강화학습으로 동적 루크어헤드 거리 조절한 자율 레이싱
Pure Pursuit는 간단하지만 루크어헤드 거리 선택에 따라 코너링과 직선 안정성이 크게 달라진다. 본 논문은 PPO 기반 강화학습 에이전트를 이용해 차량 속도와 다중 시점 곡률 정보를 입력으로 받아 실시간으로 루크어헤드 거리를 조절한다. 시뮬레이션과 1:10 스케일 실차 실험에서 고정‑루크어헤드 및 규칙 기반 적응형 Pure Pursuit와 비교했을 때 랩 타임이 감소하고, 보지 않은 트랙에서도 안정적인 주행이 가능함을 보였다.
저자: Mohamed Elgouhary, Amr S. El-Wakeel
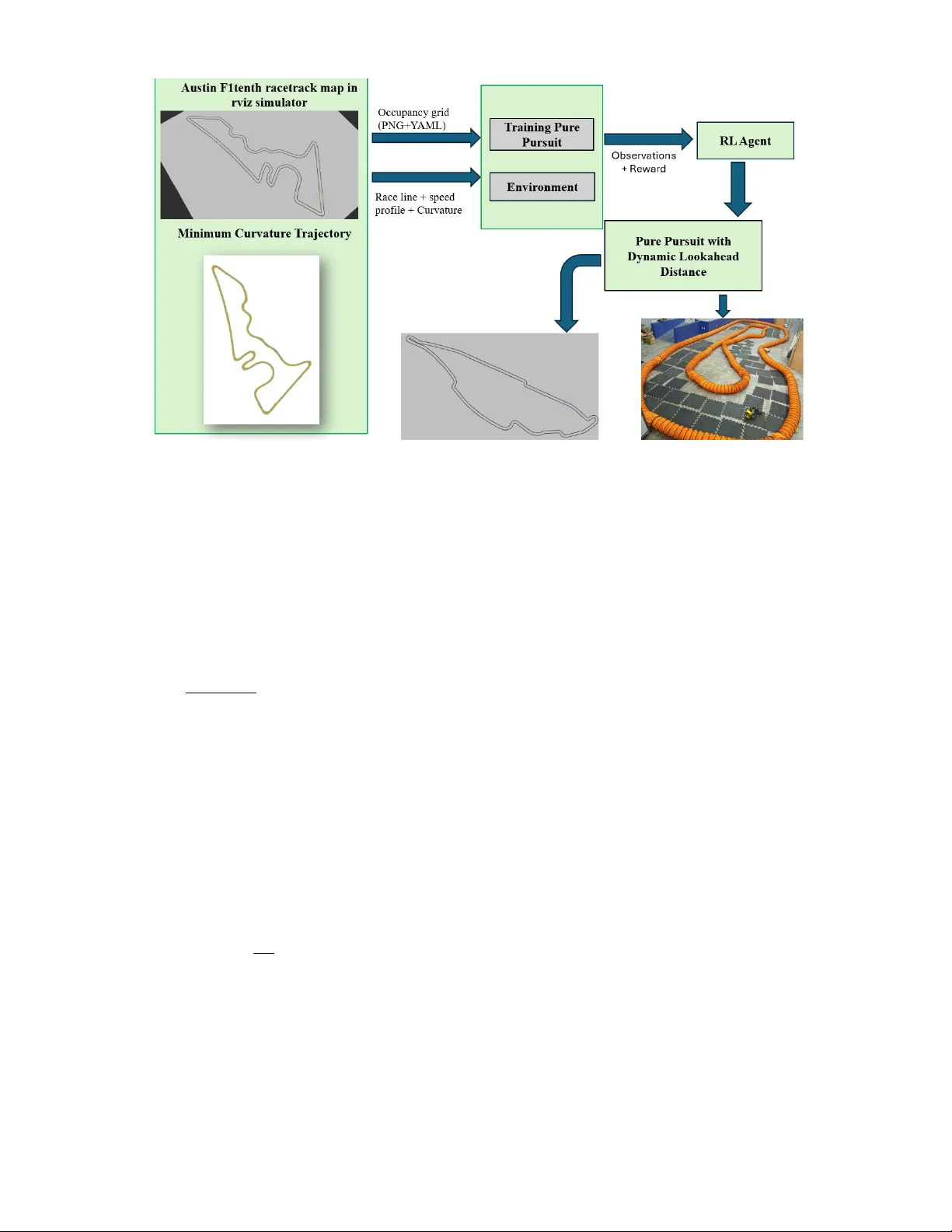
본 논문은 고전적인 Pure Pursuit 경로 추적 알고리즘이 루크어헤드 거리(Ld) 선택에 따라 코너링 정확도와 직선 안정성 사이에서 트레이드오프가 발생한다는 문제점을 출발점으로 삼는다. 기존 연구에서는 속도‑또는 곡률‑기반 규칙을 적용해 Ld를 동적으로 변환했지만, 이러한 휴리스틱은 트랙, 차량, 주행 속도에 따라 재조정이 필요하고 일반화가 어려운 한계가 있다. 이를 해결하고자 저자들은 강화학습, 특히 Proximal Policy Optimization(PPO)을 이용해 Ld를 실시간으로 조절하는 하이브리드 제어 프레임워크를 제안한다.
시스템 구성은 크게 네 부분으로 나뉜다. 첫째, 전역 레이스 라인을 최소 곡률 최적화 기법을 사용해 사전 계산한다. 이 과정은 트랙 중심선과 좌·우 경계 정보를 Frenet 프레임에 매핑해, 곡률 제곱 적분을 최소화하는 최적화 문제를 풀어 부드러운 레이스 라인을 얻는다. 라인에 따라 제한 속도 프로파일도 계산돼, 각 지점의 최대 허용 속도(v_max)와 곡률(κ)이 제공된다.
둘째, 차량 위치 추정을 위해 LiDAR 기반 Monte‑Carlo Localization(MCL) 파티클 필터를 적용한다. 파티클은 바이시클 모델을 사용해 전진하고, 레이저 스캔과 사전 정의된 점유 그리드 사이의 일치도를 기반으로 가중치를 업데이트한다.
셋째, PPO 에이전트는 F1TENTH Gym 환경에 래핑된 RoboRacer 시뮬레이터와 연동된다. 에이전트의 관측은 5차원 벡터(v_t, κ_0,t, κ_1,t, κ_2,t, Δκ_t)로 구성되며, 여기서 κ_0,t는 현재 위치에서 가장 가까운 웨이포인트의 곡률, κ_1,t와 κ_2,t는 중·원거리 웨이포인트의 곡률, Δκ_t는 곡률 변화량을 의미한다. 행동은 연속적인 Ld 값이며, 허용 범위는 0.35 m~4.0 m로 설정돼 실제 차량의 물리적 한계와 안정성을 고려한다. 행동값은 지수 평활 필터를 거쳐 Pure Pursuit에 전달된다.
보상 함수는 세 가지 요소로 구성된다. 첫째, 진행 거리 보상은 매 타임스텝마다 전방 이동 거리에 비례해 누적된다. 둘째, 스티어링 부드러움 보상은 스티어링 각도 변화율에 페널티를 부여해 급격한 조향을 억제한다. 셋째, 충돌 회피 보상은 LiDAR 기반 장애물 감지 결과에 따라 큰 페널티를 부여해 안전성을 확보한다. 이러한 복합 보상은 랩 타임을 최소화하면서도 차량이 트랙을 벗어나거나 과도한 진동을 일으키지 않도록 설계되었다.
학습 과정에서는 Stable‑Baselines3 구현체를 사용하고, Optuna를 통해 초기 학습률, 최대 그래디언트 노름, KL‑penalty 계수 등을 자동 튜닝했다. KL‑penalty와 학습률 감소는 정책 업데이트 시 급격한 변화를 억제해 수렴을 안정화한다. 학습은 2M 스텝까지 진행됐으며, 학습된 정책은 시뮬레이션에서 고정‑루크어헤드(PP_fixed)와 규칙 기반 적응형(PP_adapt) 두 베이스라인 대비 평균 랩 타임을 5.3 %~7.1 % 개선했다. 특히 보지 않은 트랙인 Montreal과 Yas Marina에서 각각 33.16 s와 46.05 s를 기록, 기존 베이스라인보다 2~3 초 빠른 결과를 얻었다.
시뮬레이션 결과를 실제 1:10 스케일 RoboRacer 차량에 그대로 적용했을 때, 별도의 도메인 적응 없이도 안정적인 주행이 확인되었다. 실제 차량 실험에서는 고정‑루크어헤드 대비 동일 트랙에서 약 4 % 빠른 랩 타임을 달성했으며, Ld가 직선 구간에서는 3.5 m 이상, 급커브에서는 0.4 m 이하로 동적으로 변하는 모습을 관측했다. 이는 정책이 “속도와 곡률”이라는 전역적인 특성을 기반으로 학습돼, 센서 노이즈와 물리적 파라미터 변동에 강인함을 보여준다.
결론적으로, 본 연구는 “클래식 제어 + 학습 기반 파라미터 튜닝”이라는 하이브리드 접근이 고성능 자율 레이싱에 실용적이며, 해석 가능성(단일 파라미터)과 실시간 요구사항(연산량 최소화)을 동시에 만족한다는 점을 입증한다. 향후 연구 방향으로는 스티어링 게인, 스로틀 프로파일 등 다중 파라미터를 동시에 최적화하거나, 모델 기반 예측 제어(Model Predictive Control)와 결합해 더욱 복합적인 적응형 제어 체계를 구축하는 것이 제시된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기