AI와 5G 라디오 액셀러레이터의 융합, 비용·수익을 동시에 잡는 새로운 네트워크 패러다임
본 논문은 GPU 기반 라디오 액세스 네트워크(AI‑RAN)가 5G·6G 인프라의 자본 효율성을 높이고, 유휴 GPU를 LLM 추론 서비스에 임대함으로써 최대 8배의 ROI를 달성할 수 있음을 정량적으로 입증한다.
저자: Gabriele Gemmi, Michele Polese, Tommaso Melodia
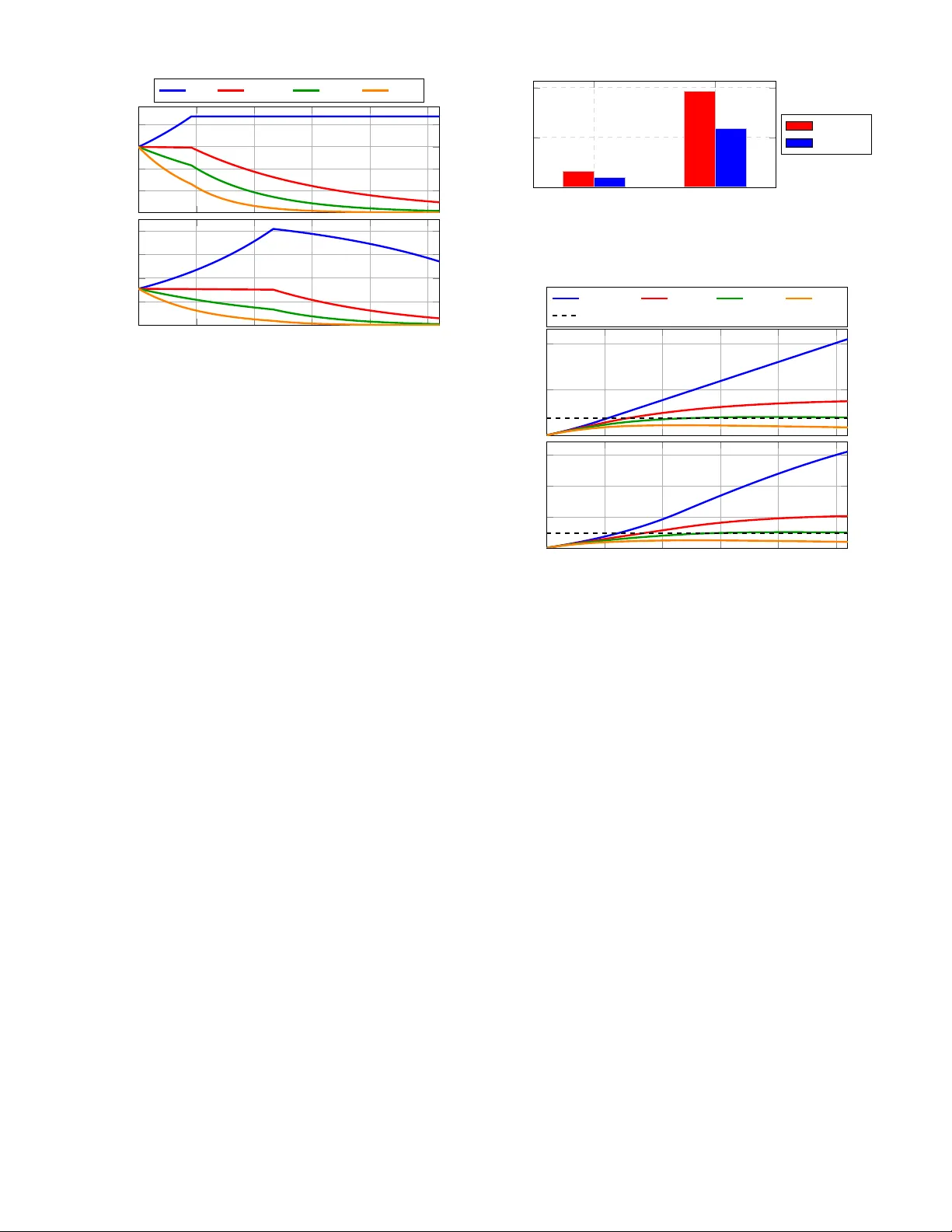
본 논문은 5G·6G 네트워크 구축 비용이 기대 이하의 수익을 내는 현 상황과, 전 세계적인 AI 연산 수요 급증이라는 두 가지 거시적 흐름을 연결한다. 저자들은 ‘AI‑RAN’이라는 개념을 도입해, 라디오 액세스 네트워크(RAN)의 디지털 베이스밴드 처리에 GPU와 같은 고성능 가속기를 활용하고, 피크 시간이 아닌 오프피크 구간에 남는 연산 자원을 대형 언어 모델(LLM) 추론 서비스에 임대함으로써 새로운 수익원을 창출한다는 가설을 검증한다.
논문은 크게 네 부분으로 구성된다. 첫째, 기존 5G 레이어‑1 처리에 대한 공개 벤치마크 데이터를 수집·정리한다. 여기에는 NVIDIA GH200 기반 Aerial 서버와 Intel FlexRAN VRB1 가속기를 탑재한 x86 서버가 포함되며, 각각의 베이스밴드 용량(B), 비용(Cost), 전력(Power) 등을 표 1에 정리한다. 베이스밴드 용량은 L_DL·N_C·BW 로 정의되며, 이를 통해 서로 다른 MIMO 레이어·셀·대역폭 구성을 하나의 지표로 비교한다.
둘째, 이러한 플랫폼을 실제 도시 환경에 적용하기 위한 배치 모델을 제시한다. ITU‑R의 1:3 매크로‑마이크로 셀 비율을 채택하고, 목표 트래픽 10 Gbps(10 년 동안) 달성을 위해 필요한 서버 수를 계산한다. 여기서 사용자당 바쁜 시간 평균 300 Mbps 요구와 연간 ρ_R 성장 계수를 적용해 시간‑주별 트래픽 프로파일 λ_RAN(h)를 도출한다. 서버당 순전송량 C_net은 베이스밴드 용량·스펙트럼 효율·오버헤드 보정을 통해 산출된다.
셋째, 남는 GPU 자원을 LLM 추론에 할당하는 수요 모델을 구축한다. BurstGPT 데이터셋을 기반으로 실제 LLM 서비스의 시간‑주별 토큰 요청량 λ_LLM(h)를 추정하고, 토큰당 가격이 연간 5‑10 배 하락한다는 ‘토큰 감가’ 시나리오를 적용한다. GPU당 초당 처리 가능한 토큰 수와 전력·전기료를 매핑해, 유휴 GPU가 생성할 수 있는 일일·연간 매출을 정량화한다.
넷째, 비용·수익을 통합한 경제 모델을 통해 ROI를 계산한다. CapEx는 피크 시점에 차원화된 서버 수 G_RAN·Cost_server 로, OpEx는 시간‑주별 서버 전력 소비·PUE·전기 요금으로 산출한다. 남는 GPU 수 G_free(w,h)를 이용해 AI‑on‑RAN 매출을 구하고, 이를 CapEx·OpEx와 비교한다. 민감도 분석에서는 토큰 가격 하락 속도, AI 수요 변동, GPU 밀도(서버당 GPU 수) 등을 파라미터로 변동시 ROI 변화를 확인한다.
주요 결과는 다음과 같다. (1) GPU 기반 Aerial 플랫폼은 FlexRAN 대비 4배 이상의 베이스밴드 용량을 제공하지만, 비용·전력 프리미엄이 7‑8배에 달한다. (2) 오프피크 구간에 평균 30‑40 %의 GPU 활용률을 달성하면, 추가 수익이 CapEx·OpEx를 상쇄하고 10년 기준 ROI가 4‑8배에 이른다. (3) 토큰 가격이 예상보다 빠르게 하락해도, GPU 활용률이 40 % 이상이면 순이익이 유지된다. (4) AI 수요가 급감하거나 GPU 밀도가 낮을 경우, FlexRAN 기반 저비용 배치가 더 경제적이다.
마지막으로, 저자들은 본 연구에 사용된 모델·코드와 웹앱을 오픈소스로 공개하여, 네트워크 사업자·클라우드 제공업체·정책 입안자가 손쉽게 시뮬레이션하고 투자 결정을 내릴 수 있도록 지원한다. 이와 같이, 논문은 기술적 실현 가능성과 경제적 타당성을 동시에 입증함으로써, 차세대 6G 네트워크 설계에 GPU 기반 가속기와 AI 서비스의 동시 활용을 전략적 선택지로 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기