멀티모달 사이버 위기 훈련에서 성공을 예측하는 핵심 요인 분석
본 연구는 사이버 보안 테이블탑 시뮬레이션에서 학습 목표와 실제 팀 행동 사이의 인스트럭셔널 정렬(Alignment)을 Bloom 분류법으로 측정하고, 정렬 정도가 과제 성공에 미치는 영향을 검증한다. 23개 팀(76명)의 로그와 이메일 데이터를 활용한 두 단계 연구에서, 정렬 차이가 성공을 유의하게 예측함을 확인했으며, 텍스트 임베딩 및 행동 로그와 결합한 멀티모달 특징이 가장 높은 예측 성능(AUC≈0.80)을 보였다.
저자: Conrad Borchers, Valdemar Švábenský, S
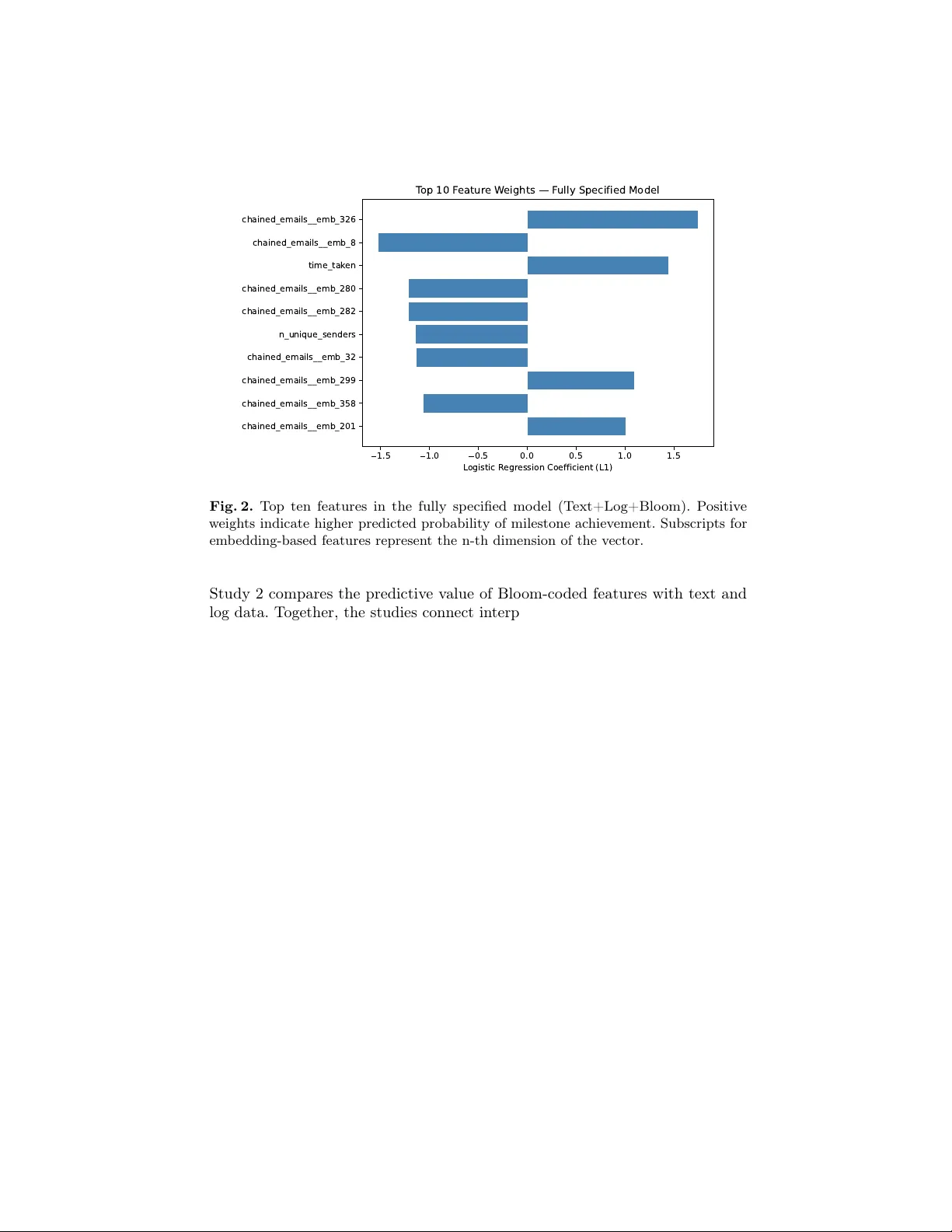
본 논문은 사이버 보안 위기 대응을 위한 테이블탑 시뮬레이션(테이블탑 익서사이즈, TTX)에서 학습 설계와 실제 학습 행동 사이의 정렬(Instructional Alignment)을 측정하고, 그 정렬이 학습 성과에 미치는 영향을 실증적으로 분석한다. 연구는 두 개의 서브스터디로 구성된다.
**연구 배경 및 목표**
Instructional Alignment는 학습 목표, 활동, 평가가 일관성을 유지하는지를 의미하며, Bloom’s Taxonomy를 통해 인지적 요구 수준을 정의한다. 기존 연구는 주로 단일 모달(클릭스트림, 과제 점수) 데이터를 활용했지만, 협업 기반 시뮬레이션에서는 이메일, 로그, 행동 데이터 등 다양한 모달이 동시에 발생한다. 따라서 본 연구는 (1) 목표와 실제 이메일 커뮤니케이션 사이의 Bloom 수준 차이가 성공을 예측하는가(RQ1), (2) Bloom 라벨만을 사용한 모델과 멀티모달 피처(텍스트 임베딩, 로그 기반 행동 피처)를 결합한 모델 중 어느 것이 더 예측력이 높은가(RQ2)를 탐구한다.
**데이터 및 실험 설계**
- **참가자**: 체코와 에스토니아의 대학·직업학교 학생들로 구성된 23팀(총 76명)
- **시나리오**: INJECT Exercise Platform을 이용한 5회 연속 TTX, 각 팀은 18개의 마일스톤을 순차적으로 수행한다.
- **데이터**: 팀별 이메일 본문(텍스트), 플랫폼 로그(액션 타임스탬프, 액션 종류), 마일스톤 완료 여부(이진)
**코딩 절차**
이메일을 Bloom’s Taxonomy의 6단계(Remembering, Understanding, Applying, Analyzing, Evaluating, Creating) 중 가장 높은 수준으로 라벨링하였다. 3명의 코더가 독립적으로 라벨링하고, 토론·재조정을 거쳐 최종 라벨을 확정했으며, Cohen’s κ는 0.55~0.68, Fleiss’ κ는 0.636을 기록했다.
**Study 1 – 정렬과 성과**
각 마일스톤에 대해 (1) 관찰된 Bloom 수준, (2) 목표 Bloom 수준(마일스톤 정의에 기반) 사이의 차이를 0(일치), 1(인접), 2(불일치)로 정의한 ‘Discrepancy Score’를 계산했다. 일반화 선형 혼합 모델(GLMM)로 마일스톤 성공 여부를 예측했으며, 모델은 팀별 랜덤 인터셉트를 포함했다. 결과는:
- 관찰된 Bloom 수준만을 포함한 기본 모델보다, Discrepancy Score를 추가한 모델이 유의하게 더 좋은 적합도를 보였다(우도비 검정 p<0.01).
- Discrepancy Score가 1 증가할 때 성공 odds ratio가 약 0.45(95% CI 0.32‑0.63)로 감소했다.
- Bloom 수준과 Discrepancy 간 상호작용은 유의하지 않아, 정렬 차이가 모든 인지 수준에서 비슷한 영향을 미쳤다.
**Study 2 – 멀티모달 예측 모델**
다양한 피처 집합을 구성했다:
1. **Bloom‑only**: 각 마일스톤별 Bloom 라벨 빈도 (6차원)
2. **텍스트 임베딩**: BERT‑base 모델을 이용해 이메일 본문을 768‑차원 벡터로 변환, 평균 풀링 후 차원 축소(PCA) 적용
3. **로그 피처**: 액션 종류 카운트, 응답 시간 평균·분산, 마일스톤 진행 속도 등 12개 통계량
4. **조합**: 위 세 집합을 모두 결합
모델은 L1 정규화 로지스틱 회귀를 사용했으며, 팀 단위 그룹 교차 검증(Leave‑One‑Team‑Out)으로 일반화 성능을 평가했다. 주요 결과는 다음과 같다.
- Bloom‑only 모델 AUC≈0.55 (거의 무작위 수준)
- 텍스트 임베딩 모델 AUC≈0.74, 로그 피처 모델 AUC≈0.71
- 텍스트 + 로그 결합 모델 AUC≈0.80 (테스트 셋)
- Bloom 피처를 추가해도 AUC 상승폭은 미미(≈0.01)
이로써 멀티모달 데이터가 단일 인지 라벨보다 학습 성과를 예측하는 데 훨씬 유용함을 확인했다.
**논의 및 시사점**
- **정렬의 진단적 가치**: Discrepancy Score는 교육 설계자가 목표와 실제 활동 사이의 차이를 실시간으로 파악하고, 즉각적인 피드백을 제공할 근거가 된다.
- **예측 모델의 실용성**: 텍스트와 로그를 결합한 모델은 사전에 팀의 성공 가능성을 높은 정확도로 예측할 수 있어, 교육자에게 조기 개입 시점을 알려줄 수 있다.
- **제한점**: 이메일이 없는 마일스톤(20%)에 대한 정렬 측정이 불가능했으며, 구두 대화는 분석에서 제외되었다. 또한, Bloom 라벨링의 신뢰도가 카테고리마다 차이가 나므로 자동화된 라벨링 모델 개발이 필요하다.
**결론**
본 연구는 사이버 보안 시뮬레이션에서 인스트럭셔널 정렬을 정량화하는 새로운 방법을 제시하고, 정렬 차이가 학습 성과에 중요한 영향을 미친다는 실증적 증거를 제공한다. 동시에, 멀티모달 학습 분석(텍스트 임베딩 + 행동 로그)이 성과 예측에 가장 효과적이며, Bloom 라벨은 진단적 인사이트 제공에 주로 활용될 수 있음을 보여준다. 이러한 결과는 교육 설계, 실시간 학습 지원, 그리고 자동화된 학습 분석 시스템 구축에 중요한 시사점을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기