도메인 불변 프롬프트 학습으로 비전‑언어 모델 일반화 향상
본 논문은 CLIP 기반 비전‑언어 모델에 소프트 프롬프트를 적용한 CoOp을 확장하여, 도메인 일반화(DG)를 목표로 하는 Domain‑Invariant Context Optimization(DiCoOp)을 제안한다. GRL(Gradient Reversal Layer)을 이용한 적대적 학습으로 프롬프트 내 도메인 정보를 억제하고, 클래스 구분 능력은 유지한다. DFP, CFP, SCP의 세 가지 프롬프트 구조를 실험했으며, 특히 클래스‑우선(…
저자: Arsham Gholamzadeh Khoee, Yinan Yu, Robert Feldt
본 논문은 대규모 사전학습된 비전‑언어 모델(VLM)인 CLIP이 이미지와 텍스트를 공유 임베딩 공간에 정렬함으로써 제로샷 전이 학습을 가능하게 하는 배경에서 출발한다. 기존 연구인 Context Optimization(CoOp)은 텍스트 프롬프트를 학습 가능한 컨텍스트 벡터로 변환해, 다운스트림 이미지 분류 작업에서 성능을 크게 끌어올렸다. 그러나 CoOp은 도메인 이동(domain shift) 상황에서 명시적인 대응 메커니즘이 없으며, 특히 훈련에 사용되지 않은 새로운 도메인에 대한 일반화 능력이 제한적이다.
이를 해결하고자 저자들은 Domain‑Invariant Context Optimization(DiCoOp)이라는 프레임워크를 제안한다. DiCoOp은 두 가지 핵심 요소로 구성된다. 첫째, 프롬프트 학습 과정에 Gradient Reversal Layer(GRL)를 삽입해 도메인 분류 손실을 역전시킴으로써 프롬프트가 도메인 정보를 학습하지 못하도록 만든다. 둘째, 프롬프트 토큰을 ‘도메인 전용’과 ‘클래스 전용’으로 명시적으로 구분하는 세 가지 구조—Shared Context Prompting(SCP), Domain‑First Prompting(DFP), Class‑First Prompting(CFP)—를 도입한다.
수식적으로는 전체 손실 L(v)=L_cls(v)−λL_dom(v) 로 정의된다. 여기서 L_cls는 기존 CoOp과 동일하게 클래스 라벨에 대한 교차 엔트로피 손실이며, L_dom은 도메인 라벨에 대한 교차 엔트로피 손실이다. λ는 도메인 억제 강도를 조절하는 하이퍼파라미터다. 학습 단계에서는 각 이미지에 대해 두 번의 포워드 패스가 수행된다. 첫 번째는 클래스 토큰과 결합된 프롬프트를 사용해 클래스 예측을 수행하고, 두 번째는 도메인 토큰과 결합된 프롬프트를 사용해 도메인 예측을 수행한다. 두 번째 패스에서는 GRL에 의해 그래디언트가 부호가 반전되어, 프롬프트 파라미터가 도메인 구분 능력을 잃게 된다. 이렇게 번갈아 가며 업데이트함으로써, 프롬프트는 클래스 구분은 유지하면서 도메인 차이를 무시하도록 학습된다.
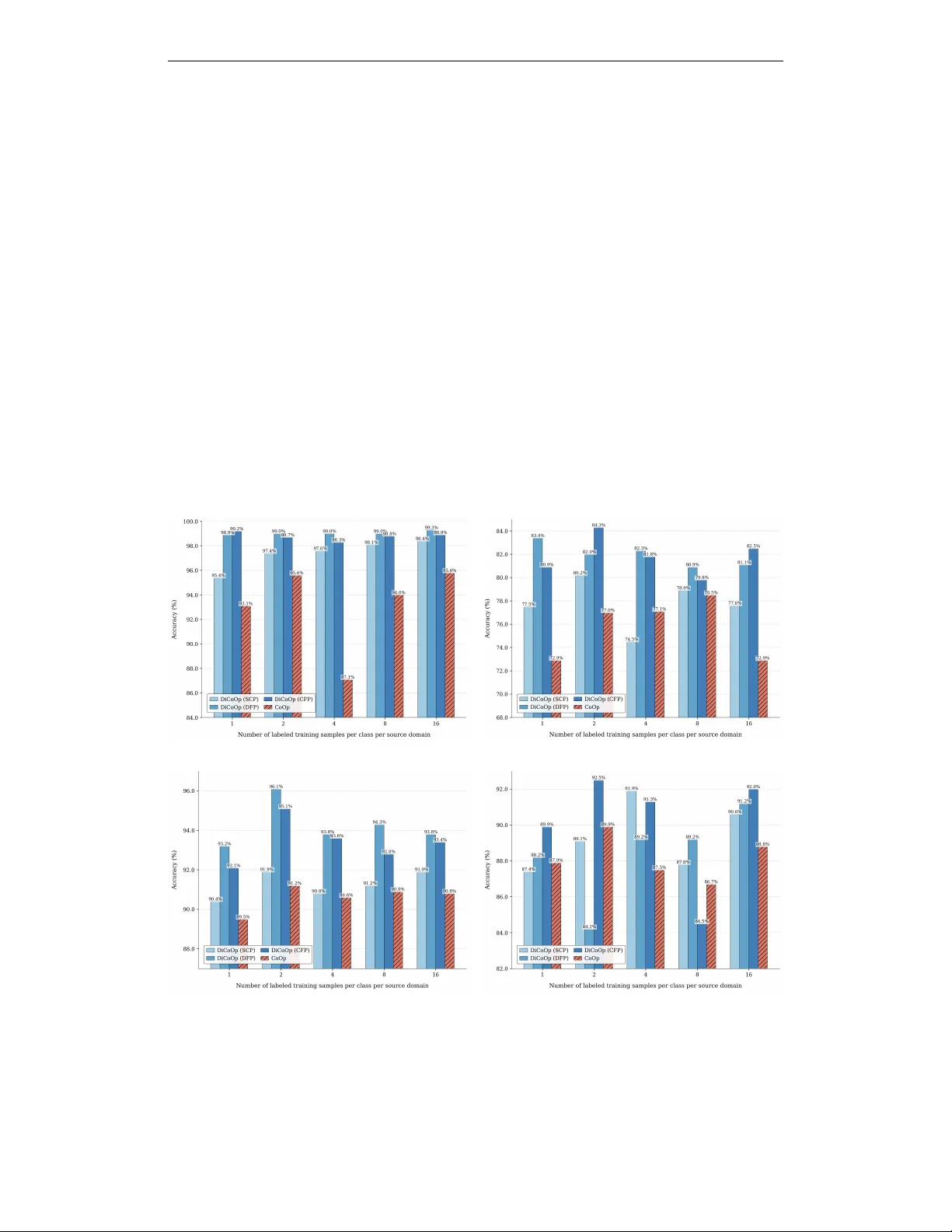
실험은 두 개의 공개 데이터셋을 대상으로 진행되었다. 첫 번째는 사진, 스케치, 만화, 예술 회화 등 네 가지 도메인으로 구성된 PACS이며, 7개의 객체 카테고리를 포함한다. 두 번째는 Mini‑DomainNet으로, Clipart, Painting, Sketch, Real 네 도메인에 126개의 카테고리가 있다. 각각의 실험에서는 leave‑one‑domain‑out 설정을 사용해, 하나의 도메인을 테스트용으로 남기고 나머지 도메인에서 프롬프트를 학습한다. PACS에서는 ResNet‑50 백본을, Mini‑DomainNet에서는 ViT‑B/16 백본을 사용했으며, 프롬프트 길이 M=16을 고정하였다.
결과는 다음과 같다. PACS에서 n‑shot(1,2,4,8,16) 실험 모두에서 DiCoOp이 CoOp보다 높은 정확도를 기록했으며, 특히 CFP와 DFP가 SCP보다 일관되게 우수했다. 이는 도메인·클래스 토큰을 물리적으로 분리함으로써 도메인 억제 효과가 강화된 것으로 해석된다. Mini‑DomainNet에서도 DiCoOp은 모든 타깃 도메인에서 CoOp을 능가했으며, 평균 정확도는 CoOp 대비 2.23% 상승했다. 특히 CFP와 DFP는 평균 84.5%의 정확도를 달성해, 가장 높은 성능을 보였다.
논문의 기여는 크게 세 가지로 정리된다. (1) 프롬프트 레벨에서 도메인 적대적 학습을 도입한 DiCoOp 프레임워크 제시, (2) 도메인·클래스 토큰을 분리하는 세 가지 프롬프트 설계(Domain‑First, Class‑First, Shared)와 그 효과 분석, (3) 두 가지 벤치마크에서 CoOp 대비 일관된 성능 향상을 입증함으로써, 비전‑언어 모델의 도메인 일반화 능력을 실질적으로 개선했다는 점이다.
한계점으로는 도메인 라벨이 필요하다는 전제와, 프롬프트 길이·분할 비율 등에 대한 민감도 분석이 부족하다는 점을 들 수 있다. 또한 실험이 이미지 분류에 국한되어 있어, 객체 검출, 세그멘테이션, 의료 영상 등 다른 비전‑언어 작업에 대한 일반화 가능성은 아직 검증되지 않았다. 향후 연구에서는 (i) 메타‑학습이나 자기지도 학습을 결합해 도메인 라벨 없이도 도메인 억제 효과를 얻는 방법, (ii) 프롬프트 구조를 자동으로 탐색하는 Neural Architecture Search(NAS) 기법 적용, (iii) 다양한 도메인·태스크에 대한 확장 실험을 통해 DiCoOp의 범용성을 검증하는 방향이 제시된다.
결론적으로, DiCoOp은 비전‑언어 모델의 프롬프트 튜닝에 도메인 적대적 원리를 도입함으로써, 기존 소프트 프롬프트 방식이 갖는 도메인 취약성을 보완하고, 실제 현장에서 다양한 환경 변화에 강인한 모델을 구축하는 데 실용적인 진전을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기