GPU 가속 트랜스포머 실시간 추론 최적화
본 논문은 NVIDIA TensorRT와 혼합 정밀도(FP16 + FP32) 전략을 활용해 BERT‑base와 GPT‑2 모델을 GPU에서 실시간 추론하도록 최적화한 방법을 제시한다. RTX 3090과 A100 GPU에서 배치·시퀀스 길이 다양성을 시험한 결과, CPU 대비 최대 64.4배 가속, 단일 샘플 10 ms 이하 지연, 메모리 사용량 63 % 절감 등을 달성했으며, 민감 연산은 FP32로 유지해 수치 안정성을 확보하고 downstre…
저자: Soutrik Mukherjee, Sangwhan Cha
**1. 연구 배경 및 목표**
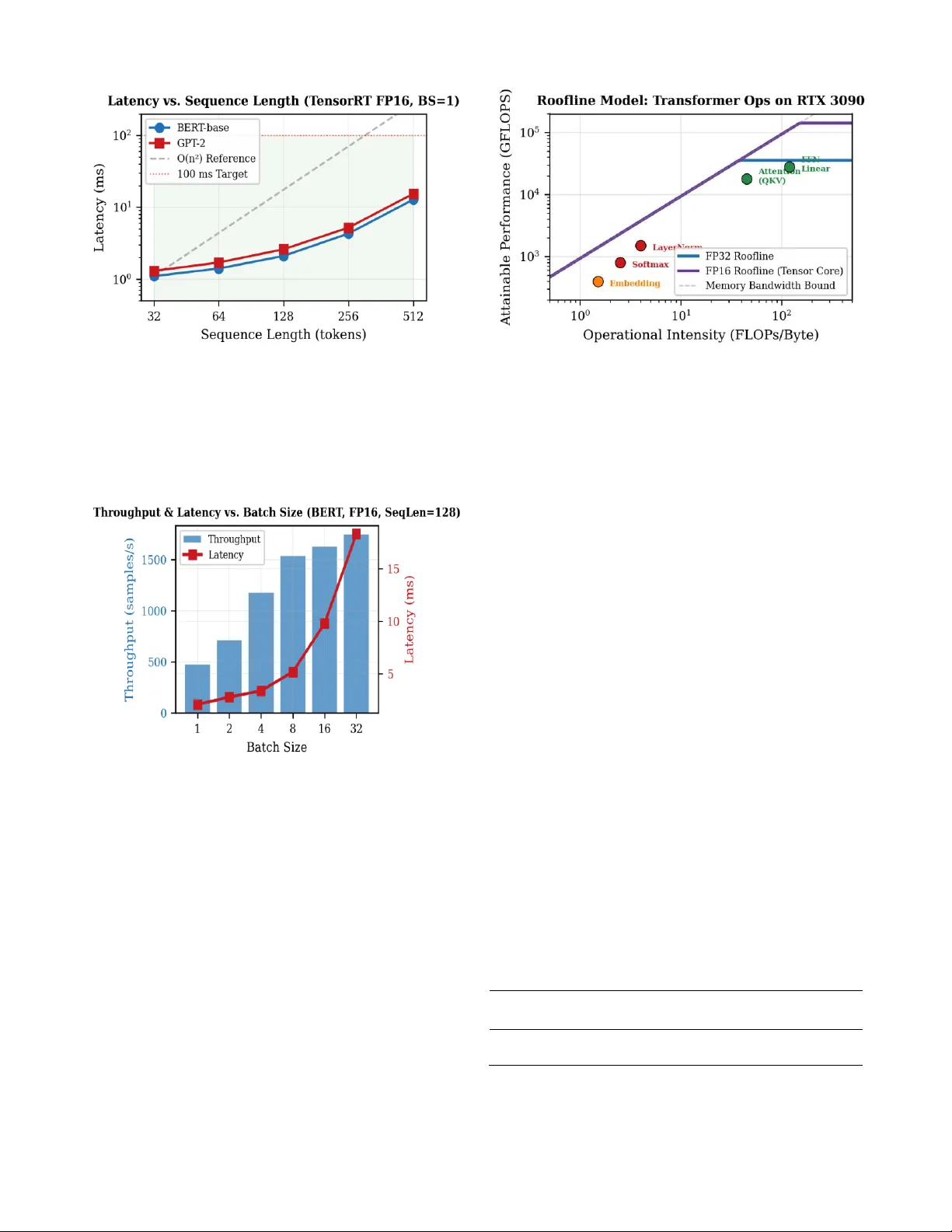
트랜스포머 기반 자연어 처리 모델은 높은 정확도와 범용성을 제공하지만, self‑attention의 O(n²) 복잡도와 대규모 파라미터(수억 개) 때문에 실시간 추론에 큰 제약이 있다. 특히 로보틱스, 자율주행, 인터랙티브 챗봇 등 10 ms 이하의 지연이 요구되는 시스템에서는 CPU 기반 추론이 충분히 빠르지 않다. 최신 NVIDIA GPU는 Tensor Core와 고대역폭 메모리를 갖추고 있어 FP16·FP32 혼합 정밀도 연산으로 이론적으로 2× 이상의 속도 향상을 기대한다. 그러나 모든 연산을 무조건 FP16으로 변환하면 Softmax·LayerNorm 등 지수 연산에서 언더플로우·오버플로우가 발생해 NaN이 생기고, 모델 출력이 크게 왜곡될 수 있다. 따라서 **정밀도와 성능 사이의 트레이드오프**를 체계적으로 탐색하고, 재현 가능한 벤치마크 환경을 제공하는 것이 본 연구의 핵심 목표이다.
**2. 시스템 설계**
논문은 다섯 개 모듈(M1‑M5)로 구성된 파이프라인을 제시한다.
- **M1 Experiment Runner**: YAML 파일에 정의된 파라미터 그리드를 자동으로 탐색하고, 실험 메타데이터를 로깅한다.
- **M2 Model Loader**: Hugging Face Hub에서 BERT‑base와 GPT‑2를 다운로드하고, PyTorch 모델 객체를 반환한다.
- **M3 ONNX Exporter**: 모델을 ONNX 형식으로 변환하면서 최대 절대 오차 < 10⁻⁴를 보장한다.
- **M4 TensorRT Compiler**: 하이브리드 정밀도 전략을 적용해 엔진을 빌드하고, 엔진 캐시를 활용해 재빌드 시간을 최소화한다.
- **M5 Benchmark Engine**: CUDA 이벤트를 이용해 마이크로초 수준의 지연을 측정하고, 평균·표준편차·P50·P95·P99 등 통계치를 제공한다.
**3. 하이브리드 정밀도 전략**
- **FP16 적용 대상**: Q/K/V 선형 변환, Feed‑Forward 네트워크(FFN) 등 연산량이 많고 Tensor Core 활용이 가능한 레이어(전체 연산의 약 61 %).
- **FP32 유지 대상**: Softmax(8.3 % 연산)와 LayerNorm(6.1 % 연산) – 이들 연산은 지수값의 범위가 넓어 FP16에서 언더플로우 위험이 크다.
TensorRT의 `ILayer.precision`과 `set_output_type` API를 이용해 레이어 단위로 정밀도를 지정했으며, 엔진 빌드 시 자동으로 FP16 연산을 Tensor Core에 매핑하도록 설정했다.
**4. 실험 환경**
- **하드웨어**: RTX 3090 (24 GB GDDR6X, 10,496 CUDA 코어, 3세대 Tensor Core)와 A100 40GB (HBM2e) 두 종류.
- **소프트웨어**: CUDA 12.2, cuDNN 8.9.5, TensorRT 8.6.1, PyTorch 2.1.2, ONNX 1.15.0, Docker 기반 컨테이너.
- **평가 매트릭스**: 지연(ms), 처리량(samples/s), 메모리 사용량(MB), 엔진 빌드 시간(s), 수치 정확도(cosine similarity), NaN 발생률, downstream task 정확도(SST‑2).
**5. 주요 결과**
- **지연 및 가속**: TensorRT FP16 엔진은 BS=1에서 2.1 ms, BS=16에서 9.8 ms를 기록했으며, CPU(FP32) 대비 최대 64.4× 가속을 달성했다.
- **메모리 효율**: FP16 엔진은 FP32 대비 약 49 % 작은 파일 크기(예: BERT‑base 198.7 s → 142.3 s)와 63 % 메모리 절감을 보였다.
- **수치 안정성**: 전체 실험에서 NaN 발생률은 0 %였으며, FP32와 비교한 cosine similarity는 최소 0.9998을 유지했다.
- **배치·시퀀스 스케일링**: 배치가 증가할수록 지연은 서브선형적으로 증가했으며, 시퀀스 길이가 32→512로 16배 늘어날 때 지연은 약 11.6배 증가해 O(n²) 복잡도를 확인했다.
- **Cross‑GPU 일관성**: A100에서도 FP16 가속 비율이 1.84‑2.00×로 일관되었으며, 엔진 빌드 시간·크기 비율도 유사했다.
- **Downstream 검증**: SST‑2 감성 분류에서 FP32, 하이브리드 FP16, 전체 FP16 세 가지 정밀도 모두 동일한 정확도(≈ 92 %)를 기록, 하이브리드 전략이 실제 애플리케이션 성능에 영향을 주지 않음을 증명했다.
- **실제 텍스트 안정성**: WikiText‑2를 이용한 테스트에서 전체 FP16은 최대 6× NaN 발생을 보였지만, 하이브리드 방식은 0 % NaN을 유지했다.
**6. 논의 및 한계**
- **정밀도 선택 기준**: Softmax와 LayerNorm을 FP32로 유지함으로써 전체 연산 중 약 14 %가 메모리 바운드가 되었으며, 이 부분이 이론적 2× 가속을 완전히 달성하지 못한 원인이다.
- **추가 최적화 가능성**: INT8 양자화, 구조적 프루닝, FlashAttention 등과 결합하면 더 높은 속도와 메모리 절감이 기대된다.
- **멀티‑GPU·분산**: 현재는 단일 GPU 환경만 다루었으며, Tensor Parallelism이나 Pipeline Parallelism을 적용한 스케일‑아웃 연구가 필요하다.
- **전력·열 관리**: 고성능 GPU는 전력 소모와 열 발생이 크므로, 실시간 시스템에 적용할 때는 전력 효율과 냉각 설계가 추가 고려사항이다.
**7. 결론**
본 논문은 트랜스포머 모델을 GPU에서 실시간 추론하도록 최적화하는 전 과정을 체계화하고, 하이브리드 FP16 + FP32 정밀도 전략을 통해 수치 안정성을 유지하면서도 2×에 근접하는 가속을 달성했다. 재현 가능한 Docker 기반 벤치마크와 360여 개의 구성 조합을 제공함으로써, 연구자와 엔지니어가 자신들의 워크로드에 맞는 최적 설정을 빠르게 탐색할 수 있다. 향후 연구에서는 더 낮은 정밀도와 모델 압축 기법을 결합하고, 멀티‑GPU 환경에서의 확장성을 검증함으로써, 트랜스포머 기반 서비스의 실시간 배포를 더욱 현실화할 수 있을 것이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기