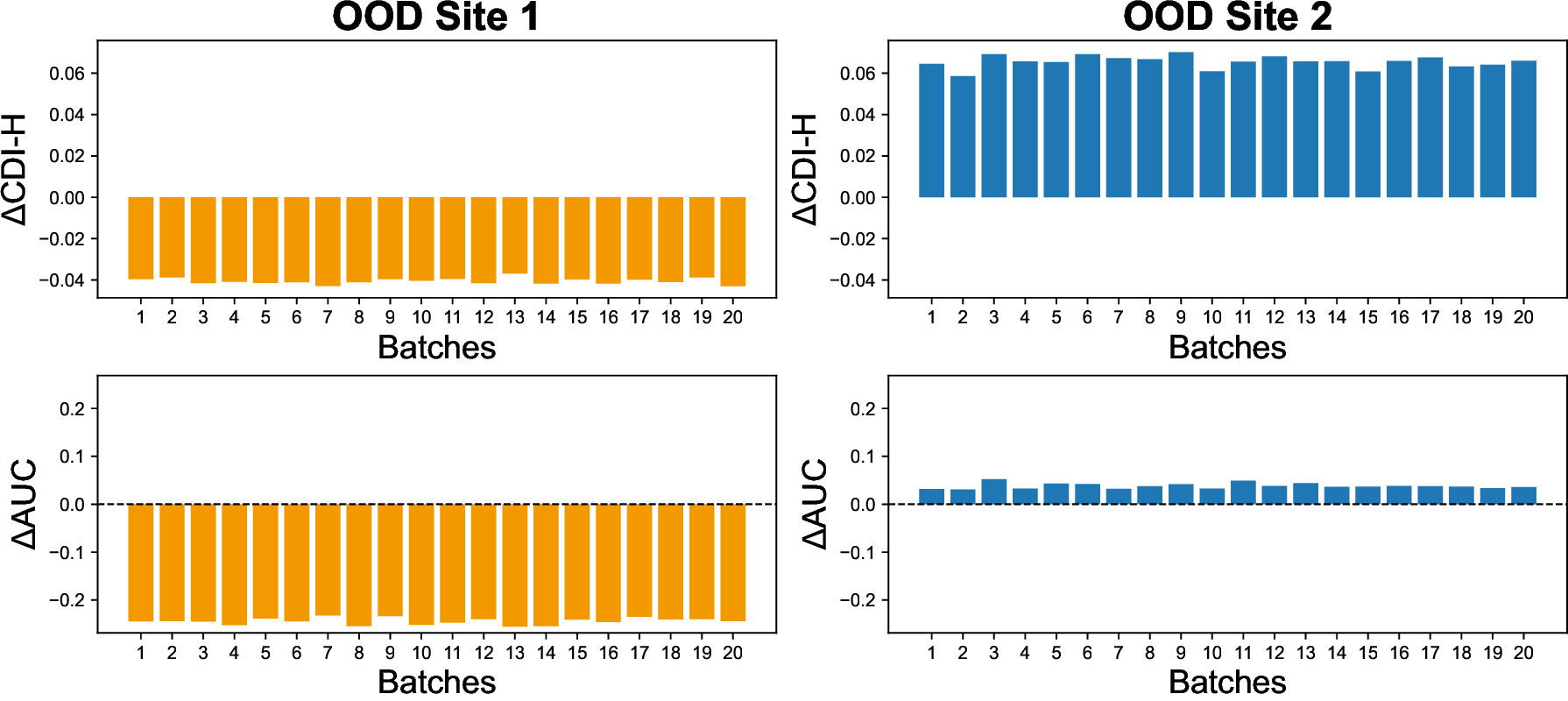
Collaborative Edge-to-Server Inference for Vision-Language Models
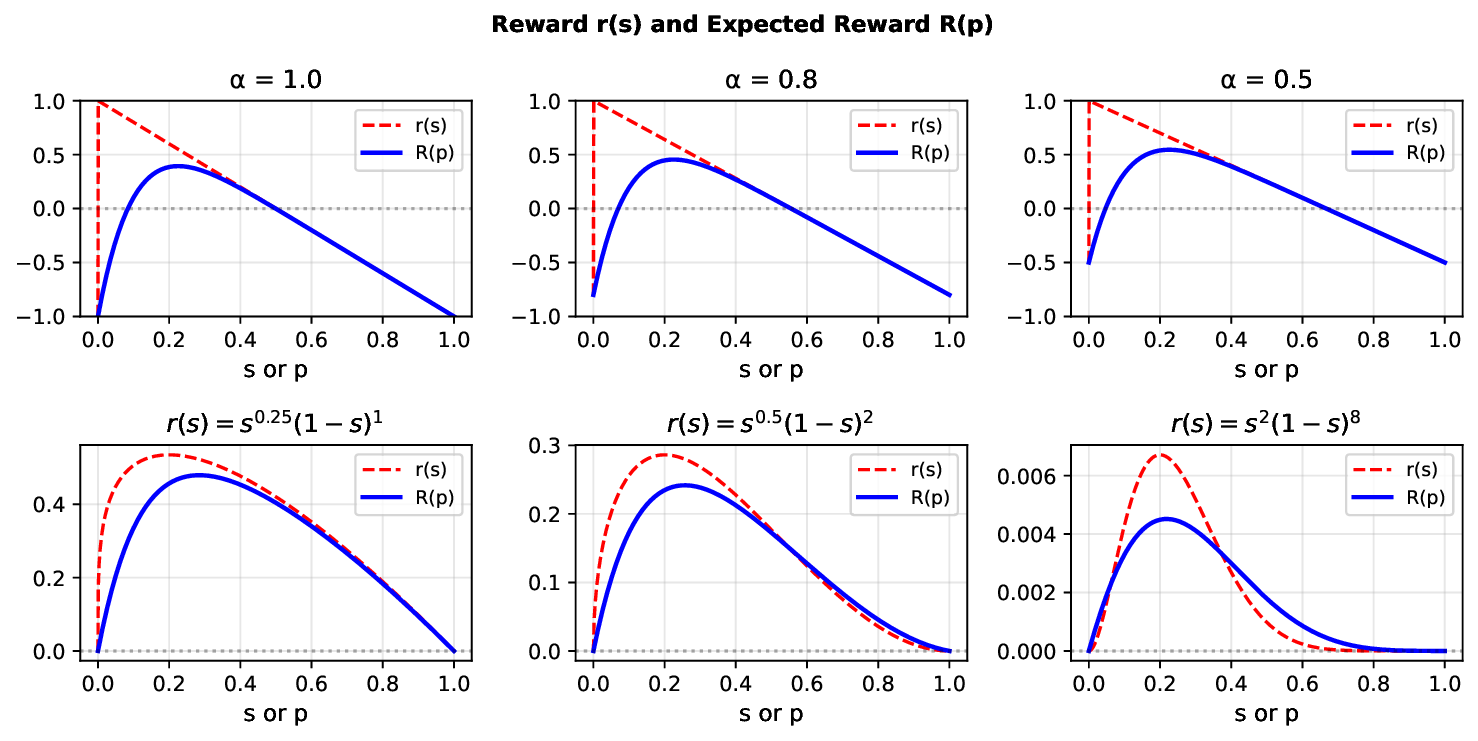
본 논문은 엣지 디바이스와 서버 간의 협업을 통해 비전 언어 모델(VLM)의 추론 과정에서 발생하는 통신 비용 문제를 해결하려는 시도입니다. 전통적인 VLM 추론 방법에서는 엣지 디바이스에서 캡처된 이미지를 서버로 전송하고, 이 이미지는 서버 내부의 비전 인코더에 맞게 리사이징됩니다. 그러나 이러한 과정에서 세밀한 시각 정보가 손실되어 추론 정확도가 저하될 수 있습니다. 논문은 이를 해결하기 위해 두 단계 프레임워크를 제안합니다. 첫 번째 단계에서는 서버에서 전체 이미지에 대한 초기 추론을 수행하고, VLM 내부의 주의 메커니즘을
Model