오프라인 다중에이전트 강화학습을 위한 적응형 부분 행동 교체 학습
오프라인 MARL에서 공동 행동 공간이 급격히 커지는 문제를 해결하기 위해, 저자는 부분 행동 교체(PAR) 전략을 상태에 따라 동적으로 선택하는 컨텍스트 밴드잇 기반 정책을 제안한다. 새로운 프레임워크 PLCQL은 PPO로 학습되는 PAR 정책과 불확실성 가중 보상을 결합해, 교체할 에이전트 수를 상황에 맞게 조절한다. 이로써 기존 SPaCQL이 필요로 하던 다중 서브셋 평가를 한 번의 Q‑함수 계산으로 대체해 계산량을 크게 줄였으며, 66 …
저자: Yue Jin, Giovanni Montana
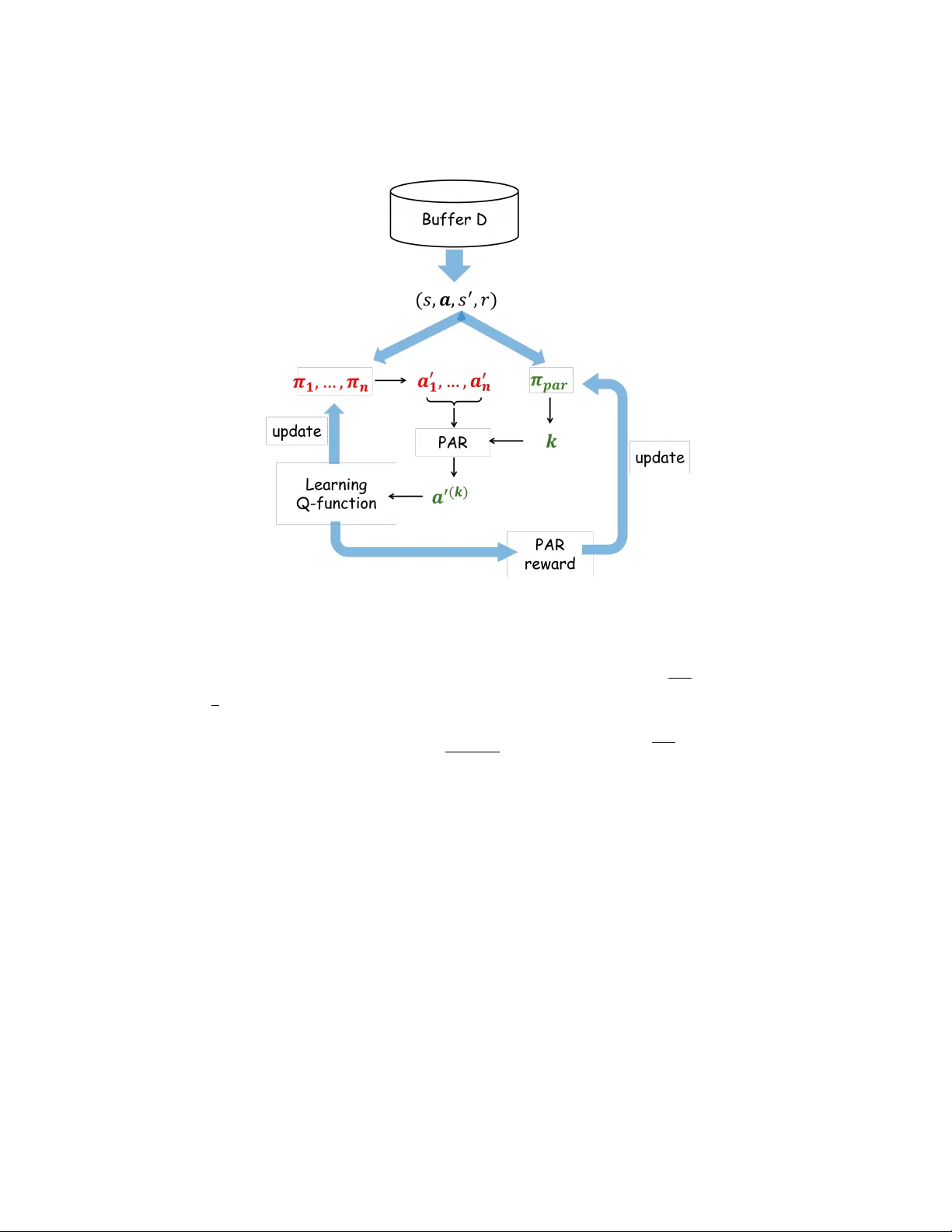
오프라인 다중에이전트 강화학습(Offline MARL)은 고정된 데이터셋만을 이용해 협동 정책을 학습해야 하는 상황에서, 특히 로봇, 자율주행, 대규모 자원 관리 등 실제 시스템에 적용될 때 큰 장점을 가진다. 그러나 에이전트 수가 늘어날수록 가능한 공동 행동 공간이 지수적으로 확대되어, 동일한 데이터셋이 차지하는 비율은 급격히 감소한다. 이로 인해 학습 과정에서 OOD(Out‑Of‑Distribution) 공동 행동을 평가하게 되고, 신경망 기반 가치 함수는 이러한 미보정 행동에 대해 과도하게 높은 Q‑값을 예측할 위험이 있다. 기존의 오프라인 RL에서 사용되는 행동 정규화나 보수적 가치 추정 기법은 단일 에이전트 상황에서는 어느 정도 효과적이지만, 다중 에이전트 환경에서는 공동 행동의 조합 희소성이 훨씬 더 심각해져 직접적인 적용이 어려웠다.
Partial Action Replacement(PAR)라는 아이디어는 이러한 문제를 완화하기 위해, 전체 공동 행동 중 일부 에이전트만 현재 정책에 따라 행동을 바꾸고, 나머지는 데이터에 기록된 행동을 그대로 사용한다. 이렇게 하면 한 번에 변형되는 차원의 수가 제한되어, OOD 행동에 대한 평가가 제한적이며, 가치 추정의 불확실성이 감소한다. 그러나 PAR을 효과적으로 활용하려면 어느 에이전트 집합을 교체할지, 혹은 교체할 에이전트 수 k를 어떻게 정할지가 핵심이다. 기존 방법인 Soft Partial Conservative Q‑Learning(SPaCQL)은 여러 k값에 대해 무작위로 서브셋을 샘플링하고, 각각에 대해 Q‑값을 계산한 뒤 불확실성 기반 가중치를 적용한다. 이 과정은 매 학습 스텝마다 O(n)번의 Q‑함수 평가를 필요로 하며, 계산 비용이 크게 늘어난다. 또한, 불확실성 가중치가 단순히 앙상블 분산에만 의존하기 때문에, 협동 효율을 직접적으로 촉진하는 서브셋을 우선시하지 못한다.
본 논문은 이러한 한계를 극복하기 위해 PLCQL(Partial Learning‑based Conservative Q‑Learning)이라는 새로운 프레임워크를 제안한다. 핵심 아이디어는 “PAR 서브셋 선택을 상태에 따라 동적으로 결정하는 정책”을 학습하는 것이다. 이를 위해 저자들은 다음과 같은 설계 선택을 했다.
1. **컨텍스트 밴드잇 모델링**
- 컨텍스트: 현재 전이에서 얻은 부트스트랩 상태 s′(다음 상태)
- 행동: 교체할 에이전트 수 k ∈ {1,…,n}
- 보상: 불확실성‑가중된 가치 추정 r_par(s′,k) = σ(−u_Q·T) + Q_θ1(s′,a′(k))
여기서 u_Q는 Q‑함수 앙상블의 분산이며, σ는 시그모이드 형태의 스케일링 함수, T는 온도 파라미터다. 높은 분산은 해당 서브셋에 대한 데이터 커버리지가 낮음을 의미하므로 보상을 억제한다.
2. **PAR 정책 π_par**
- 파라미터화된 신경망이 s′를 입력받아 k에 대한 확률 분포를 출력한다.
- 선택된 k에 대해 에이전트 집합 c는 균등 무작위로 샘플링되고, 그 집합에 속한 에이전트만 현재 정책 π에 따라 행동을 선택한다.
3. **Bellman 연산 T_k**
- T_k Q(s,a) = E_{s′,a′(k)}
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기