LLM 남용 방지를 위한 스테가노그래피 캔리 파일 방어 체계
본 논문은 기업 내부 문서에 암호학적으로 검증 가능한 식별자를 은닉한 스테가노그래피 캔리 파일을 생성하고, 클라우드 기반 LLM 서비스의 입력 전 단계에서 이를 추출·검증함으로써 무단 문서 업로드를 차단하는 프레임워크를 제안한다. 두 가지 운영 모드(A: 기존 문서에 심볼릭 인코딩, B: GPT‑2 기반 언어 스테가노그래피와 심볼릭 레이어 결합)를 설계하고, 4단계 전송·변형 위협 모델을 통해 복원율을 평가한다. 실험 결과, 정상 및 정제 파이…
저자: Md Raz, Venkata Sai Charan Putrevu, Meet Udeshi
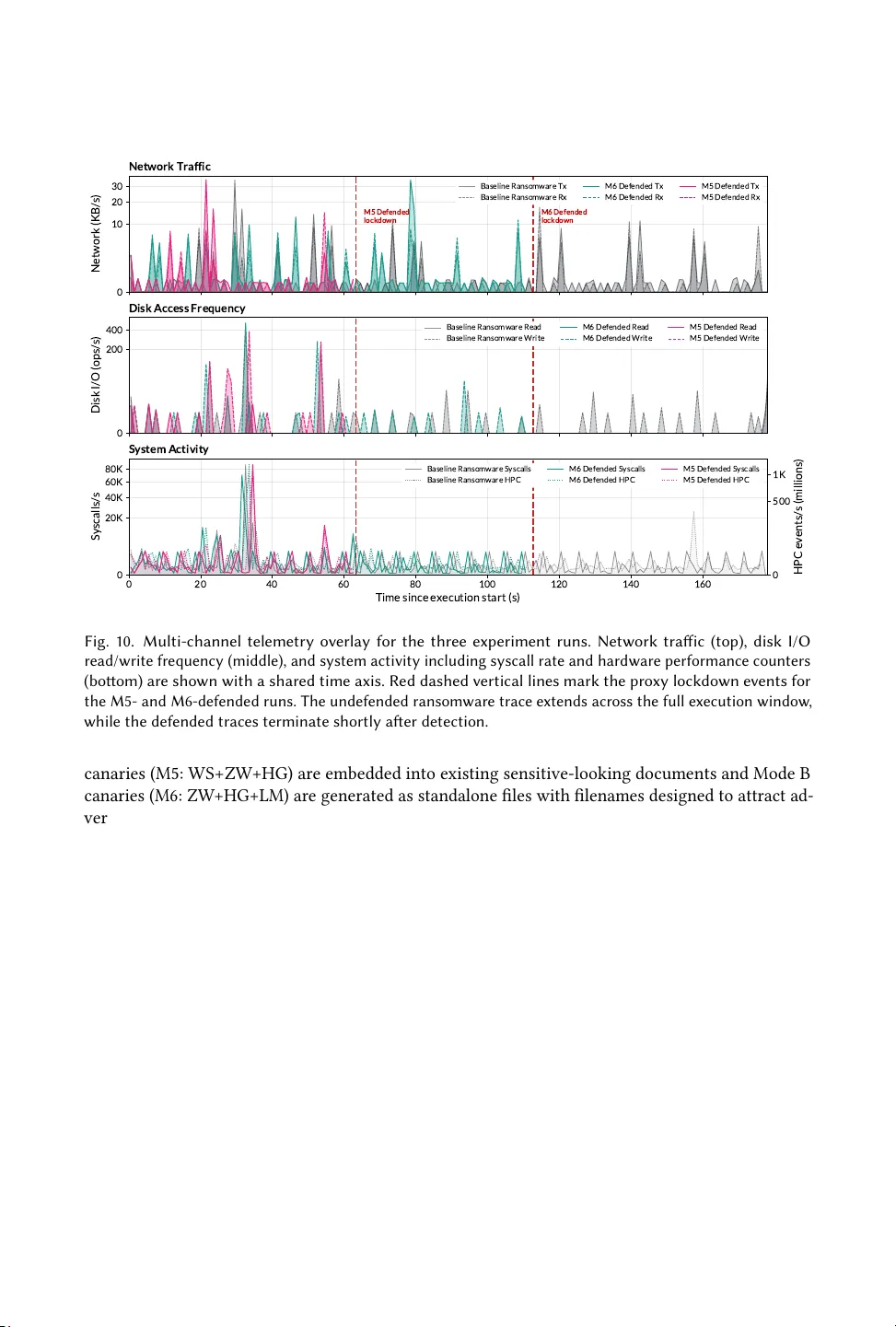
본 논문은 기업 내부에서 생성·보관되는 민감 문서가 외부 클라우드 기반 대형 언어 모델(LLM) 서비스에 무단으로 업로드되는 위험을 해결하기 위해, 텍스트 스테가노그래피와 암호학적 인증을 결합한 “스테가노그래피 캔리 파일” 프레임워크를 제안한다. 연구 배경으로는 AI‑구동 악성코드가 문서 분석, 코드 생성, 정보 추출 등을 위해 외부 LLM을 활용하는 최신 공격 흐름을 제시한다. 기존 엔드포인트·네트워크 기반 DLP는 평문이 외부 서비스에 전송된 뒤에는 가시성을 상실하고, 의미 기반 PII 탐지는 높은 오탐률과 회피 가능성으로 실효성이 떨어진다. 따라서 문서 자체에 식별자를 은닉하고, LLM 서비스 입구에서 이를 검증·차단하는 방어가 필요하다는 점을 강조한다.
프레임워크는 두 가지 운영 모드(A, B)를 제공한다.
- **Mode A**: 기존 민감 문서에 심볼릭 스테가노그래피를 적용한다. 구체적으로 공백 대체(Whitespace Substitution, WS), 제로‑폭 문자 삽입(Zero‑Width, ZW), 동형문자( Homoglyph, HG) 세 가지 인코딩을 레이어링한다. 각 인코딩은 바이트 스트림을 Unicode 코드 포인트에 매핑해 눈에 보이지 않게 삽입한다. 암호학적 식별자는 HMAC‑SHA256 혹은 EdDSA 서명 형태로 생성되어, 복원 시 검증 가능하도록 설계된다.
- **Mode B**: GPT‑2 기반 언어 스테가노그래피를 활용해 자연스러운 문장을 생성하고, 그 위에 Mode A와 동일한 심볼 레이어를 겹친다. 여기서는 산술 코딩(arithmetic coding)을 이용해 비밀 비트를 확률 모델에 매핑하고, 생성된 텍스트는 인간이 읽어도 의미가 일관된다. 이렇게 하면 텍스트 자체가 정상적인 문서처럼 보이면서도, 심볼 레이어가 변형에 대한 추가 방어를 제공한다.
논문은 전송·변형 위협을 **4‑Tier Taxonomy** 로 구분한다.
- **Tier 1**: 복사·붙여넣기, 단순 텍스트 추출 등 가장 기본적인 워크플로우.
- **Tier 2**: PDF→텍스트 변환, HTML 정제, 기본 Unicode 정규화(NFC) 등 일반적인 사전 처리.
- **Tier 3**: 공격자가 의도적으로 인코딩을 교란시키는 변형(예: Unicode NFKC, 공백 압축, 문자 교체, 자동 교정).
- **Tier 4**: 극단적인 변형(예: 완전 재작성, 번역, 요약)으로, 스테가노그래피가 원본을 완전히 소실시킬 가능성이 있다.
실험에서는 7가지 구성과 6개의 복합 전송 체인을 설계해 각 인코딩·레이어의 복원율을 측정했다. 결과는 다음과 같다.
- Tier 1·2에서는 모든 인코딩이 100% 복원율을 보였으며, HMAC·EdDSA 검증에서도 오탐이 전혀 없었다.
- Tier 3에서는 Mode A가 심볼 레이어 간 교차 간섭으로 복원율이 급격히 감소할 수 있음을 확인했으며, 특히 동일 문자 위치에 WS와 ZW를 동시에 적용하면 복원율이 0%에 수렴했다. 반면 Mode B는 언어 스테가노그래피가 문자‑레벨 변형에 어느 정도 내성을 보여 97% 복원율을 유지했다.
- 레이어링 원칙을 도출해 “비중첩 레이어링”(각 심볼 레이어는 서로 다른 문자 위치에 적용)과 “다중 채널 조합”(심볼 + 언어) 전략이 복원율을 최적화한다는 결론을 제시한다.
시스템 구현은 LLM 서비스 제공자 측에 **Pre‑Ingestion Filter** 를 배치하는 형태다. 필터는 업로드된 텍스트 스트림을 실시간으로 스캔하고, 사전 정의된 HMAC·EdDSA 키로 식별자를 검증한다. 검증 성공 시 요청을 차단하거나 경고를 반환한다. 이 과정은 모델 자체의 거부 메커니즘에 의존하지 않으며, 서비스 제공자와 고객 간 계약 기반 보안 계층을 추가한다.
성능 측면에서는 인코딩·디코딩이 서브밀리초 수준, HMAC 검증이 마이크로초 수준으로, 실시간 서비스에 적용 가능함을 보였다. 메모리 사용량도 수 MB 수준에 머물러 대규모 배치 처리 파이프라인에 쉽게 통합될 수 있다.
마지막으로, 논문은 **엔드‑투‑엔드 사례 연구** 로 LLM‑오케스트레이션 랜섬웨어(PromptLock) 파이프라인을 재현했다. 공격자는 초기 정찰 단계에서 파일 목록을 LLM에 전달하고, 이후 암호화 모듈을 다운로드한다. 캔리 파일이 포함된 문서를 업로드하면 사전 필터가 식별자를 검출해 공격 흐름을 조기에 차단했으며, 파일 암호화가 전혀 이루어지지 않았다.
**핵심 기여**는 다음과 같다.
1. **방어 프레임워크**: 심볼릭·언어 스테가노그래피를 결합한 다중 레이어 캔리 파일 설계와 암호학적 검증 메커니즘.
2. **전송‑변형 Taxonomy** 및 체계적 평가: 4‑Tier 모델을 통해 각 레이어의 복원율과 실패 모드를 정량화.
3. **실제 공격 차단**: LLM‑기반 랜섬웨어 시나리오에서 사전 차단을 입증.
**제한점 및 향후 과제** 로는 (1) 고도화된 공격자가 사전‑인제스트 필터 자체를 우회하거나, (2) 언어 모델이 스테가노그래피 탐지를 위한 훈련을 받게 될 경우 방어 효율이 감소할 가능성을 들었다. 또한, Tier 4와 같은 극단적 변형에 대한 복원율은 낮으며, 이를 보완하기 위한 추가 메타데이터 기반 트립와이어나 다중 파일 결합 기법이 필요하다.
결론적으로, 이 연구는 LLM 활용 환경에서 데이터 유출을 탐지·차단하는 새로운 방어 패러다임을 제시하며, 실용적인 구현과 정량적 평가를 통해 기업 보안에 바로 적용 가능한 솔루션을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기