클라우드 서비스 현장 평가를 위한 실전 LLM 에이전트 벤치마크 CirrusBench
CirrusBench는 실제 클라우드 서비스 티켓을 기반으로 만든 벤치마크로, 다중 턴 대화와 복잡한 툴 연동을 보존한다. 기존의 정답률 중심 평가를 넘어 고객 만족을 측정하는 효율성 지표(Normalized Efficiency Index, Multi‑Turn Latency 등)를 도입해 LLM 에이전트의 실사용 적합성을 종합적으로 평가한다.
저자: Yi Yu, Guangquan Hu, Chenghuang Shen
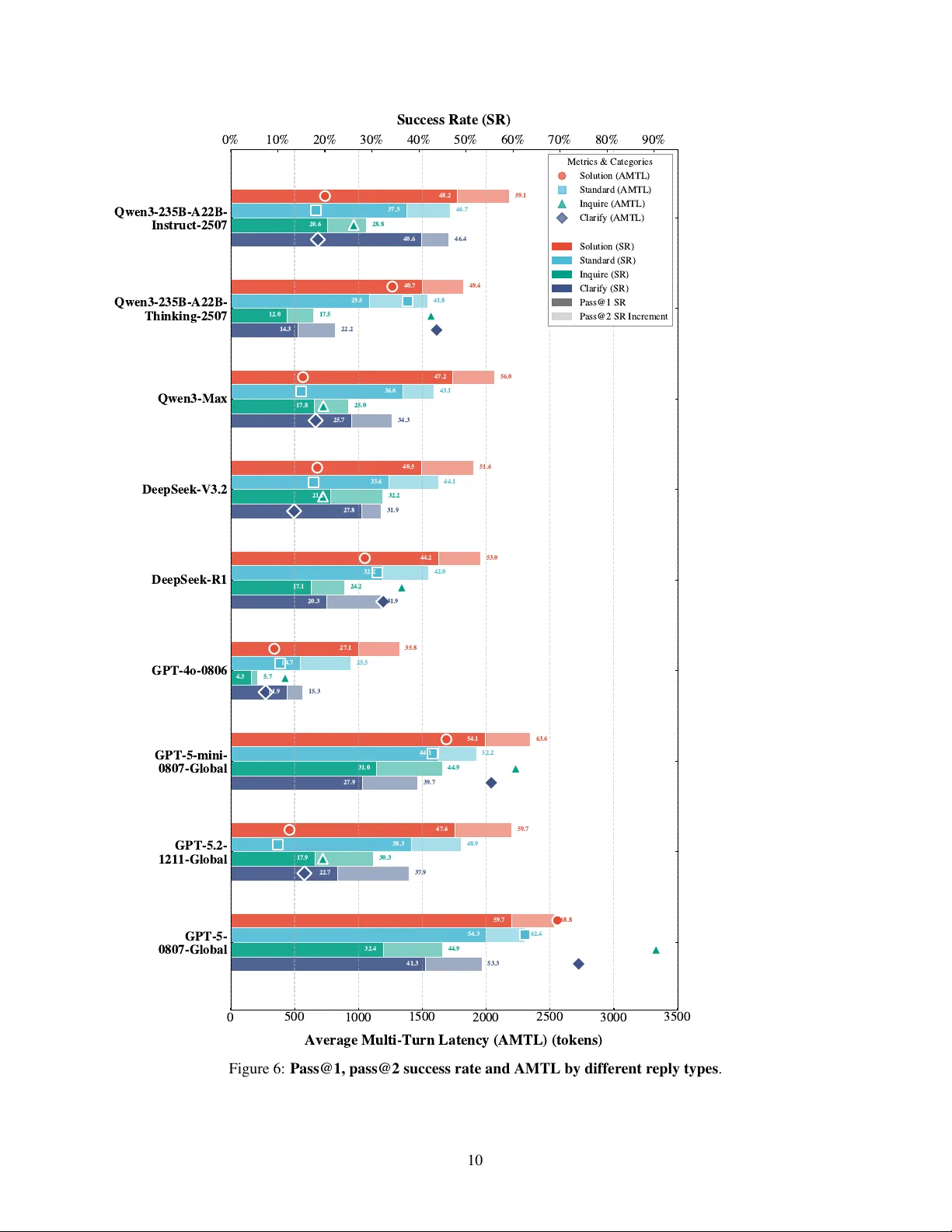
본 연구는 LLM 기반 에이전트가 클라우드 서비스와 같은 고도 기술 지원 현장에서 실제로 사용될 때 마주하는 복합적인 요구사항을 정량화하고 평가하기 위해 새로운 벤치마크 프레임워크인 CirrusBench를 제안한다. 기존 벤치마크는 주로 합성된 시뮬레이션 환경이나 역할극 데이터를 사용해 정답률과 툴 선택 정확도에 초점을 맞추었으며, 실제 고객 입력의 다양성·불확실성 및 해결 효율성이라는 핵심 요소를 간과했다. 이를 보완하기 위해 저자들은 실제 서비스 티켓 로그를 수집·전처리하여 1,500개의 단일 턴 과제와 425개의 툴 호출이 필요한 복합 과제로 구성된 데이터셋을 구축하였다. 데이터 전처리 과정은 (1) 개인정보 식별·마스킹, (2) 대화 중 불필요한 인삿말·폐쇄 문구 제거, (3) 실제 툴 호출 결과를 기록한 ‘툴 모크’ 생성, (4) 고객의 연속 질문을 하나의 턴으로 병합하는 대화 정규화, (5) 중·영 번역, (6) LLM 기반 체크포인트 자동 라벨링, (7) 도메인 전문가 검증의 7단계로 이루어졌다. 특히 체크포인트는 의도 파악, 툴 호출 결정, 툴 결과 통합 등 핵심 추론 단계로 정의돼, 모델의 논리 흐름을 세밀히 추적할 수 있게 한다.
평가 메트릭은 두 축으로 나뉜다. 첫 번째는 전통적인 정답 기반 지표인 Success Rate(SR)와 Task Progress Rate(TPR)이며, 두 번째는 고객 만족을 직접적으로 반영하는 ‘고객 중심 지표’다. Logical Jump(LJ)은 대화 흐름 중 불필요하게 전환되는 논리적 단계 수를 측정해 대화 효율성을 평가한다. Normalized Efficiency Index(NEI)는 모델이 사용한 토큰·시간 대비 성공 여부를 정규화해, 과도한 연산·툴 호출 없이 문제를 해결하는 능력을 수치화한다. Single‑Turn Latency(STL)와 Multi‑Turn Latency(MTL)는 각각 단일 턴 응답 시간과 전체 대화 종료까지 소요된 총 시간을 측정한다. 이러한 지표들은 고객이 실제 서비스 이용 시 기대하는 빠른 응답과 최소한의 상호작용을 객관적으로 반영한다.
실험에서는 최신 LLM 에이전트(GPT‑4‑Turbo, Claude‑2, Gemini‑1.5, LLaMA‑2‑Chat 등)를 CirrusBench에 적용해 성능을 비교했다. 정답률 측면에서는 대부분 80% 이상을 달성했지만, NEI와 MTL에서는 평균 0.35 이하의 낮은 점수를 기록했다. 특히 ‘Thinking’ 모델이라 불리는 고연산 모델은 추론 단계에서 툴 호출을 과도하게 반복해 평균 응답 시간이 2배 이상 늘어났으며, 논리 점프(LJ)도 1.8배 증가했다. 체크포인트 분석 결과, 3개 이상의 논리 점프를 포함한 대화에서는 오류 누적 확률이 45%까지 상승했으며, 이는 장기 대화에서 모델이 상태 추적에 실패함을 의미한다. 또한, 툴 연동이 필요한 과제에서는 툴 호출 정확도는 70% 수준에 머물렀고, 툴 파라미터 설정 오류가 전체 실패 원인의 38%를 차지했다.
저자들은 이러한 결과를 바탕으로 향후 연구 방향을 제시한다. 첫째, 툴 호출 효율성을 높이기 위한 ‘툴 프롬프트 최적화’와 ‘실시간 툴 피드백 루프’ 설계가 필요하다. 둘째, 다중 턴 대화에서 상태 유지와 오류 복구를 위한 ‘대화 메모리 관리’와 ‘재질문 전략’이 중요하다. 셋째, 고객 중심 지표를 학습 목표에 포함시켜 모델이 효율성을 스스로 최적화하도록 하는 ‘멀티-목표 강화 학습’이 요구된다. 마지막으로, 실제 서비스 환경에서 발생하는 장기 토큰 시퀀스(최대 37K 토큰) 처리를 위해 메모리 효율이 높은 아키텍처(예: 플래시 어텐션, 라인어리어 트랜스포머)와 지식 기반 검색 결합이 필수적이다.
결론적으로 CirrusBench는 실전 클라우드 서비스 상황을 그대로 재현한 최초의 대규모 LLM 에이전트 벤치마크이며, 정답률을 넘어 효율성과 고객 만족을 측정하는 새로운 평가 패러다임을 제시한다. 이를 통해 연구자와 기업은 실제 운영 환경에 적합한 에이전트를 설계·개선할 수 있는 구체적인 기준을 확보하게 된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기